《最新出炉》系列入门篇-Python+Playwright自动化测试-40-录制生成脚本
1.简介
各种自动化框架都会有脚本录制功能, playwright这么牛叉当然也不例外。很早之前的selenium、Jmeter工具,发展到每种浏览器都有对应的录制插件。今天我们就来看下微软自动化框架playwright是如何录制脚本的。很多小伙伴或者童鞋们会觉得奇怪,怎么现在才将录制生成脚本啊,要是早点讲解和分享,我还费什么劲,揪头发写代码啊。宏哥这里说一下:这么做的目的就是为了录制生成脚本打基础的。要不然开始直接上手就录制了,就算生成脚本你也不知道什么意思,更不用说脚本中有错误需要你调试修改脚本了。playwright 可以支持自动录制生成脚本,也就是说只需要在页面上点点点,就可以自动生成对应的脚本了。
2.启动脚本自动录制
1.在CMD命令行中,使用如下命令,打开自动录制功能:
playwright codegen
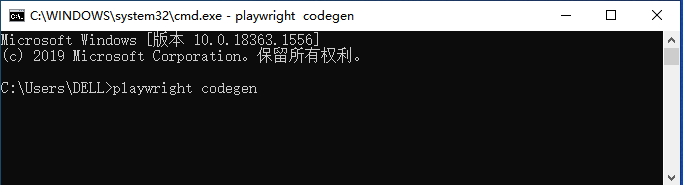
2.执行该命令后,程序会自动打开两个窗口,一个是浏览器窗口,您可以在其中与要测试的网站进行交互,另一个是 Playwright Inspector 窗口,您可以在其中记录测试、复制测试、清除测试以及更改测试语言。随着我们在浏览器窗口中进行手动操作,在Playwright Inspector界面中会自动生成手动操作对应的自动化代码。如下图所示:
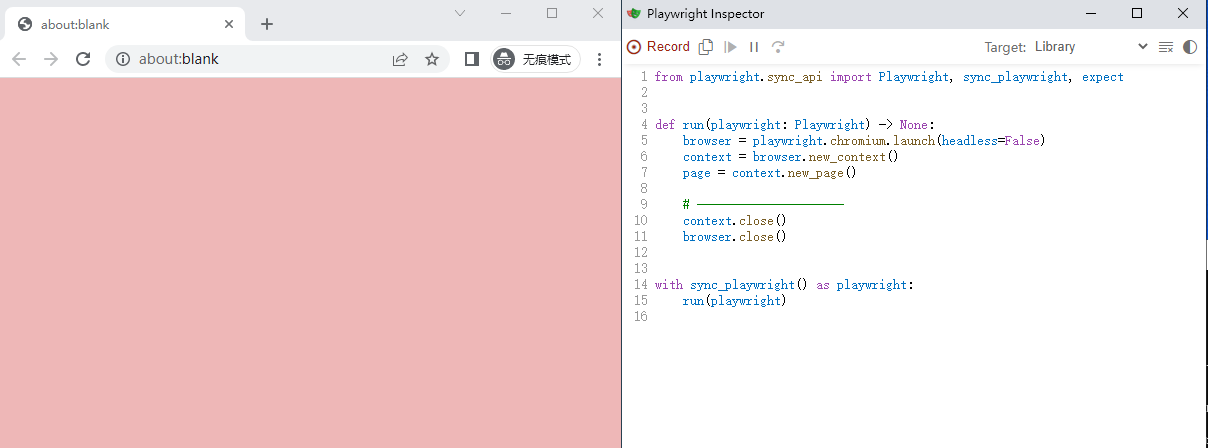
3.在Playwright Inspector界面的Target选项中,可以切换编程语言:Python、Java、Node.js、.NET C#。如下图所示:
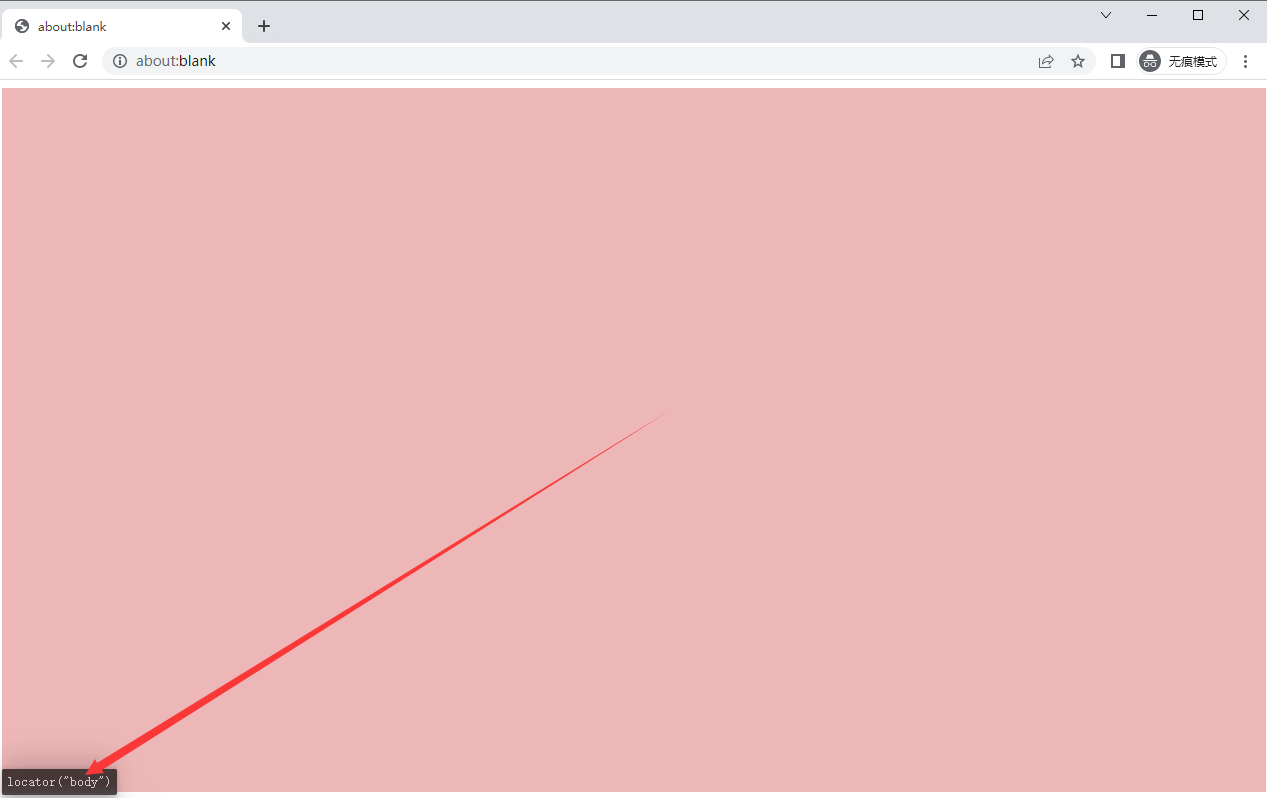
4.在浏览器界面中,当把鼠标放置在某个区域上,会自动提示出定位该位置的选择器代码,使用起来非常方便。如下图所示:
3.关闭脚本自动录制
3.1方法一
录制完成后,手动关掉浏览器即可。
3.2方法二
在CMD命令行中,使用快捷键Ctrl+C,然后输入Y,关闭自动录制功能,如下图所示:

4.自动保存录制脚本到本地文件
如果直接使用“playwright codegen”命令启动脚本录制,虽然在录制的过程中会自动生成脚本,但关掉浏览器后,生成的脚本也被自动关掉了。这样就再也找不回来了,白白辛苦半天。
如果想将生成的脚本自动保存在文件中,可以使用如下命令启动脚本录制:
playwright codegen -o 本地文件名

使用“-o”命令指定一个本地文件,在脚本录制完成后,自动生成的脚本会保存在该文件中。
5.启动浏览器时,自动打开指定页面
如果未指定访问的页面时,录制命令自动打开一个空白页面。但我们可以使用如下命令,让浏览器在启动后,自动打开一个指定页面。
