《一头扎进》系列之Python+Selenium框架设计篇2- 价值好几K的框架,不看白不看,看了还想看
1. 简介
上一篇介绍了自动化框架的架构,今天宏哥就带领小伙伴或者童鞋们开始开工往这个框架里开始添砖加瓦。主要是介绍一个框架unittest单元测试框架和一种设计思想POM。
2. unittest单元测试框架
前面文章已经简单介绍了一些关于自动化测试框架的介绍,知道了什么是自动化测试框架,主要有哪些特点,基本组成部分等。在继续介绍框架设计之前,我们先来学习一个工具,叫unittest。
unittest是一个单元测试框架,是Python编程的单元测试框架。有时候,也做叫做“PyUnit”,是Junit的Python语言版本。这里了解下,Junit是Java语言的单元测试框架,Java还有一个很好用的单元测试框架叫TestNG,本系列只学习Python,所以只需要unittest是
Python里的一个单元测试框架就可以了。
unittest支持测试自动化,共享测试用例中的初始化和关闭退出代码,在unittest中最小单元是test,也就是一个测试用例。要了解unittest单元测试框架,先来了解以下几个重要的概念。
2.1 测试固件(test fixture)
一个测试固件包括两部分,执行测试代码之前的准备部分和测试结束之后的清扫代码。这两部分一般用函数setUp()和tearDown()表示。这里举例以下,例如要测试百度搜索selenium这个场景,我们的测试固件可以这样写,setUp()里写打开浏览器,浏览器最大
化,和打开百度首页等脚本代码;在tearDown()里写结束搜索后,退出并关闭浏览器的代码。
2.2 测试用例(test case)
unittest中管理的最小单元是测试用例,一个测试用例,包括测试固件,和具体测试业务的函数或者方法。一个测试用例中,测试固件可以不写,但是至少有一个已test开头的函数。unittest会自动化识别test开头的函数是测试代码,如果你写的函数不是test开头,
unittest是不会执行这个函数里面的脚本的,这个千万要记住,所有的测试函数都要test开头,记住是小写的哦。
2.3 测试套件 (test suite)
很简单,就是很多测试用例的集合,叫测试套件,一个测试套件可以随意管理多个测试用例。如果测试用例比作单个学生,测试套件就是好像是班级的概念。
2.4 测试执行器 (test runner)
test runner是一个用来执行加载测试用例,并执行用例,且提供测试输出的一个组建。test runner可以加载test case或者test suite进行执行测试任务。
我们举例来,练习一下test fixture和test case的使用,学习unittest的简单用法:
2.5 设计思路
1. 新建一个testbaidu.py的文件
2. 导入unittest模块
3. 当前测试类继承unittest.TestCase,相当于当前利用unittest创建了一个test case,这个test case是能够被unittest直接识别。
4. 写setUP(),主要是打开浏览器和打开站点
5. 写一个test_search()用例写搜索的代码
6. 写tearDown(),主要是浏览器退出操作
相关脚本代码如下:
2.5.1 代码实现:
