第四次个人作业---结对编程
| Git地址 | https://github.com/DreamOne11/WordCount |
| 结对同学的作业地址 | <同伴博客> |
| 结对同学的学号 | 201731062134 |
| 个人博客地址 | https://www.cnblogs.com/dreamone11/ |
| 作业要求 | <作业要求> |
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 45 | 50 |
| Development | 开发 | 830 | 1180 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 25 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 35 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 400 | 660 |
| · Code Review | · 代码复审 | 100 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 115 | 120 |
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 25 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 990 | 1350 |
三、基本解题思路
1、在看到题目后,我们两个人便进行了题目分析,决定根据题目要求先实现基础功能再在基础功能上增加新功能。这个思路确定了我们的项目框架。(在后续程序设计中会说到)
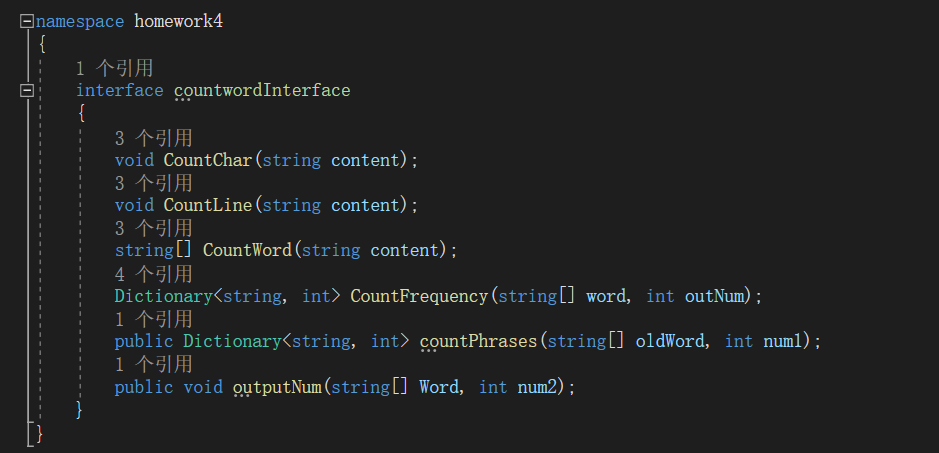
2、因为后续需要接口封装,所以我们针对四个基础功能在接口中定义了相对应的方法。然后在父类中实现了接口中的四个基础方法。(字符数统计、单词数统计、行数统计、单词频率统计)
3、后续新增的两个功能我们放在了上述父类的一个子类中,因为无论是按输入参数生成词组还是按输入参数输出对应个数的高频词这两个新增功能都会再次依靠基础功能加以实现,所以继承结构的框架就非常重要了。
4、因为用户会输入相应参数,所以我们在主函数入口类中设计了相应的参数识别和提取。
四、程序设计(详细)
分工:同伴负责:四个基础功能;我负责:文件写入、命令行参数定义、两个附加功能
-
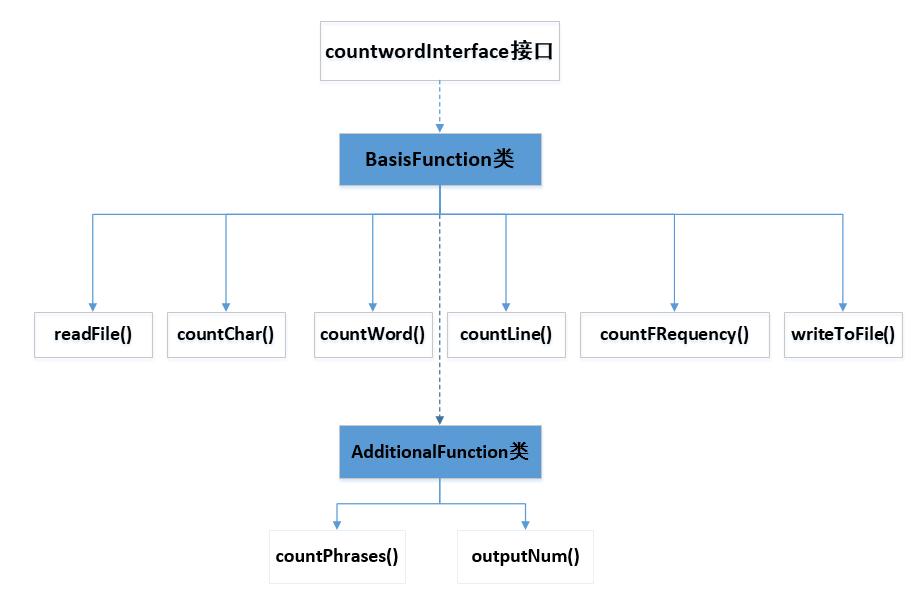
基础框架设计
![]()
