《手把手教你》系列练习篇之3-python+ selenium自动化测试(详细教程)
1. 简介
前面介绍了,XPath, id , class , link text, partial link text, tag name, name 七大元素定位方法,本文介绍webdriver支持的最后一个方法:by_css。css和XPath类似,也需要掌握一些语法,才能写出正确的,完整的css选择表达式。相关w3c介绍,请点击这里。
2. by_css定位元素
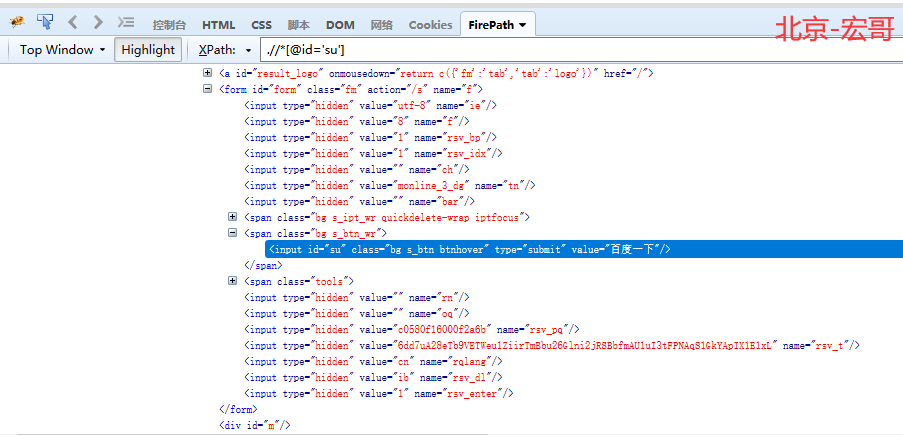
以百度首页的“百度一下”按钮为例,我们通过by_css来定位到这个按钮。如图
2.1 代码实现:
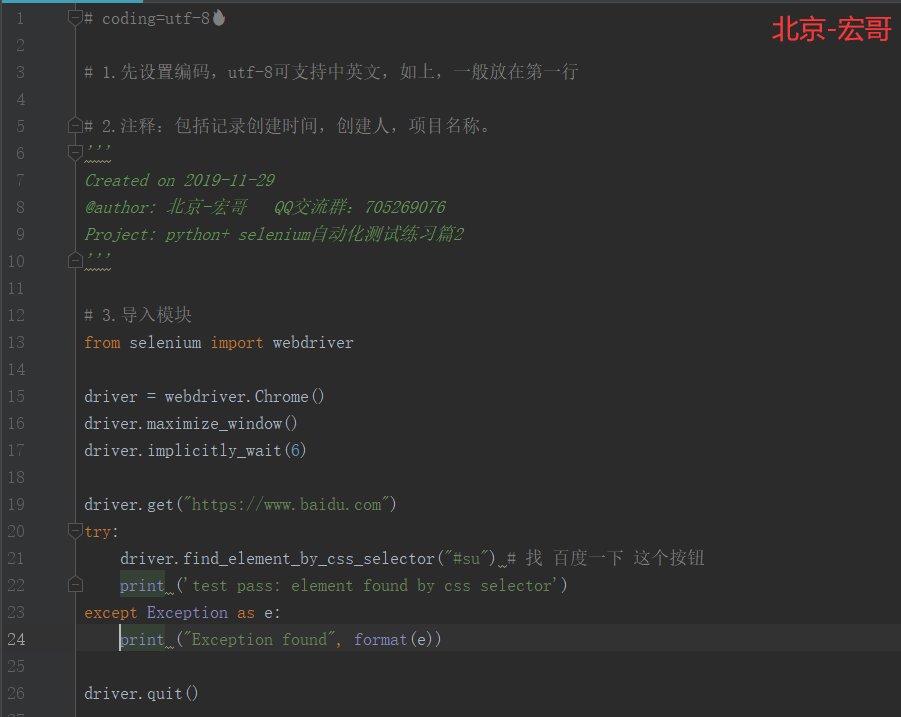
2.2 参考代码:
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-11-29 @author: 北京-宏哥 QQ交流群:705269076 Project: python+ selenium自动化测试练习篇3 ''' # 3.导入模块 from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") try: driver.find_element_by_css_selector("#su") # 找 百度一下 这个按钮 print ('test pass: element found by css selector') except Exception as e: print ("Exception found", format(e)) driver.quit()
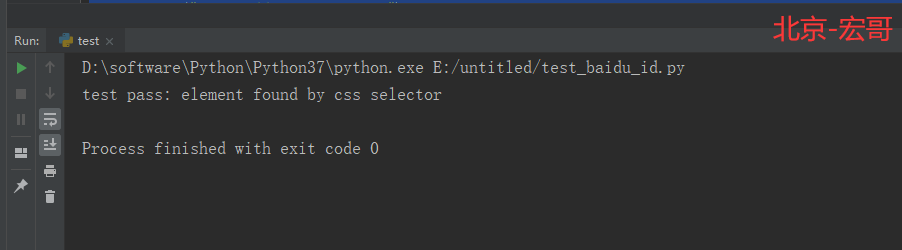
2.3 运行结果:
运行代码后,控制台打印如下图的结果
总结:如果一开始没有接触css,感觉写css表达式有点困难,没关系。看个人喜好和适合哪个,例如,如果你掌握好了XPath的写法,那么就可以不去管css,毕竟大部分xpath表达式都能够定位到元素。有些人可能说了,css要比xpath表达式查找元素的速度要
快,这个你不要去担心,对计算机来讲,你根本无法区分哪个更快,也不是自动化测试考虑的重点。
