一、实验目的
l 熟练使用 scrapy 爬虫框架;
l 掌握通过关键词搜索爬取数据的方法;
l 熟练编写 python 代码实现数据爬取;
二、实验原理
网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。通俗来说就是模拟用户在浏览器上的操作,从特定网站,自动提取对自己有价值的信息。主要通过查找域名对应的 IP 地址、向 IP 对应的服务器发送请求、服务器响应请求,发回网页内容、浏览器解析网页内容四个步骤来实现。
本实验时通过爬虫框架 Scrapy 爬取舆情数据,scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted(其主要对手是 Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
三、实验环境
Dsight 实验室中的 python3 环境、第三方包有 scrapy,re
Pycharm 、NotePad++、Sublime Text 等代码编辑工具
步骤1:分析电商网站目标数据信息
电商网站上手机基本信息如下:
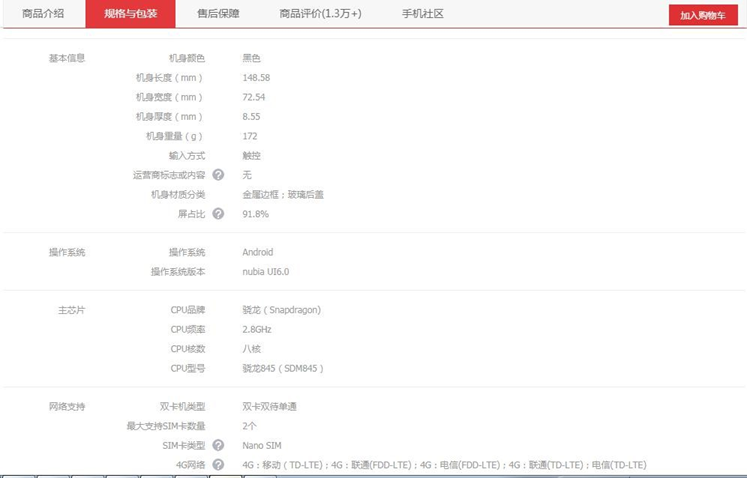
步骤2:读取手机品牌作为搜索关键词
根据手机品牌作为搜索关键词:

实现代码如下:
with open('./mobile_project/data/手机品牌.csv', 'r', encoding='utf-8') as f: csv_reader = csv.reader(f) # 通过csv按行读取
for brand in csv_reader: brand = brand[0] print('++++++++++crawling:{}'.format(brand))
if brand.strip(): brand = brand.strip() + ' 手机' yield
Request(jd_search_url.format(kw=brand, page=page), headers=self.headers, meta={'kw': brand, 'page': page}, callback=self.parse_search_result)
