Java进阶知识01 Oracle数据库,基础知识
本文知识点(目录):
1、Oracle的五大约束条件
2、在PLSQL developer中连接数据库的操作
3、Oracle的基本数据类型
4、dos命令行(连接数据库和一些简单授权操作)
5、Oracle SQL和Oracle的关系
6、创建数据库的方法(从创建数据库到创建用户,再到授权,最后到建表一些简单操作)
7、oracle基本操作语句(一些常用的dos命令行操作语句)
8、oracle操作数据表的语句【命令行操作指令】
8.1、select 子句
8.2、where 子句
8.3、order by 子句
8.4、单行函数
8.5、隐式转换
8.6、通用函数和条件判断
8.7、多行函数、group by 子句
8.8、多表查询
8.9、子查询
8.10、集合查询
8.11、Oracle分页(分页查询)
8.12、约束和表、表结构、表内数据的CRUD操作
8.13、Oracle事务
8.14、Oracle视图
8.15、Oracle序列
8.16、Oracle索引
1、Oracle的五大约束条件:
a、主键 primary key
b、外键 foreign key,
c、唯一 unique,
d、检测 check
e、非空 not null
实例运用:
-- 商品表 客户表 购物车表 /* 商品表 goods 编号gid , 名称 , 价格 ,厂商 客户表 customer 编号cid ,姓名,性别,出生日期,身份证 购物车表 purchase 商品编号,客户编号,商品数量 请建立表,要求 必须有主外键,所有的名称不能为空,价格必须大于0,身份证必须唯一,性别必须是男女默认男,商品数量必须是1到30之间 */ create table goods( gid number(8) primary key, gname varchar2(50) not null, price number(15,2) check(price >0), firm varchar2(100) ); create table customer( cid number(8) primary key, cname varchar2(30) not null, sex char(2) default '男' check (sex in ('男','女')), birth date, idcard char(18) unique );
create table purchase ( gid number(8) references goods(gid), cid number(8) references customer(cid), goodsnum number(8) check( goodsnum between 1 and 30) );
2、在PLSQL developer中连接数据库的操作
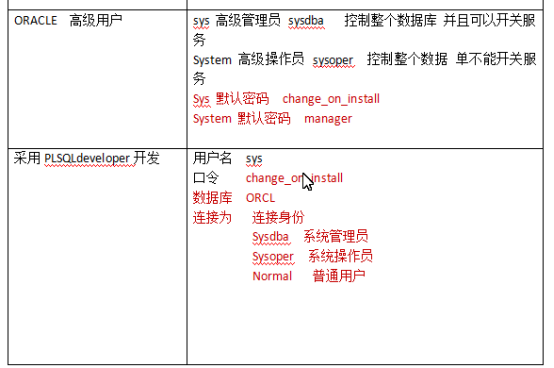
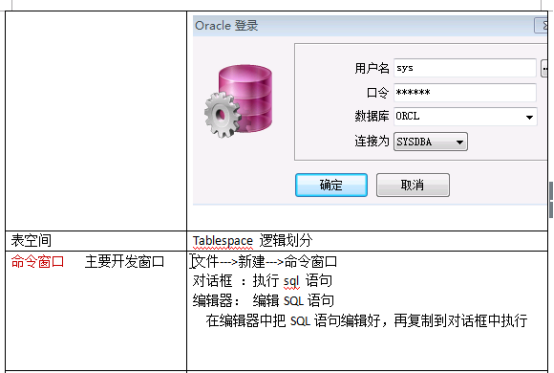


1 ---管理员登录 2 conn sys/oracle@orcl as sysdba; 3 --解锁scott用户 4 alter user scott account unlock; 5 -- scott:用户名; tiger:新密码 6 alter user scott identified by tiger; 7 --scott登录 8 conn scott/tiger@orcl as normal;
3、Oracle的基本数据类型
可参照:http://blog.csdn.net/weixin_41278231/article/details/78716417
1) 数字型 number [小数,整数]
number(5,3)表示总共5个数字,小数点后3个,最大值99.999
number(5) 表示整数 最大值99999
2) 字符型
char 定长字符 : char(10) 如果没有达到10字符就用空格补充,他所占的大小总是10字符空间
varchar2 变长字符和varchar类似 :varchar2(10) 如果没有达到10个字符长度不用空格补充
clob 大文本类型:文字很多,小说,简介,新闻内容...
blob 大文本类型: 图片,文件,压缩文件...
3)时间型
date 年月日 时分秒
timestamp 年月日 时分秒 秒可以带小数点(精确到0点几秒)
4、dos命令行
1、连接数据库 在命令提示符中运行: C:\Adminstrator> sqlplus sys/change_on_install@orcl as sysdba 或者 sqlplus sys/change_on_install as sysdba 或者 C:\Adminstrator> sqlplus / as sysdba -- 如果有多个数据库,建议用第一种方法,密码后面带上数据库名称,否则,默认连接登录的是最近一次新建的数据库。 在Oracle的PL/SQL Developer中的SQL命令行工具中运行:
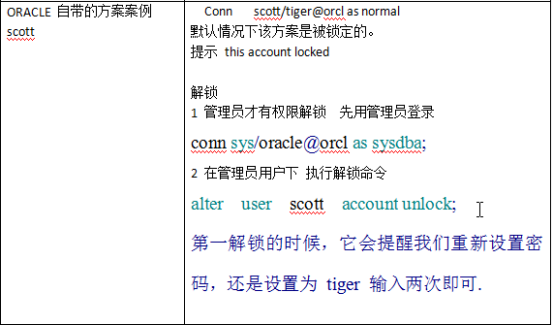
SQL> conn sys/change_on_install@orcl as sysdba; -- 解析:as SYSDBA:连接为数据库管理员。@后面的orcl是数据库名称。 SQL> conn userName/user@orcl as normal; -- 格式:conn 用户名/密码@数据库名 as normal; 解析:as normal:连接为normal(普通数据库用户). 解析:sys:用户名(超级管理员) change_on_install:(默认)密码 sysdba:连接身份 连接身份:一共三种,分别为 sysdba:系统管理员 sysoper:系统操作员 normal:普通用户 2、解锁用户: SQL> alter user scott account unlock; 修改密码: SQL> alter user scott identified by 123; -- scott:用户名; 123:新密码 3、以scott普通用户的身份进入 SQL> sqlplus scott/tiger 或者 sqlplus scott/tiger@orcl -- @跟你要连接登录的数据库名称 -- 注:oracle的关键字(比如sqlplus/as)不区分大小写,用户名(如scott/sysdba)不区分大小写,但是密码严格区分大小写. SQL> select status from v$instance; -- v$动态表开头,查看动态实例,open为启动。 SQL> shutdown immediate -- 关闭数据库 SQL> startup -- 继续启动 SQL> show parameter db_name -- 查看数据库名称 -- 查询当前连接的数据库下的SCOTT用户的默认状态 SQL> select username,account_status from dba_users where username='SCOTT'; SQL> desc emp; -- 查询表结构,emp:员工表 SQL> show user -- 查看当前已连接数据库的用户
5、Oracle SQL和Oracle的关系
(1)第四代语言:SQL【结构化查询语言,面向关系的】
第一代:机器语言
第二代:汇编
第三代:C/C++/C#/Java/VB/...
第四代:SQL
将来。。。
(2)SQL92/99 标准的四大分类
(A)DML(数据操纵语言):select,insert,update,delete
(B)DDL(数据定义语言):create table,alter table,drop table,truncate table 。。。
(C)DCL(数据控制语言):grant 权限 to scott,revoke 权限 from scott 。。。
(D)TCL(事务控制语言):commit,rollback,rollback to savepoint 。。。
(3)oracleSQL与SQL92/99的关系
SQL92/99标准,访问任何关系型数据库的标准
oracleSQL语言,只访问Oracle数据库服务器的专用语言
(4)Java技术和oracleSQL的关系
JDBC-->使用OracleSQL语法-->Oracle服务器--->orcl数据库-->表-->记录
Hibernate-->使用OracleSQL语法-->Oracle服务器
MyBatis-->使用OracleSQL语法-->Oracle服务器
=========================================================================================================================================
6、创建数据库的方法 http://www.cnblogs.com/manmanlu/p/5993449.html
1、数据库创好后,给数据表分配大小(可忽略此步)
create tablespace day48ssh datafile 'S:\OracleDB\oradata\day48ssh\day48ssh_data.DBF' size 500M;
解析:day48ssh:数据库名称
size 500M:给数据表分配的空间大小
'S:\OracleDB\oradata\day48ssh\day48ssh_data.DBF':本地路径
2、新增用户zhao/1234
创建用户:create user zhao identified by 1234;
授予用户使用表空间的权限:alter user zhao quota unlimited on day48ssh;
授予zhao用户创建session的权限,即登陆权限:grant create session to zhao;
授予zhao用户创建table的权限:grant create table to zhao;
授予zhao用户创建sequence的权限:grant create sequence to zhao;
授予zhao用户操作表空间的权限:grant resource to zhao;
或者一键授权:
grant create session,create table,create sequence,create view,resource to zhao;
3、执行建表脚本(创建表) “案例表”
create table users(
id number(5) primary key,
account varchar2(20) not null,
password varchar2(20) not null
);
创建序列:create sequence users_seq; 由于oracle没有自增长,所以...
