
3.K均值算法
扑克牌手动演练k均值聚类过程:>30张牌,3类
在其中选择了3张牌作为初始中心,即点数为1、2、3的牌放在上面作为中心
第1轮:聚类中心为1、2、3,新聚类中心为1、2、6

第2轮:聚类中心为1、2、6,新聚类中心为1、3,6

第3轮:聚类中心为1、3、6,新聚类中心为1、3、6

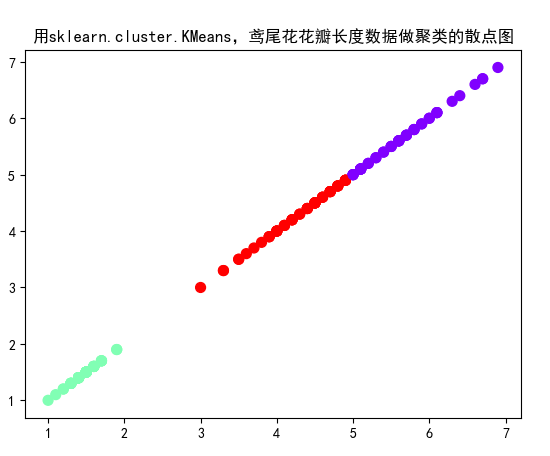
用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mplmpl.rcParams['font.sans-serif'] = ['SimHei']
iris = load_iris()
x = iris.data[:, 2].reshape(-1, 1)model = KMeans(n_clusters=3)
model.fit(x)
y = model.predict(x)
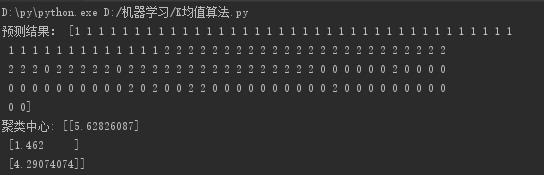
print("预测结果:", y)
kc = model.cluster_centers_
print("聚类中心:", kc)
plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap='rainbow')
plt.title("用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类的散点图")
plt.show()
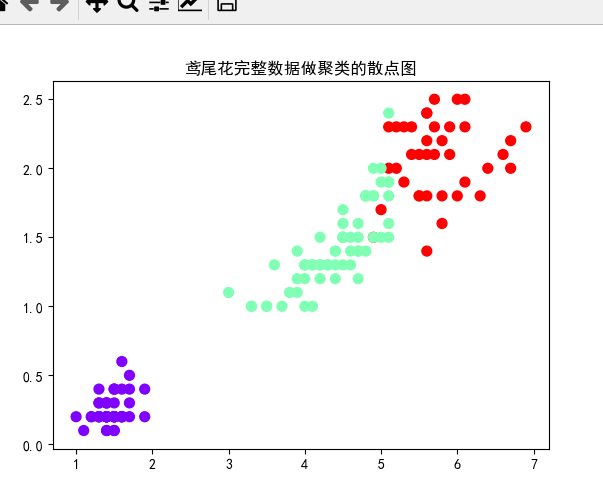
鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mpl# 指定字体,解决plot不能显示中文的问题
mpl.rcParams['font.sans-serif'] = ['SimHei']iris = load_iris()
x = iris.data
model = KMeans(n_clusters=3)
model.fit(x)
y = model.predict(x)
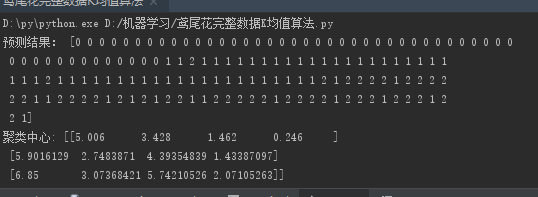
print("预测结果:", y)
kc = model.cluster_centers_
print("聚类中心:", kc)
plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap='rainbow')
plt.title("鸢尾花完整数据做聚类的散点图")
plt.show()
想想k均值算法中以用来做什么?
以上,已经详细了解并实现了K均值算法,在这部分内容中,将使用K均值算法来实现图像压缩,所谓图像压缩指的是在图像像素方面的处理。图像常用的编码方式为RGB编码,即用三基色(RED,GREEN,BLUE)表示图像颜色。每个像素由三个8位无符号二进制数(范围从0到255)表示其像素颜色,例如,一个像素的颜色可以用(220,101,25)表示。给定的图像包含这数千种颜色,通过K均值算法,可以将其颜色的数量降至16种,从而实现图像压缩。
像素处理
图像的每个像素颜色即代表训练样本,通过K均值算法寻找16种颜色代表图像中的所有像素的颜色,即也就是寻找16个聚类中心,最后,将所有的像素颜色替换为16个聚类中心所对应的颜色。
- 图像加载和预处理
对于每一个像素,可以用一个三维矩阵表示,其中,第一维和第二维表示其所在位置,第三维代表其是蓝色,红色,或者绿色。例如一个矩阵,表示53行,44列所在的像素其颜色为3.
在此过程中,需要将图像转换为的矩阵,其中,m=像素的行×列。其实现过程可以用如下代码表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号