
[翻译] 一个kubernetes网络简明教程[Part 1]
一个kubernetes网络简明教程[Part 1]
翻译: icebug
所有我学到的关于kubernetes网络的事情
你可能已经在kubernetes集群当中跑了一堆服务并且正在享受其带来的好处. 或者至少, 你已经计划这么干了. 虽然已经有一大堆工具可以用来安装或者管理集群, 你任然想知道这一切到底是怎么回事. 另外, 当出现故障时到哪里去寻找解决方案? 我知道, 因为我遇到过.
当然, Kubernetes刚开始使用时非常简单. 但还是让我直面它吧--它就是一只引擎盖下面的怪兽. 这里有很多可剥离的组件, 如果你想在失败面前处乱不惊, 知道如何将它们完美地组在一起工作则是一项必备技能. 其中最复杂, 也是最有挑战的一部分就是网络了.
所以我开始着手去理解网络在kubernetes当中究竟是如何工作的. 我读文档, 看演讲, 甚至翻阅了源代码, 如下是我的一些发现.
Kubernetes网络模型
在kubernetes的核心当中, Kubernetes网络有一个重要的基础设计哲学.
每一个Pod都有一个独一无二的IP.
这个Pod IP被这个Pod当中的所有容器所共享, 并且它可以从其他所有的Pod当中路由过来. 你注意到了一些“pause”字样的容器运行在你的Kubernetes节点当中吗? 它们被称为“沙盒容器”, 它们的唯一作用就是保留和占据一个被Pod当中所有容器所共享的网络命名空间(netns). 就这样, 一个Pod IP并不会随着Pod当中的一个容器的起停而改变. 这种一个Pod一个IP的模型的一个巨大的好处就是跟宿主机永远也不会有IP或者端口冲突, 我们甚至都不用管应用用的是什么端口.
有了上面的基础, Kubernetes目前唯一的需求就是这些Pod IP是可路由或者说可以被所有其他Pod访问的, 不管这些Pod运行在什么节点上.
节点内网络通信
第一步先要确保同一个节点上的Pod可以相互通信, 然后再把这个想法扩展到跨节点通信以及互联网通信等.
在每一个Kubernetes节点上, 在这里假设是一台Linux机器, 会有一个root网络命名空间(root表示基命名空间, 区别于系统当中的超级用户root) -- root netns.
主要的网络接口eth0在root netns当中.
同样的, 每一个Pod也都有它自己的netns, 有一个虚拟的以太网络接口对连接到root netns当中. 这只是一个基础的管道对, 一端连接到root netns当中, 另一端连接到Pod netns当中.

Kubernetes节点 (root命名空间)
我们把Pod这端的接口命名为eth0, 所以Pod并不知道底下的宿主机并认为自己已经设置了root netns, 另一端连接root netns的接口的命名为vnetxxx的样式.
