
2.编写独立应用程序实现数据去重
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C。
在/root/spark-local/mycode/remdup目录下新建
mkdir -p src/main/scala目录
新建文件vim remdup.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object RemDup {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
val dataFile = file:///home/charles/data
val data = sc.textFile(dataFile,2)
valres=data.filter(_.trim().length>0).map(line=>(line.trim,"")).partitionBy(newHashPartitioner(1)).groupByKey().sortByKey().keys
res.saveAsTextFile("result")
}
}
(2)在目录/usr/local/spark/mycode/remdup目录下新建simple.sbt
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0"
(3)在目录/usr/local/spark/mycode/remdup下执行下面命令打包程序

(4)最后在目录/usr/local/spark/mycode/remdup下执行下面命令提交程序

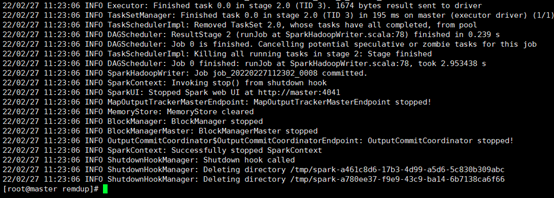
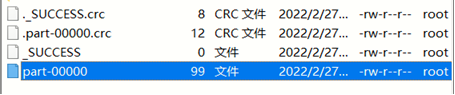

成功了
注:如果目录下没有文件需要自己添加文件夹,否则会报错
3.编写独立应用程序实现求平均值问题
建新目录

在目录下新建文件
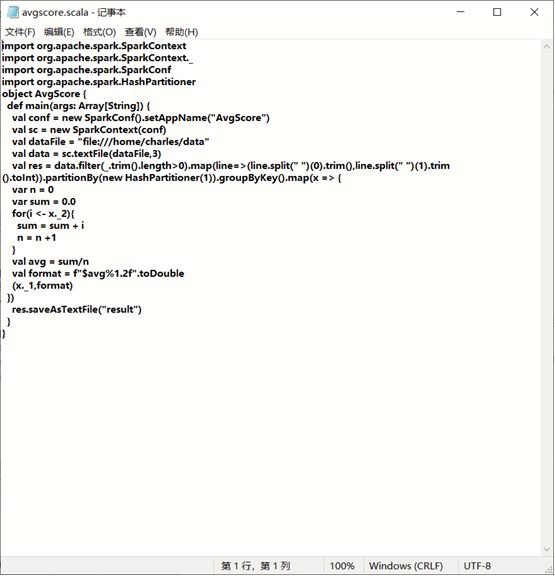
在avgscore文件夹下新建simple.sbt文件
打包
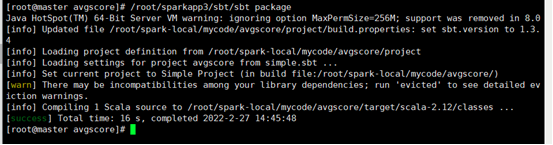
成功
提交程序



 浙公网安备 33010602011771号
浙公网安备 33010602011771号