
多级缓存-记录
好久没写过博客了
今天记录一下今天的学习内容
多级缓存的主要原理
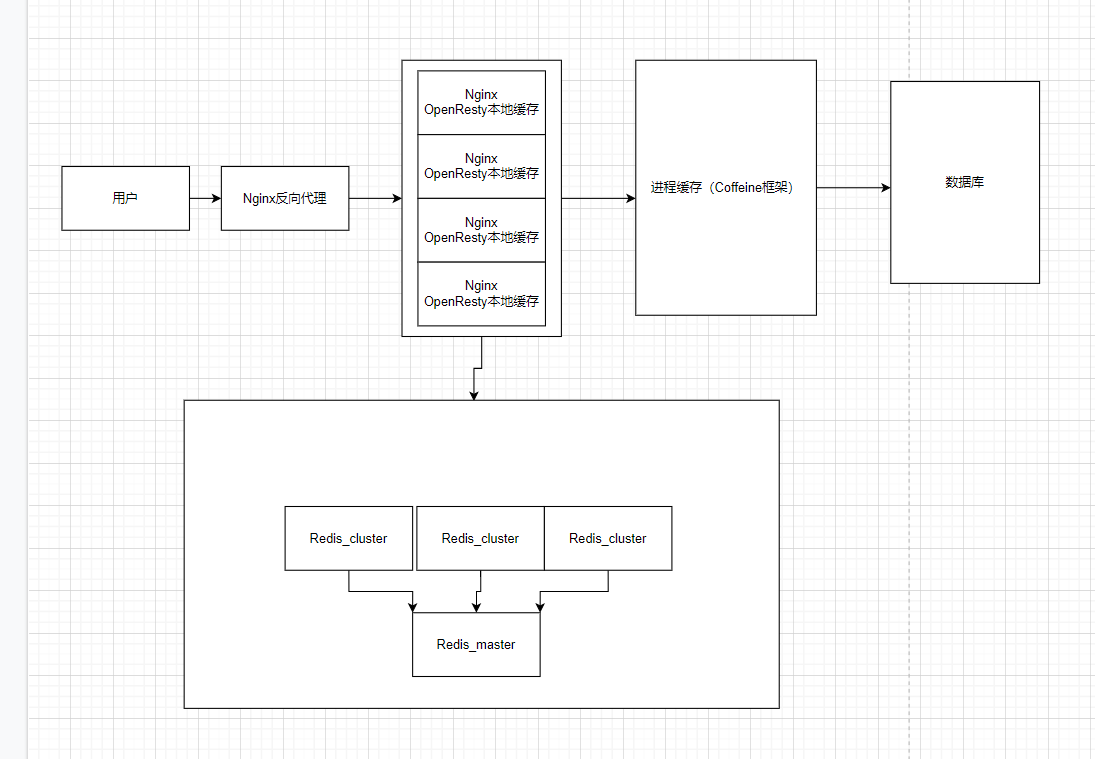
因为tomcat承受并发的能力有限,而redis承受并发的能力高很多,所以在tomcat用redis做缓存无法激发redis最大能力,所以在nginx部分使用OpenResty框架用lua语言先做一遍缓存,如果没有命中,再用lua发送请求到Nginx做反向代理而不是直接发给tomcat,然后返回得到的值
Caffeine这一层缓存成为一级缓存,OpenResty这一层称为二级缓存
经常被读取的数据被称作热点数据,较少被读取的数据叫做冷数据
热点数据一般需要被存在一级缓存中,这样可以减少操作redis读取数据的网络开销,并且速度更快,而冷数据一般只被存在二级缓存中
相关lua代码
发送请求到当前端口
local resp = ngx.location.capture("/test",{ method = ngx.HTTP_GET, args = {k1 = "i'm lua"},--get方式提交
body = "a=1&b=2" --Post方式提交,args和body二选一 }) ngx.say(resp.body)
-- resp.status 响应状态码
-- resp.body 响应体
-- resp.header 响应头
访问redis
local redis = require "resty.redis" local red = redis:new() local ok, err = red:connect("127.0.0.1", 6379) red:auth("password") ngx.say(red:get("testlua"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号