
自然语言处理入门小白从0开始学自然语言处理+学习笔记(一)
1、自然语言处理学习路径规划
- 自然语言处理(NLP)开发环境搭建
- 分词demo(搭建helloworld工程)
- 案例:nlp实现预测天气冷暖感知度
- ---案例需求和数据准备
- ---可视化数据分析
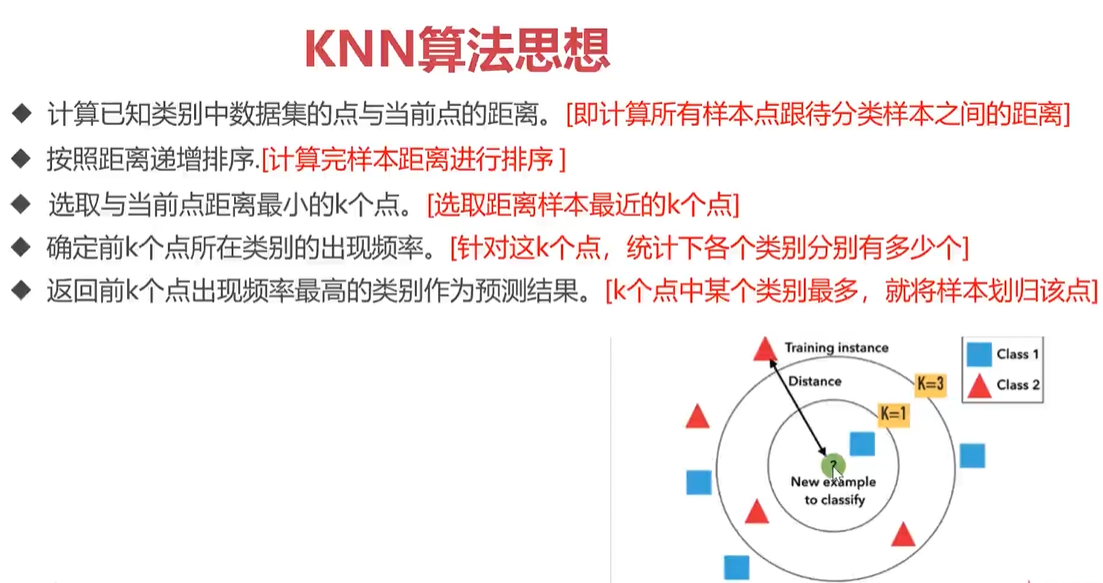
- ---KNN模型原理及欧式距离计算
- ---KNN分类器模型实现
- ---利用KNN分类器采访随机游客预测天气感知度
- ---机器学习库sklearn实现预测天气冷暖感知度
- 自然语言处理学习总结归纳
2、自然语言处理(NLP)开发环境搭建
- 自然语言处理一般用python语言,java其实也可以,反正每个语言生态都有自己的相关NLP库
- 开发环境千万个,萝卜青菜给有所爱,这里给搭建推荐用idea了
- 下载idea https://www.jetbrains.com/idea/download/
- 下载python语言插件(File->settings->plugins->marketplace->搜索:python选择python language那个)
- 有了插件,就可以新建python项目了,先默认新建一个项目,比如:nlp
- 下载idea https://www.jetbrains.com/idea/download/
3、分词demo(搭建helloworld工程)
- 按照国际上的惯例,咱们应该先写个hello world,体验一下python(希望大家有python基础,没有也没关系)
- NLP当中有个常用的技术,分词,咱也不会,用个第三方的试试
- jieba库是一款优秀的 Python 第三方中文分词库jieba 支持三种分词模式:精确模式、全模式和搜索引擎模式,下面是三种模式的特点。
- 精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
- 全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
- 搜索引擎模式:在精确模式的基础上,对长词再次进行切分
上代码之前得安装这个分词包,秒级安装镜像pip install jieba -i https://pypi.douban.com/simple/
好,上代码:
import jieba;
str = "中国是工人阶级领导的以工农联盟为基础的人民民主专政的社会主义国家";
res = " ".join(jieba.cut(str))