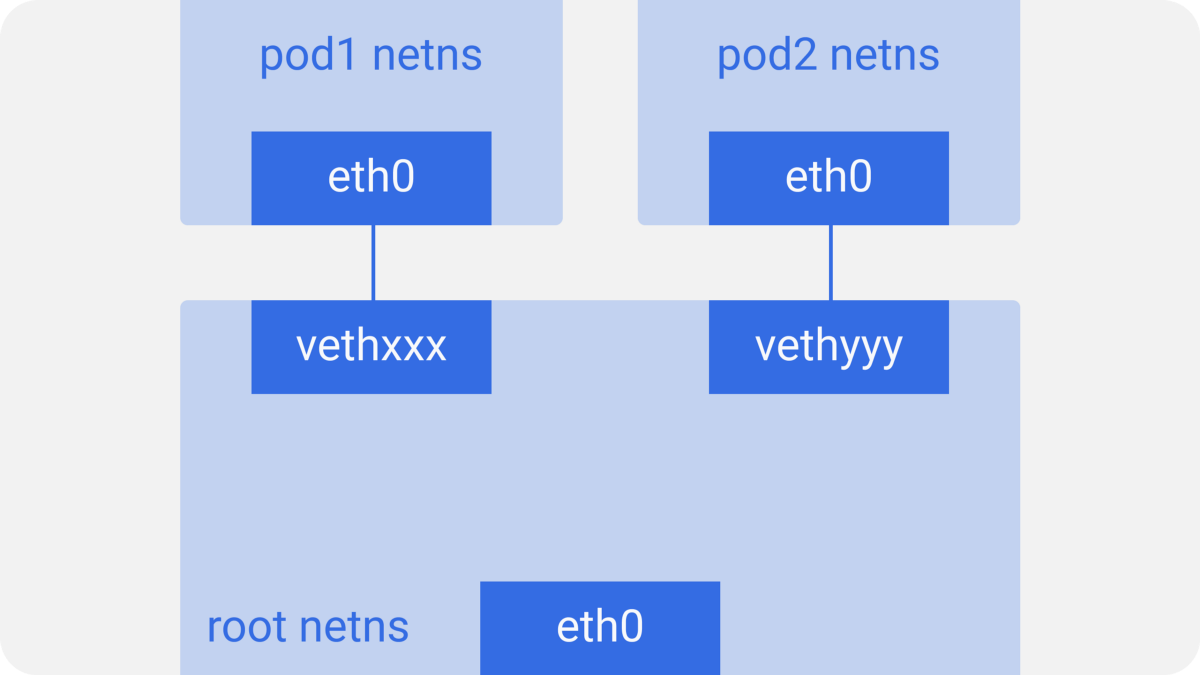
Kubernetes节点 (Pod网络命名空间)
你可以通过ifconfig命令或者ip a命令在你的节点上看到所有的接口.
这一切对于节点上的所有Pod都一样. 对于想要想要互相通信Pod, 还需要用到Linux以太网网桥cbr0, Docker用了一个相似的网桥命名为docker0. 你可以通过brctl show看到所有的网桥.
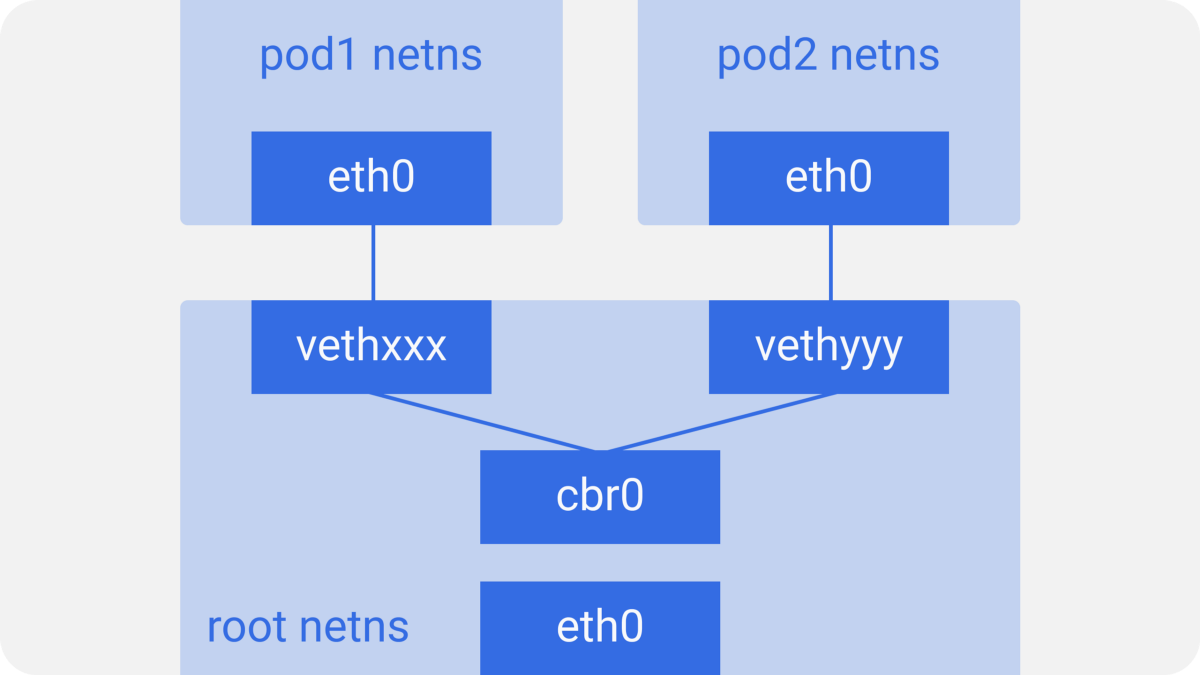
Kubernetes Node (Linux network bridge)
假设一个网络包要从Pod 1到Pod 2.