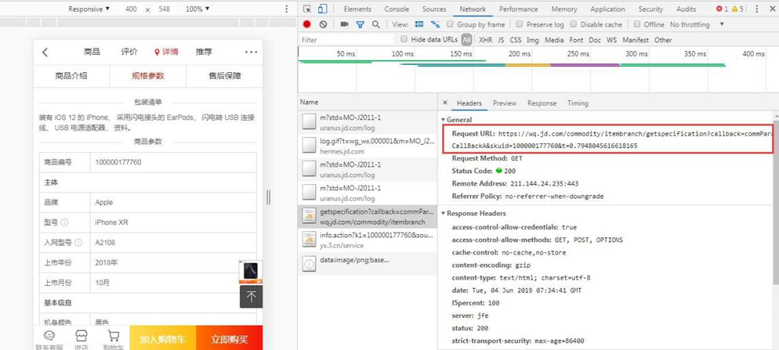
步骤3:查看商品详情请求的api
获取访问链接通过电脑网页访问手机端商品详情页,查看商品详情请求的 api:
步骤4:明确解析字段
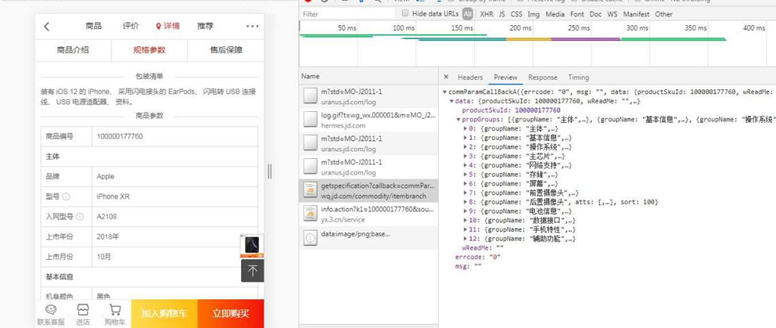
步骤5:解析搜索结果
解析商家信息:
if 'data' in json_data and 'searchm' in json_data['data'] and json_data['data']['searchm']['Paragraph']: for item in json_data['data']['searchm']['Paragraph']: has_next_page = True ret = {} content = item['Content'] ret['name'] = content['warename'] ret['custom_attr_list'] = content['CustomAttrList'] ret['shop_name'] = item['shop_name'] ret['comment_count'] = item['commentcount'] ret['good_rate'] = item['good'] ret['shop_id'] = item['shop_id'] ret['id'] = item['wareid'] ret['price'] = item['dredisprice'] ret['url'] = 'https://item.jd.com/{}.html'.format(item['wareid']) ret['keyword'] = kw yield Request(jd_wine_info_url.format(skuid=ret['id']), headers=self.headers, meta=ret, callback=self.parse_product_info)
解析手机详细配置信息:
"""解析商品详细配置信息"""