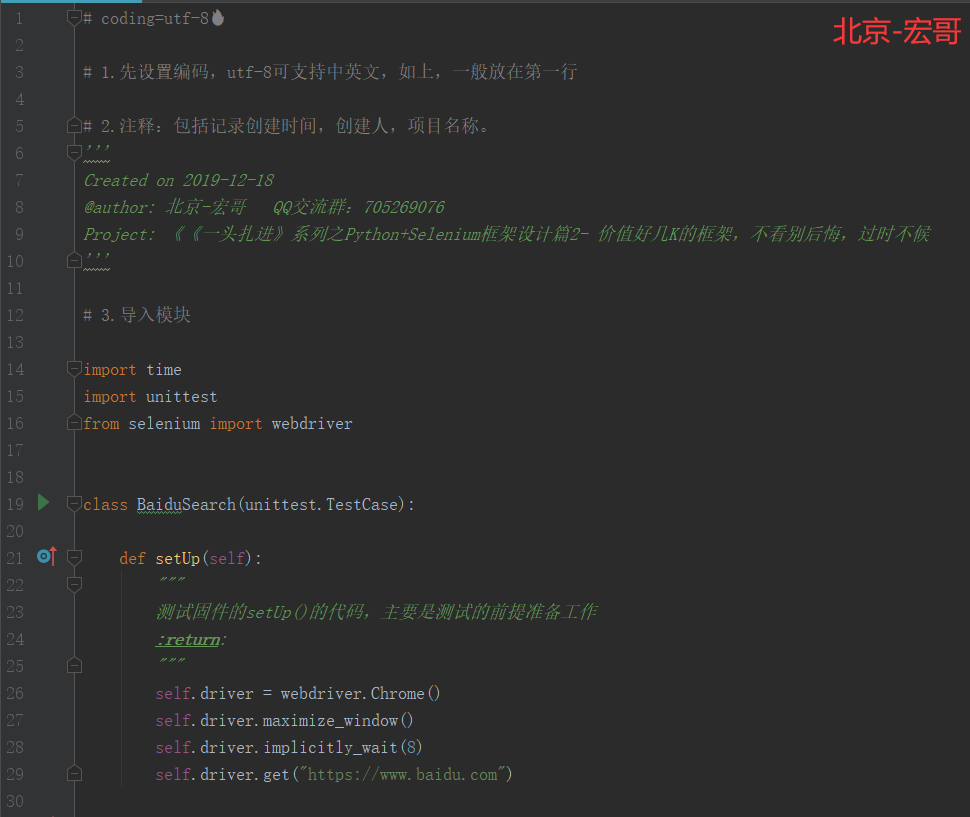
2.5.2 参考代码:
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-18 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇2- 价值好几K的框架,不看别后悔,过时不候 ''' # 3.导入模块 import time import unittest from selenium import webdriver class BaiduSearch(unittest.TestCase): def setUp(self): """ 测试固件的setUp()的代码,主要是测试的前提准备工作 :return: """ self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(8) self.driver.get("https://www.baidu.com") def tearDown(self): """ 测试结束后的操作,这里基本上都是关闭浏览器 :return: """ self.driver.implicitly_wait(8) self.driver.quit() def test_baidu_search(self): """ 这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。 :return: """ self.driver.find_element_by_id('kw').send_keys('selenium') time.sleep(1) self.driver.find_element_by_id('su').click() time.sleep(3) try: assert 'selenium' in self.driver.title print ('Test Pass.') except Exception as e: print ('Test Fail.', format(e)) if __name__ == '__main__': unittest.main()
2.5.3 运行结果:
运行代码后,控制台打印如下图的结果
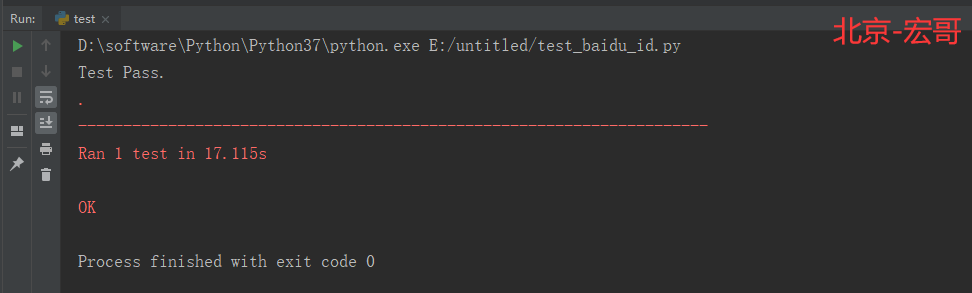
解释:
最后结尾处的unittest.main(),添加这个是支持在cmd,里面,cd到这个脚本文件所在的目录,然后python 脚本名.py执行,如果不添加这一段,是无法执行cmd里面运行脚本的,在PyCharm中,不添加最后一段,也可以通过,右键 Run "unittest xxx",来达到执行效果。
3. 什么是POM(Page Object Model)
前面我们介绍了Python中的单元测试框架unittest,以后我们所有的测试类文件,都采用unittest来辅助我们进行debug和脚本开发。搞定了debug机制和确定了unittest来进行创建和管理我们的自动化测试脚本,接下来我们来考虑下,框架设计中一种很普遍的设计
思想-POM(Page Object Model)。
3.1 POM是什么
