会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
底部
天宝老爹
博客园
首页
新随笔
管理
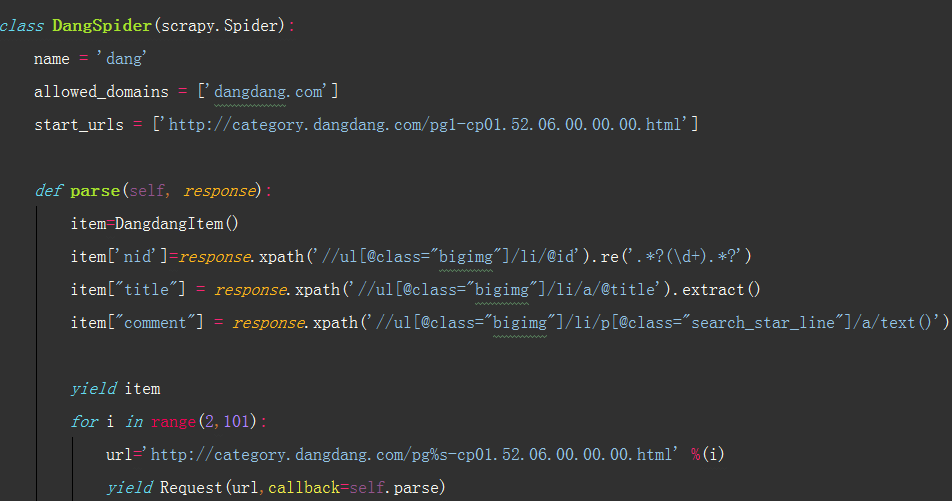
Python 爬虫 当当网图书 scrapy
目标站点需求分析
获取当当网每个图书名字和评论数
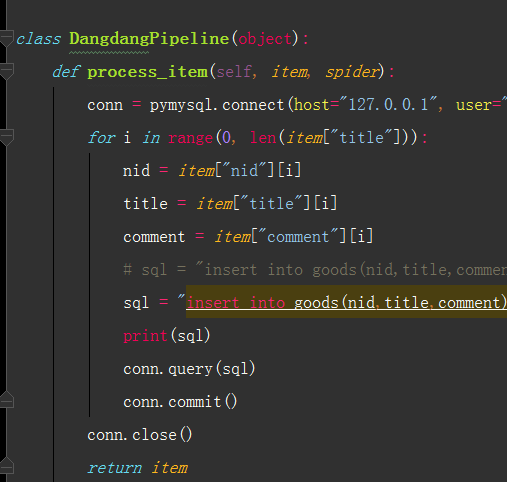
涉及的库
scrapy,mysql
获取解析单页源码
保存到数据库中
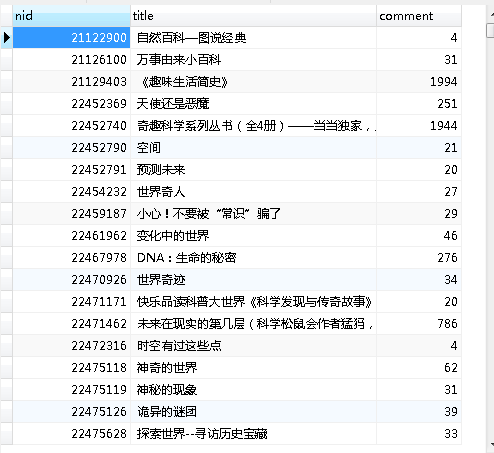
结果
posted @
2019-02-19 20:54
逐梦~前行
阅读(
485
) 评论(
0
)
收藏
举报
刷新页面
返回顶部

 浙公网安备 33010602011771号
浙公网安备 33010602011771号