建议:一定要掌握好XPath或者css来定位元素,其他的几种了解就可以。毕竟在实际项目开发脚本阶段,很多元素是无法通过id ,css, text, name来直接定位这个网页元素,更多的还是根据XPath或者css表达式去定位。
3. 清除文本方法
在前面的文章中,我们或多或少的用到了输入字符和点击按钮这样的操作。用send_keys()来输入字符串到文本输入框这样的页面元素,用click()来点击页面上支持点击的元素。有时候,我们需要清除一个文本输入框内的文字,然后重新输入新的字符串,那边清
除这个方法如何实现呢。
调用webdriever中clear()方法:
相关代码如下,为了演示测试效果,我们运行完脚本,不关闭浏览器:
3.1 代码实现:

3.2 参考代码:
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-02 @author: 北京-宏哥 QQ交流群:705269076 Project: python+ selenium自动化测试练习篇3 ''' # 3.导入模块 from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") driver.find_element_by_id("kw").send_keys("Selenium") try: driver.find_element_by_id("kw").clear() # 调用clear()方法去清除 print ('test pass: clean successful') except Exception as e: print ("Exception found", format(e))
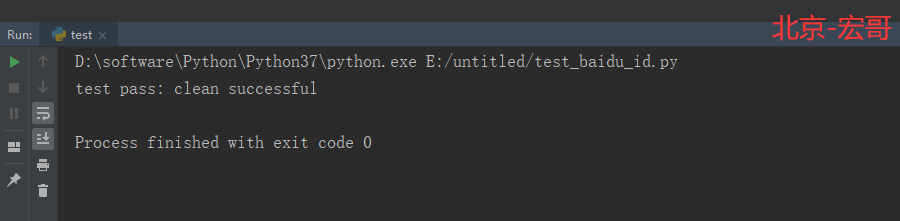
3.3 运行结果:
运行代码后,控制台打印如下图的结果
4. 调用webdriver中刷新页面的方法
本小节宏哥给小伙伴们或者童鞋们来介绍如何调用webdriver中刷新页面的方法。其实前边已经说过,这个只不过是作为练习我们再来巩固一下而已。
相关脚本代码如下:
4.1 代码实现:

4.2 参考代码:
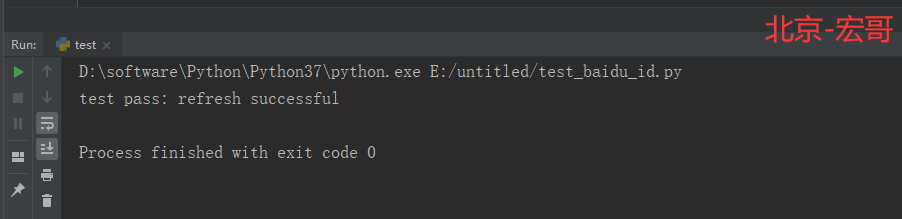