ret = response.meta matcher = product_info_ptn.findall(response.text) if not matcher: print('*************get product info error') return json_data = json.loads(matcher[0]) # 商品属性信息,这里直接将属性的中文作为key,方便理解!!! prop_dict = {} for prop_group in json_data['data']['propGroups']: for attr in prop_group['atts']: prop_dict[attr['attName']] = '|'.join(attr['vals']) ret['prop'] = prop_dict yield ret
步骤6:存储爬取结果

任务四:基于实验平台执行爬虫程序
运行编写完成的 python 脚本,爬取目标数据
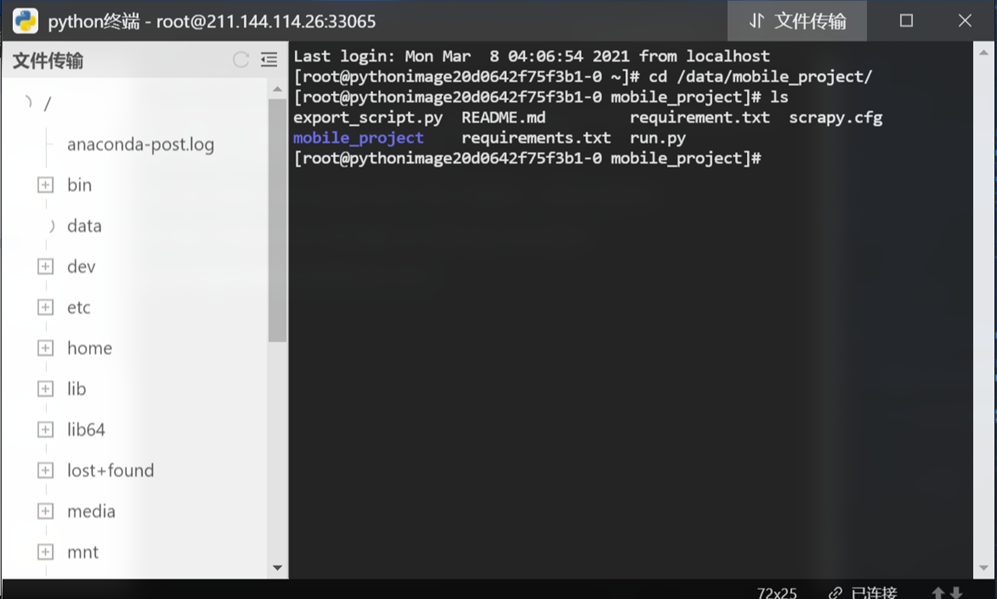
步骤1:进入实验室并上传项目文件
进入实验室,打开python工具,上传参考资料里的mobile_project文件夹到data目录下。
步骤2:创建虚拟环境
收起文件传输面板,在Python控制台输入指令“cd /data/mobile_project/”即可进入创建虚拟环境的目录,如下图所示:
输入指令“virtualenv .venv”回车,在此目录下新建一个“.venv”文件夹,作为此项目的虚拟环境,如果提示没有virtualenv 命令,则输入指令“pip install virtualenv”如下图所示:
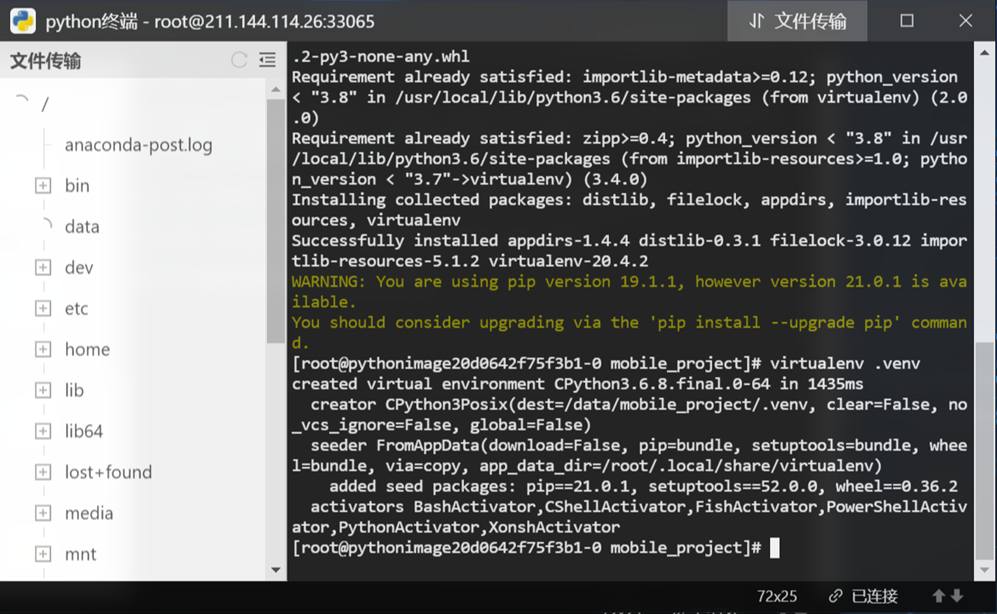
使用指令“virtualenv .venv”,成功创建虚拟环境,并使用命令“source .venv/bin/activate”进入虚拟环境
步骤3:下载安装依赖库
pip install -r requirements.txt
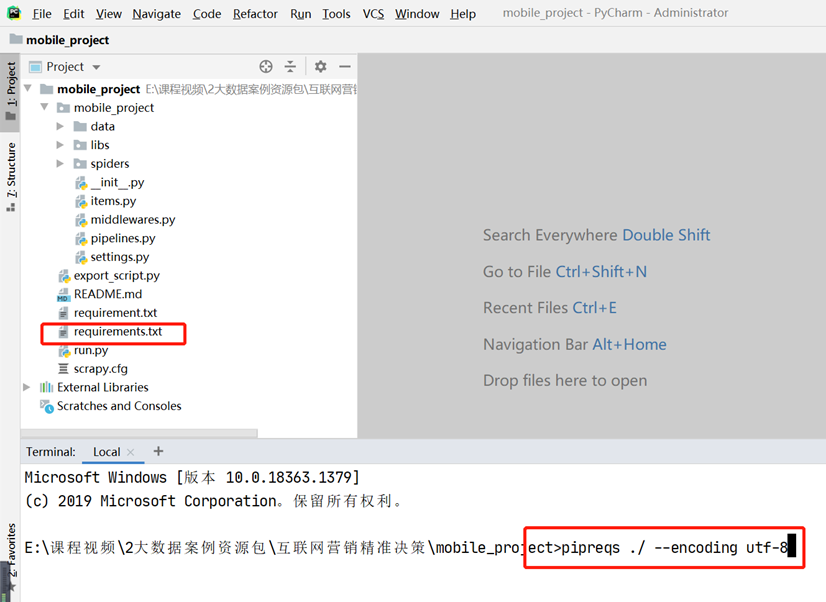
【requirements.txt】文件的生成说明:打开PyCharm下面的Terminal,终端自动进入当前目录,项目中就会生成好requirements.txt文件,输入以下命令:
pipreqs ./ --encoding utf-8
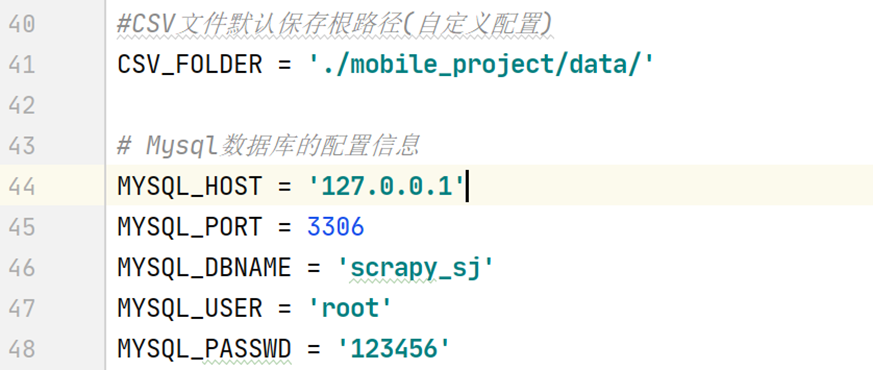
