《最新出炉》系列入门篇-Python+Playwright自动化测试-49-Route类拦截修改请求-下篇
1.简介
在日常工作和学习中,自动化测试的时候:在加载页面时,可能页面出现很多不是很重要或者不是我们所关注的,这个时候我们就可以选择不加载这些内容,以提高页面加载速度,节省资源。例如:可能页面上图片比较多,而我们又不关心图片内容。那么,在加载页面时,可以选择不加载图片,以提高页面加载速度。这里我们主要用到一个Route类拦截修改请求 。
2.Route类语法
Route类介绍官方API的文档地址:https://www.cuketest.com/playwright/docs/api/class-route/
在Playwright中,`Route`类用于捕获和修改请求和响应。它允许您拦截和处理特定的网络请求,以模拟不同的行为或进行自定义操作。
您可以使用`page.route()`方法创建`Route`对象,并指定要拦截的请求URL或使用正则表达式进行匹配。
一旦创建了`Route`对象,您可以通过调用`route.continue()`、`route.fulfill()`或`route.abort()`来控制请求的进一步处理。
还可以通过`route.request()`和`route.response()`属性来访问请求和响应对象。
使用`Route`类,您可以拦截和修改网络请求,从而实现各种目的,如网络请求的模拟、修改请求头、延迟响应等。它是一个非常有用的工具,可用于各种Web自动化和测试场景中。
