zookeeper--分布式中间件
1 简介
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
- ZooKeeper包含一个简单的原语集,提供Java和C的接口。
- ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
- ZooKeeper在大数据产品中主要提供两个功能:1 帮助系统避免单点故障,建立可靠的应用程序,2 提供分布式协作服务和维护配置信息。
官网:https://zookeeper.apache.org
2 设计模式及组件架构
2.1 设计模式
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。可以简单理解为文件系统和通知机制
2.2 集群角色
ZooKeeper集群中的节点分为三种角色:Leader、Follower和server,其结构和相互关系如图所示。通常来说,需要在集群中配置奇数个(2N+1)ZooKeeper服务,至少(N+1)个投票才能成功的执行写操作。
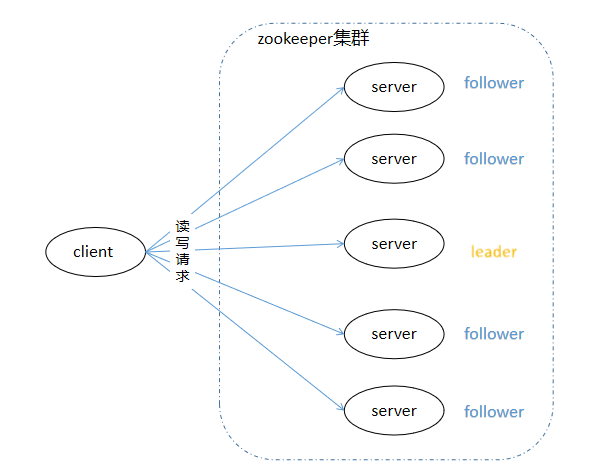
| 名称 | 描述 |
|---|---|
| Leader | Leader负责进行投票的发起和决议,更新系统状态; |
| Follower | Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票, 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。 |
| server | server不参与选举和写请求的投票,每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的 |
| Client | 客户端 |
2.3 Zookeeper集群的节点状态
Looking :选举状态。
Following :Follower 节点(从节点)所处的状态。
Leading :Leader 节点(主节点)所处状态。
3 内部原理
3.1 paxos算法基础
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos做了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos
paxos算法简介:https://www.cnblogs.com/du-z/p/17188629.html
3.2 选举机制
- 半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器,最少3台。
- 在ZooKeeper集群中只有一个节点作为集群的Leader,由各Follower通过ZooKeeper Atomic Broadcast(ZAB)协议选举产生
3.3 数据模型与数据节点znode
3.3.1 数据模型与数据节点znode介绍
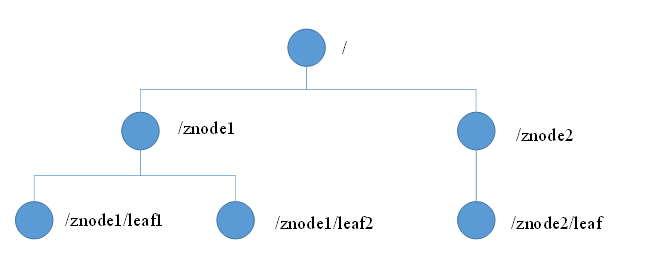
- 最上层根节点以 / 表示,每个节点可以拥有N个子节点
- 每个节点上都可以存储数据,数据类型可以是数字,字符串和二进制序列;
- 树形结构的每一个节点就是子目录项,称作znode,znode是Zookeeper中数据的最小单元(默认存储上限1M数据),并且每一个znode都有一个唯一的路径标识
- Zookeeper是用来协调服务的,而不是用来存储业务数据的;
- 节点znode有版本version, 每个节点znode中存储的数据可以有多个版本.也就是说,一个访问路径中可以存储多份数据,版本号version自动递增
- 节点znode可以被监控,监控这个目录节点中存储的数据的变化以及子节点目录的变化等,如果发生变化就可以通知设置监控的客户端
