
打印证券名称字段时要对齐. 对齐!对齐!
打印证券名称字段时要对齐. 对齐!对齐!
简述
打印一个列表数据 或者字典时, 如果列数据里是中英文混编的, 比如""证券名称""
那么, 对齐输出就是个问题了. 即便是用强大的python str.format函数, 也需要做一些
细致的工作.
缘由
通常地, 打印一个中文字的宽度是2或者是1.8(取决于所使用的字体)
比如用新宋体时就是2, 采用Consolas字体时就是1.8.
前者是CMD窗口里的缺省字体设置, 而后者是spyder环境里字体的缺省设置.
以cmd窗口里, 运行python 3 脚本为场景, 来看看问题的症结在哪里.
要求是: "证券名称"的打印域宽是8, 这是因为该字段都不超过4个汉子, 允许里面夹杂着ascii字符.
如果是"招商银行", 那么其len()的值是4, 表示是4个unicode字符的字符串, format()输出时
采用宽度为4就可以得到域宽为8的字符串输出了.
代码片段为:
print('{:<4}'.format(name))
如果是"柳工"呢, 其长度是2, 2个汉子, 还想得到8个域宽, 该如何设置打印的宽度呢?
答案是: 8-2=6 (因为每个汉子的打印域宽为2, 字段里有几个汉字就要减掉几, 就能得到format里需要设定的宽度)
代码片为:
print('{:<6}'.format(name))
如果是"*st老张"呢,
该字段的特点是: 3个ascii字符, 2个汉字, unicode()长度值是5
答案是: 8-2=6, '' *st ''站3个位置, ''老张''站4个位置, 填充的1个空格站一个位置(6-len(name)=6-5=1)
SO make IT 8个打印域宽
正解
为每一个 名称 设定不同的宽度pWidth, 以确保其打印域宽=8
count = print_width(name) #统计出汉字的个数 in name 字段里的
pWidth= 8 - count
代码片:
def test_monitor_quotes(p=120,delta=10, block='zxg', subset=(10,15,1)):
u'''
'''
symbols,contexts = read_zxg(subset)
i=0
print('{:>5} {:<8} {:<6} {:>12} {:<20s}'.format('Num', 'Name', 'Code', 'Change_rate', 'Time'))
def print_width(name):
# count=0
# for e in n:
# if ord(e)<128:
# count +=1
# pWidth = count + (len(n)-count)*2
# pWidth = 8 if pWidth<8 else
#width=len(name.encode('gbk'))
#len1 =len(name)
count=0
for e in name:
if ord(e)>=128:
count += 1
return 8-count
while p>=0:
i +=1
tm = time.localtime()
quote = hq.test_get_s_quotes(symbols, show=False)
for enum,q in enumerate(quote):
#q=quote[0]
contex=Context(contexts[enum])
change_r = (q['price']/q['last_close'] -1 )*100.
# 依据 contex.name, 计算它的打印域宽
pWidth = print_width(contex.name)
print('{:>5} {d.name:<{pw}} {d.code:<6} {roc:12.2f} {tms:20s}'.format(
i,d=contex, pw=pWidth, roc=change_r, #print_width
tms=time.strftime('%Y%m%d %H:%M:%S',tm)))
print()
time.sleep(delta)
p -= delta # time.localtime().tm_sec
结果展示
在spyder的ipython窗口里:
注意: 我已经把字体从consolas改为新宋体了(后面有解释)
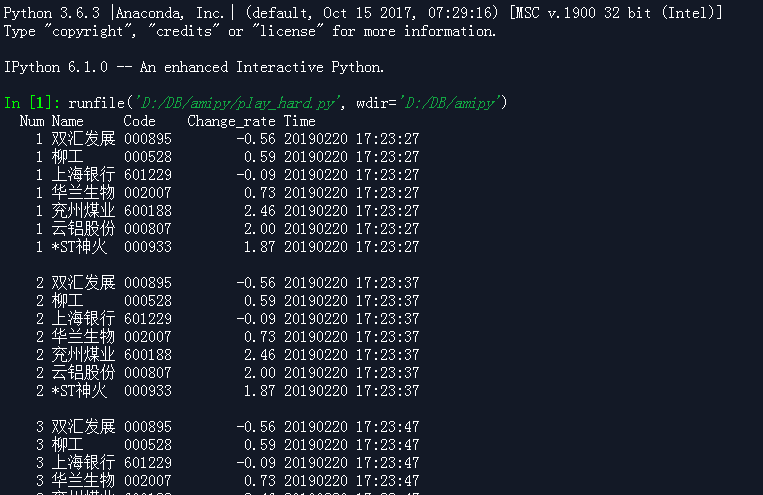
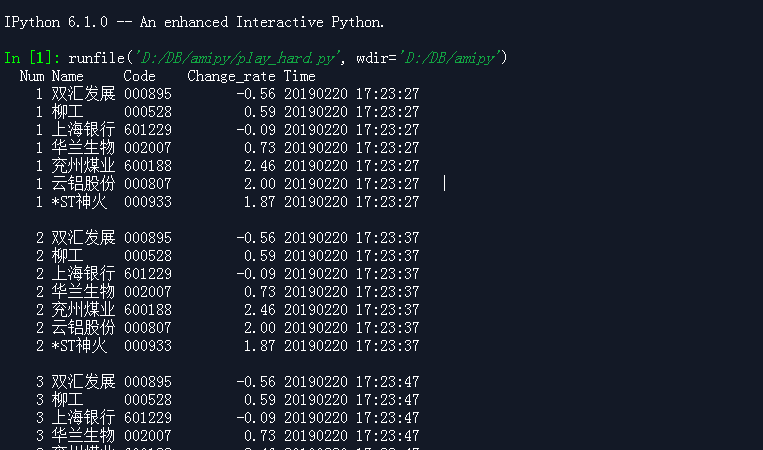
哎呀! 又截图一次, blog里的效果还是有点虚. 不知道为什么??
