memcached源码剖析4:并发模型
memcached是一个典型的单进程系统。虽然是单进程,但是memcached内部通过多线程实现了master-worker模型,这也是服务端最常见的一种并发模型。实际上,除了master线程和worker线程之外,memcached还有一些其他的辅助线程(比如logger线程),但是与本文主题无关,所以这里不做描述。
master-worker线程模型
memcached有1条主线程,以及4条woker线程。可以通过启动参数-t来指定worker线程的数量,如果不指定,默认情况下就是4。简单来说,主线程负责监听请求,分发给worker线程。而worker线程负责接收具体的请求命令并且作出处理。
示意图如下:
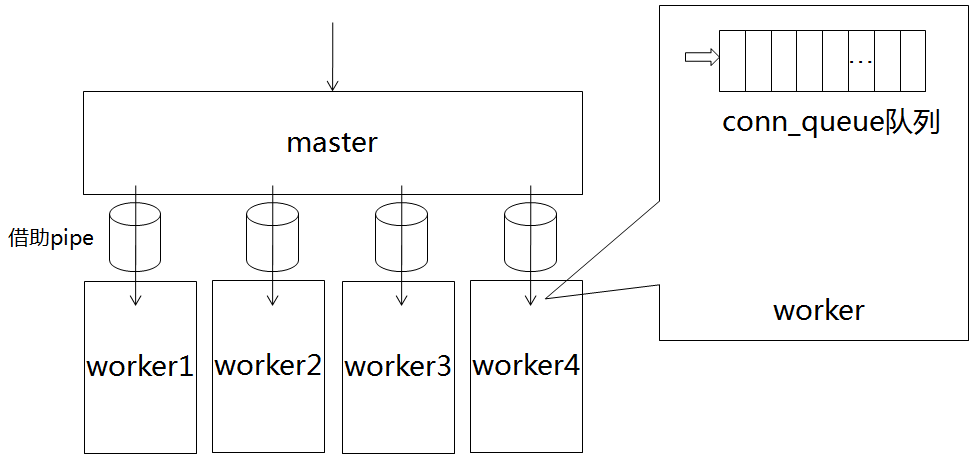
这张图大致画出了主从线程之间的关系。
主线程监听到有新的连接之后,会做出一次选择,我们称之为dispatch,其实就是确定此连接后续会由哪个worker线程处理。一旦确定worker线程,接下来主线程会借助管道通知该worker线程。在每条worker线程的内部,都有一个连接队列。worker线程收到通知之后,会从连接队列中取出一个连接,用于后续接受具体的命令,以及做出响应。
OK,上面只是一个大概的描述,准确的细节,我们还是得通过分析源代码才能得知。
worker线程的创建
来看一下worker线程的创建过程,在main函数中有:
/* start up worker threads if MT mode */ memcached_thread_init(settings.num_threads);
settings.num_threads控制着worker线程的个数。前文提到可以通过-t参数改变,因为在main函数刚开始分析启动参数的一段中有:
case 't': settings.num_threads = atoi(optarg); if (settings.num_threads <= 0) { fprintf(stderr, "Number of threads must be greater than 0\n"); return 1; } /* There're other problems when you get above 64 threads. * In the future we should portably detect # of cores for the * default. */ if (settings.num_threads > 64) { fprintf(stderr, "WARNING: Setting a high number of worker" " threads is not recommended.\n" " Set this value to the number of cores in" " your machine or less.\n"); } break;
可以看到,最好不要设置超过64条线程,线程一旦太多,频繁的切换也需要开销,另外就是memcached大量使用互斥锁,可能会使得没有抢到锁的线程处于等待状态。不过笔者并没有测试过线程数量递增与性能的损失比例。
接下来看memcached_thread_init函数:
void memcached_thread_init(int nthreads) { // 锁的初始化 ... // 初始化init_lock,init_cond pthread_mutex_init(&init_lock, NULL); pthread_cond_init(&init_cond, NULL); // 锁的初始化 ... // 分配LIBEVENT_THREAD的空间 threads = calloc(nthreads, sizeof(LIBEVENT_THREAD)); if (! threads) { perror("Can't allocate thread descriptors"); exit(1); } // 初始化各线程 for (i = 0; i < nthreads; i++) { int fds[2]; if (pipe(fds)) { // 这里创建了管道!!! perror("Can't create notify pipe"); exit(1); } threads[i].notify_receive_fd = fds[0]; threads[i].notify_send_fd = fds[1]; setup_thread(&threads[i]); /* Reserve three fds for the libevent base, and two for the pipe */ stats_state.reserved_fds += 5; } // 启动各线程 for (i = 0; i < nthreads; i++) { create_worker(worker_libevent, &threads[i]); } // 等待各条线程初始化完成之后,再继续执行 pthread_mutex_lock(&init_lock); wait_for_thread_registration(nthreads); pthread_mutex_unlock(&init_lock); }