插入一条记录:insert into users values(users_seq.nextval,'zhao','123456');
=========================================================================================================================================
调整dos命令行显示数据表的格式(简称:好看格式,就是把凌乱的格式转化为一个好看的表的形式,蓝色为表的字段名):
这个是orcl数据库下的scott用户的emp表:(number(int)类型用9作占位符,其他类型都可用a,a后面用数字长度作占位符)
col empno for 9999;
col ename for a10;
col job for a10;
col mgr for 9999;
col hiredate for a12;
col sal for 9999999;
col comm for 9999999;
col deptno for 99;
set pagesize 20;
表结构图:
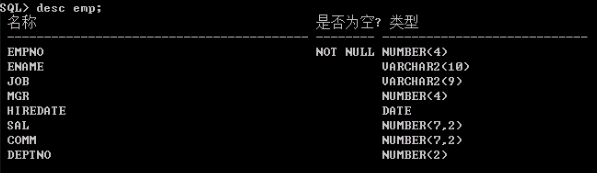
未设置前的效果图:
设置完成后,显示效果图(好看多了,不像之前那样凌乱了):
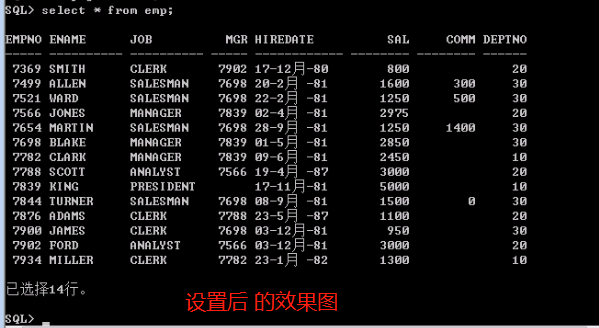
PS:假如,我要创建一个新表叫c_emp,并且c_emp中的字段和表内数据要和emp表的相同,则:
create table c_emp as select * from emp; -- 创建一个和emp表一模一样的表c_emp,只有表名不同
============================================================================================================================================
4、Oracle用户创建及权限设置
1)、普通用户scott默认是未解锁,不能直接使用,需要解锁(alter user scott account unlock;)。如果是新建的用户,则没有任何权限,必须授予权限:
grant create session to zhangsan; //授予zhangsan用户创建session的权限,即登陆权限 grant unlimited tablespace to zhangsan; //授予zhangsan用户使用表空间的权限 grant create table to zhangsan; //授予创建表的权限 grant drop table to zhangsan; //授予删除表的权限 grant insert table to zhangsan; //插入表的权限 grant update table to zhangsan; //修改表的权限 grant all to public; //这条比较重要,授予所有权限(all)给所有用户(public)
2)、oralce对权限管理比较严谨,普通用户之间也是默认不能互相访问的,需要互相授权
grant select on tablename to zhangsan; //授予zhangsan用户查看指定表的权限 grant drop on tablename to zhangsan; //授予删除表的权限 grant insert on tablename to zhangsan; //授予插入的权限 grant update on tablename to zhangsan; //授予修改表的权限 grant insert(id) on tablename to zhangsan; grant update(id) on tablename to zhangsan; //授予对指定表特定字段的插入和修改权限,注意,只能是insert和update grant alert all table to zhangsan; //授予zhangsan用户alert任意表的权限
二、撤销权限
基本语法同grant,关键字为revoke
三、查看权限
select * from user_sys_privs;//查看当前用户所有权限
select * from user_tab_privs;//查看所用用户对表的权限
四:查询/查看
查看当前的所有数据库: select * from v$database;
select name from v$database;
查看数据库结构字段:desc v$databases;
=========================================================================================================================================
************************************* oracle基本操作语句 ************************************
打开服务器 net start oracleservicebinbo 打开监听器 lsnrctl start 关闭服务器 net stop oracleservicebinbo 关闭监听器 lsnrctl stop =============================================================== 清屏: clear screen 或 host cls 退出: exit 或 quit =============================================================== 查看当前用户的角色 SQL>select * from user_role_privs; =============================================================== 查看当前用户的系统权限和表级权限 SQL>select * from user_sys_privs; SQL>select * from user_tab_privs; =============================================================== 查看当前用户的缺省表空间 SQL>select username,default_tablespace from user_users; =============================================================== 换用户 conn as sysdba sys tsinghua sqlplus "sys/tsinghua as sysdba" conn sys/zl as sysdba =============================================================== 修改表结构 alter table test modify(name not null); alter table test add(name varchar2(20)); alter table test drop column sex; alter table test set unused column sex; alter table test drop unused columns; =============================================================== 更改用户密码 sql>alter user 管理员 identified by 密码; =============================================================== 创建表空间的数据文件 sql>create tablespace test datafile 'd:oraclebinbo.dbf' size 10m; =============================================================== 创建用户 sql>create user 用户名 identified by 密码; =============================================================== bfile类型实例 创建目录 create directory tnpdir as 'c:'; 删除目录 drop directory tnpdir 授权 (读数据库目录和文件的权限) grant read on directory tnpdir to scott; 用户:scott 建表 create table bfiletest(id number(3), fname bfile); 添加数据 insert into bfiletest values(1,bfilename('TMPDIR','tmptest.java')); =============================================================== 查看用户 sql>show user =============================================================== 检查语句是否有错 show error =============================================================== 锁定用户 sql>alter user 用户名 account lock =============================================================== 解除(锁)用户 sql>alter user 用户名 account unlock =============================================================== 删除用户 sql>drop user zl; =============================================================== 给用户创建表权限 sql>grant create table to 用户名; =============================================================== 授管理员权限 sql>grant dba to 用户名; =============================================================== 给用户登录权限 sql>grant connect to 用户名 =============================================================== 给用户无限表空间权限 sql>grant unlinmited tablespace to 用户名; =============================================================== 收回权限 sql>revoke dba from 用户名; =============================================================== 查看用户下所有的表 SQL>select * from user_tables; =============================================================== 查看名称包含log字符的表 SQL>select object_name,object_id from user_objects >where instr(object_name,'LOG')>0; =============================================================== 查看某表的创建时间 SQL>select object_name,created from user_objects where object_name=upper('&table_name'); =============================================================== 查看某表的大小 SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments >where segment_name=upper('&table_name'); =============================================================== 查看放在ORACLE的内存区里的表 SQL>select table_name,cache from user_tables where instr(cache,'Y')>0; =============================================================== 再添加一个表空间的数据文件 sql>alter tablespace test add datafile 'd:oracletest1.dbf' size 10m; =============================================================== 建表
SQL>create table studen(stuno int,stuname varchar(8) not null,stubirth date default to_date('1987-5-9','YYYY-MM-DD')); 向表结构中加入一列
SQL>alter table studen add(stuphoto varchar(9)); 从表结构中删除一列
SQL>alter table studen drop column stuphoto; 修改表一列的长度
SQL>alter table studen modify(stuno number(4)); 隐藏将要删除的一列
SQL>alter table studen set unused column stuphoto; 删除隐藏的列
SQL>alter table studen drop unused columns; 向表中加入约束
SQL>alter table studen add constraint pk primary key(stuno); 删除约束
