
csv
import csv
csvFile = open("csvData.csv", "w") #创建csv文件
writer = csv.writer(csvFile) #创建写的对象
#先写入columns_name
writer.writerow(["index","a_name","b_name"]) #写入列的名称
#写入多行用writerows #写入多行
writer.writerows([[1,a,b],[2,c,d],[3,d,e]])
csvFile.close()
import pandas as pd
columns = ['image_id', 'Prediction']
dictory = {'image_id': img_name, 'Prediction': Prediction}
dataframe = pd.DataFrame(dictory, columns=columns)
dataframe.to_csv("submit/submit_test.csv", index=False, sep=',')df = pd.read_csv('filename')
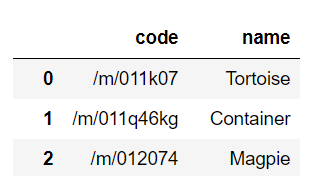
df = pd.read_csv('filename', header=None)
df = pd.read_csv('filename', header=None, names=['code', 'name'])
classlist=classid['code'].tolist()
namelist=classid['name'].tolist()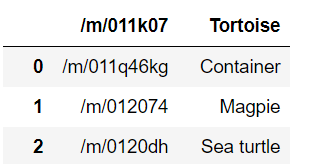

UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
open(filename,'wb')pkl
import pickle
file = './second_stage_benchmark.pkl'
f = open(file,'rb')
data = pickle.load(f) json
json.load(open(test_json_path, "rb"))txt
路径
os.path.split() #分离文件名
os.path.splitext() #分离后缀
os.path,join()
In [1]: import os
In [2]: f = '1/2/3.4.5'
In [3]: os.path.split(f)
Out[3]: ('1/2', '3.4.5')
In [4]: os.path.splitext(f)
Out[4]: ('1/2/3.4', '.5')
文件复制
import shutil
old_path = ''
new_path = ''
shutil.copyfile(old_path, new_path)