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-02 @author: 北京-宏哥 QQ交流群:705269076 Project: python+ selenium自动化测试练习篇3 ''' # 3.导入模块 import time from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") time.sleep(2) try: driver.refresh() # 刷新方法 refresh print ('test pass: refresh successful') except Exception as e: print ("Exception found", format(e)) driver.quit()
4.3 运行结果:
运行代码后,控制台打印如下图的结果
5. 浏览器前进后退
本小节来介绍上如何,利用webdriver中的方法来演示浏览器中地址栏旁边的前进和后退功能。其实这个前边也已经说过,这个只不过是作为练习我们再来巩固一下而已。
相关脚本代码如下:
5.1 代码实现:
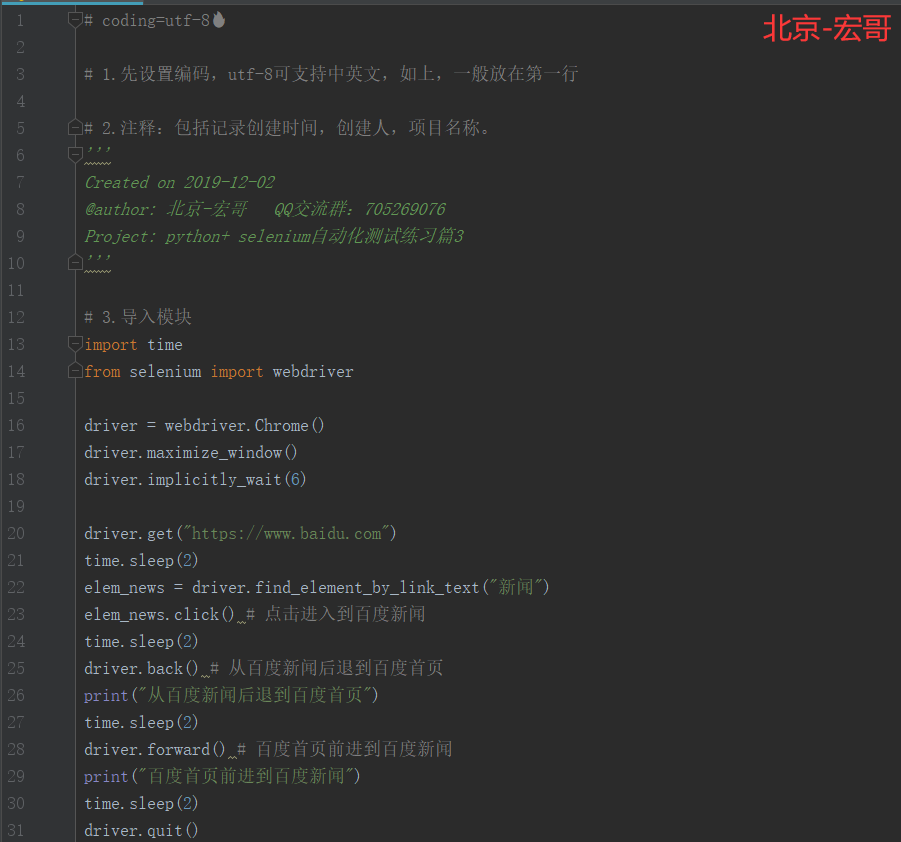
5.2 参考代码:
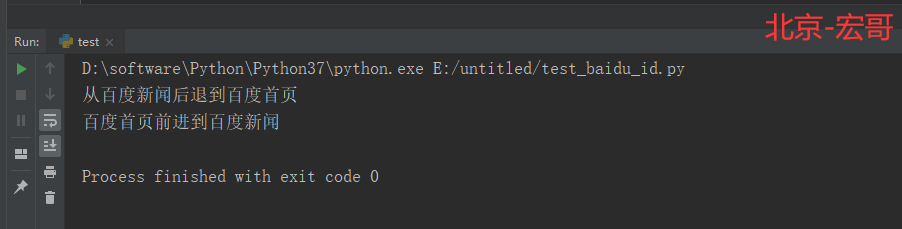
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-02 @author: 北京-宏哥 QQ交流群:705269076 Project: python+ selenium自动化测试练习篇3 ''' # 3.导入模块 import time from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") time.sleep(2) elem_news = driver.find_element_by_link_text("新闻") elem_news.click() # 点击进入到百度新闻 time.sleep(2) driver.back() # 从百度新闻后退到百度首页 print("从百度新闻后退到百度首页") time.sleep(2) driver.forward() # 百度首页前进到百度新闻 print("百度首页前进到百度新闻") time.sleep(2) driver.quit()
5.3 运行结果:
运行代码后,控制台打印如下图的结果
6. webdriver方法获取浏览器的版本号