- 节点znode中每次对Zookeeper状态的改变都会产生一个zxid(Zookeeper Transaction Id),这个zxid是全局有序的,如果zxid1小于zxid2,就说明zxid1中状态的改变在zxid2中状态的改变之前发生
- 每个znode由两部分组成:1 data:节点存放的数据信息;2 stat:节点状态信息
3.3.2 数据节点znode的四种类型
| 节点类型 | 特性 |
|---|---|
| 持久节点PERSISTENT | 一旦创建节点znode, 就会一直存在.即使Zookeeper宕机也不会消失,直到将该节点znode删除; 每个持久节点PERSISTENT中既可以包含数据,也可以包含子节点 |
| 临时节点EPHEMERAL | 临时节点znode的生命周期是与客户端会话session绑定的,会话消失则节点消失(断开连接即删除). 临时节点znode只能作为子节点,不能创建子节点 |
| 持久顺序节点PERSISTENT_SEQUENTIAL | 除了具备持久节点PERSISTENT的性质之外,节点znode的名称还具有顺序性 |
| 临时顺序节点EPHEMERAL_SEQUENTIAL | 除了具备临时节点EPHEMERAL的性质之外,节点znode的名称还具有顺序性 |
3.4 stat节点状态信息
| stat值 | 说明 |
|---|---|
| cZxidcreate ZXID 数据节点创建时的事务ID |
|
| ctime | create time 数据节点的创建时间 |
| mZxid | modified ZXID 数据节点最终一次更新时的事务ID |
| mtime | modified time 数据节点最终一次更新时的时间 |
| pZxid | 数据节点的子节点列表最后一次修改时的事务ID 只有子节点列表变更时才会更新pZxid,子节点内容变更时不会更新 |
| cversion | 子节点版本号 当前数据节点的子节点每次变化时值增加1 |
| dataVersion | 数据节点内容版本号 数据节点创建时值为0,之后每次调用更新数据节点内容操作后值增加1 |
| aclVersion | 数据节点ACL版本号 表示该节点ACL信息变更次数 |
| ephemeralOwner | 创建当前临时节点的客户端会话的sessionId 如果当前节点是持久节点,那么ephemeralOwner=0 |
| dataLength | 数据节点数据内容长度 |
| numChildren | 当前数据节点子节点数量 |
3.5事件监听机制--重点
Zookeeper中一个很重要的特性,Zookeeper允许用户在指定的节点znode上注册一些Watcher, 并且在一些特定事件触发时 ,Zookeeper会将事件通知到监听的客户端中,事件监听机制是Zookeeper实现分布式协调服务的重要特性.
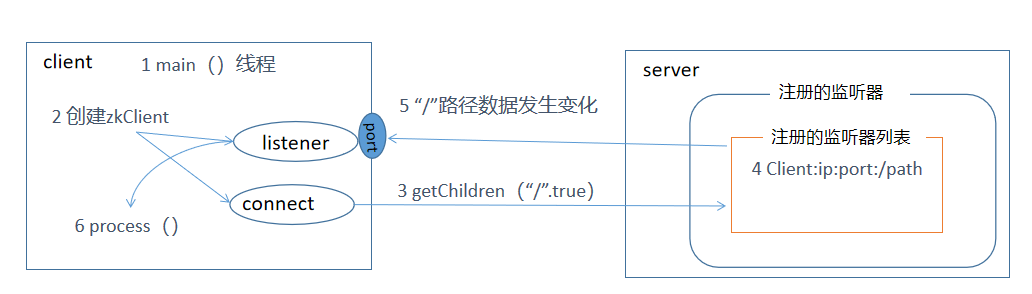
- 首先有一个main()线程
- main()线程创建zookeeper客户端,这时会创建两个线程,一个负责网络连接通信connect,一个负责监听listener
- 通过connect线程将注册的监听事件(watcher)发送给zookeeper
- 在zookeeper的注册的监听器列表中将监听事件添加到列表中
- zookeeper监听到有数据路径发生变化(触发watcher事件),就会将这个事件发送给listener线程
- listener线程就会调用内部的process()方法
常见的监听
- 监听节点数据的变化 get path [watch]
- 监听子节点增减变化 ls path [watch]

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步