playwright codegen 指定打开的网址 -o script.py
保存到本地的文件:

6.项目实战
6.1同步生成脚本
宏哥这里以百度搜索“北京-宏哥”为例。一个完整的搜索流程代码生成如下:
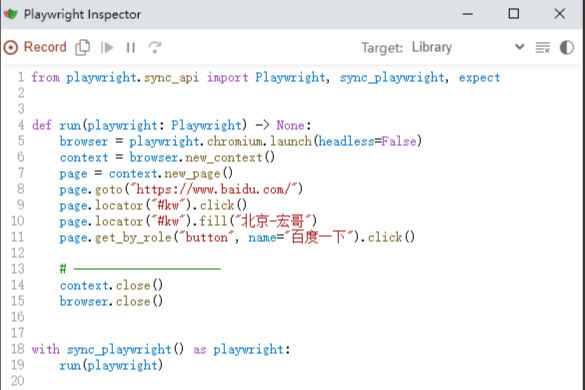
参开代码:
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False) context = browser.new_context() page = context.new_page() page.goto("https://www.baidu.com/") page.locator("#kw").click() page.locator("#kw").fill("北京-宏哥") page.get_by_role("button", name="百度一下").click() # --------------------- context.close() browser.close() with sync_playwright() as playwright: run(playwright)
6.2异步生成脚本
1.启动自动录制脚本。
2.在Target切换到异步,如下图所示:
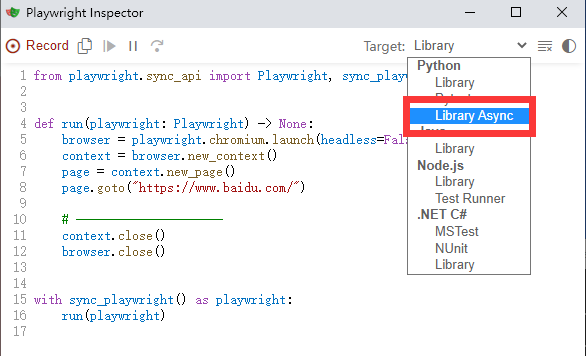
3.开始录制:一个完整的搜索流程代码生成如下:
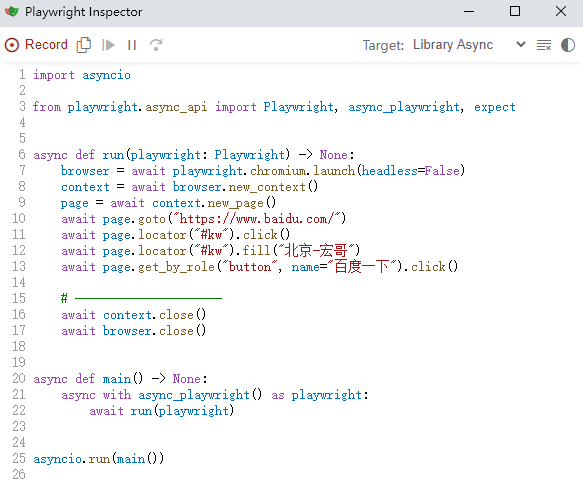
参开代码:
import asyncio from playwright.async_api import Playwright, async_playwright, expect async def run(playwright: Playwright) -> None: browser = await playwright.chromium.launch(headless=False) context = await browser.new_context() page = await context.new_page() await page.goto("https://www.baidu.com/") await page.locator("#kw").click() await page.locator("#kw").fill("北京-宏哥") await page.get_by_role("button", name="百度一下").click() # --------------------- await context.close() await browser.close() async def main() -> None: async with async_playwright() as playwright: await run(playwright) asyncio.run(main())
