

sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(generalize)。
我们以分类花的例子来看下:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 建立模型
model = KNeighborsClassifier()
# 训练模型
model.fit(X_train, y_train)
# 将准确率打印出
print(model.score(X_test, y_test))
这样这个模型的得分为:
0.911111111111
但是如果我再运行一下,这个得分又会变成:
0.955555555556
如果再进行多次运行,这个得分的结果就又会不一样。
为了能够得出一个相对比较准确的得分,一般是进行多次试验,并且是用不同的训练集和测试集进行。
这个叫做交叉验证,一般有留一法,也就是把原始数据分成十份,其中一份作为测试,其它的作为训练集,并且可以循环来选取其中的一份作为测试集,剩下的作为训练集。
当然,这里只是提供一个基本思想,具体你要分成几份可以自己来定义。
比如,下面的代码我们定义了5份并做了5次实验:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# 建立模型
model = KNeighborsClassifier()
# 使用K折交叉验证模块
scores = cross_val_score(model, X, y, cv=5)
# 将5次的预测准确率打印出
print(scores)
输出为:
[ 0.96666667 1. 0.93333333 0.96666667 1. ]
对这几次实验结果进行一下平均作为本次实验的最终得分:
# 将5次的预测准确平均率打印出
print(scores.mean())
结果为:
0.973333333333
在KNN算法中,其中有个neighbors参数,我们可以修改此参数的值:
model = KNeighborsClassifier(n_neighbors=5)
但这个参数值选择哪个数字为最佳呢?
我们可以通过程序来不停选择这个值并看在不同数值下其对应的得分情况,最终可以选择得分较好对应的参数值:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
# 可视化模块
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
y = iris.target
# 建立测试参数集
k_range = range(1, 31)
k_scores = []
for k in k_range:
# 建立模型
model = KNeighborsClassifier(n_neighbors=k)
# 使用K折交叉验证模块
scores = cross_val_score(model, X, y, cv=10)
# 计算10次的预测准确平均率
k_scores.append(scores.mean())
# 可视化数据
plt.plot(k_range, k_scores)
plt.show()
显示的图形为:
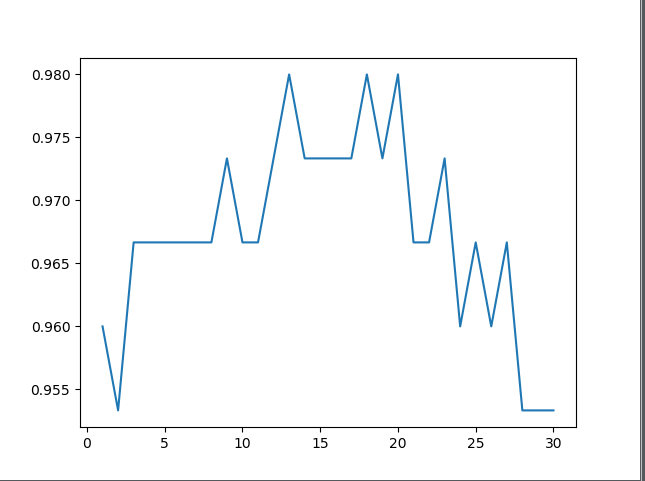
从这个结果图上看,n_neighbors太小或太大其精确度都会下降,因此比较好的取值是5-20之间。
另外对于回归算法,需要用损失函数来进行评估:
loss = -cross_val_score(model, data_X, data_y, cv=10, scoring='neg_mean_squared_error')
作者:dreampursuer(公众号:独立开发者手记)

出处:http://www.cnblogs.com/dreampursuer/
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://www.cnblogs.com/dreampursuer/
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步