3.Route类方法
abort()取消匹配的路由请求fulfill(response)伪造服务器返回数据,如body、headers等continue(request)伪造路由请求数据fallback(request)伪造路由请求数据,允许多次使用
3.1continue
`route.continue(): Promise<void>` - 继续请求,使其按正常流程继续发送并接收响应。
如何使用`Route`类的`continue()`方法继续请求呢?
宏哥这里以这个dog的API:https://dog.ceo/api/breeds/list/all 为例,判断开头部分URL如果相同继续请求返回数据,如果不同则不会执行继续请求的操作。首先看一下API请求后的数据,如下图所示:

3.1.1代码设计
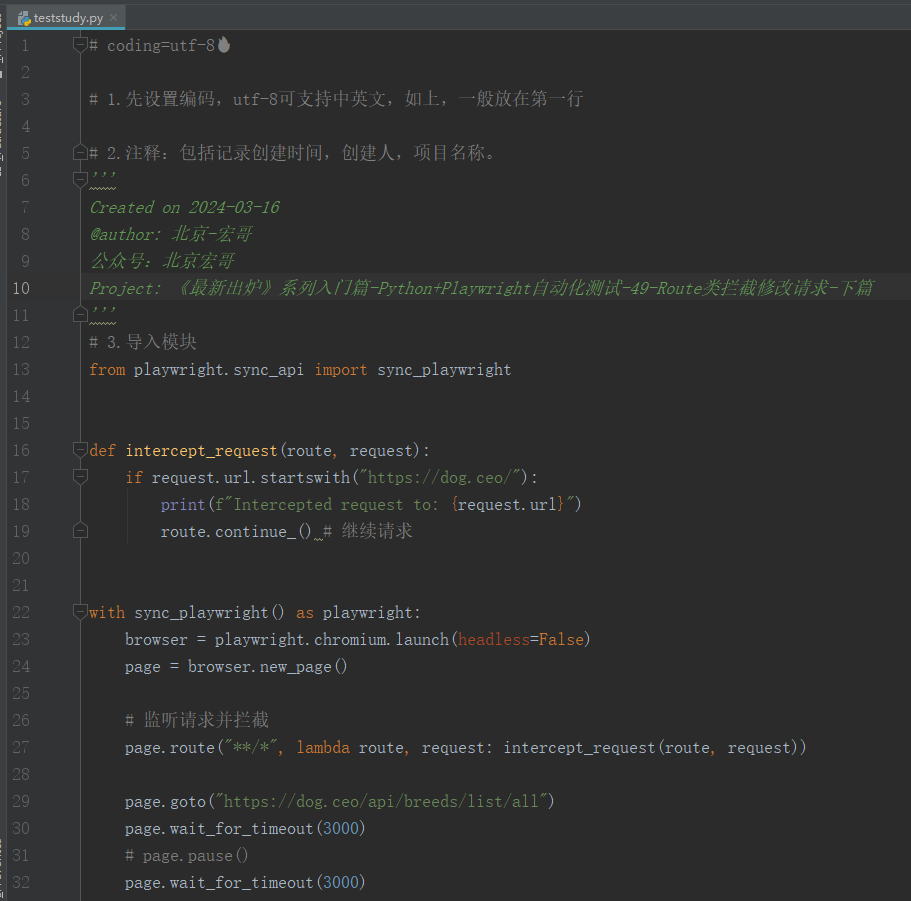
3.1.2参考代码
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2024-03-16 @author: 北京-宏哥 公众号:北京宏哥 Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-49-Route类拦截修改请求-下篇 ''' # 3.