在Ipython窗口里的效果, 跟cmd窗口里的是一样的.
用360截图工具再来一个截图, 看看效果与snipaste的截图有没有不同:
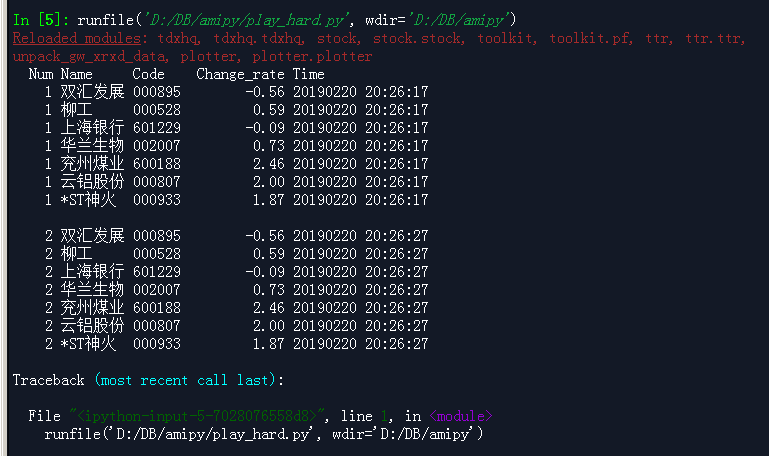
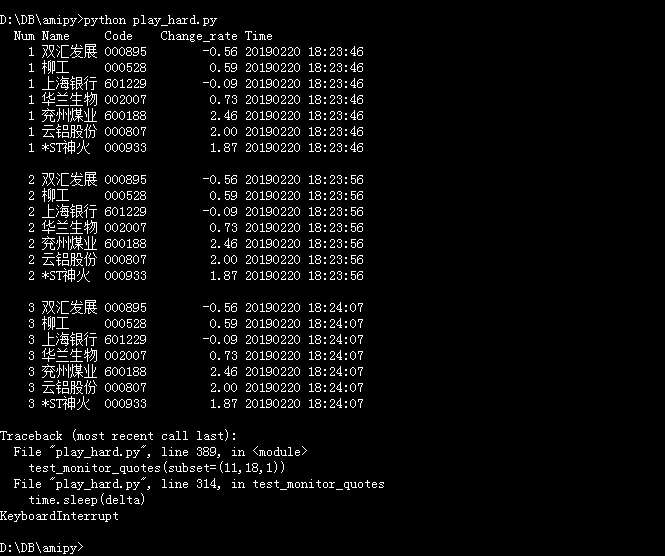
在cmd窗口里的结果:
如何应对1.8宽度的运行环境呢?
比如还想用IPython的consolas字体, 确实已经习惯了这个配置, 可是用上述办法又不能精确对齐, 咋办呢?
答案是: 先填充全角空格到name字段, 使得它至少包含5个汉字. 做这个转换的目的就是因为:
5 * 1.8 = 9, 是个整数Integer, 就是说能够精确对齐了.
如果是4个汉字, 那么其打印域宽将是: 4*1.8 = 7.2,
这时候你无论怎么填充, 都得不到一个精确的对齐. 因为有小数部分了.
考虑到该字段里可能还会有1至3个ascii符的情况, 所以需要把该字段的打印域宽设定为: 9+3=12
比前面的宋体的情况要多出4个英文空格的空间. 还要进行一次转换
所以太麻烦了, 而且浪费了4个打印宽度.
因此权衡再三, 决定还是放弃这个外观很美的字体, 虽然已经很习惯了这个设置.
改用我天朝的, 基于宋代就发明了的官方字体(宋体)的"新宋体".

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步