SQL>alter table studen drop constraint pk; =============================================================== 创建表 sql>create table 用户名(name varchar2(20),password varchar(20)) tablespace 空间名; =============================================================== 添加字段 sql>alter table test add(column_x char(10) not null); =============================================================== 更改字段 sql>alter table emp modify(column_x char (20)); =============================================================== 删除字段 如待删除域属于某个索引,则不允许删除操作,必须将此域先设置为NULL。 sql>alter table emp modify(column_x null); sql>update emp set column_x=null; sql>commit; sql>alter table emp drop(column_x); =============================================================== 选择表空间 sql>alter user 用户名 default tablespace test; =============================================================== 管理员删除别的用户中的表 sql>drop table 用户名.表名; =============================================================== 退出 sql>exit; 或 sql>quit; =============================================================== 默认进入 sql>sqlplus "/ as sysdba" =============================================================== 查看数据库 sql>show parameter block; =============================================================== 写大量语句用记事本,新建方式。 输入"ed"回车 保存后 输入"/"运行; =============================================================== 查询用户有多少表 sql>select * from tab;
************************************* oracle操作数据表的语句 ************************************
1 ------------------------ select子句 ------------------------ 2 3 -- 命令行窗口:scott用户连接登录orcl数据库 4 sqlplus scott/tiger@orcl 5 =============================================================== 6 -- 1、查询emp表的结构 7 desc emp; 8 -- 2、查询emp表的全部数据 9 select * from emp; 10 -- 3、查询emp表的指定数据 11 select empno,ename from emp; 12 =============================================================== 13 -- 4、select子句大小写和别名问题 14 -- Sql语句的关键字、列名、表名大小写不敏感,但是建议大写 15 select empno,ename from emp; 或 SELECT empno,ename From emp; 或 select empNO,ename FROM emp; -- 等等,都可以 16 -- 别名:用as关键字(as可以省略) 17 select empno as "编号",ename as "姓名",sal as "工资",deptno as "部门号" from emp; 18 -- 或者 19 select empno "编号",ename "姓名",sal "工资",deptno "部门号" from emp; 20 -- 注意:别名可以要双引号,也可以不要,但是不能用单引号; 21 -- 如果别名中有空格,必须要用双引号;因为在oracle中单引号表示字符串类型或者是日期类型。 22 -- 列名不能使用单引号,因为oracle认为单引号是字符串型或日期型 23 select empno as "编号",ename as 姓名,sal "月 薪" from emp; 24 =============================================================== 25 -- 5、拼接符|| 26 select ename || '的薪水是' || sal || '美元' from emp; -- 运行结果:***的薪水是***美元 27 =============================================================== 28 -- 6、去重(distinct 去除重复) 29 select distinct ename from emp; 30 =============================================================== 31 -- select子句的计算 32 select ename as "姓名",sal*12 as "年薪" from emp; -- 注意:任何一个NULL值与数字运算的结果都是NULL。 33 =============================================================== 34 -- 7、NULL的处理 35 select ename,comm+100 as comm from emp; 36 -- Oracle提供了一个函数:NVL(a,b) ——如果a的值是null,取b的值;否则就取a的值。 37 select ename,NVL(comm,0)+100 as comm from emp; -- NVL(a,b)可以小写,nvl(a,b) 38 -- 或者使用哑表来查询:dual 39 select nvl(null,10) from dual; -- 只是做个演示 40 =============================================================== 41 -- 8、显示系统时间 42 select sysdate from dual; -- 使用sysdate,显示系统当前时间,在默认情况下,oracle只显示日期,而不显示时间,比如:26-4月-15. 43 =============================================================== 44 -- 9、Oracle读(解析和执行)、写(生成).sql文件 45 spool e:/oracle-day01.sql; -- 使用spool命令,解析执行。 46 -- spool e:/oracle-day01.sql;开始,spool off;结束。 中间不管执行多少SQL语句,都将写到硬盘e:\oracle-day01.sql文件中。 47 spool off; -- 使用spool off命令,结束spool语句,并保存SQL语句到硬盘e:\oracle-day01.sql文件中。 48 @ e:/crm.sql; -- 使用@命令,将硬盘文件e:\crm.sql,读到orcl实例中,并执行文件中的sql语句。 49 =============================================================== 50 -- 10、Oracle的注释 51 使用--符号,设置单行注释 52 使用/* */符号,设置多行注释 53 54 -- 小结:其他语言的注释符号 55 html: <!-- --> 56 css:/* */ 57 js:/* */ 或 // 58 xml:<!-- --> 59 jsp:<!-- --> 60 mysql: -- 或 # 61 oracle:-- 或 /* */ 62 java:/* */ 或 // 63 properties:# 64 =============================================================== 65 -- 11、sql 和 sql plus 的小结 66 -- SQL语句的特点: 67 1)是SQL92/99的ANSI官方标准,只要按照该标准来写,在任何的关系型数据库中都可以直接执行 68 2)SQL语句的关健字不能简写,例如:select,where,from 69 3)大小写不敏感,提倡大写 70 4)能够对表数据进行增删改查操作 71 5)必须以分号结束 72 6)通常称做语句 73 74 -- SQL PLUS命令的特点: 75 1)是oracle自带的一款工具,在该工具中执行的命令叫SQLPLUS命令 76 2)SQL PLUS工具的命令中的关健字可以简写,也可以不简写,例如:col ename for a10; -- col是column的缩写 77 3)大小写不敏感,提倡大写 78 4)可以不用分号结束,也可以用分号结束(限于连接登录时,等个别指令),个人提倡:不管SQL或SQL PLUS,都以分号结束 79 5)通常称做命令,是SQL PLUS工具中的命令
1 ------------------------ where子句 ------------------------ 2 3 -- 1、查询emp表中20号部门的员工信息 4 select * from emp where deptno = 20; 5 =============================================================== 6 -- 2、查询姓名是SMITH的员工,字符串使用'',内容大小写敏感 7 select * from emp where ename = 'SMITH'; 8 =============================================================== 9 -- 3、查询1980年12月17日入职的员工,注意oracle默认日期格式(DD-MON-RR表示2位的年份) 10 select * from emp where hiredate = '17-12月-80'; 11 =============================================================== 12 -- 4、查询工资大于1500的员工 13 select * from emp where sal > 1500; 14 =============================================================== 15 -- 5、查询工资不等于1500的员工 【 != 或 <> 】 16 select * from emp where sal <> 1500; 17 select * from emp where sal != 1500; 18 =============================================================== 19 -- 6、查询薪水在1300到1600之间的员工,包括1300和1600 20 select * from emp where (sal>=1300) and (sal<=1600); 21 -- 或者 22 select * from emp where sal between 1300 and 1600; 23 =============================================================== 24 -- 7、查询薪水不在1300到1600之间的员工,不包括1300和1600 25 select * from emp where sal not between 1300 and 1600; 26 =============================================================== 27 -- 8、查询入职时间在"1981-2月-20"到"1982-1月-23"之间的员工 28 select * from emp where hiredate between '20-2月-81' and '23-1月-82'; 29 -- 注意: 30 -- 1)对于数值型,小数值在前,大数值在后 31 -- 2)对于日期型,年长值在前,年小值在后 32 =============================================================== 33 -- 9、查询20号或30号部门的员工,例如:根据ID号,选中的员工,批量删除 34 select * from emp where (deptno=20) or (deptno=30); 35 -- 或者 36 select * from emp where deptno in (30,20); 37 =============================================================== 38 -- 10、查询不是20号或30号部门的员工 39 select * from emp where deptno not in (30,20); 40 =============================================================== 41 -- 11、查询姓名以大写字母S开头的员工。 使用%表示0个,1个或多个字符 42 select * from emp where ename like 'S'; 43 -- 等价 44 select * from emp where ename = 'S'; 45 select * from emp where ename like 'S%'; 46 -- 注意: 47 -- 凡是精确查询用=符号 48 -- 凡是不精确查询用like符号,我们通常叫模糊查询 49 =============================================================== 50 -- 12、查询姓名以大写字母N结束的员工 51 select * from emp where ename like '%N'; 52 =============================================================== 53 -- 13、查询姓名第一个字母是T,最后一个字母是R的员工 54 select * from emp where ename like 'T%R'; 55 =============================================================== 56 -- 14、查询姓名是4个字符的员工,且第二个字符是I,使用_只能表示1个字符,不能表示0个或多个字符 57 select * from emp where ename like '_I__'; 58 =============================================================== 59 -- 15、插入一条姓名为'T_IM'的员工,薪水1200 60 insert into emp(empno,ename,sal) values(1111,'T_IM',1200); 61 =============================================================== 62 -- 16、查询员工姓名中含有'_'的员工,使用\转义符,让其后的字符回归本来意思【like '%\_%' escape '\'】 63 select * from emp where ename like '%\_%' escape '\'; 64 =============================================================== 65 -- 17、插入一个姓名叫'的员工 66 insert into emp(empno,ename) values(2222,''''); 67 -- Oracle中,字符型和日期型都是用单引号,别名才是用双引号。