步骤4:打开mysql工具,查看和连接节点信息
同时打开mysql工具,查看节点信息
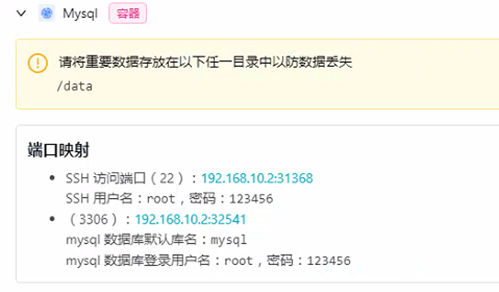
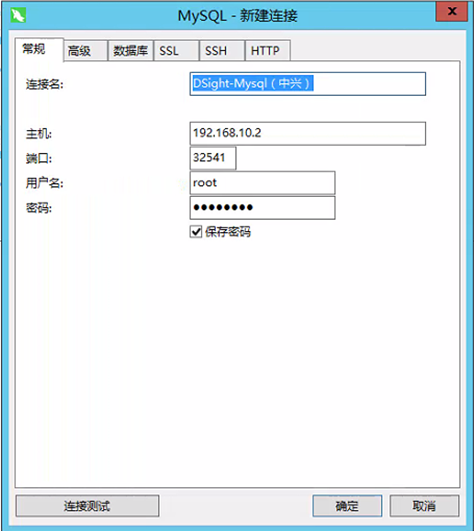
步骤5:创建数据库
进入mysql容器,或者navicat远程连接。连接后,创建数据库:
create database scrapy_sj;
show databases;
use scrapy_sj;
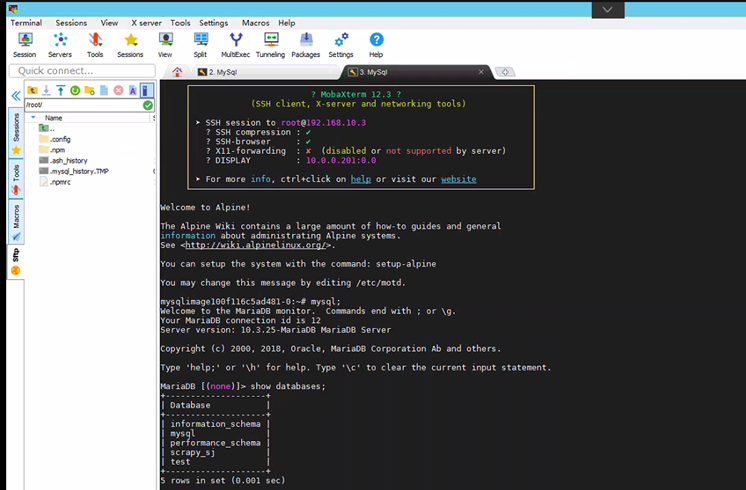
步骤5:创建表格
进入mysql容器,或者navicat远程连接。连接后,创建相关表格
DROP TABLE IF EXISTS `jd_search_sj`;
CREATE TABLE `jd_search_sj` (
`id` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`keyword` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL,
`data` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `jd_product_comments`;
CREATE TABLE `jd_product_comments` (
`id` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`keyword` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`data` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
PRIMARY KEY USING BTREE (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `jd_history_price`;
CREATE TABLE `jd_history_price` (
