

MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017.04)

1、使用 depthwise conv + pointwise conv代替 standard conv,需要有DW优化支持的平台上才能显出speed。
计算量减少比例:
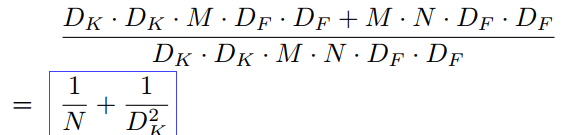
计算量和参数量主要集中在 pointwise conv上,pointwise conv不需要im2col操作,

2、两个超参调解channel和resolution:width multiplier α and resolution multiplier ρ, 参数减少程度为α^2、ρ^2![]()
3、由于模型小,训练时很多tricks没有用,见论文3.2
4、使用relu6,在float16/int8的嵌入式设备中效果较好
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (2017.07)
motivation
For each residual unit in ResNeXt the pointwise convolutions occupy 93.4% multiplication-adds.
A straightforward solution is to apply channel sparse connections.
There is one side effect: outputs from a certain channel are only derived from a small fraction of input channels
提出 channel shuffle。改进resnet
difficult to efficiently implement depthwise convolution on lowpower mobile devices, which may result from a worse computation/memory access ratio compared with other dense operations. 所以只在bottleneck中使用。

def channel_shuffle(x, groups):
"""
Parameters
x: Input tensor of with `channels_last` data format
groups: int number of groups per channel
Returns
channel shuffled output tensor
Examples
Example for a 1D Array with 3 groups
>>> d = np.array([0,1,2,3,4,5,6,7,8])
>>> x = np.reshape(d, (3,3))
>>> x = np.transpose(x, [1,0])
>>> x = np.reshape(x, (9,))
'[0 1 2 3 4 5 6 7 8] --> [0 3 6 1 4 7 2 5 8]'
"""
height, width, in_channels = x.shape.as_list()[1:]
channels_per_group = in_channels // groups
x = K.reshape(x, [-1, height, width, groups, channels_per_group])
x = K.permute_dimensions(x, (0, 1, 2, 4, 3)) # transpose
x = K.reshape(x, [-1, height, width, in_channels])
return x
MobileNetV2: Inverted Residuals and Linear Bottlenecks (2019.03)
深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的,作者认为这是ReLU导致。
Relu会对低维embed造成信息丢失。
https://www.zhihu.com/question/265709710/answer/298245276
Depthwise Conv确实是大大降低了计算量, 而且NxN Depthwise + 1X1 PointWise的结构在性能上也能接近NxN Conv。 在实际使用的时候, 我们发现Depthwise 部分的kernel比较容易训废掉: 训完之后发现depthwise训出来的kernel有不少是空的... 当时我们认为是因为depthwise每个kernel dim 相对于vanilla conv要小得多, 过小的kernel_dim, 加上ReLU的激活影响下, 使得神经元输出很容易变为0, 所以就学废了: ReLU对于0的输出的梯度为0, 所以一旦陷入了0输出, 就没法恢复了。 我们还发现,这个问题在定点化低精度训练的时候会进一步放大。

方案:inverted residuals 升维(channel) + Linear Bottlenecks 丢弃最后Relu6。
channel数减少可以减少skip branch的带宽。(带宽是指从cache写入DDR的带宽。 假设我们把旁路的多个卷积on the fly去做, 那么读写的带宽需求是: input 读, eltwise 加的时候主路feature读, 以及eltwise 输出的写。 v2的特典是eltwise部分channel少, 所以省带宽。)
另外该backbone也可用于det和seg task


ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design (2018.06)
motivation:
1、FLOPs is an indirect metric.
First, several important factors that have considerable affection on speed are not taken into account by FLOPs.
Second, operations with the same FLOPs could have different running time, depending on the platform.
2、two principles should be considered
First, the direct metric.
Second, such metric should be evaluated on the target platform.
论文将memory access cost (MAC)纳入考虑因素,并分别在GPU和ARM上实验,提出4条Guidelines

G1) Equal channel width minimizes memory access cost (MAC)
G2) Excessive group convolution increases MAC
G3) Network fragmentation reduces degree of parallelism.
G4) Element-wise operations are non-negligible.
由此设计结构:

好处:
main branch 的3个conv channel相同(G1)
two 1 × 1 convolutions are no longer group-wise, (G2)
跳连 identity(G3,G4)
Concat(G4)
Why accurate?
1、more feature channels
2、feature reuse. 只有一半的channel跳连,符合connections between the adjacent layers are stronger than the others
Searching for MobilenetV3 (2019.05)
结构:


Redesigning Expensive Layers
头部:channel 32 -> 16,relu -> h-swis
尾部:pooling提前,升1280 channel 时由7x7 -> 1x1,在不会造成精度损失的同时,减少10ms耗时,提速15%,减小了30m的MAdd操作。

激活函数 h-swish:
most of the benefits swish are realized by using them only in the deeper layers.
we only use h-swish at the second half of the model.
Large squeeze-and-excite:
1/4 of the number of channels in expansion layer

Segmentation
1、trained from scratch without pretraining
2、apply atrous convolution to the last block of MobileNetV3
3、last block channel x0.5 没有明显影响,论文认为original designed for 1000 classes,segmentation only 19 classes.


参考:
轻量级神经网络“巡礼”(一)—— ShuffleNetV2
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3
轻量化网络ShuffleNet MobileNet v1/v2 解析
ShuffNet v1 和 ShuffleNet v2
为什么depthwise convolution 比 convolution更加耗时?
如何评价mobilenet v2 ?
Why MobileNet and Its Variants (e.g. ShuffleNet) Are Fast

