大数据开发:(三)flume上传HDFS
-
开启
hadoop:start-dfs.sh -
通过浏览器访问node节点,http://IP:50070
检查
- (如果无法访问,将防火墙关闭)
- 如果jps查看缺少了某个节点,首先查看xml文件是否正确,如果正确,删除hadoop/tmp文件夹,然后再次格式化,(格式化会重新创建hadoop/tmp),再次启动
-
操作分布式文件存储系统HDFS
-
查看hdfs中的文件内容
hadoop fs -ls / -
查看hdfs中的详细内容
hadoop fs -ls / -
在HDFS中创建文件夹
hadoop fs -mkdir /flume -
Flume上传数据到HDFS中
-
解压flume
-
将flume文件下得conf中flume-env.ps1.template复制一份,改为flume-env.ps1
-
修改conf下得log4j.properties文件,在文件末尾修改,改后结果为:flume.root.logger=INFO,console
-
找到hadoop安装包,从安装包中找到相关jar包,放入到flume的lib下
-
下载hadoop-common-2.2.0bin-master
HADOOP_HOME :
E:\大数据学习\hadoop-common-2.2.0-bin-masterPath 配置路径 Path:
%HADOOP_HOME%\bin %HADOOP_HOME%\sbin -
给hdfs/flume权限(可以操作权限):
hadoop fs -chmod 777 /flume
-
-
-
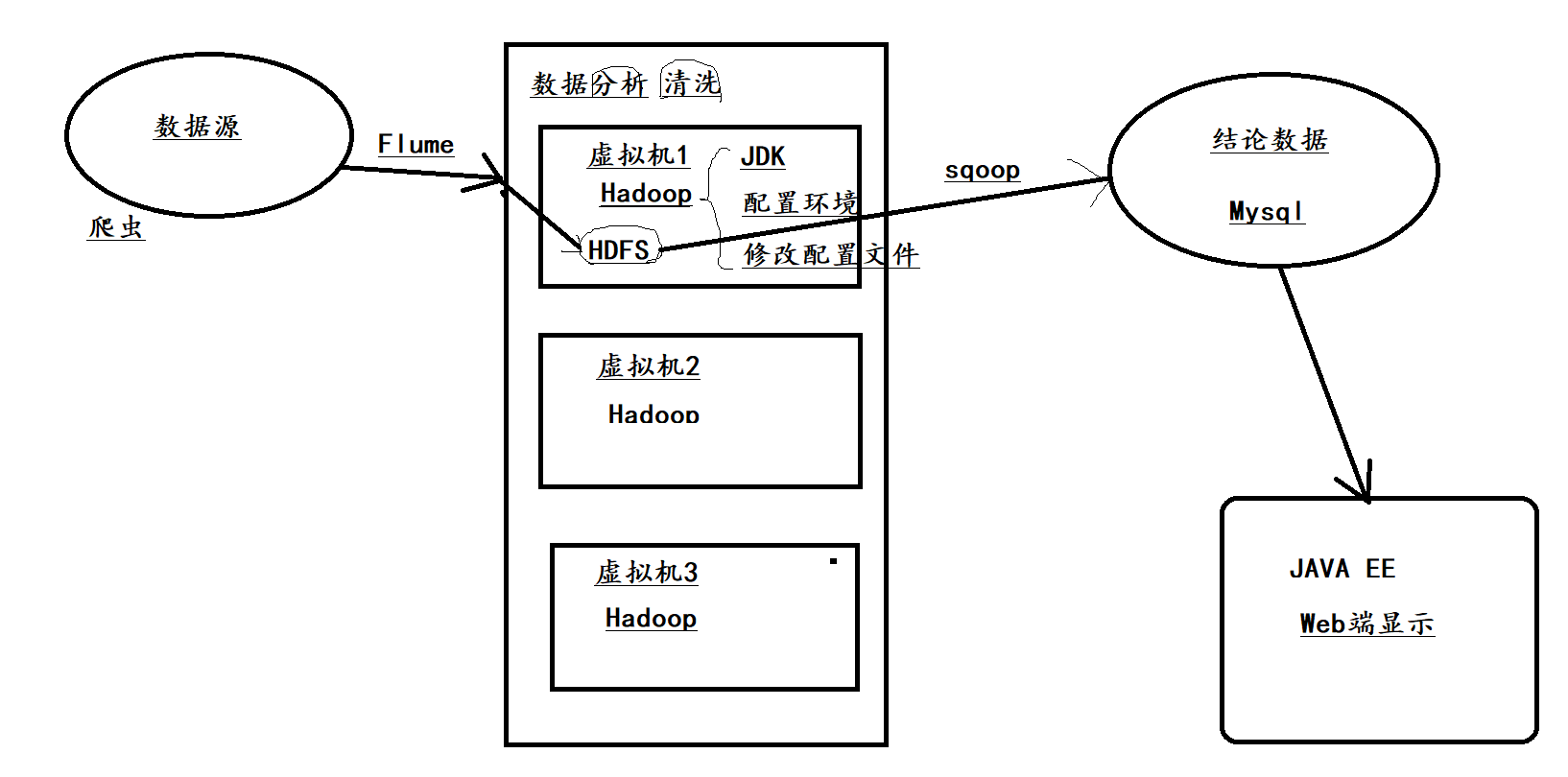
Hadoop运行机制
查看数据片内容:
hadoop fs -cat /flume/events-.1582198102809
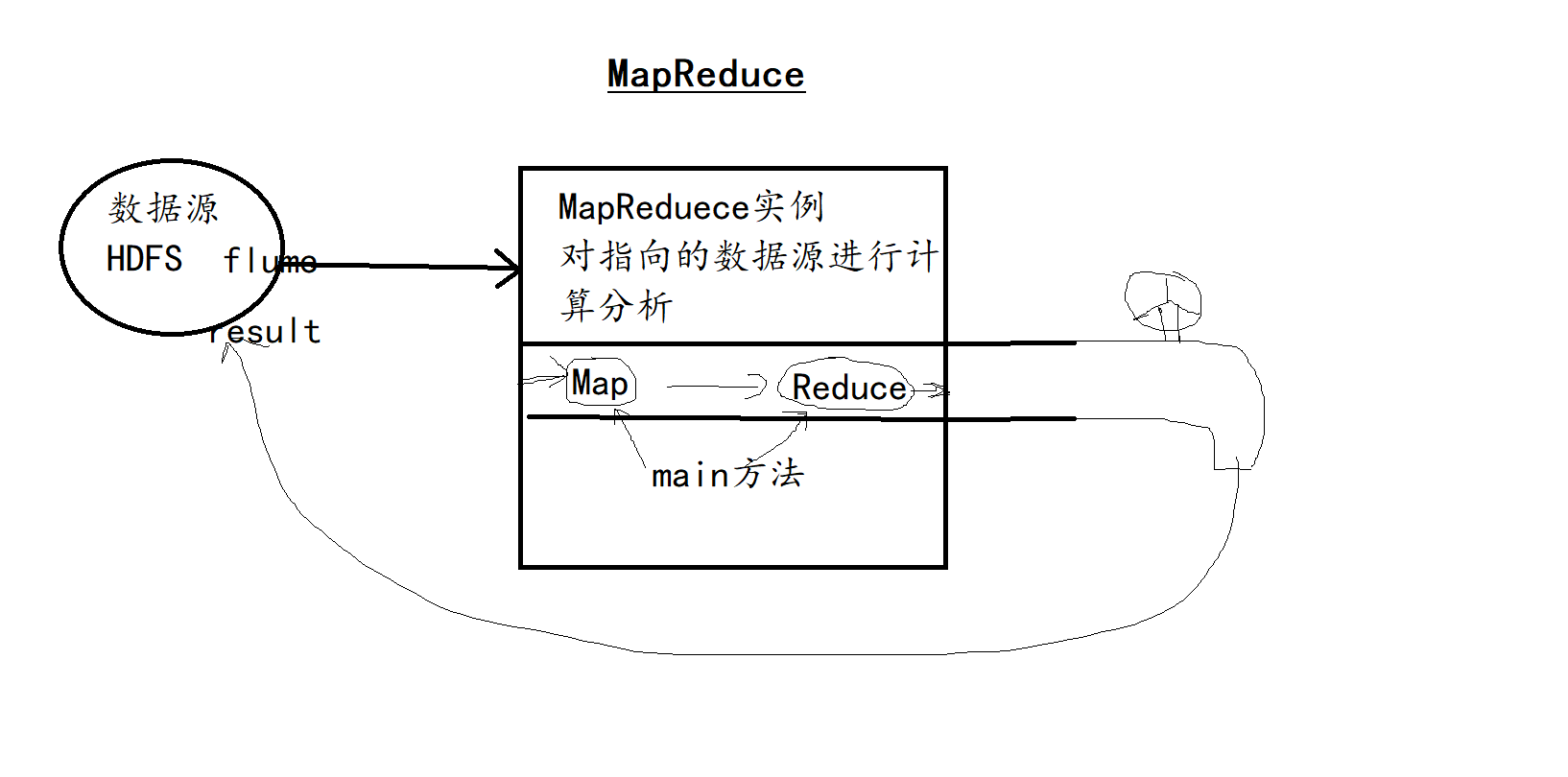
- MapReduce流程图
- 编写java文件,设置数据清洗规则
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 定义一个文件夹路径 用于存储计算分析后的可用数据