`id` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`keyword` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`data` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
PRIMARY KEY USING BTREE (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
show tables;
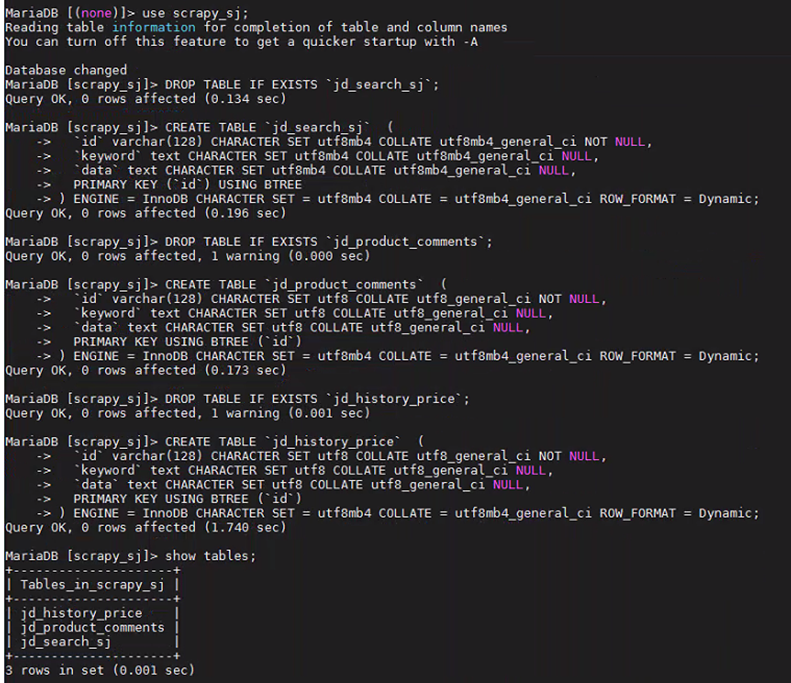
步骤6:修改脚本配置信息
修改python脚本配置信息,修改数据库配置为mysql节点信息:
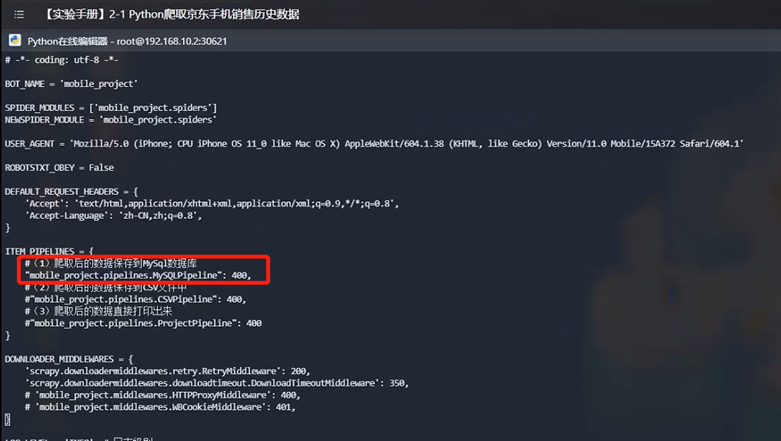
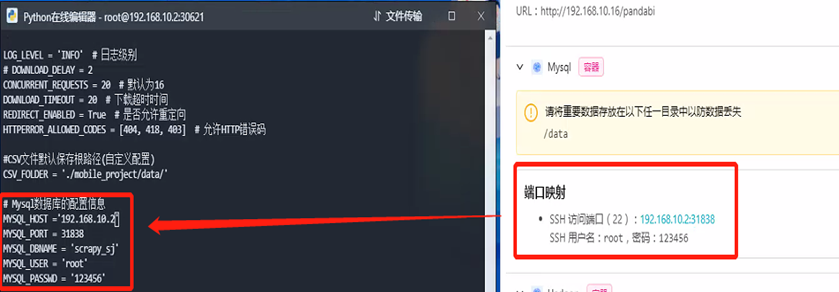
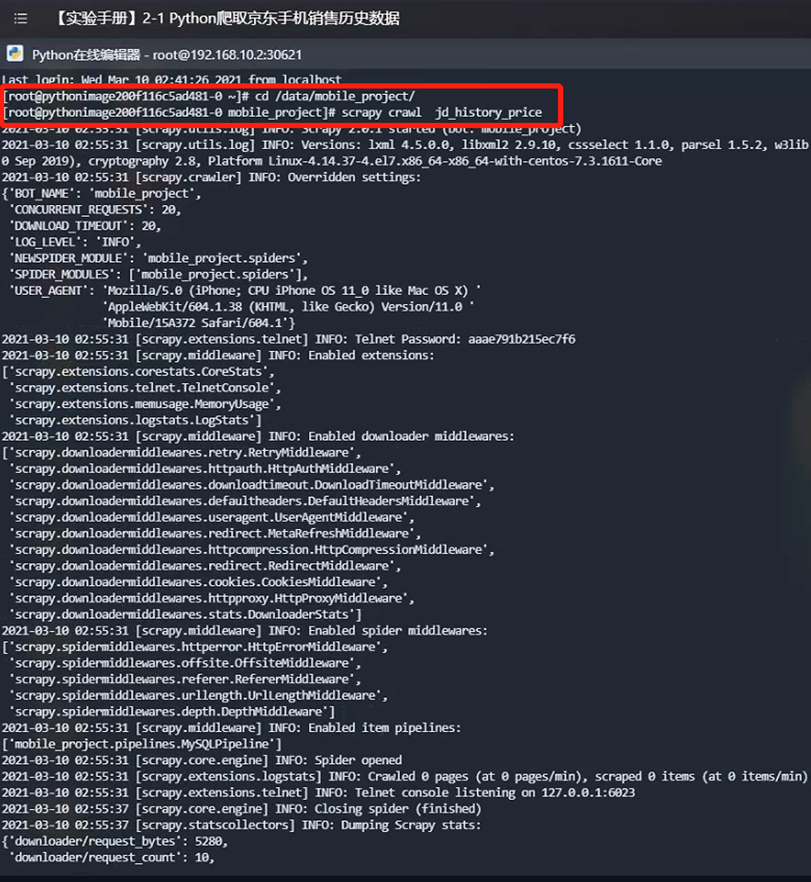
步骤7:执行爬虫脚本
scrapy crawl jd_search_sj
scrapy crawl jd_history_price
scrapy crawl jd_product_comments
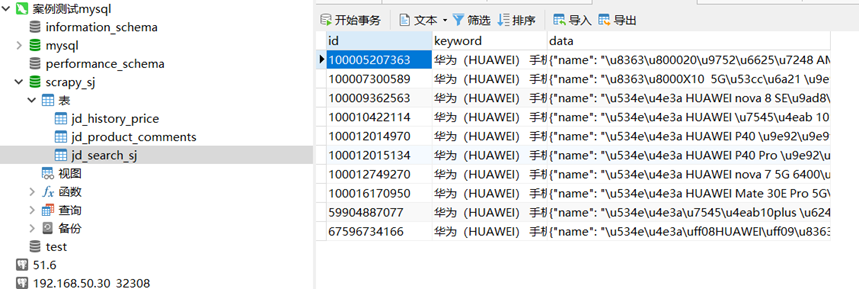
步骤8:查看数据库,确认数据写入成功
步骤9:导出为csv文件
执行export脚本,导出为csv文件(记得修改脚本里数据库配置)
python3 export_script.py
五、实验成果
本次实验完成后,需要得到以下结果: l 京东手机商品数据爬虫代码编写; l 爬取数据得到 csv 文件;爬取结果示例:
{
"name":"努比亚 nubia Z18 全面屏 3.0 极夜黑 8GB+128GB 全网通移动联通电信 4G 手机双卡双待",
"custom_attr_list":"6.0 英寸^8GB^128GB^2400 万+1600 万像素^骁龙
845(SDM845)^800 万像素^2160*1080^8.55",
"shop_name":"努比亚京东自营旗舰店",
"comment_count":"13266",
"good_rate":"97",
"shop_id":"1000001961",
"id":"100000047414",