memcached_thread_init的刚开始,是初始化一系列的锁。关于memcached中锁的运用,可以单独开一章来讲述,源码中几乎处处存在锁。这里特地列出了init_lock和init_cond,因为在memcached_thread_init的最后会涉及到。
LIBEVENT_THREAD
初始化各种锁之后,会为4条worker线程分配内存空间。我们可以看到,线程相关的数据被封装在LIBEVENT_THREAD结构体当中。
typedef struct { pthread_t thread_id; // 线程ID struct event_base *base; // 一个libevent的实例 struct event notify_event; // 监听的事件 int notify_receive_fd; // 管道的recv端 int notify_send_fd; // 管道的send端 struct thread_stats stats; // 线程的一些状态统计 struct conn_queue *new_conn_queue; // 连接队列 cache_t *suffix_cache; /* suffix cache */ logger *l; // logger } LIBEVENT_THREAD;
在为LIBEVENT_THREAD分配好内存之后,紧接着就开始在for循环中依次初始化各条线程。
这里首先做的事情,是建立主线程和worker线程之间的管道。
// 建立管道 int fds[2]; if (pipe(fds)) { perror("Can't create notify pipe"); exit(1); } // 设置管道两端的fd threads[i].notify_receive_fd = fds[0]; threads[i].notify_send_fd = fds[1];
setup_thread
前文提到了,当marster接收新连接之后,会利用管道通知worker。我们继续看setup_thread函数:
static void setup_thread(LIBEVENT_THREAD *me) { // 初始化worker线程的libevent实例 me->base = event_init(); if (! me->base) { fprintf(stderr, "Can't allocate event base\n"); exit(1); } // 监听管道的recv端,一旦获取到marster线程的通知,会触发thread_libevent_process函数 event_set(&me->notify_event, me->notify_receive_fd, EV_READ | EV_PERSIST, thread_libevent_process, me); event_base_set(me->base, &me->notify_event); if (event_add(&me->notify_event, 0) == -1) { fprintf(stderr, "Can't monitor libevent notify pipe\n"); exit(1); } // 初始化worker线程的conn_queue,即连接队列 me->new_conn_queue = malloc(sizeof(struct conn_queue)); if (me->new_conn_queue == NULL) { perror("Failed to allocate memory for connection queue"); exit(EXIT_FAILURE); } cq_init(me->new_conn_queue); if (pthread_mutex_init(&me->stats.mutex, NULL) != 0) { perror("Failed to initialize mutex"); exit(EXIT_FAILURE); } // 初始化worker线程的suffix_cache me->suffix_cache = cache_create("suffix", SUFFIX_SIZE, sizeof(char*), NULL, NULL); if (me->suffix_cache == NULL) { fprintf(stderr, "Failed to create suffix cache\n"); exit(EXIT_FAILURE); } }