- 网络包从eth0离开Pod 1的netns并通过vnetxxx进入到root netns.
- 网络包被传到网桥cbr0, 网桥通过发送“who has this IP?”的ARP请求来发现网络包需要转发到的目的地.
- vethyyy回答到它有这个IP, 所以网桥知道应该把网络包转发到哪里.
- 网络包到达vethyyy接口, 并通过管道对进入到Pod 2的netns.

Kubernetes Node (same node pod-to-pod communication)
以上就是一个节点当中的容器是如何进行网络通信的内容. 很显然, 还有别的方式, 但这可能是最简单的方式, 并且Docker也是采用的这种方式.
节点间的网络通信
正如我前面提到的, Pod也需要在各个节点之间能够相互访问. Kubernetes并不管它是如何实现的. 我们能用L2(跨节点ARP), L3(跨节点进行IP路由 -- 像云服务提供商的路由表), overlay 网络, 甚至用信鸽. 只要能网络流量能到达另一个节点上指定的Pod, 这一切都没有关系. 每一个节点都会被分配一个独一无二的CIDR块(一个IP地址范围)用于Pod IP, 所以每一个Pod都有一个独一无二的不会和别的节点上的Pod相冲突的IP.
在大多数的情况下, 尤其是在云环境当中, 云计算提供厂商的路由表保证了网络包抵达正确的目的地. 同样的事情也能够通过在每个节点上设置正确的路由来完成. 这里还有一堆其他的网络插件用于完成这件事情.
下面我们有两个节点, 跟我们前面看到的一样, 每一个节点都含有不同的网络命名空间, 网络接口和一个网桥.
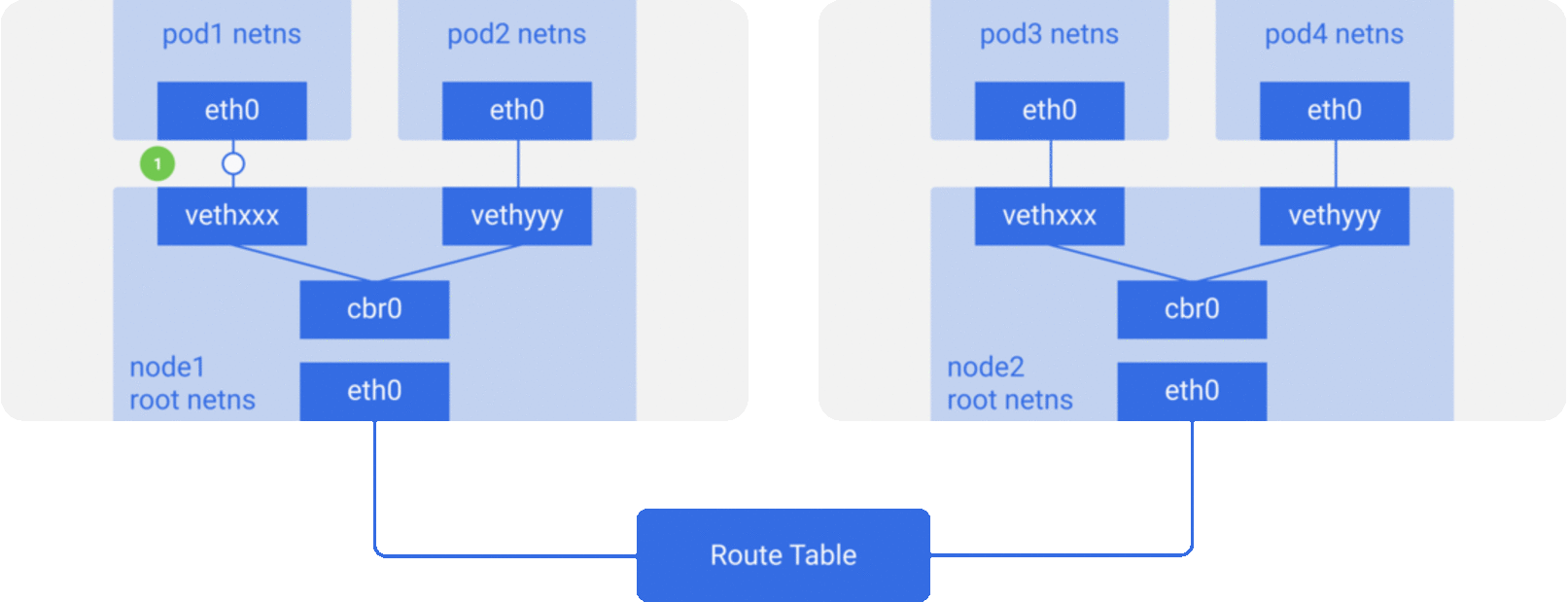
Kubernetes Nodes with route table (cross node pod-to-pod communication)
假设一个网络包从pod1到pod4(在一个不同的节点上)
-
网络包从eth0离开Pod 1的netns, 并从vethxxx进入root netns.
-
网络包被传到cbr0网桥, 通过ARP请求来寻找网络包目的地.
-