6.3pytest框架生成脚本
如果你是写自动化测试用例,还能自动生成 pytest 框架的代码,太牛叉了。。。
1.启动自动录制脚本。
2.在Target切换到Pytest,如下图所示:
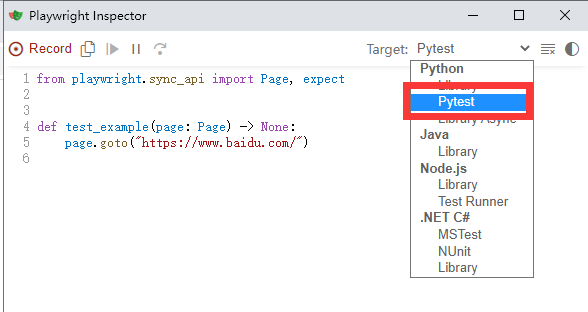
3.开始录制:一个完整的搜索流程代码生成如下:
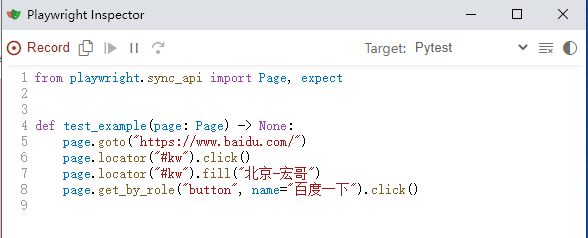
参开代码:
from playwright.sync_api import Page, expect def test_example(page: Page) -> None: page.goto("https://www.baidu.com/") page.locator("#kw").click() page.locator("#kw").fill("北京-宏哥") page.get_by_role("button", name="百度一下").click()
7.扩展
7.1录制相关命令操作
playwright还有很多录制的命令操作,有兴趣的可以自己试一下。相关命令参数如下:
1.codegen在浏览器中运行并执行操作
playwright codegen playwright.dev
2.Playwright 打开一个浏览器窗口,其视口设置为特定的宽度和高度,并且没有响应,因为需要在相同条件下运行测试。
使用该--viewport选项生成具有不同视口大小的测试。
playwright codegen --viewport-size=800,600 playwright.dev
3.--device 使用设置视口大小和用户代理等选项模拟移动设备时记录脚本和测试。
模拟移动设备iPhone11,注意:device的值必须用双引号,并且区分大小写
playwright codegen --device="iPhone 11" playwright.dev
4.模拟配色
playwright codegen --color-scheme=dark playwright.dev
5.模拟地理位置、语言和时区
playwright codegen --timezone="Europe/Rome" --geolocation="41.890221,12.492348" --lang="it-IT" maps.google.com
6.保留经过身份验证的状态
运行codegen以在会话结束时--save-storage保存cookie和localStorage 。这对于单独记录身份验证步骤并在稍后的测试中重用它很有用。
执行身份验证并关闭浏览器后,auth.json将包含存储状态。