我们一共设计了3个类,包括1个接口类,1个基础功能类和1个附加功能类。6个功能函数(父类4个,子类两个) -
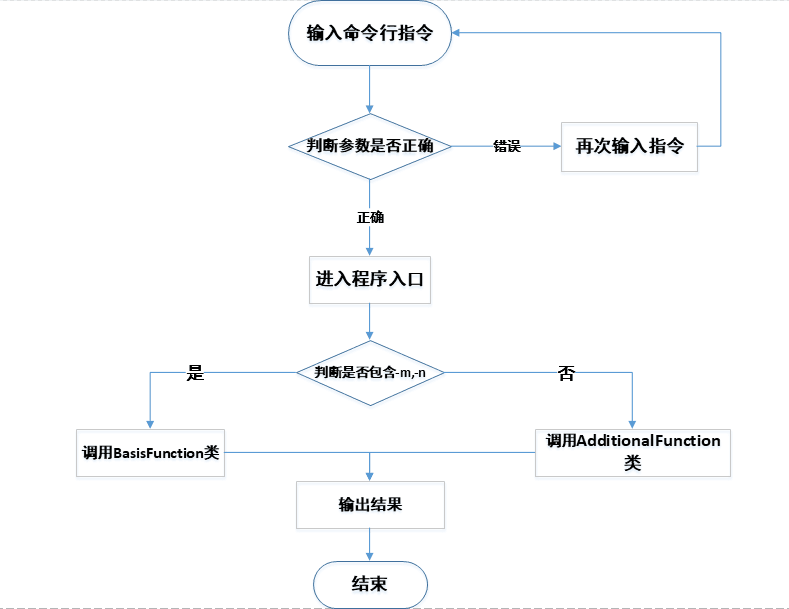
逻辑流程设计
![]()
我们对用户的操作进行了分类,假设用户没有输入任何命令行参数(只是执行了程序)那么我们调用BasisFunction(父类),用户只需输入文件路径即可得到相应的结果;假设用户使用了命令行参数此时我们再调用AddtionalFunction(子类) -
接口封装设计
![]()
-
四个基础功能的设计
这个部分由我的结对伙伴负责,请看他的博客的相关部分:同伴博客 -
两个附加功能和自定义命令行参数的设计
-
自定义命令行
在cmd命令行输入的参数会存入程序入口主函数main(string[] args)的字符串数组中。为了保证参数输入顺序不会影响程序执行顺序,使用分支语句判断并保存参数。然后再针对输入输出的路径进行判断是否为空,防止用户输入错误。按照题目要求 -i和-o参数是必须要有的但是-m和-n的组合会出现三种情况,所以要再次使用分支语句进行判断。//对-i、-m、-n、-o参数识别并保存他们后面的输入值
for (int i = 0; i < args.Length; i++)
{
if (args[i] == "-i")
pathInput = args[++i];
else if (args[i] == "-m")
num1 = Convert.ToInt32(args[++i]);
else if (args[i] == "-o")
PathOutput = args[++i];
else if (args[i] == "-n")
num2 = Convert.ToInt32(args[++i]);
} -
按照相应参数生成词组(-m)
我使用嵌套循环实现了单词组合成数组,并且存入新的字符串数组中。同时对新生成的词组计数。只需要找到文档中单词个数、命令行输入参数-m、外层循环次数的数学关系,外层循环次数代表着生成多少个词组也意味着在那里停止不会越界;内层循环则代表着由单词组合成一个词组需要循环几次也要计算循环次数和-m参数的数学关系关系。//嵌套循环生成词组
for(int i=0;i<oldWord.Length-num1+1;i++)
{
for(int j=0;j<num1;j++)
{
newWord[i] += ' '+oldWord[i+j];
}countNum++;
} -
按照参数输出高频次数个数(-n)
