
Redis Mode 工作模式
Redis 模式
我们项目接触redis一开始是作为缓存,主要是因为它的速度快。其次是用于分布式锁,如果有兴趣还可以用来做布隆过滤器。
redis的模式基本分4种,在实际 生产环境中,主要还是集群。
讨论的redis版本,以4.0为主。
单点 Standalone
这基本不用说,官网上面的demo就有,自己的网站部署玩一玩可以。
优点是不用花什么钱,自己的云服务器上面就可以安装一个。
缺点是 很明显,一台redis挂了,其他依赖redis的服务也就挂了。
主从 Master/Slave
结构图:

一个Master,可以有多个Slave,Slave 也可以有自己的Slave。这样简单的主从结构就完成了。
Master一般是用来做write,Slave一般是用来read。这样的结构可以有效的缓解系统的读写压力。
因为Master是负责write,那么就会出现主从数据的不同步,就需要通过sync,把Master的数据同步给Slave。【rdb文件,backlog】
具体点就会区分:
- 全量复制:slave刚接入,需要把master上的数据全部同步
- 增量复制:slave,网络中断,超时,导致部分数据需要增量同步
但是问题也随之而来,如果Master挂了,怎么办? 需要手动去调整
如果要恢复有2种方式
-
新增一台机器做Maste
-
将其中一台Slave,转成Master
也就意味着短时间内无法写入数据,虽然可以读取。从高可用性来说,这个结构是不完善的,因为功能已经不全了。在恢复的过程中,肯定会有部分的业务会受到影响,对于某些HA高的业务自然不能忍受。
哨兵 Sentinel
sentinel可以算是Master/Slave的改进。
在当Master无法正常工作时,Slave无法自己选出一个Master,就需要sentinel来做这个事。但是问题来了,如果sentinel也挂了,怎么办?
所以这个结构的优缺点就很明显了
-
优点: 快速响应自动故障切换,无需人工介入,客户端无需感知redis状态。
支持HA,可以满足一般的生产需求。
-
缺点: 需要维护sentinel的信息,而且水平扩展会很难处理。
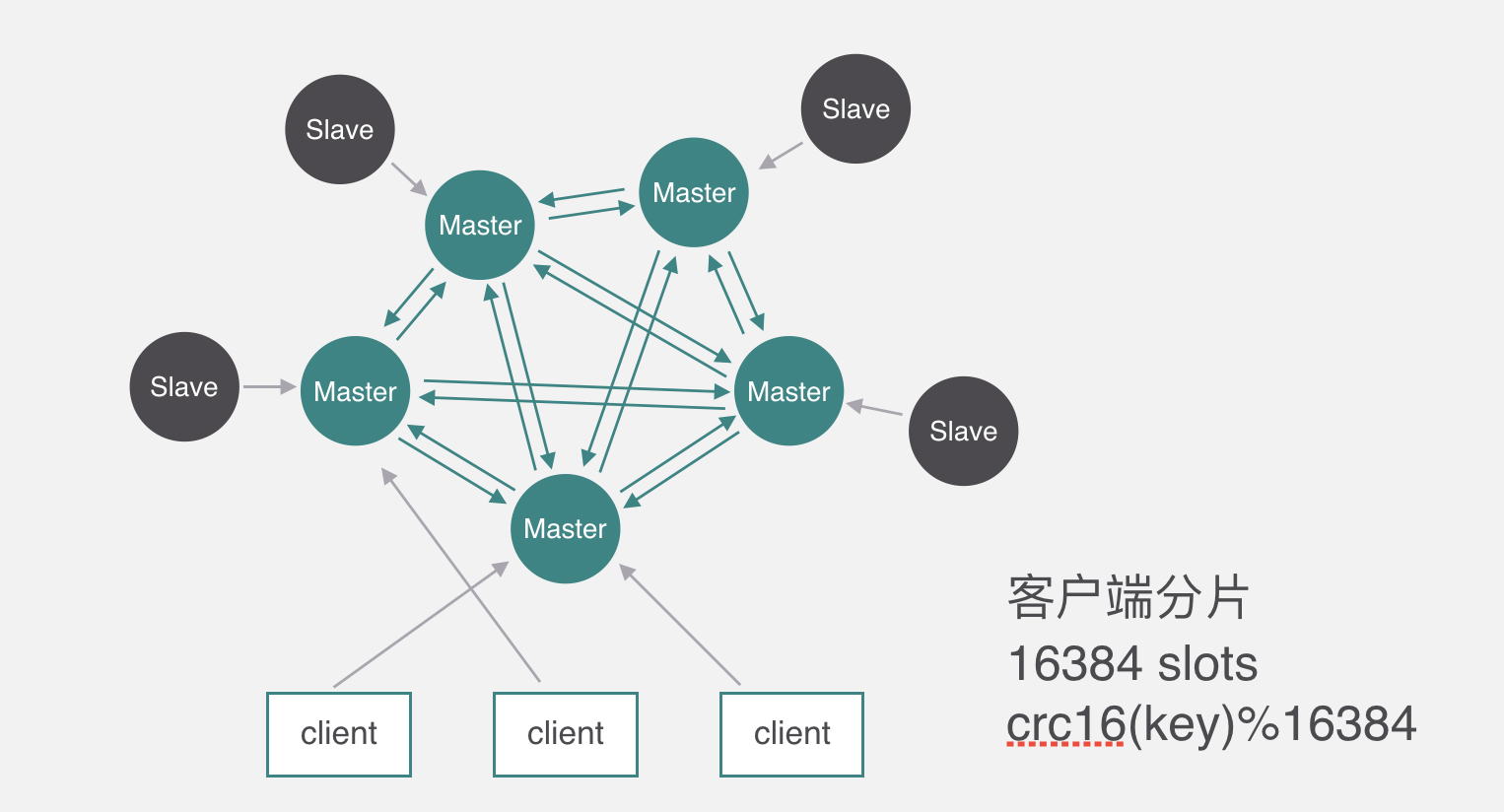
集群 Cluster
对于cluster来说,基本特点就是高可用,可扩展,负载均衡。
图片实在懒得画了,找了一个比较好理解的
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项。
内容引用:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号