导入模块 from playwright.sync_api import sync_playwright def intercept_request(route, request): if request.url.startswith("https://dog.ceo/"): print(f"Intercepted request to: {request.url}") route.continue_() # 继续请求 with sync_playwright() as playwright: browser = playwright.chromium.launch(headless=False) page = browser.new_page() # 监听请求并拦截 page.route("**/*", lambda route, request: intercept_request(route, request)) page.goto("https://dog.ceo/api/breeds/list/all") page.wait_for_timeout(3000) # page.pause() page.wait_for_timeout(3000) print('Test Complete') # Add break point here browser.close()
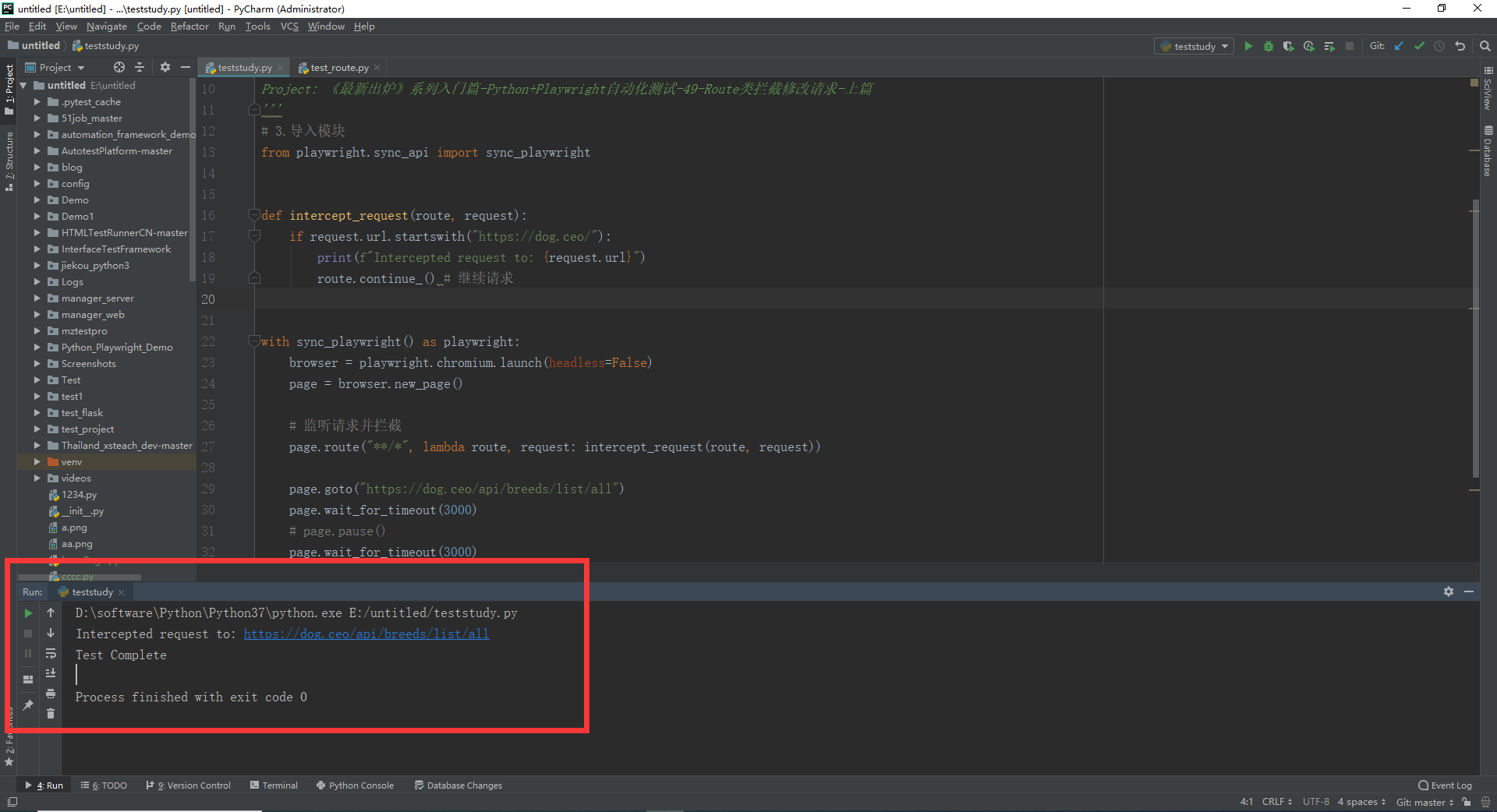
3.1.3运行代码
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作。如下图所示:
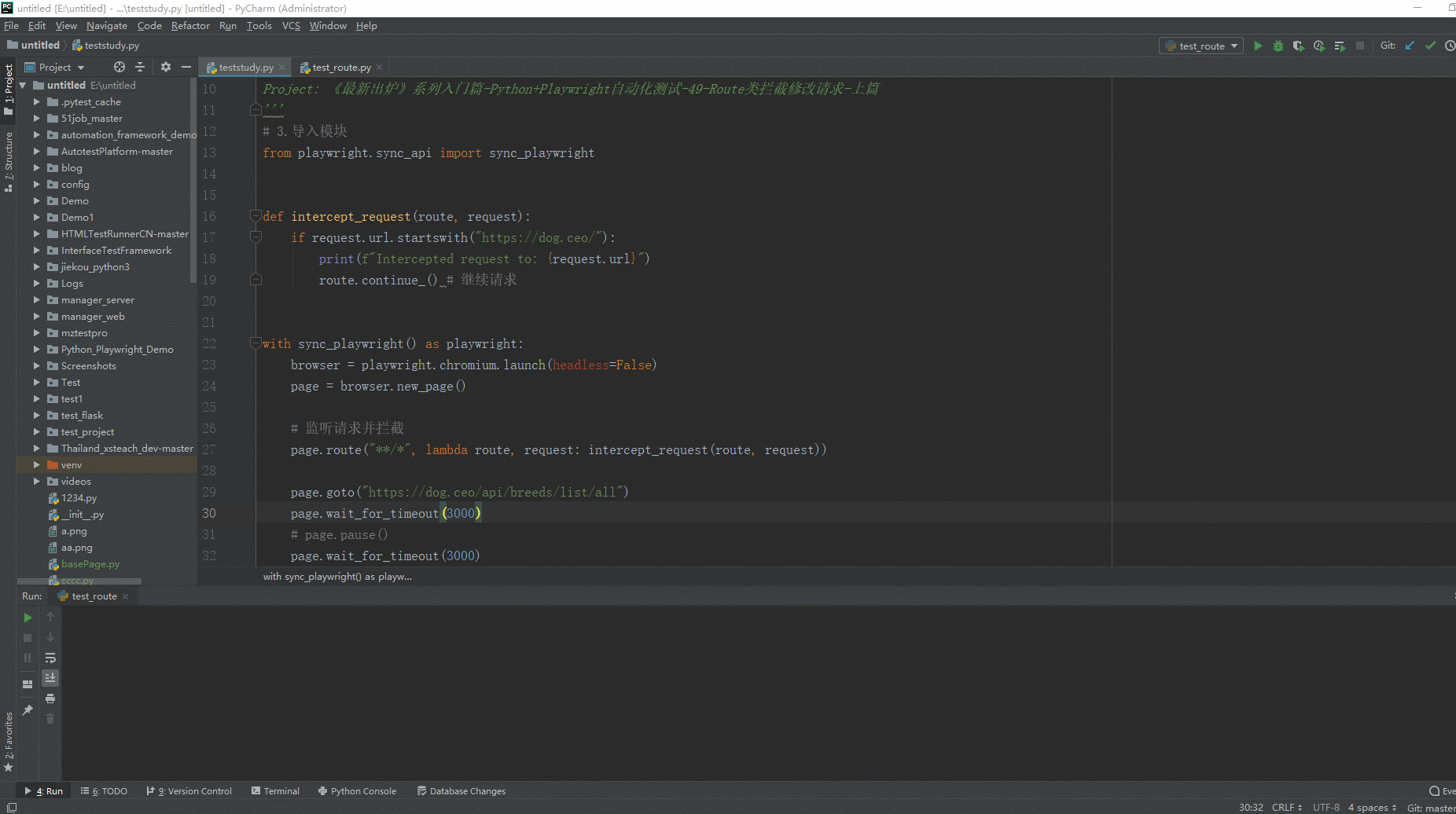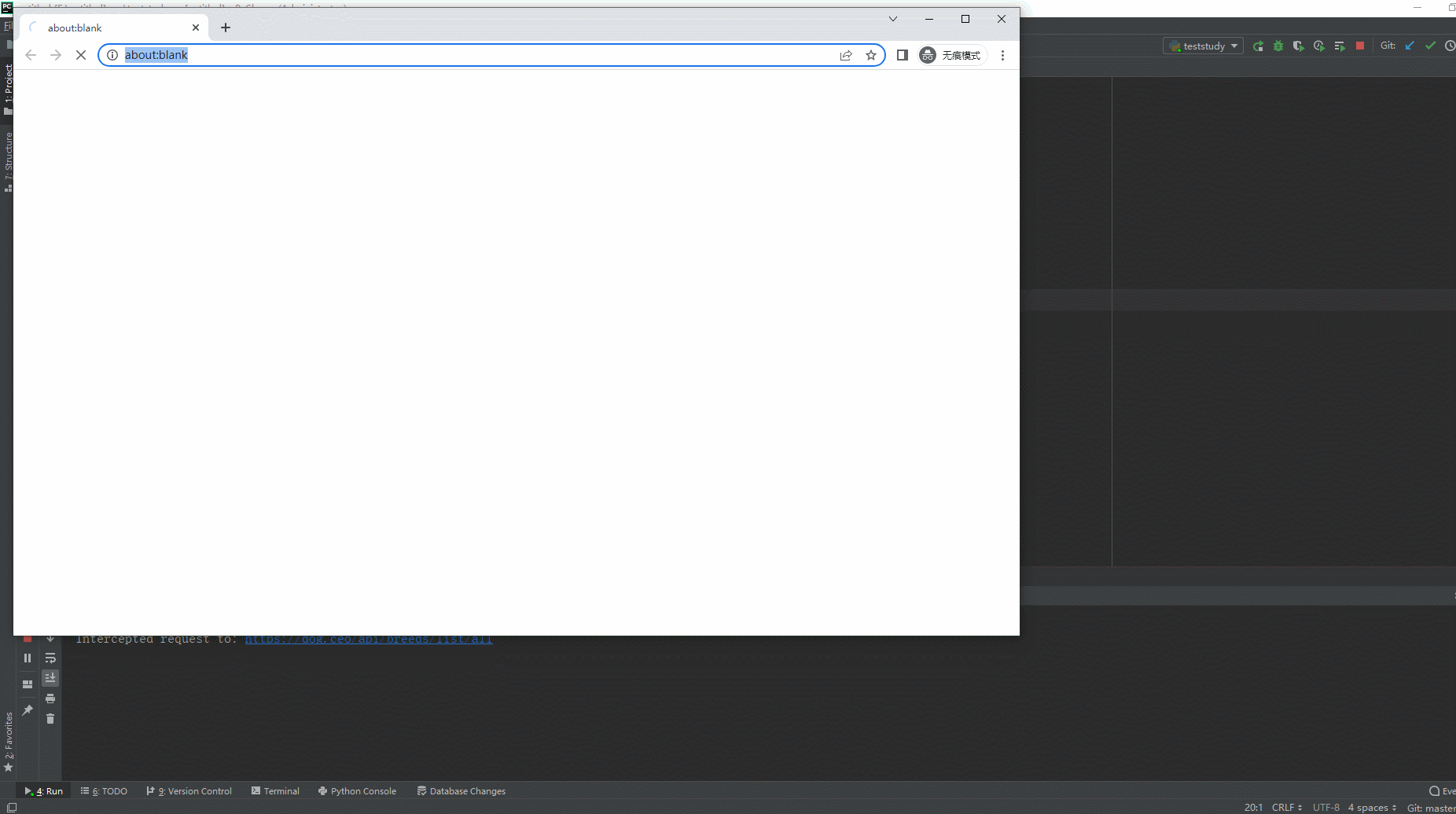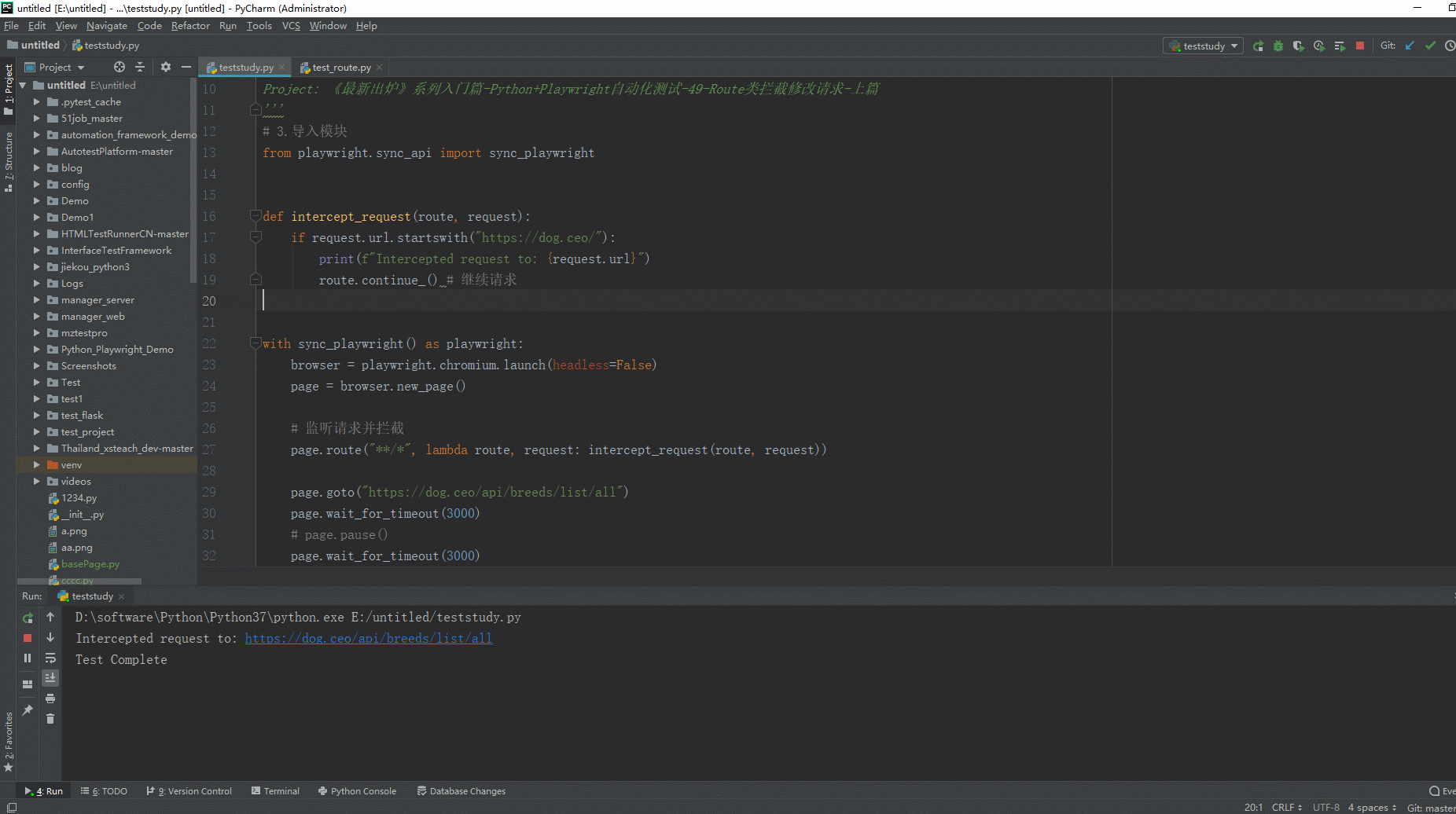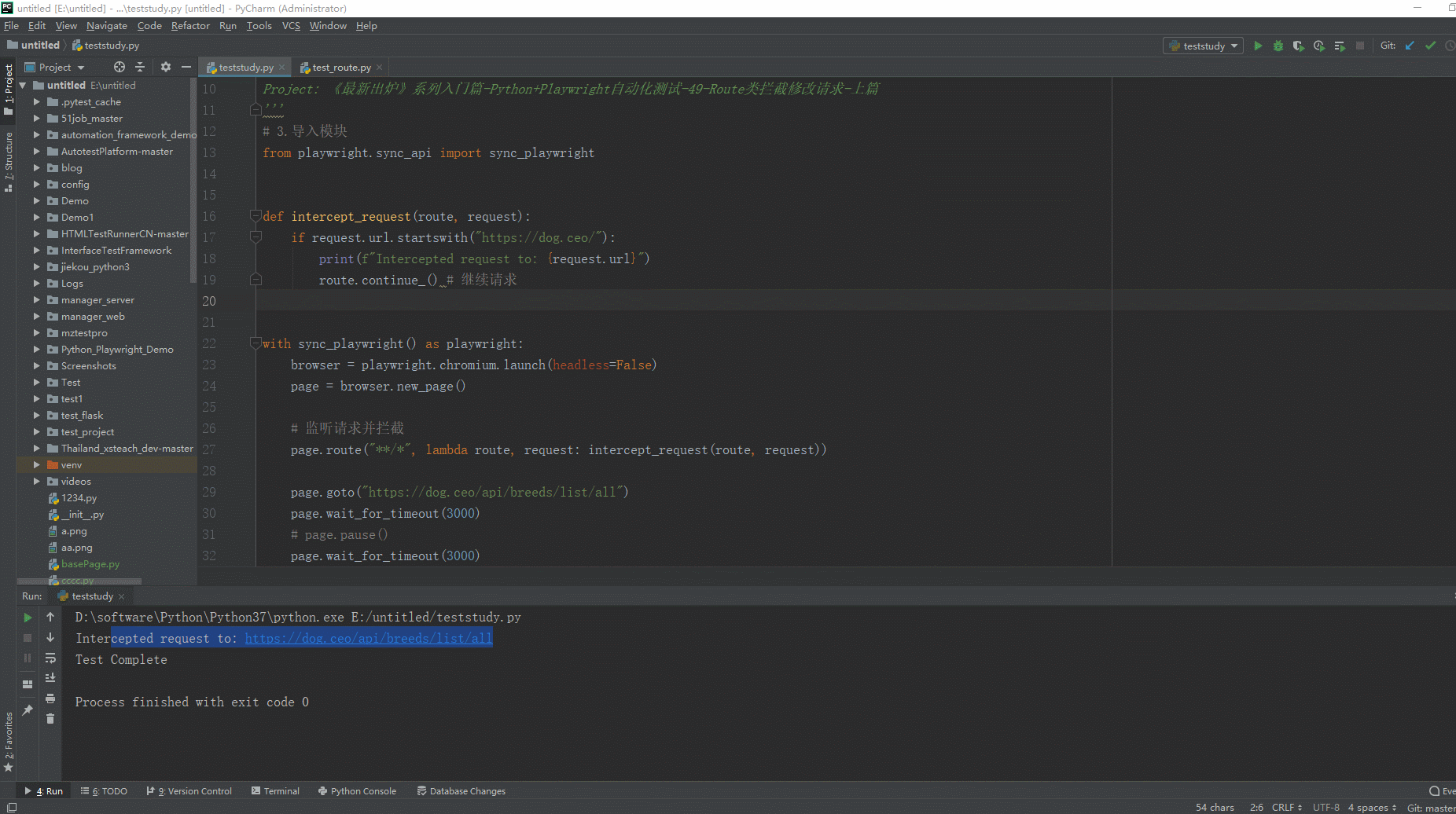
在上面的例子中,我们创建了一个简单的Playwright脚本,在页面加载后监听和拦截所有的请求。在`intercept_request`函数中,我们判断如果请求的URL以"https://dog.ceo/"开头,就打印一条信息,并调用`route.continue()`来继续请求。
当运行这个脚本时,所有的请求都会被拦截,但是只有那些URL以"https://dog.ceo/"开头的请求会被继续。
3.2fallback
Route类的fallback()方法可以用于指定当请求未匹配到任何拦截规则时的回退行为。
为了方便演示,宏哥这里仍以度娘为例,判断部分URL匹配成功,继续执行请求,反之回退。
3.2.1代码设计
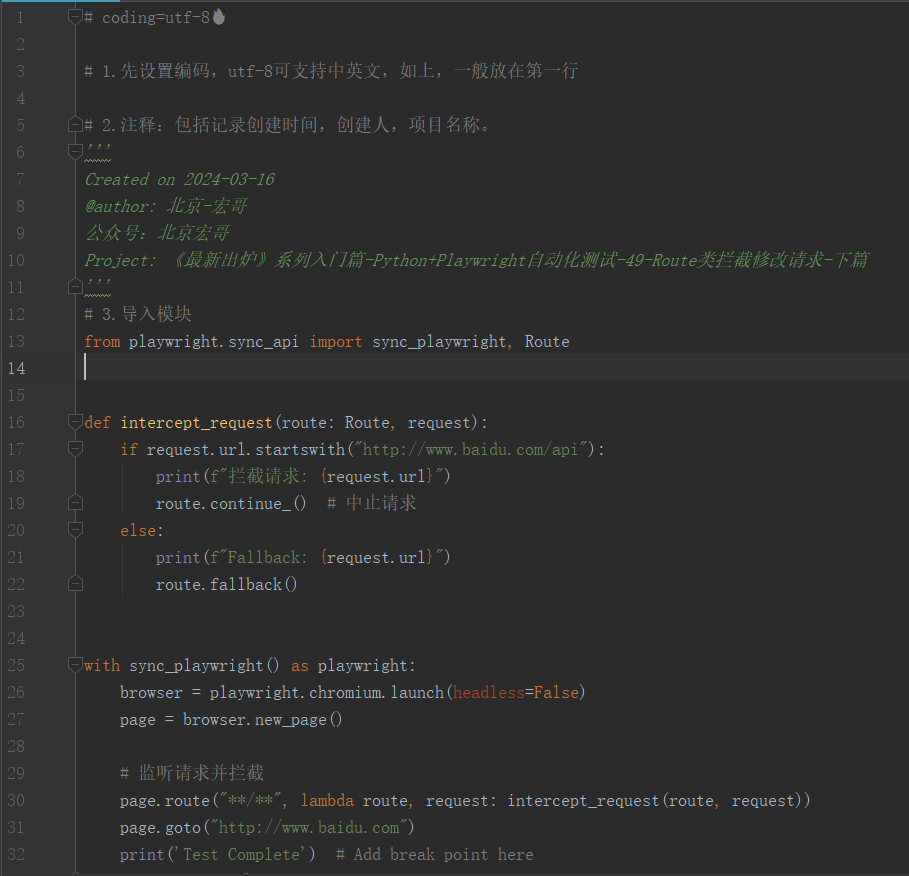
3.2.2参考代码
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2024-03-16 @author: 北京-宏哥 公众号:北京宏哥 Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-49-Route类拦截修改请求-下篇 ''' # 3.