Page Object Model (POM) 直译为“页面对象模型”,这种设计模式旨在为每个待测试的页面创建一个页面对象(class),将那些繁琐的定位操作封装到这个页面对象中,只对外提供必要的操作接口。
3.2 POM 有什么好处
POM 将页面定位和业务操作分开,分离了测试对象和测试脚本,如果UI更改页面,测试脚本不需要更改,只需要更改页面对象中的某些代码就可以,提高了可维护性。
POM,中文字母意思是,页面对象模型,POM是一种最近几年非常流行的自动化测试模型,或者思想,POM不是一个框架,就是一个解决问题的思想。采用POM的目的,是为了解决前端中UI变化频繁,从而造成测试自动化脚本维护的成本越来越大。下图,形
象描述了POM的好处。
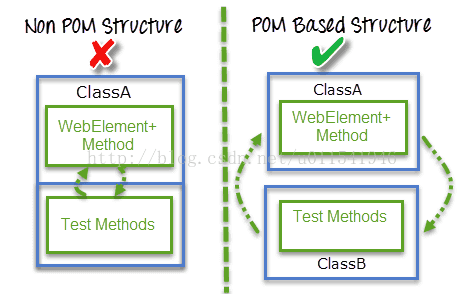
从上图看出,采取了POM设计思路和不采取的区别,左侧把测试代码和页面元素都写在一个类文件,如果需要更改页面,那么就要修改页面元素定位,从而要修改这个类中测试代码,这个看起来和混乱。右侧,采取POM后,主要的区别就是,把页面元素和业务
逻辑和测试脚本分离出来到两个不同类文件。ClassA只写页面元素定位,和业务逻辑代码操作的封装,ClassB只写测试脚本,不关心如何元素定位,只写调用ClassA的代码去覆盖不同的测试场景。如果前端页面发生变化,只需要修改ClassA的元素定位,而不需要去
修改ClassB中的测试脚本代码。
POM主要有以下优点:
1. 把web ui对象仓库从测试脚本分离,业务代码和测试脚本分离。
2. 每一个页面对应一个页面类,页面的元素写到这个页面类中。
3. 页面类主要包括该页面的元素定位,和和这些元素相关的业务操作代码封装的方法。
4. 代码复用,从而减少测试脚本代码量。
5. 层次清晰,同时支持多个编写自动化脚本开发,例如每个人写哪几个页面,不影响他人。
6. 建议页面类和业务逻辑方法都给一个有意义的名称,方便他人快速编写脚本和维护脚本。
3.3 牛刀小试
比如测试一个登陆页面:新浪微博 ,执行测试的人员传递不同的数据到帐号、密码框就可以了,而不应该去顾虑:页面是否已经加载完成?怎样定位到帐号输入框?怎样定位到登陆按钮等等问题。
这些问题全部交由登陆页面的“页面对象”去解决并封装起来,只提供给测试人员三个接口方法:1.帐号输入接口、2.密码输入接口、3.提交接口。
首先定义一个基本页面 BasePage类 ,定义基本的页面操作,提供给其他页面去继承,basePage.py 内容如下:
3.3.1 代码实现:
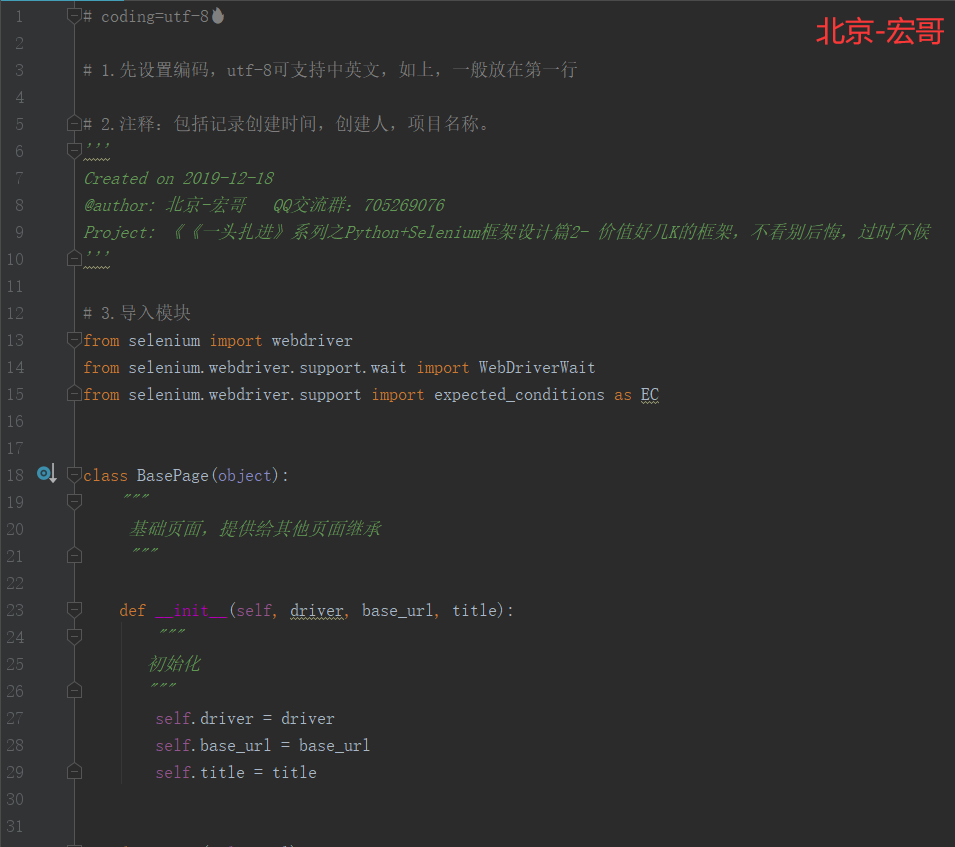
3.3.2 参考代码:
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-18 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇2- 价值好几K的框架,不看别后悔,过时不候 ''' # 3.