至此,LIBEVENT_THREAD中,一些字段初始化工作都已准备就绪。
create_worker
接着看第二个for循环中的create_worker函数,就是利用pthread_create,真正的创建线程。
static void create_worker(void *(*func)(void *), void *arg) { pthread_attr_t attr; int ret; pthread_attr_init(&attr);
// 利用ptread_create创建线程,线程执行函数为worker_libevent if ((ret = pthread_create(&((LIBEVENT_THREAD*)arg)->thread_id, &attr, func, arg)) != 0) { fprintf(stderr, "Can't create thread: %s\n", strerror(ret)); exit(1); } }
值得一提的是,线程被创建时指定的执行函数为worker_libevent。这意味着,4条worker线程被pthread真正创建之后,会进入到worker_libevent。来看看worker_libevent:
static void *worker_libevent(void *arg) { LIBEVENT_THREAD *me = arg; // 初始化logger me->l = logger_create(); if (me->l == NULL) { abort(); } // 利用条件变量与主线程同步 register_thread_initialized(); // 一旦执行下面一句,worker线程就开始挂起,直到接收主线程通知 event_base_loop(me->base, 0); return NULL; }
其中的register_thread_initialized要与memcached_thread_init函数最后三句结合一起来看:
pthread_mutex_lock(&init_lock);
wait_for_thread_registration(nthreads);
pthread_mutex_unlock(&init_lock);
这是利用条件变量进行线程同步的一个很经典的做法。
wait_for_thread_registration表示,主线程挂起在条件变量上,只要init_count<4则主线程一直会挂起。而子线程的register_thread_initialized表示,子线程一旦init完成,就将init_count++,并且告知主线程,主线程随后继续判断init_count是否<4。最终,只有当4条worker线程都init结束之后,主线程才会结束挂起,继续向下执行。
至此,worker线程初始化的相关源码都已经阅读完了。memcached的源码相对其他一些开源项目,其实还是很清晰明了的。
marster线程的监听
主线程初始化完worker线程之后,会进一步处理网络连接。通过代码可以看到,memcached可以支持三种协议:uds(unix domain socket),tcp,udp。
// 如果指定了uds路径,则创建unix domain socket if (settings.socketpath != NULL) { errno = 0; if (server_socket_unix(settings.socketpath, settings.access)) { vperror("failed to listen on UNIX socket: %s", settings.socketpath); exit(EX_OSERR); } } // 否则,创建tcp和udp的socket if (settings.socketpath == NULL) { ... // tcp errno = 0; if (settings.port && server_sockets(settings.port, tcp_transport, portnumber_file)) { vperror("failed to listen on TCP port %d", settings.port); exit(EX_OSERR); } // udp errno = 0; if (settings.udpport && server_sockets(settings.udpport, udp_transport, portnumber_file)) { vperror("failed to listen on UDP port %d", settings.udpport); exit(EX_OSERR); } ... }
memcached的启动参数-p和-U分别控制了setting.port和setting.udpport。
举例,如果想只支持tcp协议的连接,监听端口号为8888,不支持udp连接,我们可以按如下方式启动:
memcached -p8888 -U0
OK,接下来就是具体来看socket的处理了。
server_socket
先画一个简单的调用关系图:
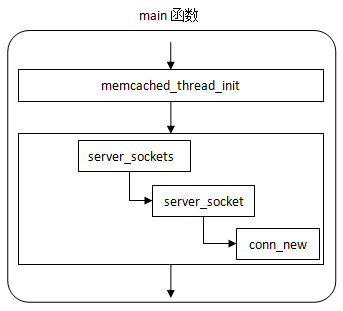
server_sockets函数稍微有些复杂,但是其本质上是调用server_socket函数来创建一个个socket。在server_socket中,具体完成了初始化socket,绑定IP和端口,添加监听的事件等工作。
我们直接来看server_socket:
static int server_socket(const char *interface, int port, enum network_transport transport, FILE *portnumber_file) { int sfd; struct linger ling = {0, 0}; struct addrinfo *ai; struct addrinfo *next; struct addrinfo hints = { .ai_flags = AI_PASSIVE, .ai_family = AF_UNSPEC }; char port_buf[NI_MAXSERV]; int error; int success = 0; int flags = 1; // 区分udp还是tcp hints.ai_socktype = IS_UDP(transport) ? SOCK_DGRAM : SOCK_STREAM; if (port == -1) { port = 0; } snprintf(port_buf, sizeof(port_buf), "%d", port); // 调用getaddrinfo来返回ai链表 error = getaddrinfo(interface, port_buf, &hints, &ai); if (error != 0) { if (error != EAI_SYSTEM) fprintf(stderr, "getaddrinfo(): %s\n", gai_strerror(error)); else perror("getaddrinfo()"); return 1; } // 遍历ai链表,针对每个地址创建socket for (next= ai; next; next= next->ai_next) { conn *listen_conn_add; // 调用socket()接口来实际创建套接字,并且将套接字设置成“非阻塞” if ((sfd = new_socket(next)) == -1) { /* getaddrinfo can return "junk" addresses, * we make sure at least one works before erroring. */ if (errno == EMFILE) { /* ...unless we're out of fds */ perror("server_socket"); exit(EX_OSERR); } continue; } ... // 设置套接字的一些其他选项 setsockopt(sfd, SOL_SOCKET, SO_REUSEADDR, (void *)&flags, sizeof(flags)); if (IS_UDP(transport)) { maximize_sndbuf(sfd); } else { error = setsockopt(sfd, SOL_SOCKET, SO_KEEPALIVE, (void *)&flags, sizeof(flags)); if (error != 0) perror("setsockopt"); error = setsockopt(sfd, SOL_SOCKET, SO_LINGER, (void *)&ling, sizeof(ling)); if (error != 0) perror("setsockopt"); error = setsockopt(sfd, IPPROTO_TCP, TCP_NODELAY, (void *)&flags, sizeof(flags)); if (error != 0) perror("setsockopt"); } // 调用bind if (bind(sfd, next->ai_addr, next->ai_addrlen) == -1) { if (errno != EADDRINUSE) { perror("bind()"); close(sfd); freeaddrinfo(ai); return 1; } close(sfd); continue; } else { success++; // 调用listen if (!IS_UDP(transport) && listen(sfd, settings.backlog) == -1) { perror("listen()"); close(sfd); freeaddrinfo(ai); return 1; } ... } if (IS_UDP(transport)) { ... } else { // 初始化conn,设置对sfd的监听事件 if (!