本小节介绍,如何通过webdriver方法获取浏览器的版本号。看起来这个功能很鸡肋,不管怎么说,还是学习下,特别是在发送自动化测试报告的时候,还是可以通过这个方法来告诉别人,执行过的脚本是通过什么浏览器,什么版本跑的吧。
相关脚本代码如下:
6.1 代码实现:
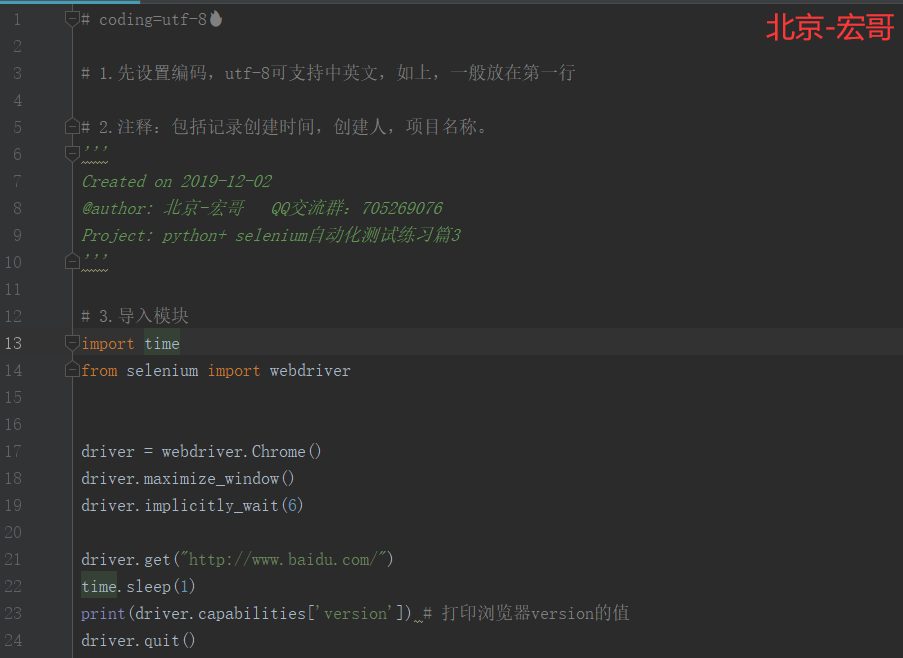
6.2 参考代码:
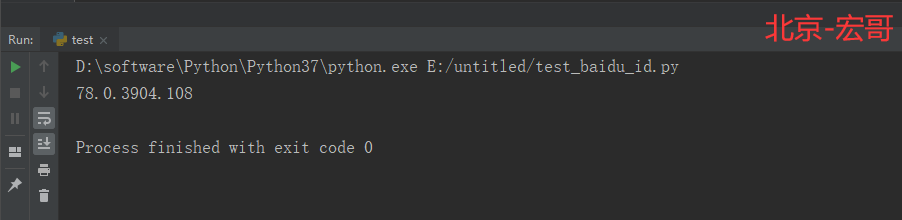
# coding=utf-8🔥 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-02 @author: 北京-宏哥 QQ交流群:705269076 Project: python+ selenium自动化测试练习篇3 ''' # 3.导入模块 import time from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("http://www.baidu.com/") time.sleep(1) print(driver.capabilities['version']) # 打印浏览器version的值 driver.quit()
6.3 运行结果:
运行代码后,控制台打印如下图的结果
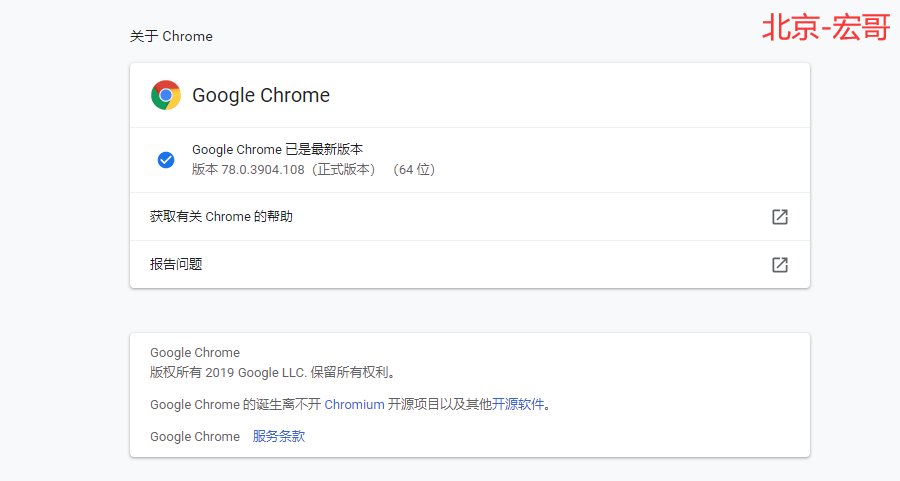
6.4 查看浏览器版本
右上角——>帮助——>关于Google Chrome,点击后如下图:查看版本号一致。
7. 小结
好了,今天的练习就到这里,希望大家好好的练习和理解。
您的肯定就是我进步的动力。如果你感觉还不错,就请鼓励一下吧!记得点波 推荐 不要忘记哦!!!

感谢您花时间阅读此篇文章,如果您觉得这篇文章你学到了东西也是为了犒劳下博主的码字不易不妨打赏一下吧,让博主能喝上一杯咖啡,在此谢过了!
如果您觉得阅读本文对您有帮助,请点一下左下角“推荐”按钮,您的将是我最大的写作动力!另外您也可以选择【关注我】,可以很方便找到我!
本文版权归作者和博客园共有,来源网址:https://www.cnblogs.com/du-hong 欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利!
公众号(关注宏哥) 客服微信



