【Clickhouse】Clickhouse 存储结构及文件分析
测试版本:22.3.3.2
测试环境:MacBookPro M1
1. Clickhouse 数据目录结构
默认clickhouse数据目录/var/lib/clickhouse,数据部分存储在/var/lib/clickhouse/data下
root@b6d725df80c8:/var/lib/clickhouse# ll
total 12
drwxr-xr-x 17 clickhouse clickhouse 544 Apr 10 14:00 ./
drwxr-xr-x 1 root root 4096 Apr 6 16:11 ../
drwxr-x--- 7 root root 224 Apr 10 14:00 access/
drwxr-x--- 4 root root 128 Apr 10 14:00 data/
drwxr-x--- 2 clickhouse clickhouse 64 Apr 10 14:00 dictionaries_lib/
drwxr-x--- 2 clickhouse clickhouse 64 Apr 10 14:00 flags/
drwxr-xr-x 2 clickhouse clickhouse 64 Apr 10 14:00 format_schemas/
drwxr-x--- 8 root root 256 Apr 10 14:00 metadata/
drwxr-x--- 2 root root 64 Apr 10 14:00 metadata_dropped/
drwxr-x--- 4 root root 128 Apr 10 14:00 preprocessed_configs/
-rw-r----- 1 clickhouse clickhouse 55 Apr 10 14:00 status
drwxr-x--- 10 root root 320 Apr 10 14:01 store/
drwxr-xr-x 2 clickhouse clickhouse 64 Apr 10 14:00 tmp/
drwxr-x--- 2 root root 64 Apr 10 14:00 user_defined/
drwxr-xr-x 2 clickhouse clickhouse 64 Apr 10 14:00 user_files/
drwxr-x--- 2 clickhouse clickhouse 64 Apr 10 14:00 user_scripts/
-rw-r----- 1 root root 36 Apr 10 14:00 uuid
# 数据部分存储目录:数据库/表/分区文件
root@b6d725df80c8:/var/lib/clickhouse/data# ll
total 0
drwxr-x--- 4 root root 128 Apr 10 14:00 ./
drwxr-xr-x 17 clickhouse clickhouse 544 Apr 10 14:00 ../
drwxr-x--- 7 clickhouse clickhouse 224 Apr 19 11:11 default/
drwxr-x--- 2 root root 64 Apr 28 01:01 system/
root@b6d725df80c8:/var/lib/clickhouse/data/default# ll
total 0
drwxr-x--- 7 root root 224 Apr 19 11:11 ./
drwxr-x--- 4 root root 128 Apr 10 14:00 ../
lrwxr-xr-x 1 root root 67 Apr 19 11:11 test_merge_tree -> /var/lib/clickhouse/store/f60/f60de9d8-27e0-4f7e-820d-6112d915cf30//
lrwxr-xr-x 1 root root 67 Apr 13 01:07 t_order -> /var/lib/clickhouse/store/407/40727376-3e59-4564-b985-7687204d1201//
lrwxr-xr-x 1 root root 67 Apr 12 13:13 t_order_mt -> /var/lib/clickhouse/store/437/437dbddb-e8bf-412a-b3db-de41cfe0d2bb//
lrwxr-xr-x 1 root root 67 Apr 19 09:17 t_order_mt3 -> /var/lib/clickhouse/store/543/5438bf9d-129a-4295-a840-302f4de12b5f//
lrwxr-xr-x 1 root root 67 Apr 14 01:38 t_users -> /var/lib/clickhouse/store/4a4/4a4df8a5-2b5e-43a3-96c6-a442fd0a608b//
2. Clickhouse表目录结构
2.1 数据部分存储格式
一张表的完整物理结构分为三级:数据表目录/分区目录/各分区下数据文件。
分区文件数据部分有两种存储格式:
Wide格式:每一列都存储在文件系统中的单独文件中
Compact格式:所有列都存储在一个文件中。Compact格式可用于提高小而频繁插入的性能。
数据存储格式由表引擎的min_bytes_for_wide_part和min_rows_for_wide_part控制:
- 如果数据部分中的字节数或行数少于相应设置的值,则该部分以Compact格式存储。否则以Wide格式存储。
- 如果未设置这些设置,则数据部分以Wide格式存储。
2.1.1 Wide格式存储数据
2.1.1.1 建表使Wide格式存储
可通过参数min_bytes_for_wide_part = 0或min_rows_for_wide_part=0使其强制使用Wide格式
CREATE TABLE test_merge_tree
(
Id UInt64,
Birthday Date,
Name String,
INDEX a Birthday TYPE minmax GRANULARITY 3
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(Birthday)
ORDER BY (Id, Name)
SETTINGS index_granularity = 2, min_compress_block_size = 24, min_bytes_for_wide_part = 0;
insert into test_merge_tree values
(1,'1988-01-01','lilei'),
(2,'1998-03-03','zhangsan'),
(3,'2000-01-02','lisi'),
(4,'2000-01-03','wangwu'),
(5,'2000-01-04','mike'),
(6,'2000-02-03','jack');
2.1.1.2 Wide存储格式目录样式
root@b6d725df80c8:/var/lib/clickhouse/data/default/test_merge_tree# ll
total 4
drwxr-x--- 8 clickhouse clickhouse 256 Apr 19 11:11 ./
drwxr-x--- 3 root root 96 Apr 19 11:11 ../
drwxr-x--- 17 root root 544 Apr 19 11:11 198801_1_1_0/
drwxr-x--- 17 root root 544 Apr 19 11:11 199803_2_2_0/
drwxr-x--- 17 root root 544 Apr 19 11:11 200001_3_3_0/
drwxr-x--- 17 root root 544 Apr 19 11:11 200002_4_4_0/