这里,边缘的两单引号是引着字符串'',而里面的两个单引号转义成一个'了。 68 =============================================================== 69 -- 18、插入一个姓名叫''的员工 70 insert into emp(empno,ename) values(2222,''''''); 71 =============================================================== 72 -- 19、查询所有员工信息,使用%或%% 73 select * from emp; 74 select * from emp where ename like '%'; 75 select * from emp where ename like '%_%'; 76 =============================================================== 77 -- 20、查询佣金为null的员工 78 select * from emp where com is null; 79 -- 注意:null不能与具体数值运算,但能与number/date/varchar2类型运算 80 =============================================================== 81 -- 21、查询佣金为非null的员工 82 select * from emp where comm is not null; 83 =============================================================== 84 -- 22、查询无佣金且工资大于1500的员工 85 select * from emp where (comm is null) and (sal>1500); 86 =============================================================== 87 -- 23、查询工资是1500或3000或5000的员工 88 select * from emp where sal in (1500,3000,5000); 89 =============================================================== 90 -- 24、查询职位是"MANAGER"或职位不是"ANALYST"的员工【方式一:使用 != 或 <>。方式二:使用not。】 91 select * from emp where (job='MANAGER') or (job<>'ANALYST'); 92 select * from emp where (job='MANAGER') or (not(job='ANALYST')); 93
1 ------------------------ order by子句 ------------------------ 2 3 -- 1、查询员工信息(编号,姓名,月薪,年薪),按月薪升序排序,默认升序,如果月薪相同,按oracle内置的校验规则排序 4 select empno,ename,sal,sal*12 5 from emp 6 order by sal asc; 7 =============================================================== 8 -- 2、查询员工信息(编号,姓名,月薪,年薪),按月薪降序排序 9 select empno,ename,sal,sal*12 10 from emp 11 order by sal desc; 12 =============================================================== 13 -- 3、查询员工信息,其中,查询年薪,并按入职日期降序排序 14 select empno,ename,sal,hiredate,sal*12 "年薪" 15 from emp 16 order by hiredate desc; 17 =============================================================== 18 -- 4、order by后面可以跟列名、别名、表达式、列号(在select子句中的列号是从1开始) 19 -- 列名: 20 select empno,ename,sal,hiredate,sal*12 "年薪" 21 from emp 22 order by hiredate desc; 23 24 -- 别名: 25 select empno,ename,sal,hiredate,sal*12 "年薪" 26 from emp 27 order by "年薪" desc; 28 29 -- 表达式: 30 select empno,ename,sal,hiredate,sal*12 "年薪" 31 from emp 32 order by sal*12 desc; 33 34 -- 列号,从1开始: 35 select empno,ename,sal,hiredate,sal*12 "年薪" 36 from emp 37 order by 5 desc; 38 =============================================================== 39 -- 5、查询员工信息,对有佣金的员工,按佣金降序排列,当order by 和 where 同时出现时,order by 在最后 40 select * 41 from emp 42 where comm is not null 43 order by comm desc; 44 =============================================================== 45 -- 6、查询员工信息,按工资降序排列,相同工资的员工再按入职时间降序排列 46 select * 47 from emp 48 order by sal desc,hiredate desc; 49 -- 注意:只有当sal相同的情况下,hiredate排序才有作用 50 =============================================================== 51 -- 7、查询20号部门,且工资大于1500,并按入职时间降序排列 52 select * 53 from emp 54 where (deptno=20) and (sal>1500) 55 order by hiredate desc; 56
1 ------------------------ 单行函数 ------------------------ 2 3 -- 单行函数:只有一个参数输入,只有一个结果输出 4 -- 多行函数或分组函数:可有多个参数输入,只有一个结果输出 5 =============================================================== 6 -- 1、测试lower/upper/initcap函数。使用dual哑表 7 select lower('www.BAIdu.COM') as lower from dual; -- 返回值:www.baidu.com 8 select upper('www.BAIdu.COM') as upper from dual; -- 返回值:WWW.BAIDU.COM 9 select initcap('www.BAIdu.COM') as initcap from dual; -- 返回值:Www.Baidu.Com //符号前面的首字母大写 10 =============================================================== 11 -- 2、测试concat/substr函数。从1开始,表示字符,不论中英文 12 select concat('hello','你好') from dual; -- 返回值:hello你好 //concat(a,b),只能跟两个参数 13 select '你好' || '世界' || 'hello' from dual; -- 返回值:你好世界hello 14 select concat(concat('你好','世界'),'hello') from dual; -- 返回值:你好世界hello 15 16 select substr('hello你好',5,3) from dual; -- 返回值:o你好 //5表示从第几个字符开始算,第一个字符为1(不是0),中英文统一处理,3表示连续截取多少个字符。 17 -- 不同于java的substring(string,m,n),m从0开始(下标),往后截取n个字符。 18 =============================================================== 19 -- 3、测试length/lengthb函数。存储时:编码方式为UTF8、GBK,一个中文占3、2个字节长度,一个英文一个字节 20 select length('hello你好') from dual; -- 返回值:7 //length()是一个长度的概念,长度为7。 21 select lengthb('hello你好') from dual; -- 返回值:9 //lengthb()是一个大小的概念,9个字节。 22 =============================================================== 23 -- 4、测试instr/lpad/rpad函数 24 select instr('helloworld','o') from dual; -- 返回值:5 //从左向右找 o 第一次出现的位置。从1开始(不是0) 25 select lpad('hello',10,'*') from dual; -- 返回值:*****hello //lpad(字段,总的大小,添充字符)左填充,即向右对齐 26 select rpad('hello',10,'#') from dual; -- 返回值:hello##### //rpad(字段,总的大小,添充字符)右填充,即向左对齐 27 -- lpad()和rpad()函数:当第二个参数小于“字段”的总长度时,从左往右截取(截取的长度为第二个参数的大小) 28 =============================================================== 29 -- 5、测试trim/replace函数 30 select trim(' ' from ' he ll ') from dual; -- 返回值:he ll //去掉两边的空格,trim(字符 from 字符串),去掉字符串首尾的指定字符 31 select trim('a' from 'aaabbbbbaaaccccaaaa') from dual; -- 返回值:bbbbbaaacccc //去掉两边的a 32 select replace('hello','l','L') from dual; -- 返回值:heLLo //字符替换 33 =============================================================== 34 -- 6、测试round/trunc/mod函数 35 select round(123.52,0) from dual; -- 返回值:124 //round(数字,从第几未开始截取),并且四舍五入 36 select round(-123.52,0) from dual; -- 返回值:-124 37 select round(123.52,1) from dual; -- 返回值:123.5 38 select round(123.52,-1) from dual; -- 返回值:120 39 select round(123.52,-2) from dual; -- 返回值:100 40 select round(-123.52,-2) from dual; -- 返回值:-100 41 42 select trunc(123.99,1) from dual; -- 返回值:123.9 //trunc(数字,从第几位开始切),切数字,不存在四舍五入的问题 43 select trunc(-123.99,1) from dual; -- 返回值:-123.9 44 select trunc(123.99,-1) from dual; -- 返回值:120 45 select trunc(-123.99,-1) from dual; -- 返回值:-120 46 select trunc(123.99) from dual; -- 返回值:123 47 48 select mod(10,3) from dual; -- 返回值:1 //mod(被除数,除数),取余数。注意:Oracle不支持%作为求余符号使用(10%3 会报错) 49 =============================================================== 50 -- 7、日期相关函数 51 select sysdate from dual; -- 返回值:22-3月 -18 //当前系统时间 52 -- round()函数作用于日期型month和year 53 select round(sysdate,'month') from dual; -- 返回值:01-3月 -18 //按照月取系统时间,返回当前月的第一天 54 select round(sysdate,'year') from dual; -- 返回值:01-1月 -18 //按照年取系统时间,返回当前年的第一天 55 -- trunc()函数作用于日期型month和year 56 select trunc(sysdate,'month') from dual; -- 返回值:01-3月 -18 //按照月取系统时间,返回当前月的第一天 57 select trunc(sysdate,'year') from dual; -- 返回值:01-1月 -18 //按照年取系统时间,返回当前年的第一天 58 =============================================================== 59 -- 8、显示昨天,今天,明天的日期;日期类型 +- 数值 = 日期类型 60 select sysdate-1 as "昨天",sysdate as "今天",sysdate+1 as "明天" from dual; 61 =============================================================== 62 -- 9、以年和月的形式显示员工的近似工龄,日期-日期=数值,假设:一年以365天计算,一月以30天计算 63 select ename "姓名",round(sysdate-hiredate,0)/365 "工龄(年)" from emp; 64 =============================================================== 65 -- 10、months_between()函数 66 select months_between('31-12月-18',sysdate) from dual; -- 精确计算到年底还有多少个月 67 select ename "姓名",months_between(sysdate,hiredate) "工龄(月)" from emp; -- 以精确月份的形式,显示员工的工龄 68 =============================================================== 69 -- 11、add_months(date,number)函数 70 select sysdate from dual; -- 返回值:22-3月 -18 //当前系统时间 71 select add_months(sysdate,1) from dual; -- 返回值:22-4月 -18 //下个月今天是多少号 72 select add_months(sysdate,-1) from dual; -- 返回值:22-2月 -18 //上个月今天是多少号 73 =============================================================== 74 -- 12、next_da(date,char)函数。