在子类的countFrequency中我们设计了统计了单词出现频率平且使用双关键词排序的方法实现频率和字典排序,所以在设计-n这个附加功能时只需要将 -n的参数传入子类方法就可以实现。可以说之前的框架设计在这里起到了很大的作用。
-
五、代码规范
- 缩进问题:采用4个空格
- 每条语句单独占一行,一个‘{’占一行;同类变量可以在一行定义多个
- 命名方式:变量定义采用驼峰命名法(如stuNum)、类名方法名首字母也要大写(如DoSomething)、所有名字中不加下划线
- 注释:方法前用序言性注释(说明功能)、变量前用功能性注释
- 代码设计规范:方法满足单一功能性(只做一件事,并且要做好)、函数要有单一出口、体现面向对象原则
六、代码互审
互审过程中我们发现了很多的问下,下面我们就分享一下这些问题和解决方式:
- 在我审查同伴代码时出现的一些问题:
1、四个基础功能函数没有设计合理的返回值。后续改进:添加了相应返回值,方便了模块交互。
2、在countWord函数中一开始没有设计,单词长度应超过四个字符的需求。后续改进:增加了对单词长度的判断。
3、在countLine函数中最开始没有想到空白行不能计入行数的问题。后续改进:采用先将文本中的空白行剔除,再计算行数的方法。
4、在countFrequency函数中,最初没有针对在单词出现相同频率时按照字典顺序排序。后续改进:采用双关键词排序的方式优先对频率排序再对字典顺序排序。
- 同伴对我代码的复审:同伴博客
互审总结:我认为最结对编程中最重要的一部分就是代码互审,真正的做到1+1>2就是通过代码互审实现的。其实在结对编程的初期我们就都出现了一样的问题,因为这次我们使用github合作编程,每个人提交和下载代码时,经常会出现无法成功pull的问题。在我们一段时间的合作以后慢慢的才理顺了提交顺序。使用git来记录我们的合作过程也是非常重要的结对编程环节。
七、单元测试及异常处理
单元测试:
-
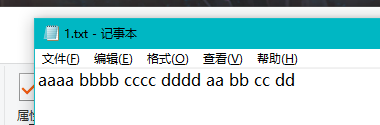
对单词长度是否超过四字符及但此前四位是否都为字母的测试代码(countWord()):
public void CountWordTest()
{
BasisFunction basisFunction = new BasisFunction();
string[] word = { "aaaa", "bbbb", "cccc", "dddd" };//测试1 测试CountWord方法得到的结果单词字符长度是否超过4
string content1 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\1.txt");
for (int i = 0; i < 4; i++)
