LinkedList为什么增删快、查询慢
List家族中共两个常用的对象ArrayList和LinkedList,具有以下基本特征。
- ArrayList:长于随机访问元素,中间插入和移除元素比较慢,在插入时,必须创建空间并将它的所有引用向前移动,这会随着ArrayList的尺寸增加而产生高昂的代价,底层由数组支持。
- LinkedList:通过代价较低的在List中间进行插入和删除操作,只需要链接新的元素,而不必修改列表中剩余的元素,无论列表尺寸如何变化,其代价大致相同,提供了优化的顺序访问,随机访问相对较慢,特性较ArrayList更大,而且还添加了可以使其作为栈、队列或双端队列的方法,底层由双向链表实现。
上面的特性接触了Java开发的人都知道,初级Java工程师面试更是必问的点,至于更加深入的知识点:为什么会有这样的特性? 底层是怎么实现的?往往到这里,大部分程序员都答不出来,笔者当初面试那会也是被这里吊打,被面试官无情的嘲讽,当时的情形是这样的

当时那个臊的啊,拿回简历出了公司坐在深圳某天桥思考了许久的人生。。。。。。。。
抽空看了下LinkedList的实现,整理成博文的形式,能给自己增加理解,也希望能帮助广大码农。
LinkedList本质是一个双向链表,由一个个的Node对象组成,如下图
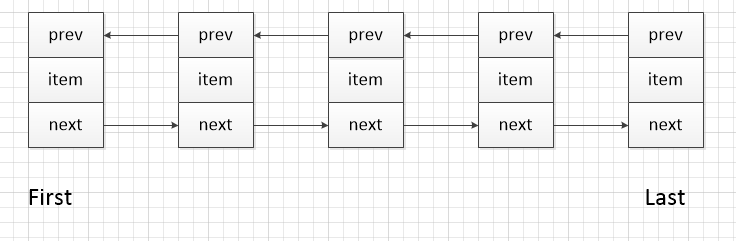
LinkedList由一个个Node组成,每一个Node持有前后节点的引用,也可以称之为指针,看下Node的结构,Node有当前元素对象、前一个节点信息、后一个节点信息三个属性,构造函数也是由这三个属性去组成,在LinkedList的添加方法中,会创建一个Node对象,持有前后节点的信息,添加到最后节点之后。
//关于Node构造函数 private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
先看下LinkedList中共的几个属性,下面三个属性分别描述LinkedList的尺寸、第一个元素、最后一个元素,这三个元素始终贯穿着在LinkedList的使用当中
//transient 保证以下几个属性不被序列化 /** * The number of times this list has been <i>structurally modified</i>. * 该字段表示list结构上被修改的次数。结构上的修改指的是那些改变了list的长度 * 大小或者使得遍历过程中产生不正确的结果的其它方式。 * */ protected transient int modCount = 0; transient int size = 0; /** * Pointer to first node. * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */ transient Node<E> first; /** * Pointer to last node. * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */ transient Node<E> last;
再看LinkedList的添加实现,可以添加为null的对象
public boolean add(E e) { linkLast(e); return true; } /** * Links e as last element. */ void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
看上面的源码可以知道,当LinkedList添加一个元素时,会默认的往LinkedList最后一个节点后添加,具体步骤为
- 获得最后一个节点last作为当前节点l
- 用当前节点l、添加参数e、null创建一个新的Node对象
- 将新创建的Node对象链接到最后节点,也就是last
- 如果当前的LinkedList为空,那么添加的node就是first,也是last
- 当前LinkedList的size+1,表示结构改变次数的对象modCount+1
整个添加过程中,系统只做了两件事情,添加一个新的节点,然后保存该节点和前节点的引用关系。
public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; }
LinkedList的删除中,会根据传递进来的参数进行null判断,因为在LinkedList的元素移除中,null和非null的处理不一样,对于nul使用==去判断是否匹配,对于非null使用.equals(Object o)去判断,至于==和equals的区别,读者自行百度。
null判断之后,传入当前节点调用unlink(E e)方法,我们可以从方法名中看出点东西,可能设计者也是为了方便读者阅读源码,可以理解为“放开链接”,也可以反映出LinkedList保存数据的方式,一个个元素相互链接而成。
E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
通过阅读上面的源码,LinkedList的删除中,也是改变节点之间的引用关系去实现的,具体逻辑整理如下:
- 如果前一个节点prev为null,即第一个节点元素,则链表first = x下一个节点;
- 如果前一个节点prev不为null,即不是第一个节点元素,则将当前节点的next赋值给prev.next,x.prev置为null,也就是当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
- 如果下一个节点next为null,即为最后一个元素,则链表last = x前一个节点;
- 如果下一个节点next不为null,即不为最后一个元素,则将当前节点的prev赋值给next.prev,同样当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
LinkedList的查询实现源码如下,
public E get(int index) { checkElementIndex(index); return node(index).item; } private void checkElementIndex(int index) { if (!isElementIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private boolean isElementIndex(int index) { return index >= 0 && index < size; } Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
通过阅读源码,我们也可以解读出LinkedList的查询逻辑
- 根据传入的index去判断是否为LinkedList中的元素,判断逻辑为index是否在0和size之间,如果在则调用node(index)方法,否则抛出IndexOutOfBoundsException;
- 调用node(index)方法,将size右移1位,即size/2,判断传入的size在LinkedList的前半部分还是后半部分
- 如果在前半部分,即index < size/2,则从fisrt节点开始遍历匹配
- 如果在后半部分,即index > size/2,则从last节点开始遍历匹配
可以看出,如果LinkedList链表size越大,则遍历的时间越长,查询所需的时间也越长。
应该可以将LinkedList的添加、删除、查询给说清楚,如果读者还有不清楚或者觉得有什么不对的地方,欢迎各位指正或者入群交流。
技术交流QQ群:579949017
或者添加个人微信:xieya0126 加入微信交流群

 浙公网安备 33010602011771号
浙公网安备 33010602011771号