参考:
https://blog.csdn.net/chenyj92/article/details/53448161
https://www.jianshu.com/p/295dcc4008b4
https://blog.csdn.net/Dlyldxwl/article/details/81148810
https://blog.csdn.net/baidu_38270845/article/details/102631140
deeplab V1
backbone:
VGG-16 + CRF
最后两层max pooling (pool4, pool5) 的 stride = 1
最后三个conv层(conv5_1、conv5_2、conv5_3)的dilate rate设置为2,第一个全连接层的dilate rate设置为4
during training
target 为 GT label subsampled by 8
batch size = 20
initial learning rate = 0.001 (0.01 for the final classifier layer)
multiplying the learning rate by 0.1 at every 2000 iterations
momentum = 0.9, weight decay = 0.0005
during testing
最后输出feature map下采样8倍,直接 bilinear interpolation 上采样8倍回到原resolution
Multi-scale prediction
input image, four max pooling layers 后接 2-layer MLP (128 3x3, 128 1x1), concate -> 5x128 = 640 channels
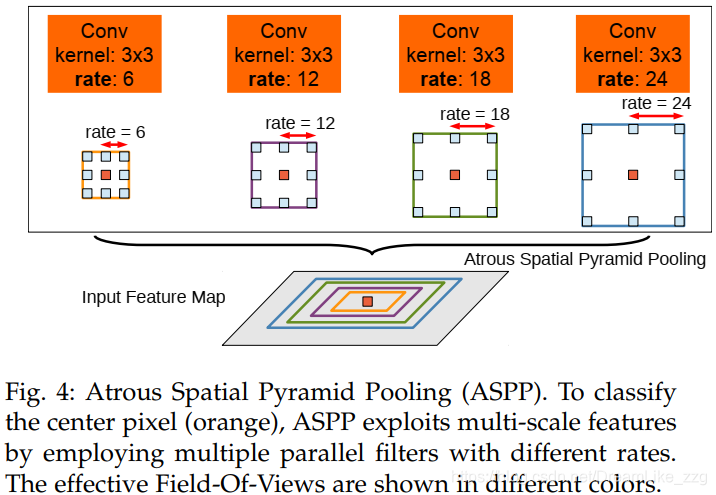
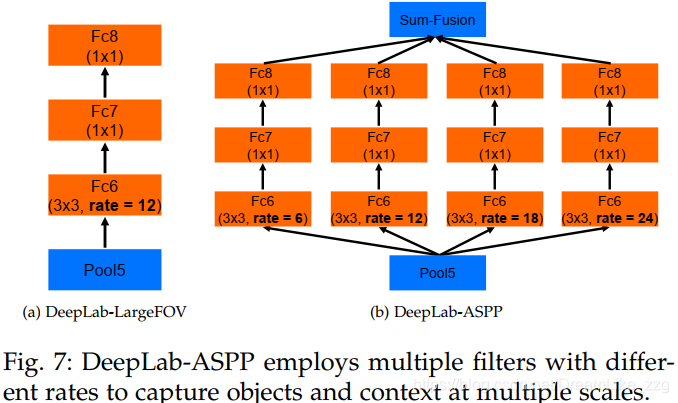
deeplabV2
ASSP