print(res)
运行效果如下:

4、案例:nlp实现预测天气冷暖感知度
4.1、案例需求及数据准备

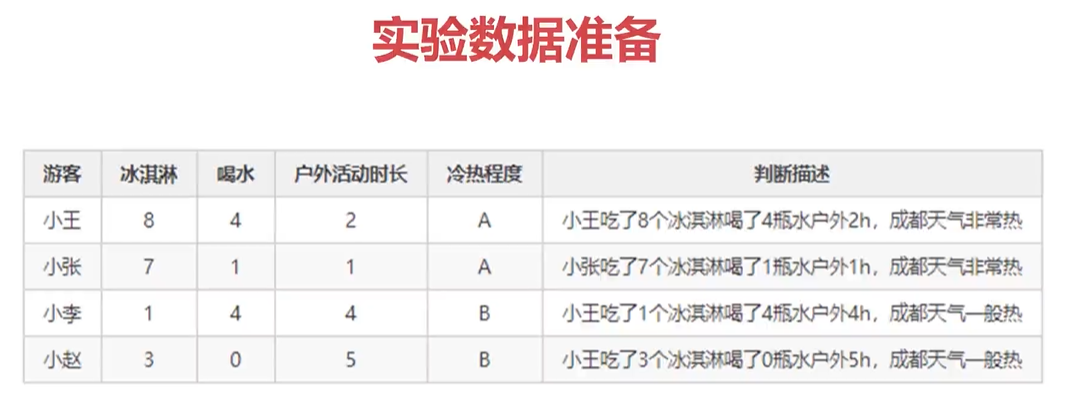
上代码:
#coding=utf8
'''创建数据源、返回数据集和类标签'''
def creat_dataset():
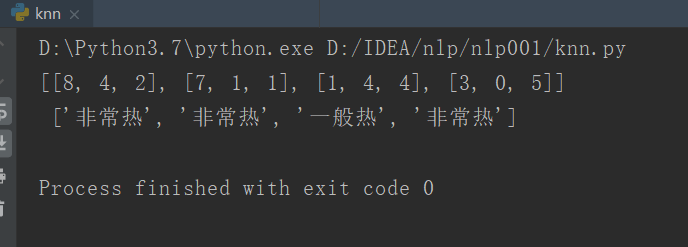
datasets = [[8,4,2],[7,1,1],[1,4,4],[3,0,5]]#数据集
labels = ['非常热','非常热','一般热','非常热']#类标签
return datasets,labels
if __name__ == '__main__':
datasets,labels = creat_dataset()
print(datasets,'\n',labels)
运行结果:
4.2、数据分析与可视化
上代码:
#coding=utf8
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''创建数据源、返回数据集和类标签'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#数据集
labels = ['非常热','非常热','一般热','非常热']#类标签
return datasets,labels
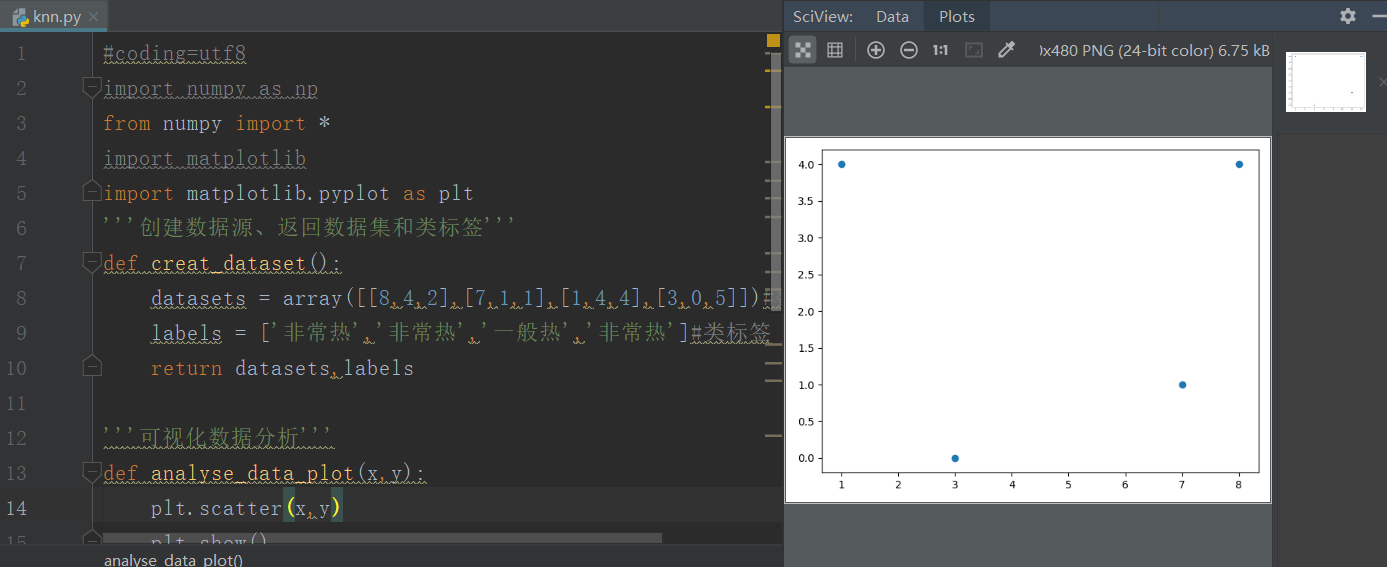
'''可视化数据分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
if __name__ == '__main__':
datasets,labels = creat_dataset()
print('数据集:\n',datasets,'\n','类标签:\n',labels)
'''数据可视化分析'''
analyse_data_plot(datasets[:,0],datasets[:,1])
运行结果:
4.3、算法模型及原理
KNN模型原理及欧式距离计算



上代码:
#coding=utf8
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''创建数据源、返回数据集和类标签'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#数据集
labels = ['非常热','非常热','一般热','非常热']#类标签
