

数据库设计
1.为什么要设计数据库
良好的数据库设计:
节省数据的存储空间
能够保证数据的完整性
方便进行数据库应用系统的开发
糟糕的数据库设计:
数据冗余、存储空间浪费
内存空间浪费
数据更新和插入的异常
2.设计数据库的步骤:
- 收集信息
- 标识实体
- 表示每个实体的属性
- 标识实体之间的关系
3.绘制ER图

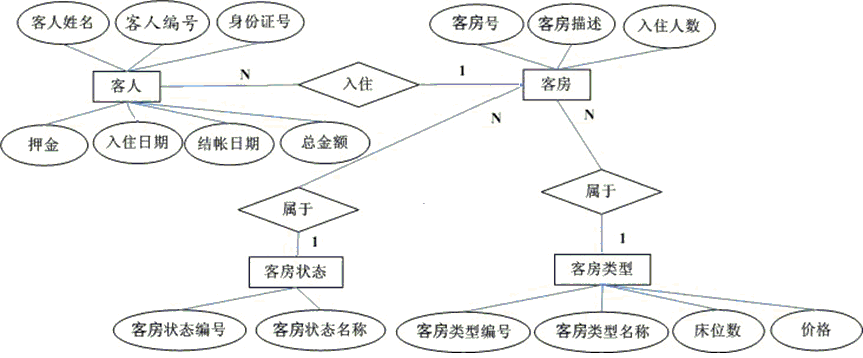
4.关系模型
用二维表的形式表示实体和实体间联系的数据模型即关系模式
E-R图转换为关系模式的步骤
1. 把每个实体都转化为关系模式R(U)形式
2. 建立实体间联系的转换
将各实体转换为对应的表,将各属性转换为各表对应的列
标识每个表的主键列
在表之间建立主外键,体现实体
5.三大范式
第一范式:确保每列的原子性(每列都是不可再分的最小数据单元)
第二范式:在第一范式实现的条件下确保每个表只描述一件事情
第三范式:要求表中各列必须和主键值之间相关不能间接相关
6.表间关系:
实体及实体之间的关系(一对一,一对多,多对一,多对多),可能是一个实体对应一个表,也可能是多个实体对应一个表
实体所包含的属性有什么
哪些属性或属性的组合可以唯一标识一个实体
7.数据库操作异常
数据操作异常:
1.插入异常,如果某实体随着另一个实体的存在而存在,即缺少某个实体时无法表示这个实体,那么这个表就存在插入异常。
2.更新异常,如果更改表所对应的某个实体实例的单独属性时,需要将多行更新,那么这个表存在更新异常。
3.删除异常,如果删除表的某一行来反映某实体实例失效时导致另一个不同实体实例信息丢失,那这个表存在删除异常。
4.数据多余,相同的数据在多个地方存在,或者表中的某个列可以由其他列计算得到,这样就是表中存在数据多余。
初始MYSQL
MySQL的优势:
运行速度快
使用成本低
可移植性强
适用用户广
命令行连接mysql:mysql -h 服务器主机地址 -u 用户名 -p 密码
创建数据库: CREATE DATABASE 数据库名;
查看数据库:SHOW databases;
选择数据库:USE 数据库名;
删除数据库:DROP DATABASE 数据库名;
数据库运行机制:
java通过JDBC接口进入数据库进行验证,验证通过后查看是否存在缓存,有缓存则返回接口,无缓存的话进行优化,简析然后在数据库中查找需要的数据返回接口,验证不通过则直接返回接口。
1.Connectors
指的是不同语言中与SQL的交互
2.Management Serveices & Utilities:
系统管理和控制工具
3.Connection Pool: 连接池
管理缓冲用户连接,线程处理等需要缓存的需求。
负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到线程管理模块。每一个连接上 MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,
接受客户端的命令请求,传递 Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的 cache 等。
4.SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
5.Parser: 解析器。
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
在 MySQL中我们习惯将所有 Client 端发送给 Server 端的命令都称为 query ,在 MySQL Server 里面,连接线程接收到客户端的一个 Query 后,会直接将该 query 传递给专门负责将各种 Query 进行分类然后转发给各个对应的处理模块。
主要功能:
a . 将SQL语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
6.Optimizer: 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。就是优化客户端请求的 query(sql语句) ,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果