Path outputPath = new Path("hdfs://192.168.159.1:8020/flume/output");
//判断新路径是否已经存在
FileSystem fileSystem =FileSystem.get(conf);
if(fileSystem.exists(outputPath)) { //如果存在 先删除再创建
fileSystem.delete(outputPath,true);
}
Job job = Job.getInstance(conf,"Demo");
job.setJarByClass(Demo.class);
// 源目录 从hdfs读下来 放到 map中 在map中清洗数据
FileInputFormat.setInputPaths(job, new org.apache.hadoop.fs.Path("hdfs://192.168.159.1:8020/flume"));
//!!!!从虚拟机里读取文件,清洗后放入hdfs中 file:
//FileInputFormat.setInputPaths(job, new Path("file:/action-data/contest/online_retailers"));
job.setMapperClass(MapOne.class);//第一个门卫
job.setMapOutputKeyClass(Text.class);//想要通过的人
job.setMapOutputValueClass(LongWritable.class);//通行证上面的戳
// 把map的数据导入reduce中
job.setReducerClass(ReduceOne.class);//第二个门卫
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//把reduce中 通过清洗的数据 导回指定目录
FileOutputFormat.setOutputPath(job, new org.apache.hadoop.fs.Path("hdfs://192.168.159.1:8020/flume/output"));
//sqoop配置mysql
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
Map
public class MapOne extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] infos = line.split("#");
System.out.println(infos[1].toString()+"************---**************");
if(infos!=null &&infos.length>0) {
String info=infos[1];
String[] strs = info.split(":");
System.out.println(strs.toString()+"***********分分***************");
if(strs!=null &&strs.length>0) {
double score=Double.parseDouble(strs[1]);
if(score>=8) {//说明 这条数据的电影评分 不小于8分
//然后使用mapper这个父类的write方法 将本条数据通过,并发往下一环节
context.write(new Text(line), new LongWritable(0));
}
}
}
}
}
reduce
public class ReduceOne extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
context.write(key, new LongWritable(0));
}
}
所需要的jar包

- 将java项目导出为jar包
- 导入到linux有权限操作的目录下
- 运行命令
hadoop jar hadooptest.jar demo.Demo - 查看:hadoop fs -ls -R /
- 查看具体数据 hadoop fs -cat /flume/output/part-r-00000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号