playwright codegen --save-storage=auth.json
运行--load-storage以消耗先前加载的存储。这样,所有的cookie和localStorage都将被恢复,使大多数网络应用程序进入身份验证状态。
playwright open --load-storage=auth.json my.web.app playwright codegen --load-storage=auth.json my.web.app # Perform actions in authenticated state.
7.2page.pause() 断点调试
如果您想在某些非标准设置中使用 codegen(例如,使用browser_context.route()),可以调用page.pause(),这将打开一个带有 codegen 控件的单独窗口。这个相比大家在宏哥之前注释的代码里看到过,主要是用来调试代码的。
from playwright.sync_api import sync_playwright with sync_playwright() as p: # Make sure to run headed. browser = p.chromium.launch(headless=False) # Setup context however you like. context = browser.new_context() # Pass any options context.route('**/*', lambda route: route.continue_()) # Pause the page, and start recording manually. page = context.new_page() page.pause()
8.小结
今天这一篇主要讲解和分享了录制的启动、关闭和完整录制流程以及其他命令的录制。 好了,时间不早了,关于playwright的录制先介绍讲解到这里,感谢您耐心的阅读!!!
感谢您花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让博主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下左下角 “推荐” 按钮,您的 将是我最大的写作动力!另外您也可以选择 【 关注我 】 ,可以很方便找到我!
本文版权归作者和博客园共有,来源网址: https://www.cnblogs.com/du-hong 欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利!
公众号(关注宏哥) 微信群(扫码进群) 客服微信




 浙公网安备 33010602011771号
浙公网安备 33010602011771号