导入模块 from playwright.sync_api import sync_playwright, Route def intercept_request(route: Route, request): if request.url.startswith("http://www.baidu.com/api"): print(f"拦截请求: {request.url}") route.continue_() # 中止请求 else: print(f"Fallback: {request.url}") route.fallback() with sync_playwright() as playwright: browser = playwright.chromium.launch(headless=False) page = browser.new_page() # 监听请求并拦截 page.route("**/**", lambda route, request: intercept_request(route, request)) page.goto("http://www.baidu.com") print('Test Complete') # Add break point here browser.close()
3.2.3运行代码
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
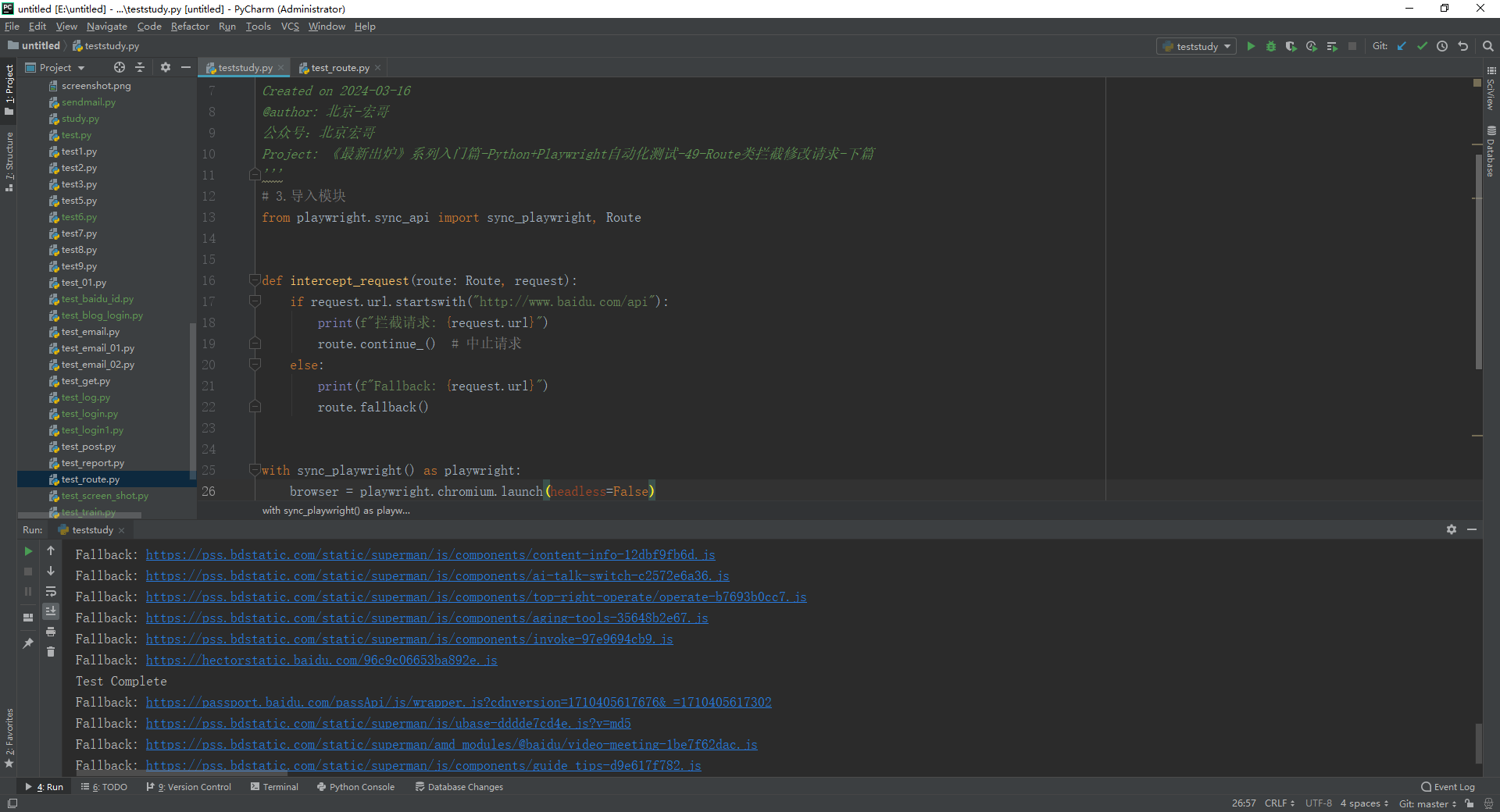
2.运行代码后电脑端的浏览器的动作。如下图所示:
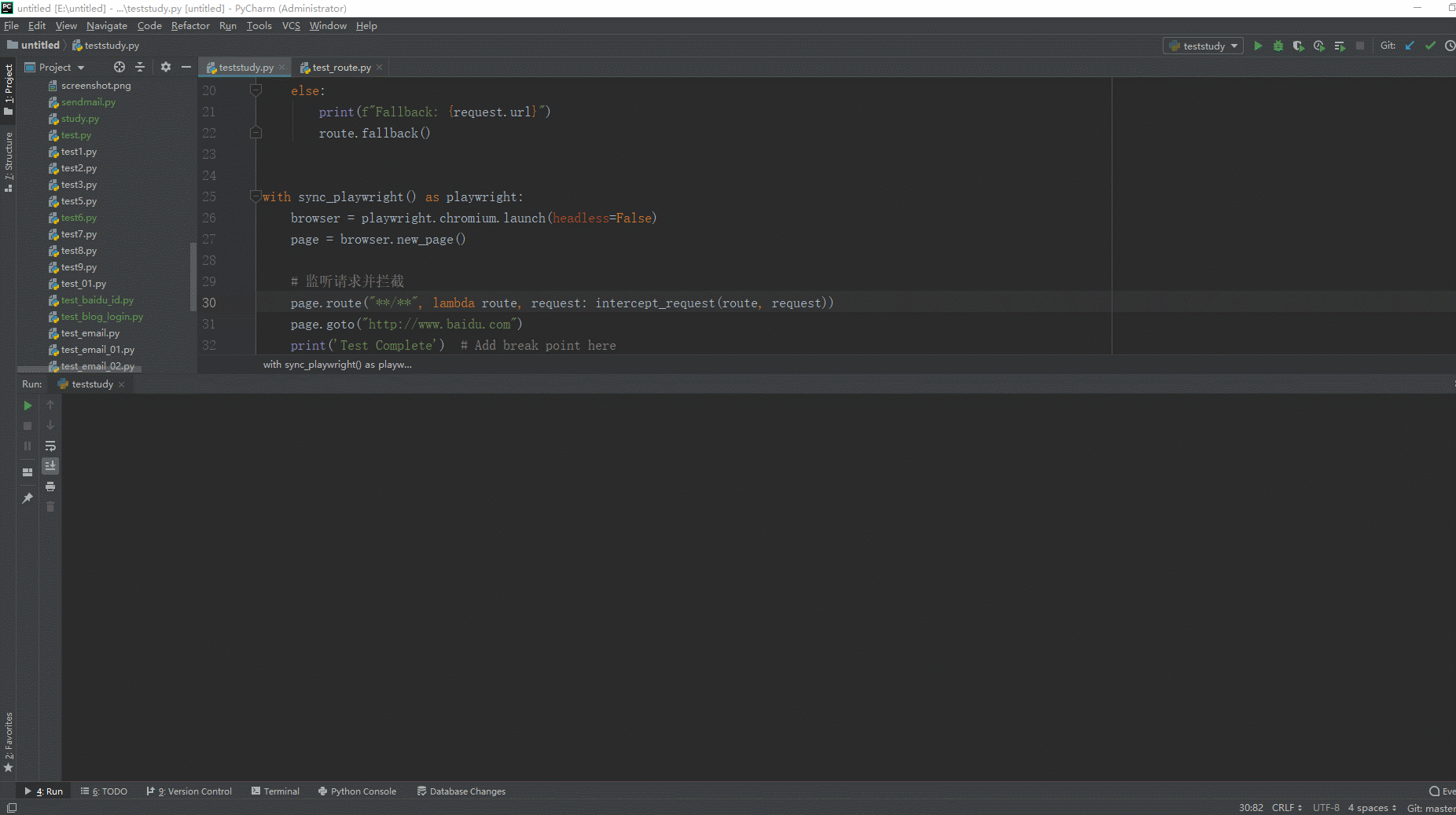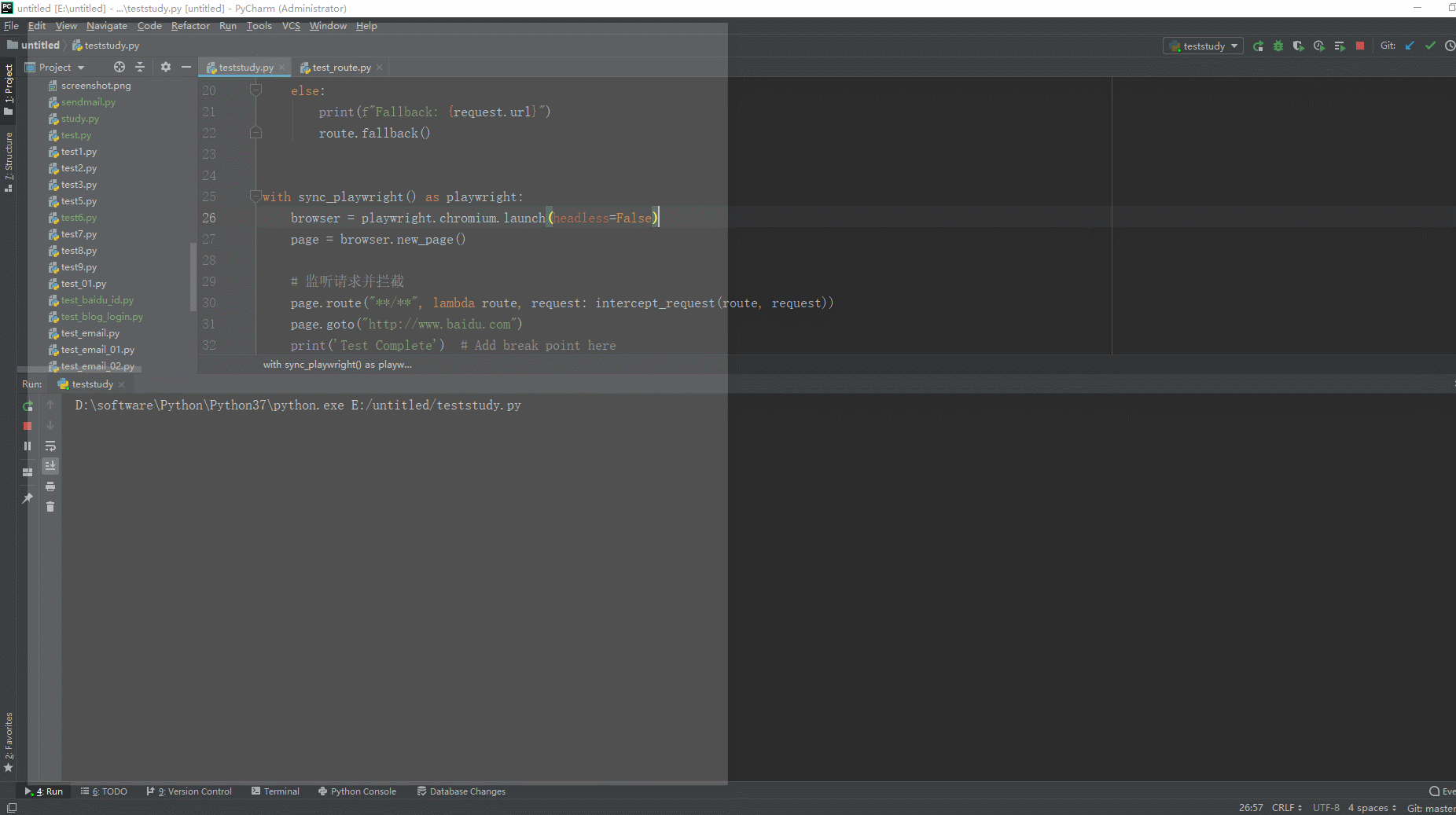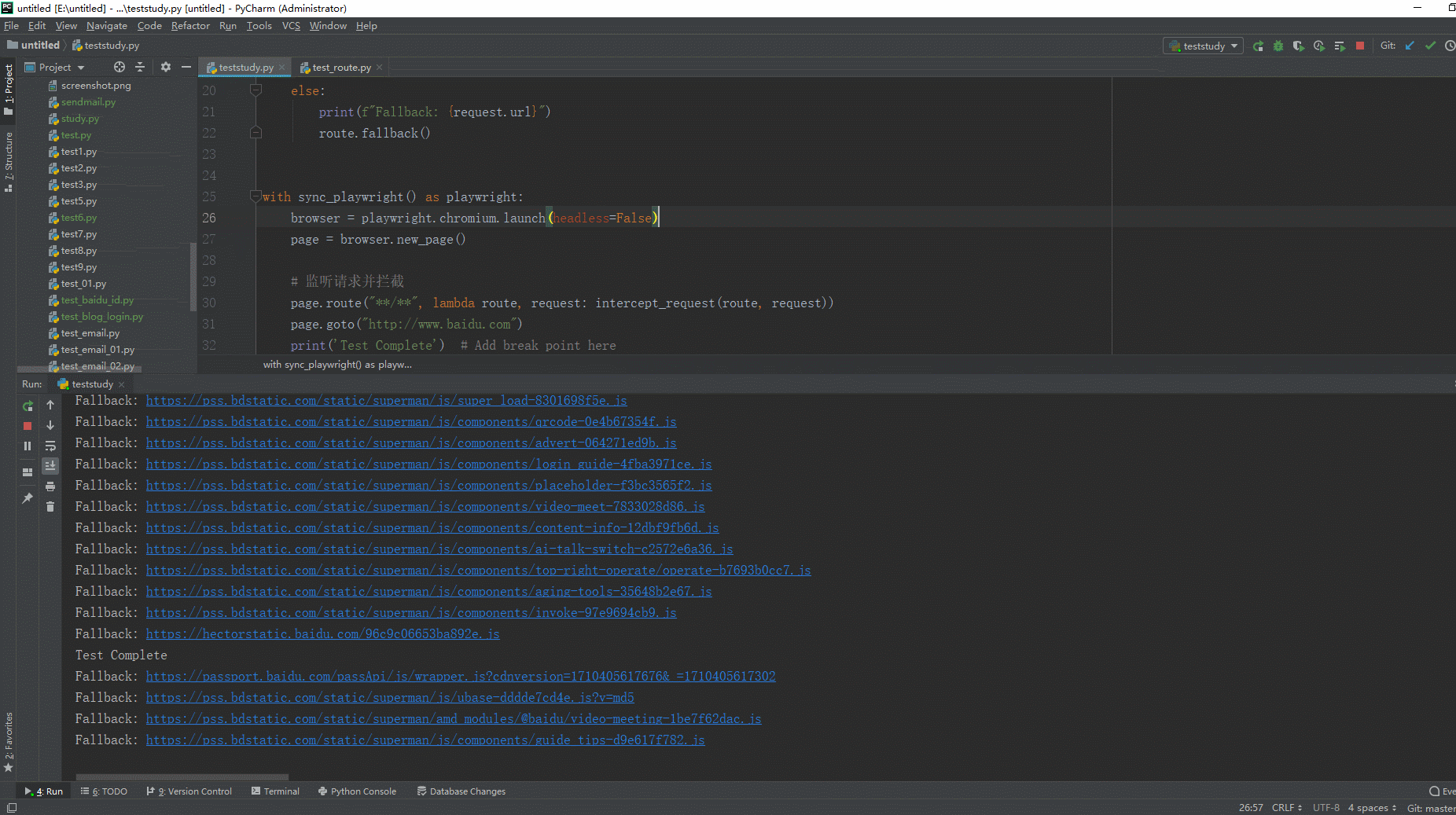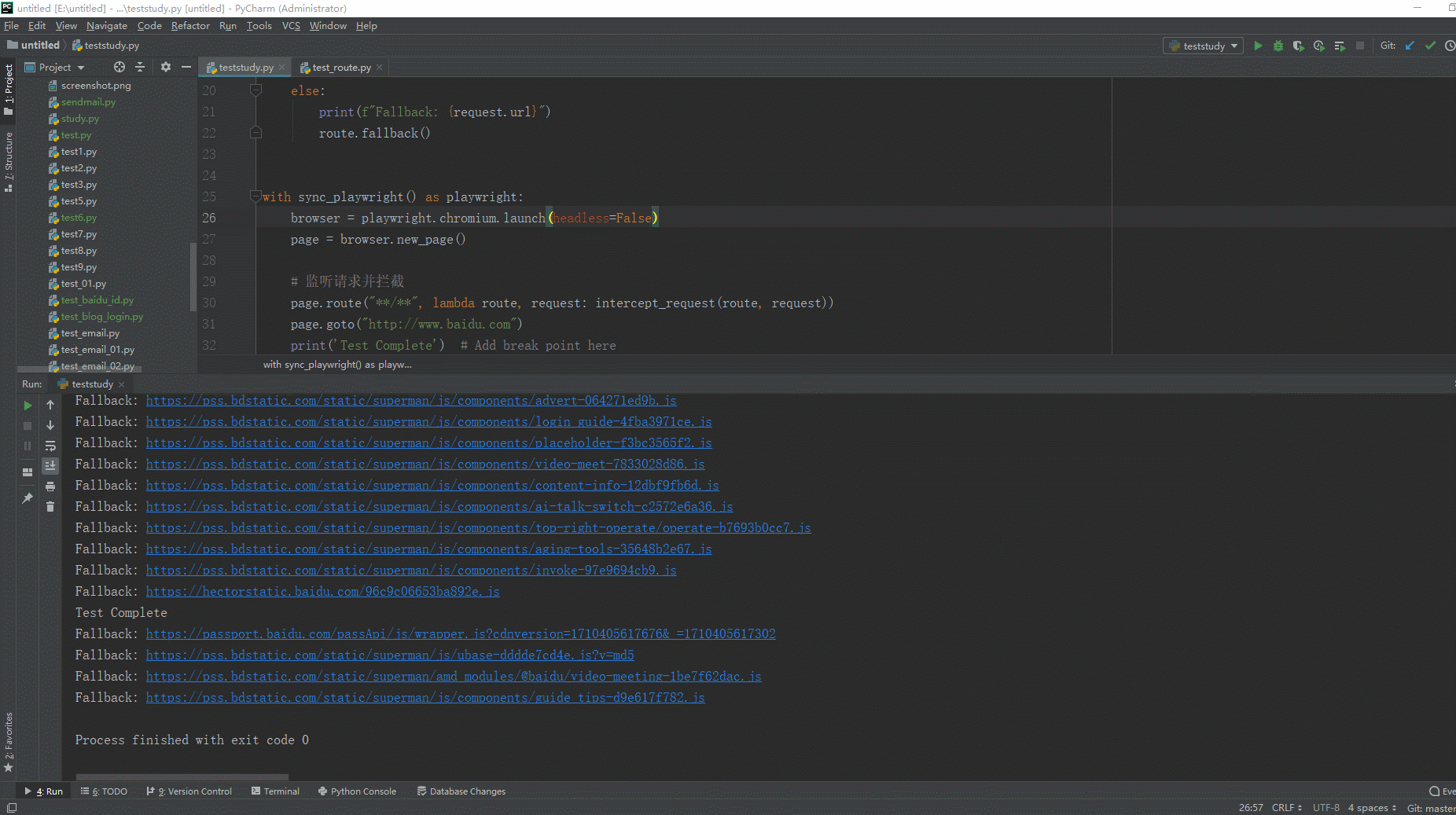
以上例子:当页面加载后会监听和拦截所有请求。在intercept_request函数中,我们根据请求的URL进行条件判断。如果URL以"https://www.baidu.com/api"开头,我们打印一条拦截消息并调用route.continue()来继续请求。否则,我们打印一条回退消息并调用route.fallback()方法,允许请求继续发送和接收响应。这里没有匹配到,触发回退行为,允许请求正常继续。
3.3属性request
最后我们来看一下其一个比较重要的属性:匹配到的request 。它可以很容易清楚地让我们看到请求的方法。用法其实很简单,和其他类的属性一样,直接使用route调用就可以。
3.3.1代码设计
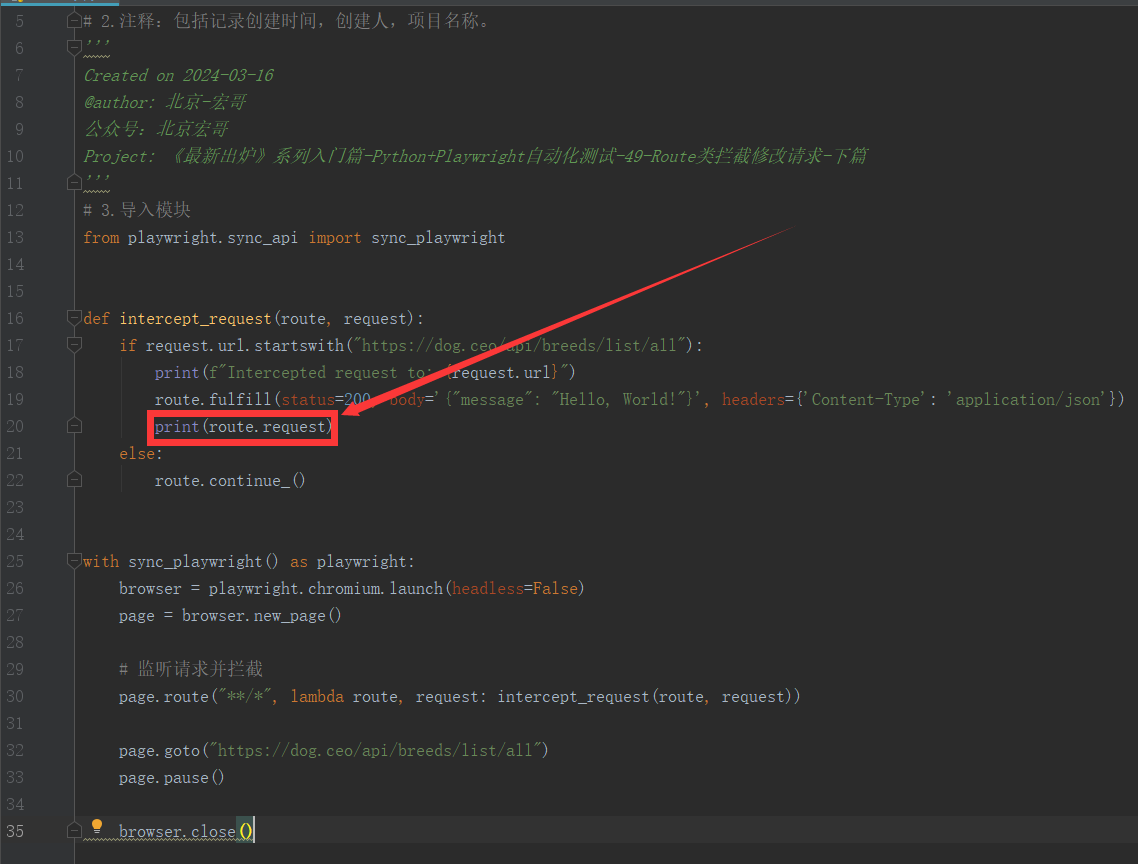
3.3.2参考代码