返回date指定的日期之后并满足char指定条件的第一个日期 75 select next_day(sysdate,'星期三') from dual; -- 从今天开始算,下一个星期三是多少号 76 select next_day(next_day(sysdate,'星期三'),'星期三') from dual; -- 从今天开始算,下下一个星期三是多少号 77 select next_day(next_day(sysdate,'星期三'),'星期日') from dual; -- 从今天开始算,下一个星期三的下一个星期日是多少号 78 =============================================================== 79 -- 13、last_day(date)函数;求出该日期的最后一天 80 select last_day(sysdate) from dual; -- 查询本月最后一天是多少号 81 select last_day(sysdate)-1 from dual; -- 查询本月倒数第二天是多少号 82 select last_day(add_months(sysdate,1)) from dual; -- 查询下一个月的最后一天是多少号 83 select last_day(add_months(sysdate,-1)) from dual; -- 查询上一个月的最后一天是多少号 84 =============================================================== 85 注意: 86 1)日期-日期=天数(number) 87 2)日期+-天数=日期 88
1 ------------------------ 隐式转换 ------------------------ 2 3 -- 1、oracle中三大类型与隐式数据类型转换 4 1)varchar2变长/char定长 ---> number -- 例如:'123'--->123 5 2)number ---> varchar2/char -- 例如:123--->'123' 6 3)varchar2/char ---> date -- 例如:'25-4月-15'--->'25-4月-15' 7 4)date ---> varchar2/char -- 例如:'25-4月-15'--->'25-4月-15' 8 5)date和number之间不能相互转换。 9 =============================================================== 10 -- 2、oracle如何隐式转换: 11 1)=号两边的类型是否相同 12 2)如果=号两边的类型不同,尝试的去做转换 13 3)在转换时,要确保合法合理,否则转换会失败。 -- 例如:12月不会有32天,一年中不会有13月 14 =============================================================== 15 -- 3、案例分析 16 -- 3.1、查询emp表1980年12月17日入职的员工(方式一:日期隐示式转换) 17 select * from emp where hiredate = '17-12月-80'; -- 返回值:7369 SMITH CLERK 7902 17-12月-80 800 20 18 19 -- 3.2、使用to_char(日期,'格"常量"式')函数将日期转成字符串 20 select to_char(sysdate,'yyyy" 年 "mm" 月 "dd" 日 "day') from dual; -- 返回值:2018 年 03 月 22 日 星期三 21 22 -- 3.3、使用to_char(日期,'格式')函数将日期转成字符串 23 select to_char(sysdate,'yyyy-mm-dd" 今天是"day hh24:mi:ss') from dual; -- 返回值:2018-03-22 今天是星期三 15:42:05 24 -- 或者 -- Oracle中的日期格式大小写不敏感(YYYY-MM-DD HH:MI:SS 或者yyyy-mm-dd hh:mi:ss 都行,其中hh24是24小时制) 25 select to_char(sysdate,'yyyy-mm-dd" 今天是"day HH12:MI:SS AM') from dual; -- 返回值:2018-03-22 今天是星期三 03:43:32 下午 26 27 -- 3.4、使用to_char(数值,'格式')函数将数值转成字符串 28 select to_char(1234567,'$9,999,999') from dual; -- 返回值:$1,234,567 29 30 -- 3.5、使用to_char(数值,'格式')函数将数值转成字符串,显示如下格式:¥1,234 31 select to_char(1234,'$9,999') from dual; -- 返回值:$1,234 32 select to_char(1234,'L9,999') from dual; -- 返回值:¥1,234 33 34 -- 3.6、使用to_date('字符串','格式')函数,查询emp表1980年12月17日入职的员工(方式二:日期显式转换) 35 select * from emp where hiredate = to_date('1980年12月17日','yyyy"年"mm"月"dd"日"'); -- 返回值:7369 SMITH CLERK 7902 17-12月-80 800 20 36 -- 或 -- 只要to_date()函数中的两个参数的格式对应上就好 37 select * from emp where hiredate = to_date('1980#12#17','yyyy"#"mm"#"dd'); -- 返回值:7369 SMITH CLERK 7902 17-12月-80 800 20 38 -- 或 39 select * from emp where hiredate = to_date('1980-12-17','yyyy-mm-dd'); -- 返回值: 7369 SMITH CLERK 7902 17-12月-80 800 20 40 41 -- 3.7、使用to_number('字符串')函数将字符串‘123’转成数字123。这里的字符串只能包括数字 42 select to_number('123') from dual; -- 返回值:123 43 -- 注意: 44 select '123' + 123 from dual; -- 返回值:246 45 select '123' || 123 from dual; -- 返回值:123123 -- 123123是varchar2类型,即:‘123123’ 46 ===============================================================
1 ------------------------ 通用函数和条件判断 ------------------------ 2 3 -- 1、使用nvl(a,b)通用函数,统计员工年收入。 通用函数:参数类型可以是number或varchar2或date类型 4 select ename,sal*12+NVL(comm,0) from emp; 5 =============================================================== 6 -- 2、使用nvl2(a,b,c)通用函数,如果a不为NULL,取b值,否则取c值,统计员工年收入 7 select ename,sal*12+NVL2(comm,comm,0) from emp; 8 =============================================================== 9 -- 3、使用nullif(a,b)通用函数,在类型一致的情况下,如果a与b相等,返回NULL,否则返回a,比较10和10.0是否相同 10 select nullif(10,10.0) from dual; -- 返回值: 空白,什么都没有 11 select nullif(10,10) from dual; -- 返回值: 空白,什么都没有 12 select NULLIF(10,12) from dual; -- 返回值:10 13 select NULLIF(10,'10') from dual; -- 错误,类型不一致 14 =============================================================== 15 /* 4、case 表达式 16 使用SQL99标准通用语法中的case表达式,将职位是分析员的,工资加2000;职位是经理的,工资加10000;其它职位,工资加600 17 case 字段 18 when 条件1 then 表达式1 19 when 条件2 then 表达式2 20 else 表达式n 21 end 22 */ 23 select ename "姓名",job "职位",sal "涨前工资", 24 case job 25 when 'ANALYST' then sal+2000 26 when 'MANAGER' then sal+10000 27 else sal+600 28 end "涨后工资" 29 from emp; 30 /* 31 返回值: 32 姓名 职位 涨前工资 涨后工资 33 ---------- --------- ---------- ---------- 34 SMITH CLERK 800 1200 35 ALLEN SALESMAN 1600 2000 36 WARD SALESMAN 1250 1650 37 JONES MANAGER 2975 12975 38 MARTIN SALESMAN 1250 1650 39 BLAKE MANAGER 2850 12850 40 CLARK MANAGER 2450 12450 41 SCOTT ANALYST 3000 5000 42 ... 43 */ 44 =============================================================== 45 /*5、decode()函数 46 使用oracle专用语法中的decode()函数,职位是分析员的,工资加2000;职位是经理的,工资加10000;职位是其它的,工资加600 47 decode(字段,条件1,表达式1,条件2,表达式2,...表达式n) 48 */ 49 select ename "姓名",job "职位",sal "涨前工资", 50 decode(job,'ANALYST',sal+2000,'MANAGER',sal+10000,sal+600) "涨后工资" 51 from emp; -- 返回值:和上面的case表达式的结果一样;但是,比case表达式更简洁。 52 ===============================================================
1 ------------------------ 多行函数 ------------------------ 2 3 函数:oracle服务器事先写好的一段具有一定功能的程序片段,内置于oracle服务器,供用户调用 4 单行函数:输入一个参数,输出一个结果。 5 多行函数:输入多个参数,或者是内部扫描多次,输出一个结果。 6 =============================================================== 7 -- 1、count()函数 8 -- 1.1、统计emp表中员工总人数 9 select count(*) from emp; -- 返回值:14 //即:该表中一共有14数据 10 -- 注意:*号适用于表字段较少的情况,如果字段较多,扫描时间就会长,效率低,项目中提倡使用某一个非null唯一的字段,通常是主键 11 12 -- 1.2、统计公司有多少个不重复的部门 13 select count(distinct deptno) from emp; -- 返回值:3 14 15 -- 1.3、统计有佣金的员工人数 16 select count(comm) from emp; -- 返回值:4 17 select concat(count(comm),'名') from emp; -- 返回值:4名 18 =============================================================== 19 -- 2、sum()函数、avg()函数。 