{
Assert.AreEqual(word[i], basisFunction.CountWord(content1)[i]);
}//测试2 测试CountWord方法得到的结果单词前四位是否都为字母
string content2 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\2.txt");
for (int i = 0; i < 4; i++)
{
Assert.AreEqual(word[i], basisFunction.CountWord(content2)[i]);
}
} -
下面是这两个测试的文本:
![]()
![]()

-
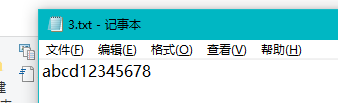
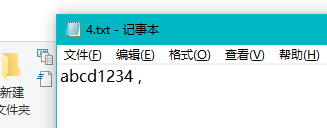
对于字符数是否包含特殊字符的测试(countChar()):
public void CountCharTest()
{
BasisFunction basisFunction = new BasisFunction();
int charNum = 12;//测试3 测试CountChar方法得到的结果字符数是否正确(不含特殊字符)
string content3 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\3.txt");
Assert.AreEqual(charNum, basisFunction.CountChar(content3));//测试4 测试CountChar方法得到的结果字符数是否正确(含特殊字符)
string content4 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\4.txt");
Assert.AreEqual(charNum, basisFunction.CountChar(content4));
} -
下面是这两个测试的文本:
![]()
![]()
-
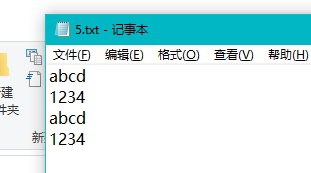
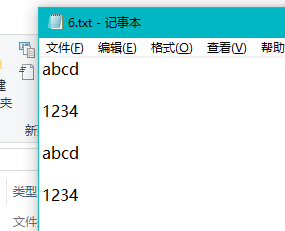
对于行数是否包含空白行的测试(countLine()):
public void CountLineTest()
{
BasisFunction basisFunction = new BasisFunction();
int lineNum = 4;//测试5 测试CountLine方法得到的结果行数是否正确(不含空行)