from playwright.sync_api import sync_playwright def intercept_request(route, request): if request.url.startswith("https://dog.ceo/api/breeds/list/all"): print(f"Intercepted request to: {request.url}") route.fulfill(status=200, body='{"message": "Hello, World!"}', headers={'Content-Type': 'application/json'}) print(route.request) else: route.continue_() with sync_playwright() as playwright: browser = playwright.chromium.launch(headless=False) page = browser.new_page() # 监听请求并拦截 page.route("**/*", lambda route, request: intercept_request(route, request)) page.goto("https://dog.ceo/api/breeds/list/all") page.pause() browser.close()
3.3.3运行代码
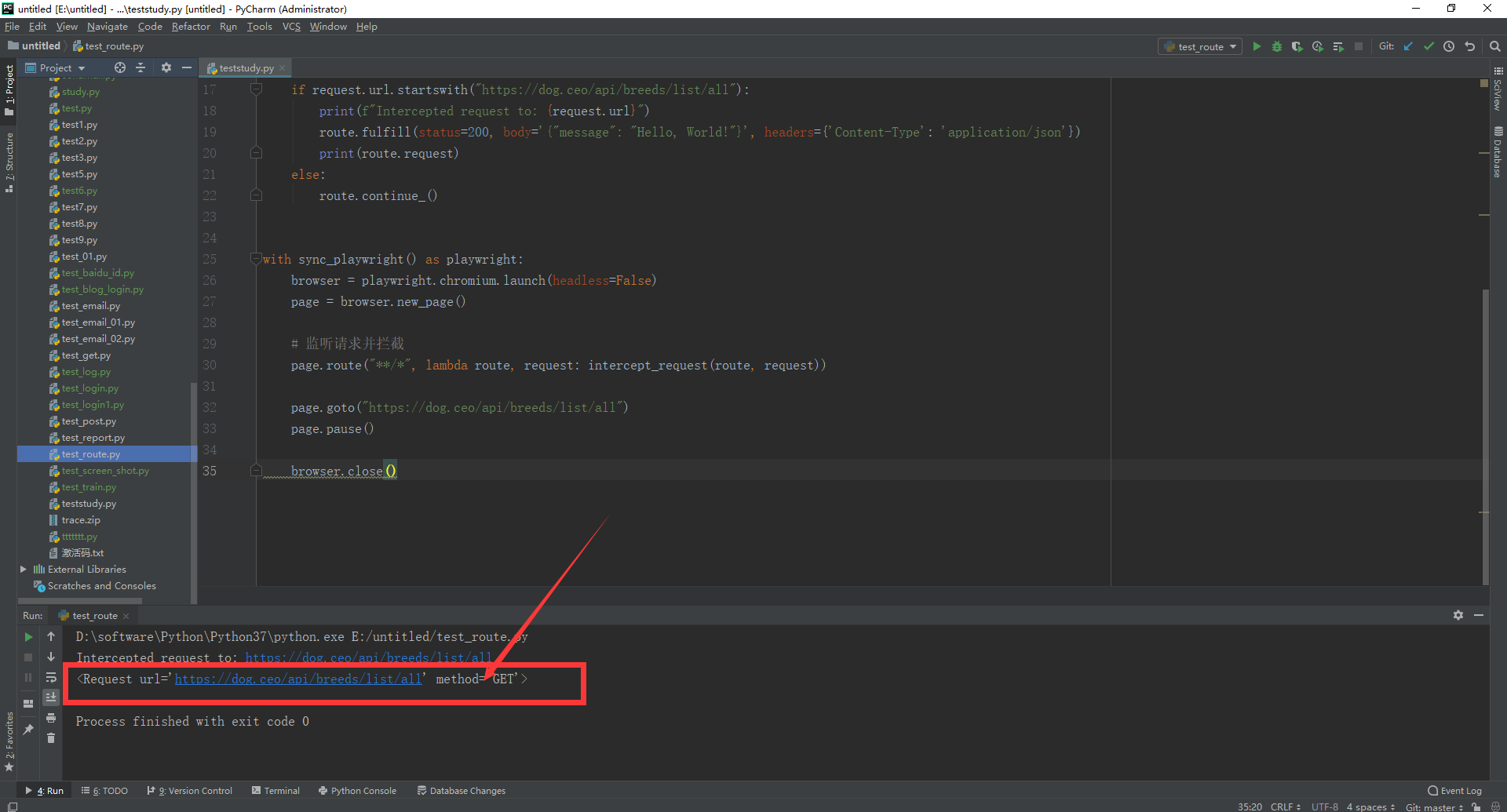
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