avg全称:average 20 -- 2.1、员工总工资,平均工资,四舍五入,保留小数点后0位 21 select sum(sal) "总工资",round(avg(sal),0) "平均工资" from emp; 22 /* 23 返回值: 24 总工资 平均工资 25 -------- --------- 26 29025 2073 27 */ 28 =============================================================== 29 -- 3、max()、min()函数 30 -- 3.1、查询员工表中最高工资、最低工资 31 select max(sal) "最高工资",min(sal) "最低工资" from emp; 32 33 -- 3.2、查询员工表中,入职最早,入职最晚的员工 34 select max(hiredate) "最晚入职时间",min(hiredate) "最早入职时间" from emp; 35 =============================================================== 36 -- 4、group by 37 -- 4.1、按部门求出该部门平均工资,且平均工资取整数,采用截断 38 select deptno "部门编号",trunc(avg(sal),0) "部门平均工资" 39 from emp 40 group by deptno; 41 /* 42 返回值: 43 部门编号 部门平均工资 44 ---------- ------------ 45 30 1566 46 20 2175 47 10 2916 48 */ 49 50 -- 4.2、查询部门平均工资大于2000元的部门 51 select deptno "部门编号",trunc(avg(sal),0) "部门平均工资" 52 from emp 53 group by deptno 54 having trunc(avg(sal),0) > 2000; 55 56 -- 4.3、按部门平均工资降序排列 57 select deptno "部门编号",trunc(avg(sal),0) "部门平均工资" 58 from emp 59 group by deptno 60 having trunc(avg(sal),0) > 2000 61 order by 2 desc; -- 2代表列号,第二2列,即:“部门平均工资” 62 63 -- 4.4.1、除10号部门外,查询部门平均工资大于2000元的部门,方式一【having deptno <> 10】 64 select deptno,avg(sal) from emp 65 group by deptno 66 having avg(sal) > 2000 67 and deptno <> 10; 68 69 -- 4.4.2、除10号部门外,查询部门平均工资大于2000元的部门,方式二【where deptno<>10】 70 select deptno,avg(sal) from emp 71 where deptno <> 10 72 group by deptno 73 having avg(sal) > 2000; -- 推荐使用这种 74 75 -- 4.5、显示部门平均工资的最大值 76 select max(avg(sal)) "部门平均工资的最大值" 77 from emp 78 group by deptno; 79 80 /* 81 group by 子句的细节: 82 1)在select子句中出现的非多行函数的所有列,【必须】出现在group by子句中. 83 select deptno,job,avg(sal) from emp; -- 出错;因为avg()是多行函数,必须使用group by分组。 84 select deptno,job,avg(sal) from emp group by deptno; -- 出错; 因为deptno、job这两个字段都是非多行函数的所有列,所以这两个字段都必须在group by子句中。 85 select deptno,job,avg(sal) from emp group by deptno,job; -- 正确 86 87 2)在group by子句中出现的所有列,【可出现可不现】在select子句中 88 select deptno,avg(sal) from emp group by deptno,job; -- 正确;group by子句中有job,select字句中,可写上job,也可以不写。 89 select deptno,job,avg(sal) from emp group by deptno,job; -- 正确 90 */ 91 92 /* 93 where和having的区别: 94 where: 95 1)行过滤器 96 2)针对原始的记录 97 3)跟在from后面 98 4)where可省 99 5)先执行 100 101 having: 102 1)组过滤器 103 2)针对分组后的记录 104 3)跟在group by后面 105 4)having可省 106 5)后执行 107 */ 108 109 /* 110 oracle中综合语法: 111 1)select子句-----必须 112 2)from子句-------必须,不知写什么表了,就写dual 113 3)where子句------可选 114 4)group by子句---可选 115 5)having子句-----可选 116 6)order by 子句--可选,如果出现列名,别名,表达式,字段 117 */ 118 ===============================================================
1 ------------------------ 多表查询 ------------------------ 2 3 -- 1、员工表emp和部门表dept的笛卡尔集(笛卡尔集表等于列数之和,行数之积;笛卡尔集表内,有些数据是不符合要求的) 4 select emp.ename,dept.dname from emp,dept; 5 -- 或者 6 select e.ename,d.dname from emp e,dept d; 7 -- 或者 8 select ename,dname from emp,dept; -- 只要你查询的字段在对方表中没有(唯一),就不需要e打点/d打点指定 9 =============================================================== 10 -- 2、使用等值连接/内连接(只能使用=号),显示员工的编号,姓名,部门名,使用表别名简化 11 select e.empno,e.ename,d.dname,d.deptno 12 from emp e,dept d 13 where e.deptno = d.deptno; 14 =============================================================== 15 -- 3、使用非等值连接(不能使用=号,其它符号可以,例如:>=,<=,<>,betwen and等),显示员工的编号,姓名,月薪,工资级别 16 select e.empno,e.ename,e.sal,s.grade 17 from emp e,salgrade s 18 where e.sal between s.losal and s.hisal; 19 20 /* 内连接查询:只能查询出符合条件的记录 21 外连接查询:既能查询出符合条件的记录,也能根据一方强行将另一个方查询出来 22 23 使用外连接,按部门10,20,30,40号,统计各部门员工人数,要求显示部门号,部门名,人数 24 比如: 25 部门号 部门名 人数 26 10 ACCOUNTING 3 27 20 RESEARCH 5 28 30 SALES 6 29 40 OPERATIONS 0 -- 这个部门没有人的话,number类型就用0代替,varchar2类型就用null代替 30 */ 31 =============================================================== 32 -- 4、使用外连接,按部门10,20,30号,统计各部门员工人数,要求显示部门号,部门名,人数 33 select d.deptno,d.dname,count(e.empno) as "人数" 34 from emp e,dept d 35 where e.deptno(+) = d.deptno 36 group by d.deptno,d.dname; -- 右外连接 37 /* 38 返回值: 39 DEPTNO DNAME 人数 40 ------ -------------- ---------- 41 10 ACCOUNTING 3 42 40 OPERATIONS 0 43 20 RESEARCH 5 44 30 SALES 6 45 */ 46 =============================================================== 47 -- 5、左外连接。 [是oracle专用的,不是SQL99规则]: 48 select d.deptno,d.dname,count(e.empno) 49 from emp e,dept d 50 where e.deptno = d.deptno(+) 51 group by d.deptno,d.dname; 52 =============================================================== 53 -- 6、右外连接。 54 select d.deptno,d.dname,count(e.empno) 55 from emp e,dept d 56 where e.deptno(+) = d.deptno 57 group by d.deptno,d.dname; 58 =============================================================== 59 -- 7、使用左外连接,按部门10,20,30,40号,统计各部门员工人数,要求显示部门号,部门名,人数,且按人数降序排列 60 select dept.deptno "部门号",dept.dname "部门名",count(emp.empno) "人数" 61 from dept,emp 62 where dept.deptno = emp.deptno(+) 63 group by dept.deptno,dept.dname 64 order by 3 desc; -- 3代表:以第三列“人数”作降序排列 65 =============================================================== 66 -- 8、使用自连接,显示"SMITH的上级是FORD",这种格式 67 select users.ename || '的上级是' ||boss.ename 68 from emp users,emp boss 69 where users.mgr = boss.empno; -- mgr是上级编号,empno是员工编号 70 =============================================================== 71 -- 9、基于上述问题(第八点),将KING的上级是“”显示出来 72 select users.ename || '的上级是' ||boss.ename 73 from emp users,emp boss 74 where users.mgr = boss.empno(+); -- KING 是老板 75 -- 注意:自连接有时候也需要用到内连接和外连接 76 ===============================================================
1 ------------------------ 子查询 ------------------------ 2 3 /* 4 子查询的作用:查询条件未知的事物 5 6 查询条件已知的问题:例如:查询工资为800的员工信息 7 查询条件未知的问题:例如:查询工资为20号部门平均工资的员工信息 8 一个条件未知的问题:可以分解为多个条件已知的问题 9 10 子查询细节: 11 1)子查询与父查询可以针对同一张表 12 2)子查询与父查询可以针对不同张表 13 3) 子查询与父查询在传参数时,数量要相同 14 4) 子查询与父查询在传参数时,类型要相同 15 5) 子查询与父查询在传参数时,含义要相同 16 */ 17 =============================================================== 18 -- 1、查询工资比WARD高的员工信息 19 -- 第一:查询WARD的工资? 20 select sal from emp where ename = 'WARD'; 21 -- 第二:查询工资比1250高的员工信息? 22 select * from emp where sal > 1250; 23 24 -- 子查询: 25 select * from emp where sal > ( 26 select sal 27 from emp 28 where ename = 'WARD' 29 ); 30 =============================================================== 31 -- 2、查询部门名为'SALES'的员工信息(方式一:子查询) 32 -- 第一:查询部门名为'SALES'的编号? 33 select deptno from dept where dname = 'SALES'; 34 -- 第二:查询部门号为30的员工信息? 35 select * from emp where deptno = 30; 36 37 -- 子查询: 38 select * 39 from emp 40 where deptno = ( 41 select deptno 42 from dept 43 where dname = 'SALES' 44 ); 45 =============================================================== 46 -- 3、查询部门名为'SALES'的员工信息(方式二:多表查询) 47 select emp.* 48 from dept,emp 49 where (dept.deptno=emp.deptno) and (dept.dname='SALES'); 50 51 -- 查询每个员工编号,姓名,部门名,工资等级(三表查询,这三张表并无外健关联) 52 select e.empno,e.ename,d.dname,s.grade 53 from emp e,dept d,salgrade s 54 where (e.deptno=d.deptno) and (e.sal between s.losal and s.hisal); 55 =============================================================== 56 -- 4、查询工资最低的员工信息。(单行子查询,使用=号) 57 select * 58 from emp 59 where sal = ( 60 select min(sal) 61 from emp 62 ); 63 =============================================================== 64 -- 5、查询部门名为'ACCOUNTING'或'SALES'的员工信息。(多行子查询,使用in关键字) 65 select * 66 from emp 67 where deptno in ( 68 select deptno 69 from dept 70 where dname in ('ACCOUNTING','SALES') 71 ); 72 =============================================================== 73 -- 6、查询工资比20号部门【任意any】一个员工工资【低<】的员工信息。(多行子查询,使用any关键字) 74 select * 75 from emp 76 where sal < any ( 77 select sal 78 from emp 79 where deptno = 20 80 ); 81 =============================================================== 82 -- 7、查询工资比30号部门【所有all】员工【低<】的员工信息。(多行子查询,使用all关键字) 83 select * 84 from emp 85 where sal < all ( 86 select sal 87 from emp 88 where deptno = 30 89 ); 90 /* 91 单行子查询:子查询只会返回一个结果,例如:800,父查询用 =、<>、>=、<= 这些符号来比较 92 多行子查询:子查询会返回多于一个结果,例如:30,20,父查询用 in、any、all 这些符号来比较 93 */ 94 ===============================================================