string content5 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\5.txt");
Assert.AreEqual(lineNum, basisFunction.CountLine(content5));//测试6 测试CountLine方法得到的结果行数是否正确(含空行)
string content6 = File.ReadAllText(@"C:\Users\charm\Desktop\charm\6.txt");
Assert.AreEqual(lineNum, basisFunction.CountLine(content6));
} -
下面是这两个测试的文本:
![]()
![]()
-
对于字典排序顺序和频率排序顺序的测试(countFrequency()):
public void CountFrequencyTest()
{
BasisFunction basisFunction = new BasisFunction();
string[] test = { "aaaa", "aaaa", "aaaa", "aaaa", "bbbb", "bbbb", "bbbb", "cccc", "cccc", "dddd" };
string[] word = { "aaaa", "bbbb", "cccc", "dddd" };
int[] frequency = { 4, 3, 2, 1 };
var result = basisFunction.CountFrequency(test, 4);//测试7 测试CountFrequency方法得到的结果单词排序是否正确
int count = 0;
foreach (KeyValuePair<string, int> kvp in result)
{
Assert.AreEqual(word[count], kvp.Key);
count++;
}//测试8 测试CountFrequency方法得到的结果单词频率排序是否正确
count = 0;
foreach (KeyValuePair<string, int> kvp in result)
{
Assert.AreEqual(frequency[count], kvp.Value);
count++;
}
} -
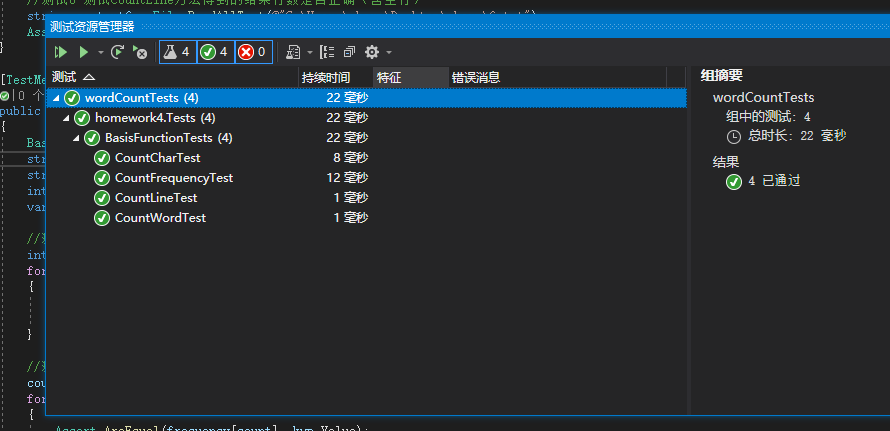
最终测试结果:
![]()
异常处理:
-
写入文档时异常处理及异常处理的单元测试:
-
代码设计:
public bool writeToFile(string content, string pathOutput)
{
bool test = false;
try
{
if (content != null)
{
test = true;
using (StreamWriter sw = new StreamWriter(pathOutput, true))
{
sw.WriteLine(content);
}
}
}
catch
{
Console.WriteLine("写入文档失败!");
}
return test;
} -
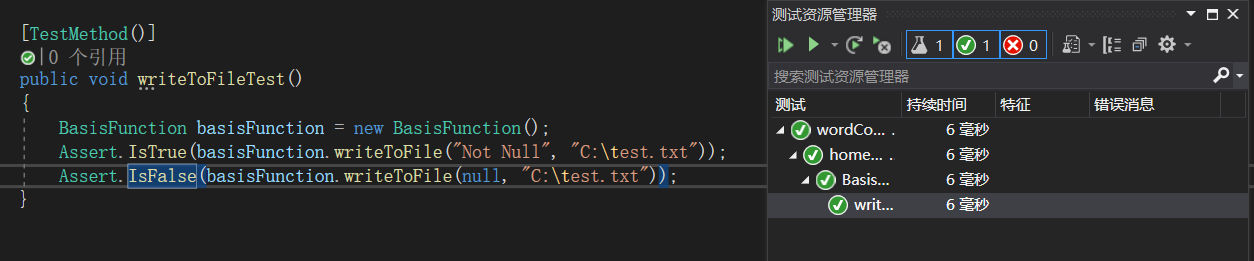
测试设计和运行:
![]()
-
-
读取文档路径是否存在的测试:
-
代码设计:
public bool ReadFile()
{
string path;
Console.WriteLine("请输入需要读取的文档的路径:");
path = Console.ReadLine();
bool test=false;
try
{
if (File.Exists(path))
{
test = true;
string content;
content = File.ReadAllText(path);
Console.WriteLine("文档处理完成!");
ProcessDoc(content);
}
}
catch
{
Console.WriteLine("文档不存在!");
}
return test;
} -
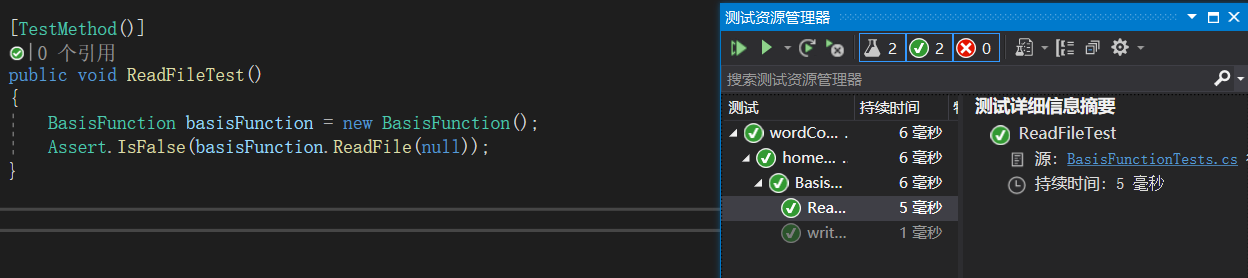
测试设计和运行:
![]()
-
-
测试心得:我们尽可能多的测试了代码中重要功能的,保证我们的代码正确率和合理性。提供多个不同文档对不同功能的测试是很重要的。
对于异常处理的设计有几点想要分享:
1、如果无法处理某个异常,那就不要捕获它; 尽量在靠近异常被抛出的地方捕获异常。2、并不是很多都必须加入异常,因为异常处理的增加会导致性能的下降。当然如果对性能没有特殊要求,在一些重要的地方还是要加入异常处理
3、我们这次设计针对文件读写的时候加入异常处理,防止读取时文件不存在,文件写入时没内容。
八、性能测试及改进
改进花费时间:25mins
-
含命令行参数测试:
![]()
![]()
-
不含命令行测试:
![]()
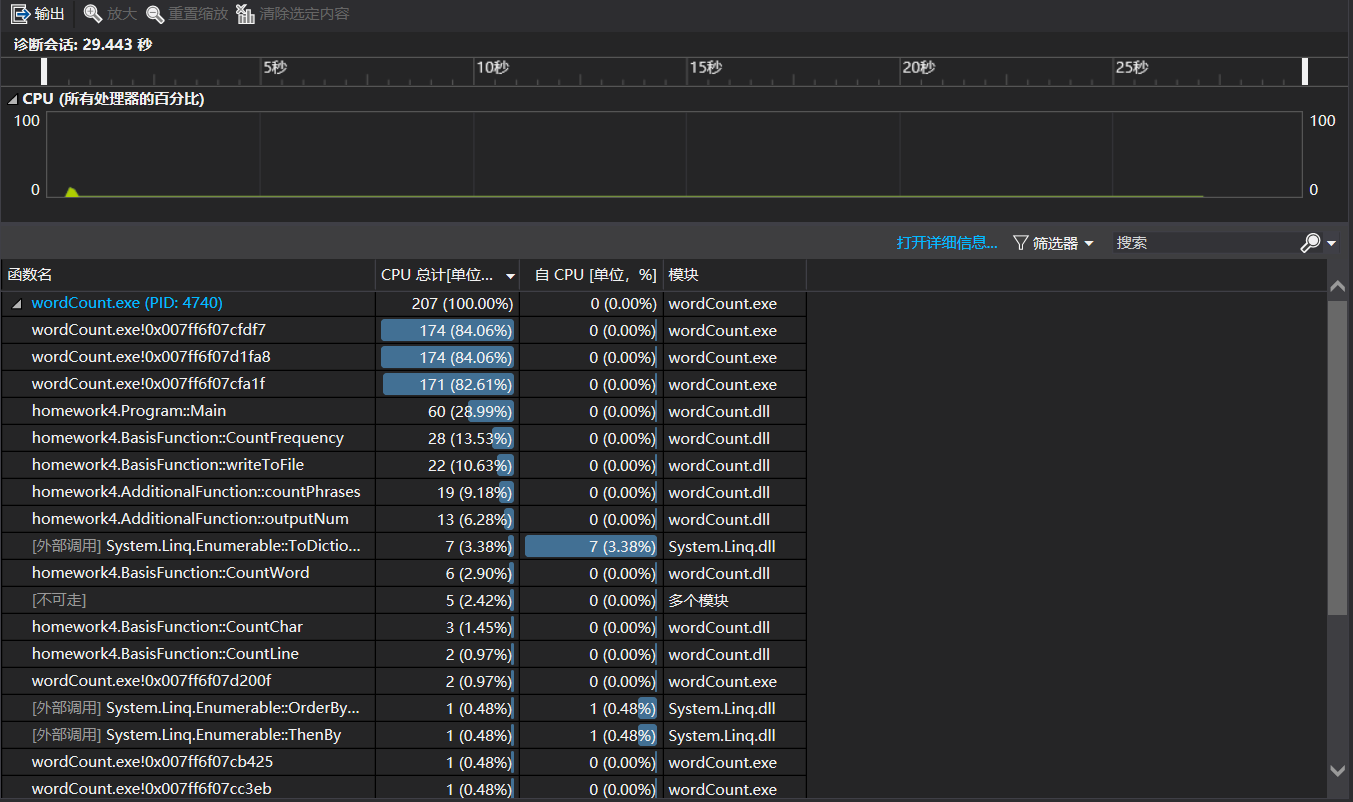
改进方案:在countWord()中改变判断单词的语句,用正则表达式替代了循环嵌套来匹配长度大于四且开头不是数字的单词。性能有所提升:
![]()