"price":"2549.00",
"url":"https://item.jd.com/100000047414.html",
"keyword":"努比亚(nubia)手机",
"prop":{
"品牌":"努比亚(nubia)",
"型号":"Z18",
"入网型号":"NX606J",
"上市年份":"2018 年",
"上市月份":"9 月",
"机身颜色":"黑色",
"机身长度(mm)":"148.58",
"机身宽度(mm)":"72.54",
"机身厚度(mm)":"8.55",
"机身重量(g)":"172",
"输入方式":"触控",
"运营商标志或内容":"无",
"机身材质分类":"金属边框|玻璃后盖",
"屏占比":"91.8%",
"操作系统":"Android",
"操作系统版本":"nubia UI6.0",
"CPU 品牌":"骁龙(Snapdragon)",
"CPU 频率":"2.8GHz",
"CPU 核数":"八核",
"CPU 型号":"骁龙 845(SDM845)",
"双卡机类型":"双卡双待单通",
"最大支持 SIM 卡数量":"2 个",
"SIM 卡类型":"Nano SIM",
"4G 网络":"4G:移动(TD-LTE)|4G:联通(FDD-LTE)|4G:电信 (FDD-LTE)|4G:联通(TD-LTE)|电信(TD-LTE)",
"3G/2G 网络":"3G:移动(TD-SCDMA)|3G:联通(WCDMA)|3G:电信(CDMA2000)|2G:移动联通(GSM)+电信(CDMA)",
"副 SIM 卡类型":"Nano SIM",
"副 SIM 卡 4G 网络":"4G:移动(TD-LTE)|4G:联通(FDD-LTE)|4G:电信(FDD-LTE)|不支持主副卡同时使用电信卡|4G:联通(TD-LTE)", "4G+(CA)":"移动 4G+|联通 4G+|电信 4G+",
"高清语音通话(VOLTE)":"移动 VOLTE|电信 VOLTE",
"网络频率(2G/3G)":"2G:GSM 850/900/1800/1900|2G:CDMA 800|3G : TD-SCDMA 1900/2000|3G : WCDMA 850/900/1900/2100|3G : CDMA2000|2G:GSM 900/1800|2G:GSM 900/1800/1900|3G:CDMA 800MHz
