给定a,b两个文件,各存放50亿各url,每个url各占64G,内存限制是4GB,请找出文件a与文件b共同的url。
如果没有内存的限制,可以首先将文件a中的url全部读入内存,放到HashSet中,接着从文件b中读取url,每读取一个url,就判断这个url在HashSet中是否存在,如果存在,那么这个url就是这两个
文件共同的url,否则不是。
由于题目要求内存大小只有4GB,而每个文件的大小为50亿*64B=5*64GB=320GB,远远超出了内存限制,因此,无法一次将所有url读取到内存中,此时可以采取分批读取的方法。
下面介绍两种常用的方法:
方法一:Hash法
通过对url求Hash值,把Hash值相同的url放到一个单独的文件里,这样就可以把50亿个url分解成较小的url,然后一次读入内存进行处理,具体实现思路如下:
首先遍历文件a,对每个url求Hash值并散列到1000个文件中,求解方法为h=hash(url)%1000,然后根据Hash的结果把这些url存放到文件fa中,通过散列,所有的url将会分布在(fa0,fa2,fa3,...,fa999)
这1000个文件中。每个文件的大小大约为300MB。同理,将文件b中的url也以同样的计算方式散列到文件fb中,所有的url将会分布在(fb0,fb1,fb2,...,fb999)这1000个文件中。显然,与fa0中相同的
url只可能存在于fb0中,因此,只需要分别找出文件fai与fbi(0 ≤i≤999)中相同的url即可。
此外,如果经过Hash处理后,还有小文件占的内存大小超过4GB,此时可以采用相同的方法把文件分割为更小的文件进行处理。
方法二:Bloom filter法
日常生活中很多地方都会遇到类似这样的问题,例如,在设计计算机软件系统时,在程序中经常判断一个元素是否在一个集合中;在字处理软件中,需要检查一个英语单词是否拼写正确;在FBI,一个嫌疑人的名字
是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等。
针对这些问题,最直接的解决方法就是将集合中全部的元素都存储在计算机中,每当遇到一个新元素时,就将它和集合中的元素直接进行比较即可。这种做法虽然能够准确无误地完成任务,但存在一个问题,就是比较
次数太多,效率比较低,当数据量不大时,这种效率低的问题并不显著,但是当数据量巨大时。例如在海量数据信息处理中,存储效率低的问题就显示出来了。
Bloom filter正是解决这一问题的有效方法,它是一种空间效率和时间效率很高的随机数据结构,用来检测一个元素是否属于一个集合。但它同样带来一个问题:牺牲了正确率,Bloom filter以牺牲正确率为前提,来换取
空间效率与时间效率的提高。当他判断某元素不属于这个集合时,该元素一定不属于这个集合;当他判断某元素属于这个集合时,该元素不一定属于这个集合。具体而言。查询结果有两种可能,即“不属于这个集合(绝对
正确)”和“属于这个集合(可能错误)”。所以,Bloom filter适合应用在对于低错误率可以容忍的场合。
它的基本原理是位数组与Hash函数的联合使用。具体而言,首先。Bloom filter是一个包含了m位的位数组,数组的每一位都初始化位0,然后定义k个不同的Hash函数,每个函数都可以将集合中的元素映射到位数组的
某一位。当向集合中插入一个元素时,根据k个Hash函数可以得到位数组中的k个位,将这些位设置为1。如果查询某个元素是否属于集合,那么根据k个Hash函数可以得到位数组中的k个位,查看这k个位中的值,如果有
的位不为1,那么该元素肯定不在此集合中;如果这k个位全部为1,那么该元素可能在此集合中(在插入其他元素时,可能会将这些位置为1,这样就产生了错误)。
下面通过一个实例具体了解Bloom filter
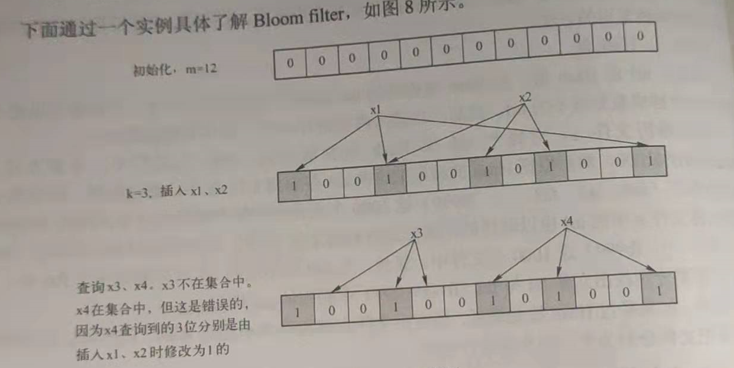
所以,当使用Bloom filter的难点时如何根据输入元素个数n,来确定位数组m的大小以及Hash函数。当Hash函数个数k=(ln2)*(m/n)时错误率最小,在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示
任意n个元素的集合。但m还应该更大些,因为要保证位数组至少一半为0,则m应该大于等于n*lg(1/E)*lge大约为n*lg(1/E)的1.44倍(lg表示以2为底的对数)。
例如假设E为0.01,即错误率为0.01,则此时m应该大约为n的13倍,这样k大约是8个(注意:m与n的单位不同,m的单位是bit,而n则是以元素个数为单位)。通常单个元素的长度都是有很多bit的,所以,使用
Bloom filter内存通常都是节省的。
Bloom filter的优点是具有很好的空间效率和时间效率。它的插入和查询时间都是常数,另外它不保证元素本身,具有良好的安全性。然而,这些优点都是以牺牲正确率为代价的。当插入的元素越多,错判“元素
属于这个集合”的概率就越大。另外,Bloom filter只能插入元素,却不能删除元素,因为多个元素的Hash结果可能共用了Bloom filter结构中的同一个位,如果删除元素,就可能会影响多个元素的检测。所以,
Bloom filter可以用来实现数据字典,进行数据的判重或者集合求交集。
对于本题而言:4GB内存可以表示340亿bit,把文件a中的url采用Bloom filter方法映射到这340亿bit上,然后遍历文件b,判断是否存在。但是采用这种方法会有一定的错误率,只要允许有一定的错误率的时候
才可以使用这种方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号