Using Parse Date Functions in R
Introduction
In daily data analysis, we often face table has date columns. In different data sources, the format of date can be very different. This will create some trouble for us.
For example, in one data source, date is recorded as a text "Year-Month-Day", but in other source it can also be "Month/Day/Year". In some other data source, date is recorded as datetime but the time part is all zero. In Execl, data source has a unique date format, which makes it a little more complex to convert.
In this article, we will discuss how to change date into a unity and clean format.
Parse Date Functions
If your data is readed from a csv file, most often you will have date in text. Below we define three variables in text to represent date and discuss them. But if you want to handle a column of date, you can still use these functions all the same.
date1 <- "2022-03-03" date2 <- "Mar 3, 2022" date3 <- "March 3, 2022"
Base R is not so popular these days, but in this problem as.Date()
as.Date(date1) # [1] "2022-03-03" as.Date(date2, format = "%b %d, %Y") # [1] "2022-03-03" as.Date(date3, format = "%B %d, %Y") # [1] "2022-03-03"
Symbols like %b, %d, %Y are placeholders, which represent those parts are valid date infomation.
For example, %Y means this part is a 4-digits number year. %d means this part is a 2-digits/ 1-digit number day. %b means this part is month in short. %B means this part is month in full name.
You can look all of them up in ?strptime
readr is a part of tidyverse. It has a function called parse_date()
parse_date(date1) # [1] "2022-03-03" parse_date(date2, format = "%b %d, %Y") # [1] "2022-03-03" parse_date(date3, format = "%B %d, %Y") # [1] "2022-03-03"
Like as.Date(), parse_date() also has a argument called format =. We can use it with %placeholder to build a personal style for R to parse the date.
lubridate is a standalone date and datetime library. It has a function called as_date() which is more robust than Base R as.Date(). Also, it has a family of functions called ymd()/ mdy()
as_date(date1, format = "%Y-%m-%d") # [1] "2022-03-03" as_date(date2, format = "%b %d, %Y") # [1] "2022-03-03" as_date(date3, format = "%B %d, %Y") # [1] "2022-03-03" ymd(date1) # [1] "2022-03-03" mdy(date2) # [1] "2022-03-03" mdy(date3) # [1] "2022-03-03"
Reading Excel in R will use readxl library. It has a function called read_excel(). But it is always a little more complex than reading a csv file. This is because Excel has it's own data type and read_excel() function cannot guess their types very perfect.
Most often I will first read it by argument col_type = "text", which means read all column as they are all text string. After that I can manually specify each column's type.
For example, we have a excel table like this:
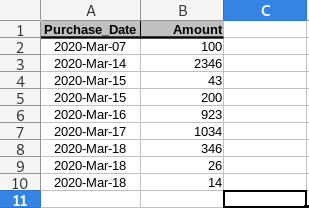
This is what I will do:
file <- list.files(".", pattern = ".xlsx", full.names = TRUE)
file
# [1] "./example.xlsx"
sales <- readxl::read_excel(file, col_types = "text")
sales
# A tibble: 9 × 2
Purchase_Date Amount
<chr> <chr>
1 43897 100
2 43904 2346
3 43905 43
4 43905 200
5 43906 923
6 43907 1034
7 43908 346
8 43908 26
9 43908 14
Now we can see the date column of Purchase_Date is read as a text of number.
There are two options below:
1. Use col_types = argument and specify the date column as date
sales <- readxl::read_excel(file, col_types = c("date", "text"))
sales
# A tibble: 9 × 2
Purchase_Date Amount
<dttm> <dbl>
1 2020-03-07 00:00:00 100
2 2020-03-14 00:00:00 2346
3 2020-03-15 00:00:00 43
4 2020-03-15 00:00:00 200
5 2020-03-16 00:00:00 923
6 2020-03-17 00:00:00 1034
7 2020-03-18 00:00:00 346
8 2020-03-18 00:00:00 26
9 2020-03-18 00:00:00 14
Now we can use ymd()
sales %>% mutate(Purchase_Date = ymd(Purchase_Date)) # A tibble: 9 × 2 Purchase_Date Amount <date> <dbl> 1 2020-03-07 100 2 2020-03-14 2346 3 2020-03-15 43 4 2020-03-15 200 5 2020-03-16 923 6 2020-03-17 1034 7 2020-03-18 346 8 2020-03-18 26 9 2020-03-18 14
2.
By microsoft's document(https://docs.microsoft.com/en-US/office/troubleshoot/excel/1900-and-1904-date-system), Excel has a date called 1900-date-system. It treats 1900-01-01 as numeric 1, each day later will plus 1 on it.
Now we can back to as.Date() or as_date() and use it's argument origin =
sales <- readxl::read_excel(file, col_types = "text") sales # A tibble: 9 × 2 Purchase_Date Amount <chr> <chr> 1 43897 100 2 43904 2346 3 43905 43 4 43905 200 5 43906 923 6 43907 1034 7 43908 346 8 43908 26 9 43908 14 sales %>% mutate(Purchase_Date = as.Date(as.numeric(Purchase_Date), origin = "1899-12-30")) # A tibble: 9 × 2 Purchase_Date Amount <date> <chr> 1 2020-03-07 100 2 2020-03-14 2346 3 2020-03-15 43 4 2020-03-15 200 5 2020-03-16 923 6 2020-03-17 1034 7 2020-03-18 346 8 2020-03-18 26 9 2020-03-18 14 sales %>% mutate(Purchase_Date = as_date(as.numeric(Purchase_Date), origin = "1899-12-30")) # A tibble: 9 × 2 Purchase_Date Amount <date> <chr> 1 2020-03-07 100 2 2020-03-14 2346 3 2020-03-15 43 4 2020-03-15 200 5 2020-03-16 923 6 2020-03-17 1034 7 2020-03-18 346 8 2020-03-18 26 9 2020-03-18 14

 浙公网安备 33010602011771号
浙公网安备 33010602011771号