1 ------------------------ 集合查询 ------------------------ 2 3 -- 1、使用并集运算,查询20号部门或30号部门的员工信息 4 select * from emp where deptno = 20 5 union 6 select * from emp where deptno = 30; 7 /* 8 注意: 9 union:二个集合中,如果都有相同的,取其一 10 union all:二个集合中,如果都有相同的,都取 11 取并集时,两个子表的结构(字段含义及其顺序)必须完全一致。 12 select * from emp 13 union 14 select * from copy_emp; -- emp表和copy_emp表的结构、表内的数据一模一样。唯一不同的是copy_emp表插入了一条数据 用于作并集查询时,体现不同之处。 15 */ 16 =============================================================== 17 -- 2、使用交集运算[intersect] 18 -- 2.1、查询工资在1000-2000和1500-2500之间的员工信息(方式一) 19 select * from emp where sal between 1000 and 2000 20 intersect 21 select * from emp where sal between 1500 and 2500; -- 即:1500到2000之间的 22 23 -- 2.2、用where行过滤,查询工资在1000-2000和1500-2500之间的员工信息(方式二) 24 select * 25 from emp 26 where (sal between 1000 and 2000) and (sal between 1500 and 2500); 27 =============================================================== 28 -- 3、使用差集运算[minus] 29 -- A-B = A-AnB 30 -- 3.1、查询工资在1000-2000,但不在1500-2500之间的员工信息(方式一) 31 select * from emp where sal between 1000 and 2000 32 minus 33 select * from emp where sal between 1500 and 2500; 34 35 -- 3.2、使用where行过滤,查询工资在1000-2000,但不在1500-2500之间的员工信息(方式二) 36 select * 37 from emp 38 where (sal between 1000 and 2000) and (sal not between 1500 and 2500); 39 =============================================================== 40 -- 4、集合查询的细节: 41 -- 4.1、集合操作时,必须确保集合列数是相等 42 select empno,ename,sal,comm from emp where deptno = 20 -- 多了一列,和下面的查询 列数不相等 43 union 44 select empno,ename,sal from emp where deptno = 30; -- 错 45 46 -- 4.2、集合操作时,必须确保集合列类型对应相同 47 select empno,ename,sal,comm from emp where deptno = 20 -- 两条语句,列数相等,但是,类型不相等,comm是number类型,hiredate是date类型 48 union 49 select empno,ename,sal,hiredate from emp where deptno = 30; -- 错 50 51 -- 4.3、A union B union C = C union B union A 52 -- Union的两个子表的先后顺序不影响结果(顺序可能不一致) 53 select * from emp where deptno = 10 54 union 55 select * from emp where deptno = 20 56 union 57 select * from emp where deptno = 30; 58 59 -- 4.4、当多个集合操作时,结果的列名由第一个集合列名决定 60 select empno "编号",ename "姓名",sal "薪水" from emp where deptno = 20 61 union 62 select empno,ename,sal from emp where deptno = 10; 63 /* 64 当多表查询,子查询,集合查询都能完成同样任务时,按如下优化方案选择: 65 多表查询--->子查询--->集合查询 66 */ 67 ===============================================================
1 ------------------------ 分页查询 ------------------------ 2 3 -- 1、什么是rownum,有何特点 4 -- 1)rownum是oracle专用的关健字 5 -- 2)rownum与表在一起,表亡它亡,表在它在 6 -- 3)rownum在默认情况下,从表中是查不出来的 7 -- 4)只有在select子句中,明确写出rownum才能显示出来,从1开始 8 -- 5)rownum是number类型,且唯一连续 9 -- 6)rownum最小值是1,最大值与你的记录条数相同 10 /* 7)rownum也能参与关系运算 11 rownum = 1 有值 12 rownum < 5 有值 13 rownum <=5 有值 14 rownum > 2 无值 15 rownum >=2 无值 16 rownum <>2 有值 与 rownum < 2 相同 17 rownum = 2 无值 18 */ 19 -- 8)基于rownum的特性,我们通常rownum只用于 < 或 <= 关系运算 20 =============================================================== 21 -- 2、显示emp表中3-8条记录(方式一:使用集合减运算) 22 select rownum "伪列",emp.* from emp where rownum <= 8 23 minus 24 select rownum,emp.* from emp where rownum <= 2; 25 =============================================================== 26 -- 3、显示emp表中3-8条记录(方式二:使用子查询,在from子句中使用,重点) 27 select xx.* 28 from (select rownum as ids,emp.* from emp where rownum <= 8) xx 29 where ids > 2; 30 -- 注意:在子查询中的别名,不可加""引号 31 =============================================================== 32 -- 4、显示emp表中5-9条记录 33 select yy.* 34 from (select rownum as ids,emp.* from emp where rownum <=9 ) yy 35 where ids >= 5; 36 -- 注意:在项目中,from后台可能有真实表名,也可能用子查询看作的表名,同时真实表和子查询看作的表要做连接查询 37 =============================================================== 38 -- 5、MySQL分页 使用关键字:limit 39 -- 每页显示10条数据,查询第一页和第二页的数据 40 select * from 表名称 limit 0,10; -- 第一页,第1到第10条数据。 41 select * from 表名称 limit 10,20; -- 第二页,第11到第20条数据。注意:MySQL 是从0开始(下标) 42 ===============================================================
1 ------------------------ 约束、表、表结构和表内数据的CRUD操作 ------------------------ 2 3 /* 4 Oracle的五大约束条件: 5 a、主键 primary key 6 b、外键 foreign key, 7 c、唯一 unique, 8 d、检测 check 9 e、非空 not null 10 */ 11 12 -- 1、对数据的CRUD操作 13 -- 1.1、创建用户表users(id整型/name字符串/birthday日期/sal整型,默认今天) 14 create table users( 15 id number(5) primary key, 16 name varchar2(8) not null unique, 17 sal number(6,2) not null, 18 birthday date default sysdate 19 ); 20 -- 创建序列 21 create sequence users_seq; -- 由于Oracle没有自增一说,所以要借助序列来实现自增长。(这里只是简单演示,所以序列也就简单的创建) 22 =============================================================== 23 -- 1.2、删除users表 24 drop table users; -- 此处的删除users表,并不是真正删除了,而是把users放入了回收站,和window的删除一样 25 =============================================================== 26 -- 1.3、查询回收站中的对象 27 show recyclebin; 28 =============================================================== 29 -- 1.4、闪回,即:将回收站删除的对象还原 30 flashback table 表名 to before drop; -- 还原之前删除的对象 31 flashback table 表名 to before drop rename to 新表名; -- 还原之前删除的对象,并将它换个新名字 32 =============================================================== 33 -- 1.5、彻底删除users表 34 drop table users purge; 35 =============================================================== 36 -- 1.6、清空回收站 37 purge recyclebin; 38 =============================================================== 39 -- 1.7、查询当前用户下所有表 40 select * from tab; 41 -- 1.7.1、查询users表中所有数据 42 select * from users; 43 =============================================================== 44 -- 1.8、修改表名称。 格式:alter table 原表名 rename to 新表名; 45 alter table users rename to users2; 46 /* 47 Oracle数据库的常用类型: 48 number:相当于MySQL/Java中的int类型。 49 varchar2:相当于MySQL中的varchar类型,Java中的String类型 50 date:时间类型。默认格式为:'27-5月-18' 51 CLOB【Character Large OBject】:大文本对象,即超过65565字节的数据对象,最多存储4G 52 BLOB【Binary Large OBject】:大二进制对象,即图片,音频,视频,最多存储4G 53 */ 54 =============================================================== 55 -- 2、对表结构的CRUD操作 56 -- 2.1、为users表增加image列。 格式:alter table 表名 add 列名 类型(宽度) 57 alter table users add image varchar2(20); 58 =============================================================== 59 -- 2.2、修改imgae列的长度为30个字节。 格式:alter table 表名 modify 列名 类型(宽度) 60 alter table users modify image varchar2(30); 61 =============================================================== 62 -- 2.3、删除image列。 格式:alter table 表名 drop column 列名 63 alter table users drop column image; 64 =============================================================== 65 -- 2.4、重名列名image为imagepath。 格式:alter table 表名 rename column 原列名 to 新列名 66 alter table users rename column image to imagepath; 67 =============================================================== 68 -- 2.5、将users表重命名user。 格式:rename 原表名 to 新表名 69 rename users to new_users; 70 -- 注意:修改表字段(结构)时,不会影响表中原有的数据 71 =============================================================== 72 -- 2.6、查询表结构(字段的详细信息)。 