导入模块 from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC class BasePage(object): """ 基础页面,提供给其他页面继承 """ def __init__(self, driver, base_url, title): """ 初始化 """ self.driver = driver self.base_url = base_url self.title = title def _open(self, url): """ 私有方法,打开url参数指定的页面, 并检查打开是否正确 """ self.driver.get(url) # 显式等待10秒,如果打开页title与预期不符或者超时,抛出异常 WebDriverWait(self.driver, 10).until(EC.title_is(self.title)) def open(self): """ 公共方法,调用私有方法_open()打开链接 """ self._open(self.base_url) def find_element(self, *loc): """ 定位指定元素 """ # 显式等待元素,超过10秒未找到则抛出超时异常(TimeoutException) # presence_of_element_located: 不关心元素是否可见,只关心元素是否存在在页面中 # visibility_of_element_located: 不仅找到元素,并且该元素必须可见 WebDriverWait(self.driver, 15).until(EC.visibility_of_element_located(loc)) return self.driver.find_element(*loc) if __name__ == '__main__': driver = webdriver.Chrome() driver.maximize_window() page = BasePage(driver, 'https://www.baidu.com/','百度一下,你就知道') page.open() driver.quit()
3.3.3 运行结果:
运行代码后,控制台打印如下图的结果

再定义一个 LoginPage类 继承 BasePage类 ,向外提供测登陆方法。文件命名为 xl_login.py ,内容如下:
3.3.4 代码实现:
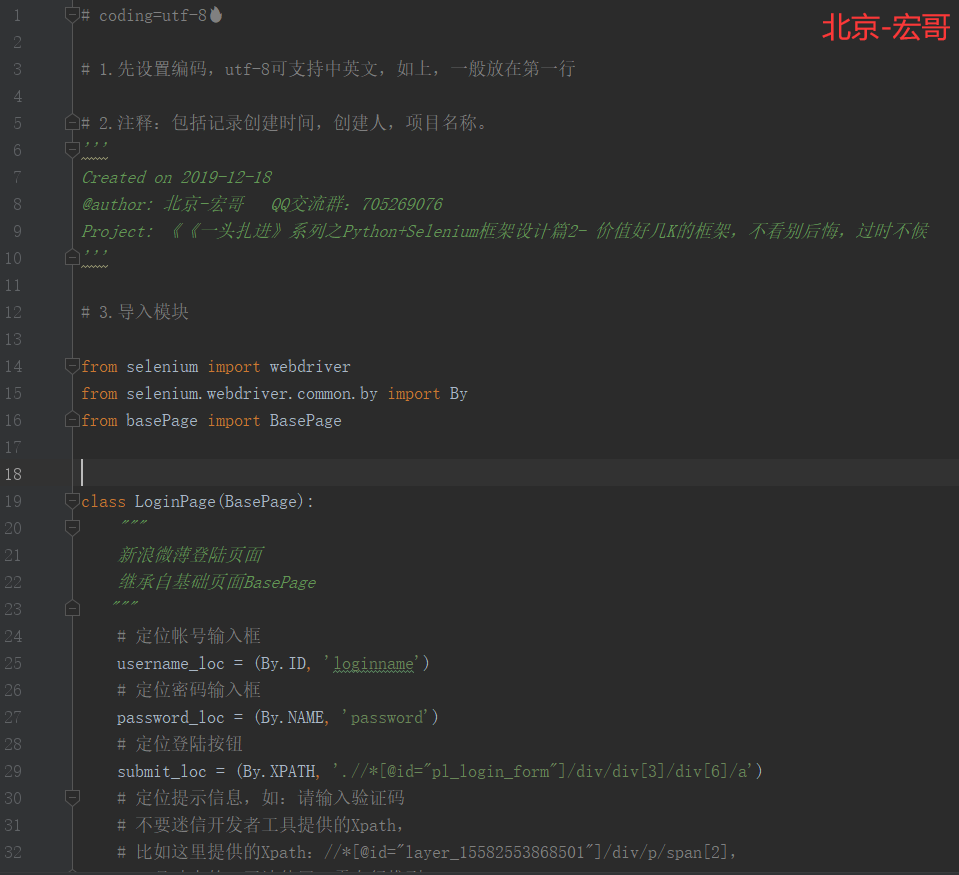
3.3.5 参考代码:
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-18 @author: 北京-宏哥 QQ交流群:705269076 Project: 《《一头扎进》系列之Python+Selenium框架设计篇2- 价值好几K的框架,不看别后悔,过时不候 ''' # 3.导入模块 from selenium import webdriver from selenium.webdriver.common.by import By from basePage import BasePage class LoginPage(BasePage): """ 新浪微薄登陆页面 继承自基础页面BasePage """ # 定位帐号输入框 username_loc = (By.ID, 'loginname') # 定位密码输入框 password_loc = (By.NAME, 'password') # 定位登陆按钮 submit_loc = (By.XPATH, './/*[@id="pl_login_form"]/div/div[3]/div[6]/a') # 