网络包从cbr0传到主网络接口eth0, 因为在这个节点上没有人有Pod 4的IP地址.
-
网络包开始离开node 1, 走上了一条出发端是Pod 1, 目的端是Pod 4的线上.
-
路由表上已经设置好了各个节点上CIDR的路由, 并且将网络包路由到CIDR块含有Pod 4 IP的节点.
-
所以网络包到达了node 2的主网络接口eth0, 虽然Pod 4不是eth0的IP, 网络包仍然被转发到cbr0, 因为节点被配置为可以进行IP转发, 节点的路由表会寻找任何匹配Pod 4 IP的路由. 然后找到cbr0作为这个节点CIDR块的目的地. 你可以通过
route -n命令查看节点的路由表, 然后会发现一条关于cbr0的路由如下: -
cbr0网桥获取到网络包, 发出一个ARP请求, 然后发现IP属于vethyyy.
-
网络包通过管道对抵达Pod4.
这是一篇关于Kubernetes网络基础的文章, 所以假如下次Kubernetes网络出现问题了, 别忘了检查那些网桥和路由表. 😉
这就是这篇文章的全部了, 在下一篇文章, 我们来看看“overlay网络是如何工作的[Part 2]”, 当pod不断地创建和删除时网络发生了什么变化, 以及流入和流出的网络流量是如何流动的.
Reference
原文: https://medium.com/@ApsOps/an-illustrated-guide-to-kubernetes-networking-part-1-d1ede3322727
译者感悟
一直想翻译一些好的英文文档和文章, 奈何惰性太强, 一直还是停留在想法阶段. 下午好友问我要不要加入Kubernetes翻译组, 这不就是自己一直想做的事情嘛, 说干就干, 然后才知道报名筛选规则至少要提交一篇自己翻译过的文章, 然后下班后找来一篇之前学习Kubernetes网络时看过的一篇文章, 零零散散花了差不多三个小时翻译了这篇文章. 第一次翻译, 可能有翻译的不太准确或者恰当的地方, 欢迎拍砖指正. 且不管能不能加入到Kubernetes翻译组, 今天算是开了个好头了.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号