格式:desc 表名称; 73 desc users; 74 =============================================================== 75 -- 3、java连接oracle数据库 76 private static String driver = "oracle.jdbc.driver.OracleDriver"; //访问oracle服务器的驱动名称 77 private static String url = "jdbc:oracle:thin:@127.0.0.1:1521:orcl"; //访问oracle服务器的连接字串,其中127.0.0.1可用localhost(本地)代替 78 private static String username = "scott"; //访问orcl数据库的用户名 79 private static String password = "tiger"; //访问orcl数据库的密码 80 =============================================================== 81 -- 4、表内数据的CRUD操作 82 /* 83 SQL92/99标准的四大类: 84 DML:select、insert、update、delete 85 DDL:create table、alter table、drop table、truncate table 86 DCL:grant select any table to scott、revoke select any table from scott 87 TCL:commit、rollback、savepoint to 回滚点 88 */ 89 90 -- 4.1、添加,向users表中数据。 格式:insert into 表名 values(全部字段); 或者 insert into 表名(个别字段) values(对应的个别字段); 91 insert into users values(users_seq.nextval,'张三',2000,sysdate); -- sysdate可以不写,因为默认就是sysdate,可上面的建表脚本 92 -- 或者 93 insert into users(id,name) values(users_seq.nextval,'李四'); 94 -- 批量插入 95 insert into users select * from copy_users where sal = 2000; -- 将copy_users表中所有sal=2000元的用户,复制到users表中 96 =============================================================== 97 -- 4.2、使用&占位符,动态输入值,&可以运用在任何一个DML语句中,在values子句中使用,例如:'&name'和&sal等 98 insert into users values(&id,'&name','&sal','&birthday'); -- 回车后,每个值都需要一个一个的输入 99 -- 注意:&是sqlplus工具提供的占位符,如果是字符串或日期型要加' '符,数值型无需加' '符 100 =============================================================== 101 -- 4.3、使用&占位符,动态输入值,&可以运用在任何一个DML语句中,在from子句中使用 102 select * from &table; 103 =============================================================== 104 -- 4.4、删除users表中的所有记录 105 delete from users; 106 -- 删除无工资的用户 107 delete from users where sal is null; 108 =============================================================== 109 -- 4.5、修改,将'张三'的工资增加20% 110 update users set sal = sal*1.2 where name = upper('张三'); 111 =============================================================== 112 -- 4.6查询users表中的所有数据 113 select * from users; 114 115 /* 116 drop table 和 truncate table 和 delete from 区别: 117 drop table 118 1)属于DDL 119 2)可回滚 120 3)不可带where 121 4)表内容和结构删除 122 5)删除速度快 123 124 truncate table 125 1)属于DDL 126 2)不可回滚 127 3)不可带where 128 4)表内容删除 129 5)删除速度快 130 131 delete from 132 1)属于DML 133 2)不可回滚 134 3)可带where 135 4)表结构在,表内容要看where执行的情况 136 5)删除速度慢,需要逐行删除 137 */ 138 ===============================================================
1、概念
什么叫做事务? 答:是不可分割的子操作形成的一个整体,该整体要么全部执行成功,要么全部失败。
为什么要用事务? 答:如果不使用事务的话,就会出现致命的操作异常。
事务放在哪一层? 答:业务层
只针对DML(数据操纵语言)操作:select、delete、update、insert
(1)Oracle的事务提交
显式提交:commit()
隐藏提交:sqlplus中执行exit、DDL、DCL
提交——从事务的开始到提交的中间内容、提交到oracle数据库中的DBF二进制文件。
(2)Oracle的事务回滚
显式回滚:rollback()
隐藏回滚:死机、断电、关闭窗口(sqlplus工具)
(3)回滚点
在操作之间设置的一个标志位,用来回滚。
(4)回滚点的使用
savepoint 回滚点
rollback to savepoint 回滚点
Oracle的事务提交或回滚之后,原来的回滚点已经无效。
Oracle的事务能够回滚,是因为oracle提供了一个实例机制。
2、jdbc 事务
1 try{ 2 connection.setAutoCommit(false);//开启事务 3 ...... 4 connection.commit();//try的最后提交事务 5 } catch() { 6 connection.rollback();//回滚事务 7 }
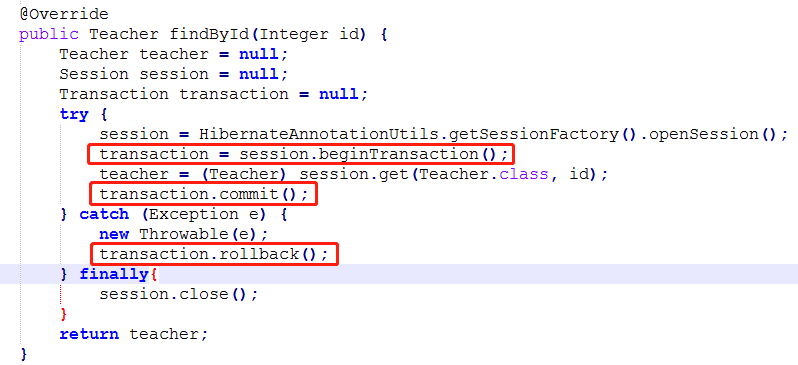
3、Hibernate 事务
4、Spring 事务
比较经典的是声明式事务管理
可参考(看下面的实例):https://www.cnblogs.com/myseries/p/10834172.html
5、MySQL 事务
start transaction;
可参考(看下面的实例):https://www.cnblogs.com/develop-SZT/p/10339138.html
6、事务的隔离级别
6.1、MySQL 的隔离级别
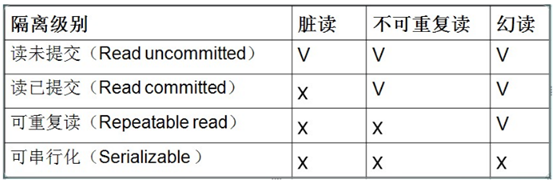
6.2、Oracle中支持Read Committed(默认)和Serializable两种。
设置隔离级别的方法:set transaction isolation level serializable;
可这样演示:两个用户同时删除emp表中的’SISI’这个员工信息,会有什么后果?
答:只有一个用户会删除成功,在先操作的用户,还没有提交的情况下,另外一个用户只能等待。
1、概念
视图是一个虚表;视图建立在已有的表基础,视图赖以建立的这个数据表称为基表。
向视图提供数据内容使用select语句,可以将视图理解为存储起来的select语句。
视图向用户提供了基表数据的另外一个表现形式。
视图只是一种逻辑上的概念,并没有存储真正的数据,真正的数据还是存储在基表中。
程序员对视图的操作,最终还是转换成对基表的操作。
一个数据表可以没有视图,也可以有一个或多个视图。
2、使用场景
不希望用户访问数据表的全部字段或全部数据,只想看到其中的部分价值信息,此时可以使用视图。银行、电信、证券、金属、军事、航天等等领域。
需要简化sql的查询过程,或提供sql的执行效率时,可以适当使用视图。
3、视图作用
a.限制数据访问
b.简化复杂查询
c.提供数据的相互独立
d.同样的数据,以不同的形式显示
4、视图的简单操作
(1)创建:
默认情况下,普通用户没有创建视图的权限。需要由sysdba授予权限:
(以sysdba的身份登录)grant create view to scott;
如果想撤销权限:(以sysdba的身份登录)revoke create view from scott;
1 1)基于emp表的所有列,创建一个视图 2 create view emp_view_1 3 as 4 select * from emp; 5 2)基于指定列创建视图 6 create view emp_view_2 7 as 8 select ename “姓名”,deptno,sal,sal*12 “年薪” from emp; 9 3)查询emp表,求出部门的最低工资、最高工资、平均工资,等方式创建视图 10 create view emp_view_3 11 as 12 select deptno “部门”,min(sal) “最低工资”,max(sal) “最高工资”,avg(sal) “平均工资” from emp group by deptno;
(2)修改:
1 -- 修改emp_view_4(id,name,salary,annual,income)视图。 格式:create or replace view 视图名 as 子查询 2 create or replace view emp_view_4(id,name,salary,annual,income) 3 as 4 select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0)+100 "年收入" 5 from emp;
(3)删除:
1 -- 删除emp_view_4视图中某一条记录(以id=2222为例) 2 delete from emp_view_4 where id = 2222; 3 -- 注意:视图默认是可以删除的(readonly=false),如果在创建视图时指定了不可删除(readonly),那么不能执行删除。 4 5 create view emp_view_5(id,name,salary,annual,income) 6 as 7 select empno,ename ,sal,sal*12,sal*12+NVL(comm,0) 8 from emp 9 with read only; -- 设置了只读 10 -- 此时执行删除delete from emp_view_5 where id=2222会失败。
5、问答
Q1:删除视图中(某一条或部分)的记录,是否会影响基表?
答:会
Q2:删除视图中的全部记录,是否会影响基表?
答:会
Q3:drop(删除)视图时,是否会影响基表?
答:不会
Q4:删除视图是否会进入回收站?
答:不会
Q5:删除基表,视图是否存在?
答:不存在
Q6:删除基表后,通过回收站闪回后,视图是否又存在了?
答:是
1、概念
类似于与MySQL中的auto increment自增长机制,但是Oracle中无自增长机制。
Oracle会提供一个产生唯一数(number类型)的机制。
通常用在表的主键。
序列保证唯一,但是不保证连续。rownum从1开始,总是连续。
序列值一般放在内存,取之较快。
2、为什么不用rownum作为主键?
答:rownum不能唯一标示某一行。
3、序列的价值
为表做主键,唯一标识表中每一条记录。
4、序列的使用
1 -- 创建序列:create sequence 序列名; 2 create sequence dept_seq; 3 4 -- 删除序列:drop sequence 序列名; 5 drop sequence dept_seq; 6 7 -- 查看序列的当前值currval和下一个值nextval。(第一次使用序列时,不能使用currval) 8 select dept_seq.nextval from dual; 9 select dept_seq.currval from dual; 10 11 -- 使用序列往表中插入一条记录。 12 insert into dept values(dept_seq.nextval,’IT’,’XINYU’); 13 14 -- 修改dept_seq序列increment by 10(步长默认为1),默认start with 1 15 alter sequence dept_seq increment by 10; 16 -- 修改dept_seq序列的start with 2(无法修改)。 17 18 -- 为某个表设置序列之后,依然能够手工插入主键。 19 insert into dept values(50,’hhhhh’,’nanchang’); 20 21 -- 删除表,不影响已经创建的序列。 22 -- 删除序列,不影响表。
序列的详细操作,可参考:https://www.cnblogs.com/dshore123/p/8269537.html
1、概念:
是一种快速查询表内容的机制。运用在表中的某个/某些字段上,但是存储是,独立于表之外。
2、索引的意义:
通过指针加速Oracle服务器的查询速度;通过rowid快速定位数据,减少磁盘的I/O,rowid是Oracle中唯一确定每一张表不同记录的唯一身份证。
3、rowid的特点:
位于每个表中,但是表面上看不到。
只有在select语句中可以查询到。
rowid与每一张表绑定在一起,如果表已经不存在那么对应的rowid就不存在了;不同的表rowid必须不同/唯一。
rowid是18位大小的字母和数字组成,唯一代表某一条记录在DBF文件中的位置。
rowid是联系表和DBF文件的桥梁。
4、创建索引的场景:
经常进行select操作时
表很大(字段多、记录多),表内容分布的范围广
列名经常在where子句或连接条件中
5、不需要创建索引的场景:
表经常进行insert/update/delete操作
表很小
列名不经常出现,或很少用于where的连接条件中
6、实例:
1 (1)单列索引: 2 -- 为dept表的deptno字段创建一个索引(单列索引):create index 索引名 on 表名(字段) 3 create index dept_deptno_index on dept(deptno); 4 (2)多列索引、联合索引 5 create index deptno_dname_index on dept(deptno,dname); 6 drop index deptno_dname_index; -- 删除索引 7 -- 注意:为某个/某些字段创建索引后,根据这个/这些字段查询时,效率会提高。 8 9 -- 查询当前出问题的列是否已经被哪个索引占用了: 10 select * from user_ind_columns where table_name = '你的大写表名' 11 and column_name = '大写字段名';
|
原创作者:DSHORE 作者主页:http://www.cnblogs.com/dshore123/ 原文出自:http://www.cnblogs.com/dshore123/p/8622757.html 版权声明:欢迎转载,转载务必说明出处。(如果本文对您有帮助,可以点击一下右下角的 推荐,或评论,谢谢!) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号