他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
7.Cache和Buffer: 查询缓存。
他的主要功能是将客户端提交 给MySQL 的 Select 类 query 请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该 query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
MySQL配置:
端口号:3306
默认字符集:utf8
将bin目录写入环境变量
root密码设置
配置错误可在根目录中找到my.ini文件更改
结构化查询语言:
|
名称
|
解释
|
命令举例
|
|
DML
(数据操作语言)
|
用来操作数据库中所包含的数据
|
INSERT
UPDATE
DELETE
|
|
DDL
(数据定义语言)
|
用于创建和删除数据库对象等操作
|
CREATE
DROP
ALTER
|
|
DQL
(数据查询语言)
|
用来对数据库中的数据进行查询
|
SELECT
|
|
DCL
(数据控制语言)
|
用来控制数据库组件的存取许可、存取权限等
|
GRANT
COMMIT
ROLLBACK
|
数据类型:
|
类型
|
说明
|
存储需求
|
|
TINYINT
|
非常小的数据
|
1字节
|
|
SMALLINT
|
较小的数据
|
2字节
|
|
MEDIUMINT
|
中等大小的数据
|
3字节
|
|
INT
|
标准整数
|
4字节
|
|
BIGINT
|
较大的整数
|
8字节
|
|
FLOAT
|
单精度浮点数
|
4字节
|
|
DOUBLE
|
双精度浮点数
|
8字节
|
|
DECIMAL
|
字符串形式的浮点数
|
M+2个字节
|
UNSIGNED属性:标识为无符号数
ZEROFILL属性:宽度(位数)不足以0填充
PRIMARY KEY: 主键
COMMENT:注释
|
字符串类型
|
说明
|
长度
|
|
CHAR[(M)]
|
定长字符串
|
M字节
|
|
VARCHAR[(M)]
|
可变字符串
|
可变长度
|
|
TINYTEXT
|
微型文本串
|
0~28–1字节
|
|
TEXT
|
文本串
|
0~216–1字节
|
|
日期类型
|
格式
|
取值范围
|
|
DATE
|
YYYY-MM-DD,日期格式
|
1000-01-01~ 9999-12-31
|
|
DATETIME
|
YY-MM-DD hh:mm:ss:
|
1000-01-01 00:00:00 ~9999-12-31 23:59:59
|
|
TIME
|
hh:mm:ss:
|
-835:59:59 ~ 838:59:59
|
|
TIMESTAMP
|
YYYYMMDDHHMMSS
|
1970年某时刻~2038年某时刻,精度为1秒
|
|
YEAR
|
YYYY格式的年份
|
1901~2155
|
创建表的语法:
CREATE TABLE [IF NOT EXISTS] 表名 (
字段1 数据类型 [字段属性|约束][索引][注释],
……
字段n 数据类型 [字段属性|约束][索引][注释]
)[表类型][表字符集][注释];
字段约束:
|
名称
|
关键字
|
说明
|
|
非空约束
|
NOT NULL
|
字段不允许为空
|
|
默认约束
|
DEFAULT
|
赋予某字段默认值
|
|
唯一约束
|
UNIQUE KEY(UK)
|
设置字段的值是唯一的
允许为空,但只能有一个空值
|
|
主键约束
|
PRIMARY KEY(PK)
|
设置该字段为表的主键
可唯一标识该表记录
|
|
外键约束
|
FOREIGN KEY(FK)
|
用于在两表之间建立关系,
需要指定引用主表的哪一字段
|
|
自动增长
|
AUTO_INCREMENT
|
设置该列为自增字段
默认每条自增1
通常用于设置主键
|
MySQL存储引擎:
使用MyISAM: 不需事务,空间小,以查询访问为主
使用InnoDB: 多删除、更新操作,安全性高,事务处理及并发控制
 posted on
posted on