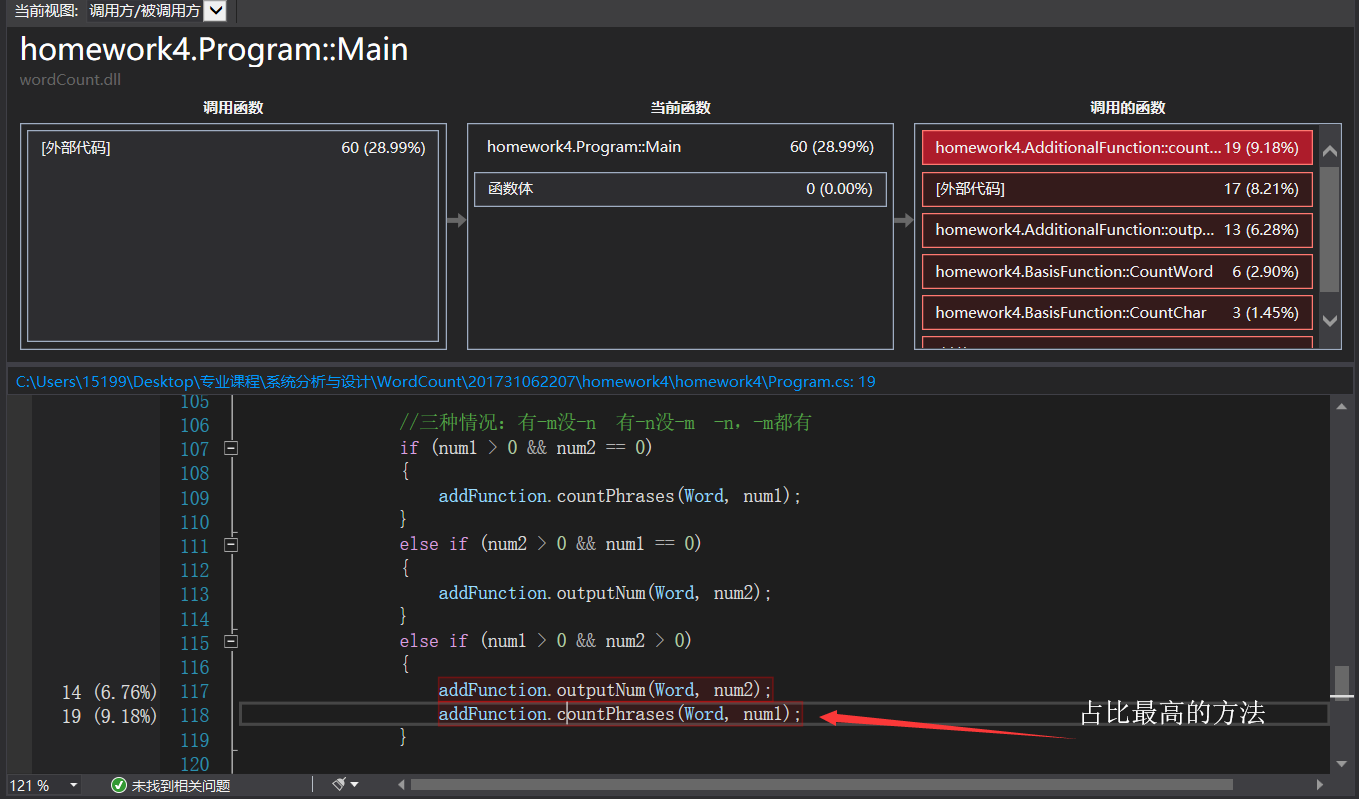
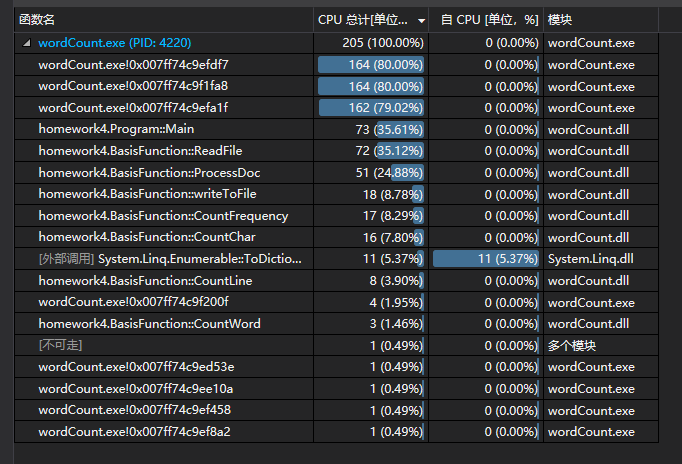
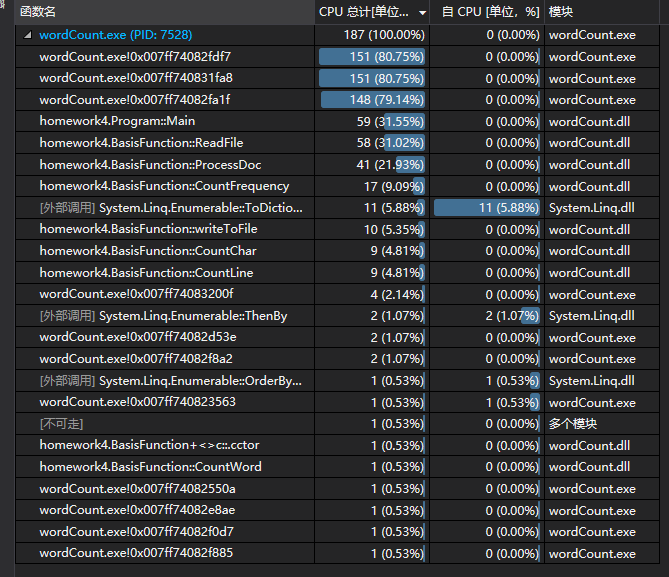
九、代码展示及程序运行结果截图
-
countChar:
public int CountChar(string content)
{
int charNum;
charNum = content.Length;
Console.WriteLine("字符数:" + charNum);
writeToFile("字符数:" + charNum, Program.PathOutput);return charNum;
} -
countLine:
public int CountLine(string content)
{
string temp = Regex.Replace(content, @"\n\s*\n", "\r\n");int lineNum = temp.Split('\n').Length;
Console.WriteLine("行数:" + lineNum);
writeToFile("行数:" + lineNum, Program.PathOutput);return lineNum;
} -
countWord:
public string[] CountWord(string content)
{
string lowContent;
lowContent = content.ToLower();string[] allWord = Regex.Split(lowContent, @"\W+");
string[] rightWord = new string[allWord.Length];
int num = 0;
for (int i = 0; i < allWord.Length; i++)
{
if (Regex.IsMatch(allWord[i], @"[1][a-z][a-z][a-z]"))
{
rightWord[num] = allWord[i];
num++;
}
}string[] word = new string[num];
for (int i = 0; i < num; i++)
{
word[i] = rightWord[i];
}Console.WriteLine("单词数:" + num);
writeToFile("单词数:" + num, Program.PathOutput);return word;
} -
countFrequency:
public Dictionary<string, int> CountFrequency(string[] word, int outNum)
{
Dictionary<string, int> wordAndFrequency = new Dictionary<string, int>();
for (int i = 0; i < word.Length; i++)
{
if (wordAndFrequency.ContainsKey(word[i]))
{
wordAndFrequency[word[i]]++;
}
else
{
wordAndFrequency[word[i]] = 1;
}
}var result = wordAndFrequency.OrderByDescending(o => o.Value).ThenBy(o => o.Key).ToDictionary(o => o.Key, p => p.Value);
int count = 0;
foreach (KeyValuePair<string, int> kvp in result)
{
Console.WriteLine(kvp.Key + ":" + kvp.Value);
writeToFile(kvp.Key + ":" + kvp.Value, Program.PathOutput);
count++;
if (count == outNum)
{
break;
}
}return result;
} -
结果:
![]()
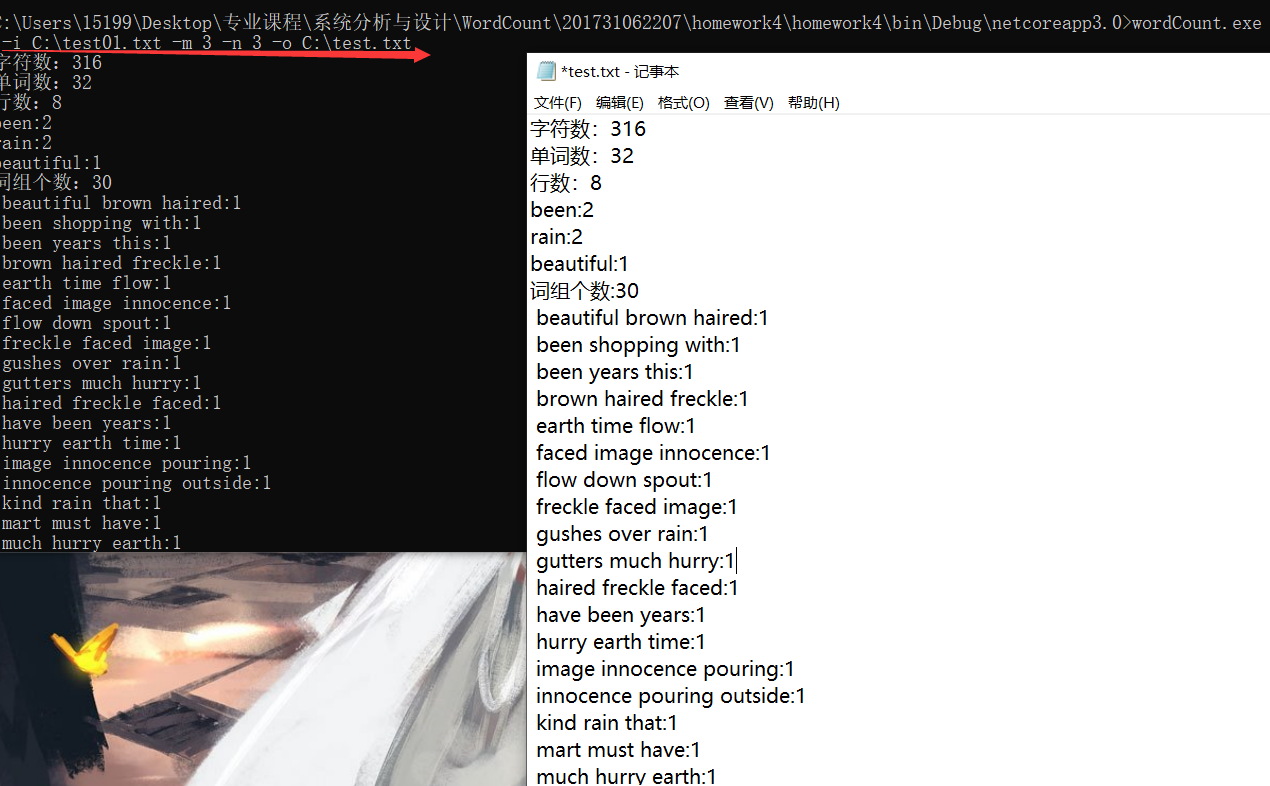
十、心得总结
这次结对编程收获很多,原来也有很对合作敲代码的时候,但是都缺少代码规范。往往是想到哪里敲哪里,分工也很随意。这些问题都导致编程过程中出现不好解决的问题,但是按照结对编程要求我们可以规范自己编码行为和合理分工。在git的使用上也让代码的传递更加的方便。最重要的还是代码互审阶段解决了我们互相出现的7个问题,使我们项目一步一步的完善。在项目完成之后我们计算了实际的时间发现在编码部分比预计多出了200分钟,其实我认为并不是我们低效了,而是我们采用的即时代码互审起了很大的作用,能随时防止我们从错误的方向上越走越远,及时纠正错误和思路让我们避免了返工。我想如果发生返工的问题那么就会花更多的时间了!在代码测试环节也比预期的想的要多一些,因为为了保证测试的全面性,花了一些时间在测试代码的设计上。希望以后也有更多的结对编程机会!
a-z ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号