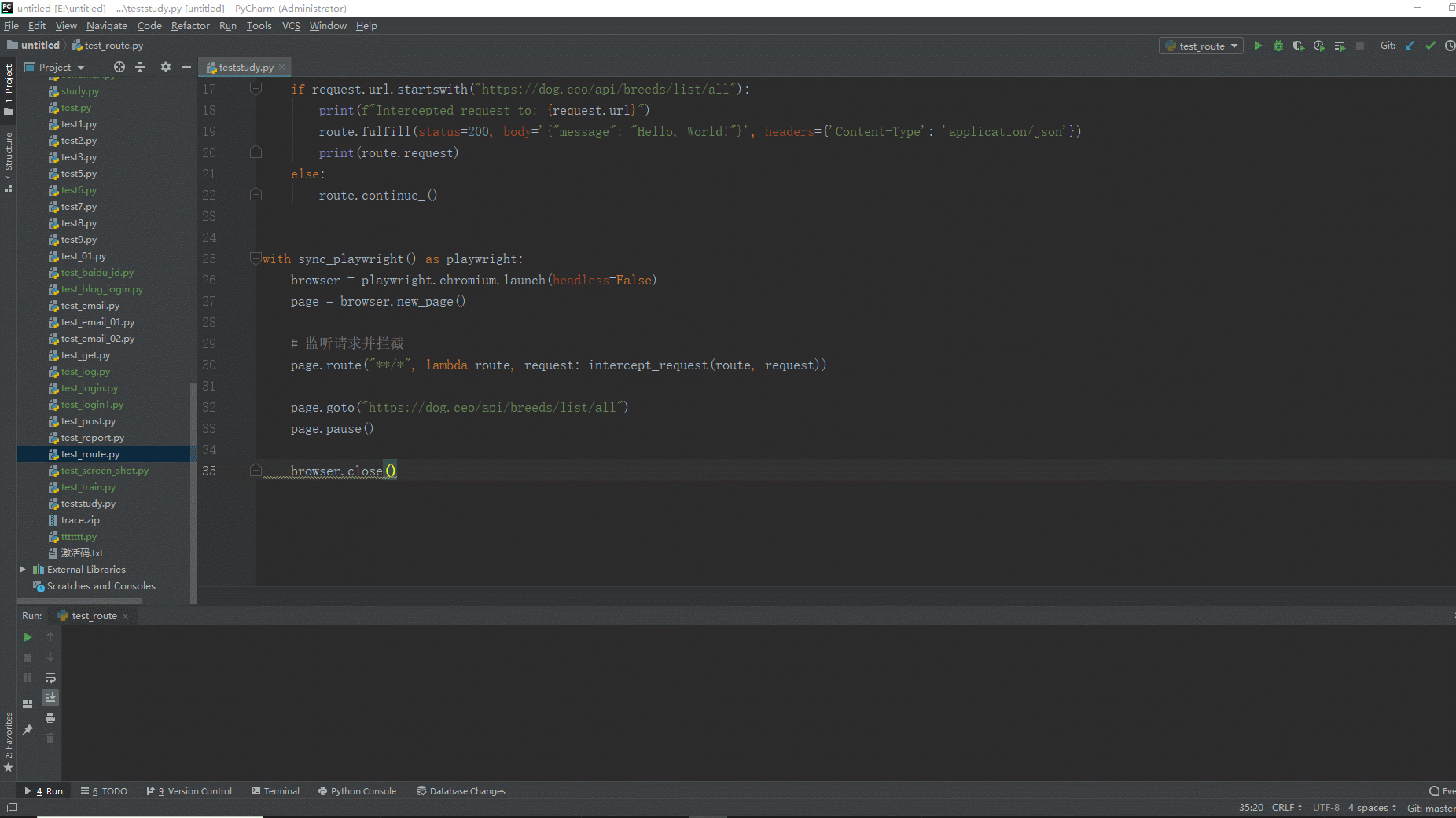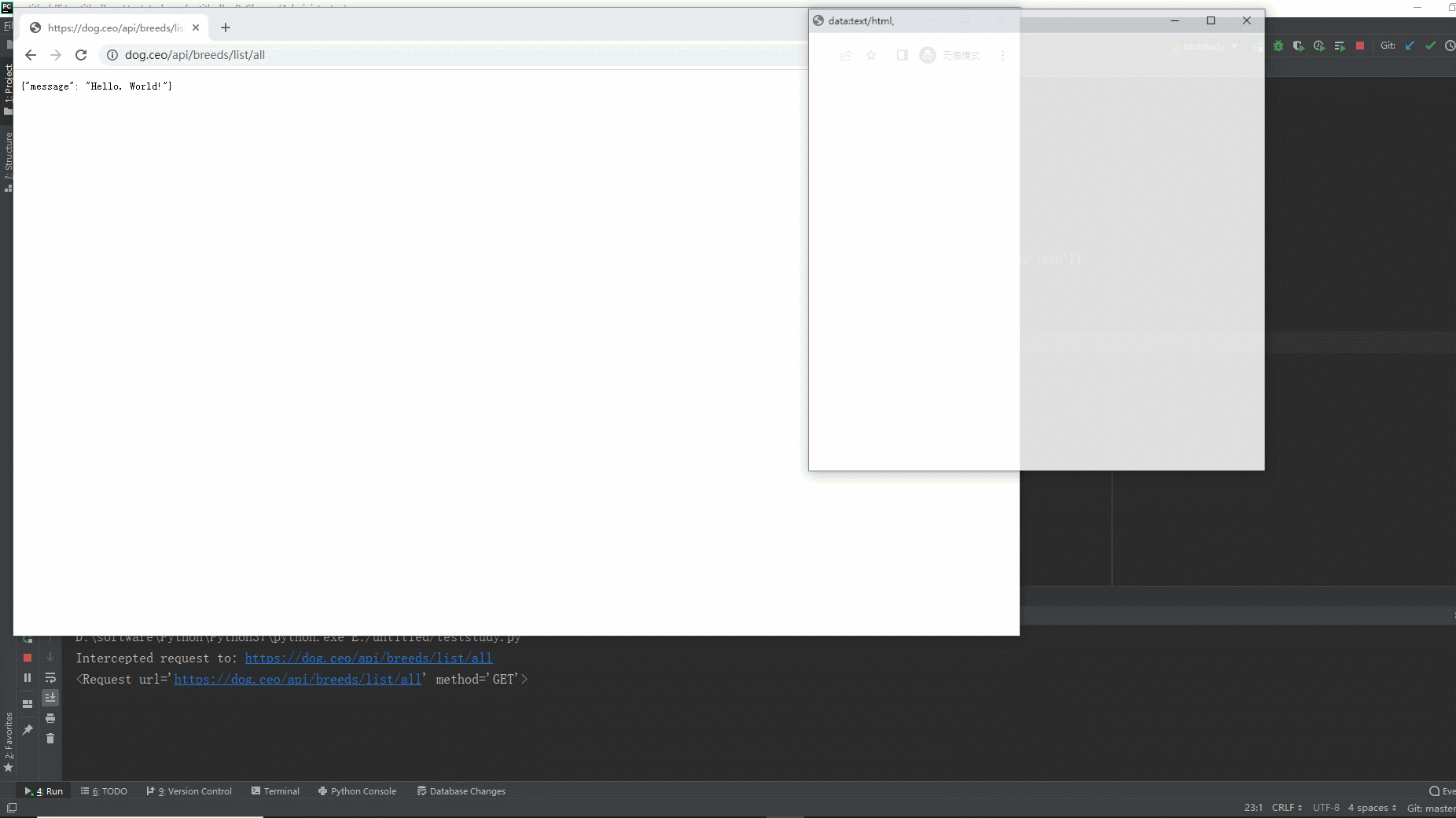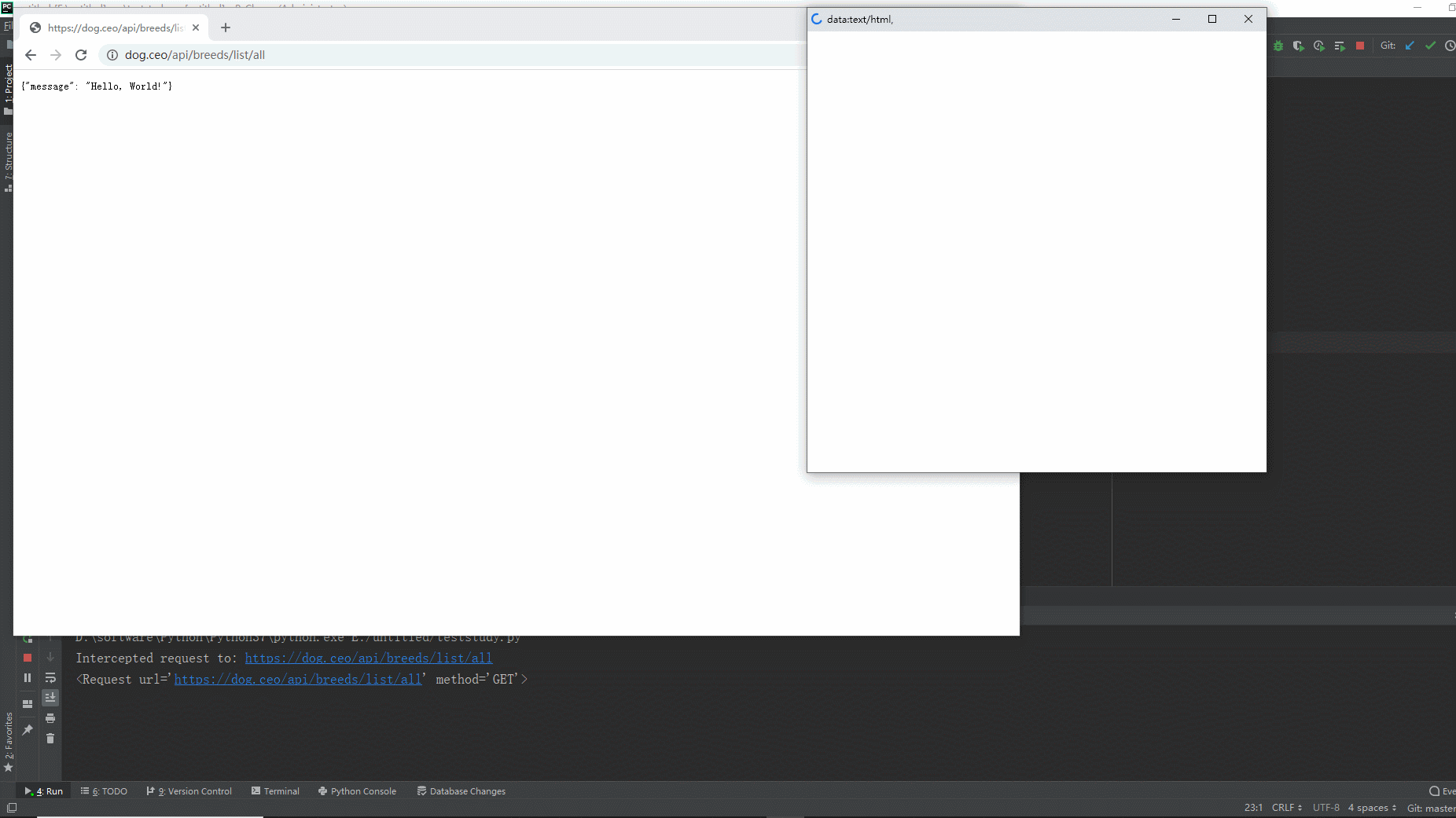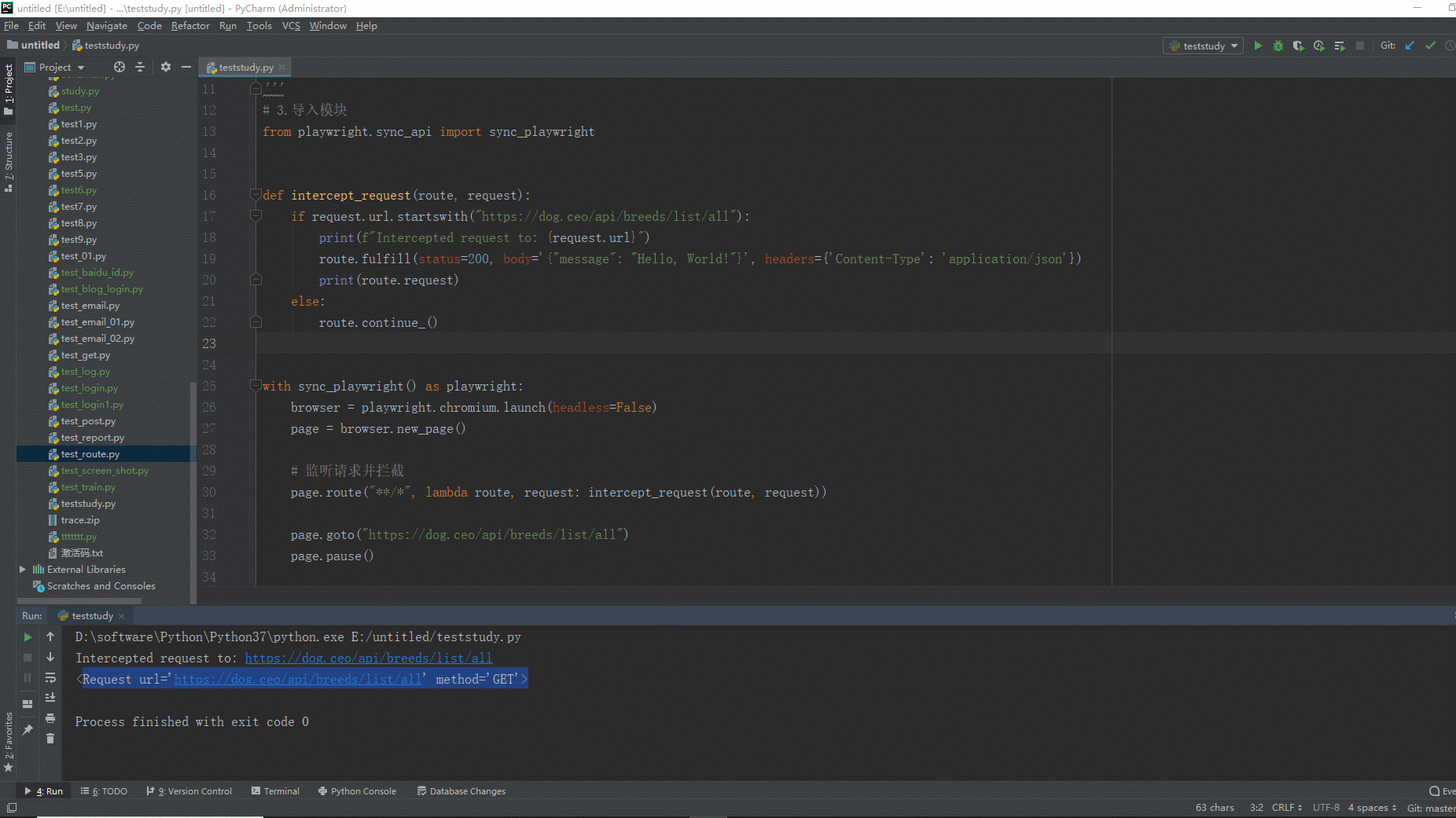
2.运行代码后电脑端的浏览器的动作。如下图所示:
4.小结
今天主要分享和介绍了使用playwright如何继续请求、请求回退的方法以及route的一个比较有用的属性,对了一定要注意continue_方法和continue方法区别,宏哥大意了,代码一直提示报错:'continue' outside loop 。好了,今天时间也不早了,宏哥就讲解和分享到这里,感谢您耐心的阅读,希望对您有所帮助。
感谢您花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让博主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下左下角“推荐”按钮,您的将是我最大的写作动力!另外您也可以选择【关注我】,可以很方便找到我!
本文版权归作者和博客园共有,来源网址:https://www.cnblogs.com/du-hong 欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利!
公众号(关注宏哥) 客服微信