(listen_conn_add = conn_new(sfd, conn_listening, EV_READ | EV_PERSIST, 1, transport, main_base))) { fprintf(stderr, "failed to create listening connection\n"); exit(EXIT_FAILURE); } // 加入conn链表的头部 listen_conn_add->next = listen_conn; listen_conn = listen_conn_add; } } freeaddrinfo(ai); /* Return zero iff we detected no errors in starting up connections */ return success == 0; }
这段代码虽然比较长,但实际上并不复杂。归根结底,依然是我们熟悉的服务端编程,socket,bind,listen...等等。其中比较关键的一点是利用conn_new函数来创建conn,以及设置监听事件。conn在memcached中是一个很重要的数据结构,后文会具体分析。来看下设置监听事件:
event_set(&c->event, sfd, event_flags, event_handler, (void *)c); event_base_set(base, &c->event); c->ev_flags = event_flags; if (event_add(&c->event, 0) == -1) { perror("event_add"); return NULL; }
这段代码可以看出,一旦前面socket创建的fd有监听到请求,则会触发调用event_handler函数。event_handler是一个非常核心的函数,它里面维护了一个状态机,根据请求的状态分别进行不同的处理。event_handler的具体实现我们也放到后面再看。
当主线程完成server_sockets处理之后,在main函数中,会调用event_base_loop:
/* enter the event loop */ if (event_base_loop(main_base, 0) != 0) { retval = EXIT_FAILURE; }
至此,主线程会进入所谓的event loop,每当有client发起连接,主线程便会执行上述的event_handler。
关于conns
前文提到在sever_socket中利用conn_new函数来创建conn连接。conn结构体在memcache中扮演着比较重要的角色。无论是主线程的监听,还是子线程与各个client进行交互处理,用到的都是这些conn。
master线程只绑定了一个event事件,client发起连接时被触发。对应的event_handler函数真正去处理的,便是传入的conn对象。
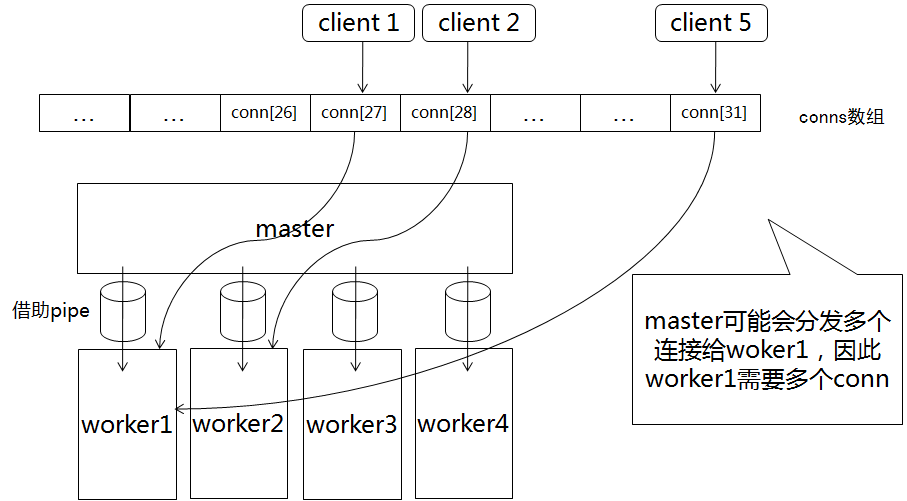
每个woker线程会绑定多个event事件,具体要视一个worker线程处理多少client的访问有关。但是每个worker线程,只有一个事件是与master线程有关的。那就是master接收到client发起的连接之后,会利用pipe通知一个worker,这个过程我们称之为“分发”。woker线程收到通知后,触发该事件,对应的函数为thread_libevent_process(参考setup_thread一小节)函数。thread_libevent_process中对于新的连接到来,也会立即用conn_new函数生成一个conn。至此,这个client与woker的所有交互,都是利用该conn完成。
画几个简单的示意图:
A,有新的连接
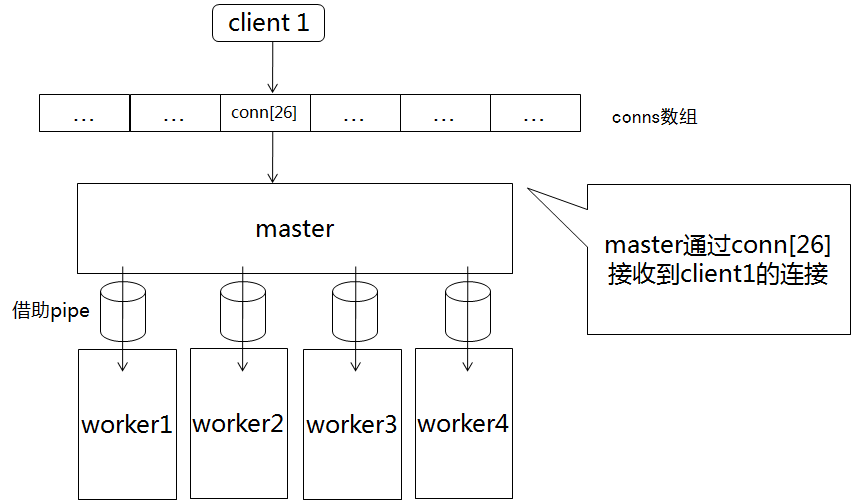
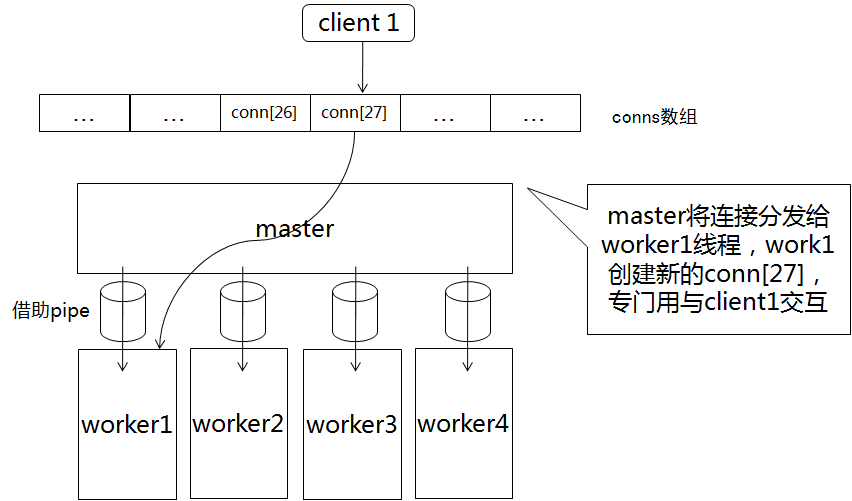
B,分发给worker1之后
C,又有新的连接

D,分发给worker2之后

E,建立了若干连接之后

本作品由driftcloudy创作,采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。欢迎自行转载,发布,演绎,但必须保留本文作者署名driftcloudy(包含链接http://www.cnblogs.com/driftcloudy),且不得用于商业目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号