return datasets,labels
'''可视化数据分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
'''构造KNN分类器'''
#def knn_Classifier(newV,datasets,labels,2):
#1.获取新的样本数据
#2.获取样本库的数据
#3.选择K值
#4.计算样本数据与样本库数据之间的距离
#5.根据距离进行排序
#6.针对K个点,统计各个类别的数量
#7.投票机制,少数服从多数原则
'''欧氏距离计算:d²=(x1-x2)²+(y1-y2)²'''
def ComputerEuclideanDistance(x1,y1,x2,y2):
d = math.sqrt(math.pow((x1-x2),2)+math.pow((y1-y2),2))
return d
'''欧氏距离计算多维度支持'''
def EuclideanDistance(instance1,instance2,length):
d=0
for i in range(length):
d += pow((instance1[i]-instance2[i]),2)
return math.sqrt(d)
if __name__ == '__main__':
#1.创建数据集和类标签
datasets,labels = creat_dataset()
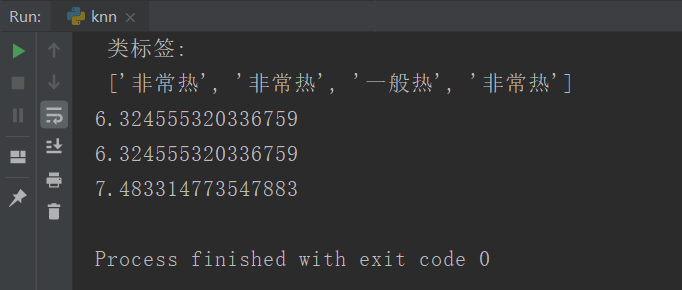
print('数据集:\n',datasets,'\n','类标签:\n',labels)
#2.数据可视化分析
#analyse_data_plot(datasets[:,0],datasets[:,1])
#3.1.欧式距离计算
d = ComputerEuclideanDistance(2,4,8,2)
print(d)
#3.2.欧式距离计算
d2 = EuclideanDistance([2,4],[8,2],2)
print(d2)
#3.3.欧式距离计算,可支持多维
d3 = EuclideanDistance([2,4,9],[8,2,5],3)
print(d3)
#KNN分类器
newV = [2,4,0]
#knn_Classifier(newV,datasets,labels,2)
运行结果:
下一篇笔记分享学习如下内容
- ---KNN分类器模型实现
- ---利用KNN分类器采访随机游客预测天气感知度
- ---机器学习库sklearn实现预测天气冷暖感知度
- 自然语言处理学习总结归纳