定位提示信息,如:请输入验证码 # 不要迷信开发者工具提供的Xpath, # 比如这里提供的Xpath://*[@id="layer_15582553868501"]/div/p/span[2], # id是动态的,无法使用,需自行推到Xpath message_loc = (By.XPATH, '//div[@class="content layer_mini_info"]/p/span[2]') # 输入用户名操作 def type_username(self, username): self.find_element(*self.username_loc).send_keys(username) # 输入密码操作 def type_password(self, password): self.find_element(*self.password_loc).send_keys(password) # 点击登陆按钮操作 def submit(self): self.find_element(*self.submit_loc).click() # 获取提示信息 def get_message(self): return self.find_element(*self.message_loc).text if __name__ == '__main__': # 测试登陆 # 预打开页面 base_url = 'https://weibo.com/' # 页面title title = '微博-随时随地发现新鲜事' # 准备好待输入的用户名和密码 username = 'haha' password = 'hehe' # 打开Chrome浏览器 driver = webdriver.Chrome() driver.maximize_window() # 登陆页面初始化 login = LoginPage(driver, base_url, title) # 打开新浪微博页 login.open() # 输入用户名 login.type_username(username) # 输入密码 login.type_password(password) # 点击登陆 login.submit() # 打印提示信息 print(login.get_message())
3.3.6 运行结果:
运行代码后,控制台打印如下图的结果
4.小结
好了,今天的分享就到这里吧!!!谢谢各位的耐心阅读。有问题加群交流讨论
您的肯定就是我进步的动力。如果你感觉还不错,就请鼓励一下吧!记得随手点波 推荐 不要忘记哦!!!
别忘了点推荐留下您来过的痕迹

感谢您花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让博主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下左下角“推荐”按钮,您的将是我最大的写作动力!另外您也可以选择【关注我】,可以很方便找到我!
本文版权归作者和博客园共有,来源网址:https://www.cnblogs.com/du-hong 欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利!
公众号(关注宏哥) 客服微信