1X&EVDO|3G:WCDMA:850/900/1700/1900/2100MHz|TD-SCDMA1880/2010",
"是否支持同时使用联通卡":"支持双卡同时在线,并同时使用联通
4G 移动数据",
"ROM":"128GB",
"ROM 类型":"UFS",
"RAM":"8GB",
"RAM 类型":"LPDDR 4X",
"存储卡":"不支持",
"主屏幕尺寸(英寸)":"6.0 英寸",
"分辨率":"2160*1080",
"屏幕像素密度(ppi)":"403",
"屏幕材质类型":"LTPS",
"屏幕生产厂商":"JDI",
"亮度":"500(type)",
"对比度":"1500(type)",
"前置摄像头":"800 万像素",
"前摄光圈大小":"f/2.0",
"美颜技术":"支持",
"摄像头数量":"2 个",
"后置摄像头":"2400 万+1600 万像素",
"摄像头光圈大小":"其他",
"闪光灯":"双色温灯",
"副摄像头光圈大小":"其他",
"拍照特点":"防抖|美颜|连拍|微距|全景|滤镜|场景模式|HDR|PDAF| 微信小视频|水印",
"电池容量(mAh)":"3450",
"电池类型":"锂电池",
"电池是否可拆卸":"否",
"充电器":"9V/2A",
"数据传输接口":"WIFI|NFC|蓝牙|WiFi 热点|OTG 接口", "NFC/NFC 模式":"支持(点对点模式)|支持(读卡器模式)|支持(卡模式)|支持卡模拟",
"耳机接口类型":"Type-C",
"充电接口类型":"Type-C",
"数据线":"USB2.0",
"指纹识别":"支持",
"语音识别":"支持",
"GPS":"支持",
"电子罗盘":"支持",
"陀螺仪":"支持",
"红外遥控":"不支持",
"其他":"距离感应|呼吸灯|多麦降噪技术|光线感应",
"常用功能":"录音|便签|重力感应"
}
}
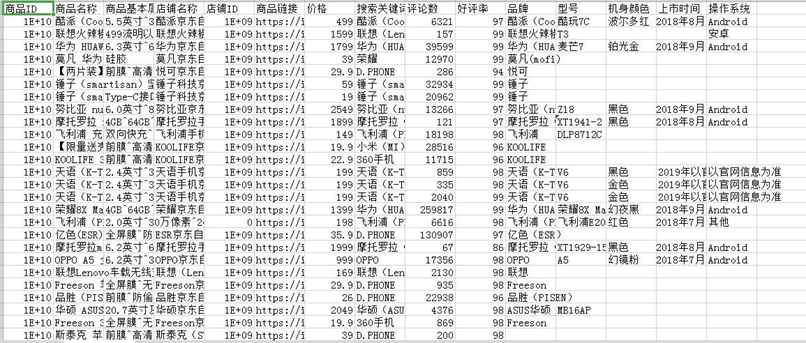
选取其中需要的字段输出到 csv 文件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号