drwxr-x--- 2 clickhouse clickhouse 64 Apr 19 11:11 detached/
-rw-r----- 1 root root 1 Apr 19 11:11 format_version.txt
root@b6d725df80c8:/var/lib/clickhouse/data/default/test_merge_tree/200001_3_3_0# ll
total 60
drwxr-x--- 17 root root 544 Apr 19 11:11 ./
drwxr-x--- 8 clickhouse clickhouse 256 Apr 19 11:11 ../
-rw-r----- 1 root root 32 Apr 19 11:11 Birthday.bin
-rw-r----- 1 root root 72 Apr 19 11:11 Birthday.mrk2
-rw-r----- 1 root root 448 Apr 19 11:11 checksums.txt
-rw-r----- 1 root root 79 Apr 19 11:11 columns.txt
-rw-r----- 1 root root 1 Apr 19 11:11 count.txt
-rw-r----- 1 root root 10 Apr 19 11:11 default_compression_codec.txt
-rw-r----- 1 root root 44 Apr 19 11:11 Id.bin
-rw-r----- 1 root root 72 Apr 19 11:11 Id.mrk2
-rw-r----- 1 root root 4 Apr 19 11:11 minmax_Birthday.idx
-rw-r----- 1 root root 44 Apr 19 11:11 Name.bin
-rw-r----- 1 root root 72 Apr 19 11:11 Name.mrk2
-rw-r----- 1 root root 4 Apr 19 11:11 partition.dat
-rw-r----- 1 root root 39 Apr 19 11:11 primary.idx
-rw-r----- 1 root root 30 Apr 19 11:11 skp_idx_a.idx2
-rw-r----- 1 root root 24 Apr 19 11:11 skp_idx_a.mrk2
2.1.2 Compact格式存储数据
2.1.2.1 建表使Compact格式存储
可通过参数min_bytes_for_wide_part = 比较大的值或min_rows_for_wide_part=比较大的值使其强制使用Compact格式
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTree
partition by toYYYYMMDD(create_time)
order by (id,sku_id)
SETTINGS index_granularity_bytes=1024;
insert into t_order_mt3 values
(101,'sku_001',1000.00,'2022-04-01 12:00:00') ,
(102,'sku_002',2000.00,'2022-04-01 11:00:00'),
(102,'sku_004',2500.00,'2022-04-01 12:00:00'),
(102,'sku_002',2000.00,'2022-04-01 13:00:00'),
(102,'sku_002',12000.00,'2022-04-01 13:00:00'),
(102,'sku_002',600.00,'2022-04-02 12:00:00');
2.1.2.2 Compact存储格式目录样式
root@b6d725df80c8:/var/lib/clickhouse/data/default/t_order_mt3# ll
total 4
drwxr-x--- 6 clickhouse clickhouse 192 Apr 19 09:18 ./
drwxr-x--- 3 root root 96 Apr 19 09:17 ../
drwxr-x--- 13 root root 416 Apr 19 09:18 20220401_1_1_0/
drwxr-x--- 13 root root 416 Apr 19 09:18 20220402_2_2_0/
drwxr-x--- 2 clickhouse clickhouse 64 Apr 19 09:17 detached/
-rw-r----- 1 root root 1 Apr 19 09:17 format_version.txt
root@b6d725df80c8:/var/lib/clickhouse/data/default/t_order_mt3/20220401_1_1_0# ll
total 44
drwxr-x--- 13 root root 416 Apr 19 09:18 ./
drwxr-x--- 6 clickhouse clickhouse 192 Apr 19 09:18 ../
-rw-r----- 1 root root 335 Apr 19 09:18 checksums.txt
-rw-r----- 1 root root 118 Apr 19 09:18 columns.txt
-rw-r----- 1 root root 1 Apr 19 09:18 count.txt
-rw-r----- 1 root root 189 Apr 19 09:18 data.bin
-rw-r----- 1 root root 144 Apr 19 09:18 data.mrk3
-rw-r----- 1 root root 10 Apr 19 09:18 default_compression_codec.txt
-rw-r----- 1 root root 8 Apr 19 09:18 minmax_create_time.idx
-rw-r----- 1 root root 4 Apr 19 09:18 partition.dat
-rw-r----- 1 root root 24 Apr 19 09:18 primary.idx
-rw-r----- 1 root root 41 Apr 19 09:18 skp_idx_a.idx2
-rw-r----- 1 root root 24 Apr 19 09:18 skp_idx_a.mrk3
2.2 二进制文件介绍
关于分区目录命令规则,分区合并这里不再缀述,研究一下分区目录下文件中到底都存了些啥。
分区文件列表如下:
这里以Wide存储格式文件查看为例
以下均以该分区为例:/var/lib/clickhouse/data/default/test_merge_tree/200001_3_3_0
2.2.1 checksums.txt
$ od -An -c checksums.txt
c h e c k s u m s f o r m a t
v e r s i o n : 4 \n 243 224 272 261
r 300 6 3 \b 200 206 305 a 357 200 I 202 224 001 \0
\0 260 001 \0 \0 365 # \f \f B i r t h d a
y . b i n 252 \ 255 354 354 s 344 H 315 k
227 346 [ 001 365 371 001 006 001 356 300 226 * B 315 321
f R 262 k 344 p 230 001 \r 0 \0 360 \n m r k
2 H 004 : 311 027 s 305 004 300 g | 034 [ 2 316
224 i \0 006 I d J \0 362 027 , 217 q ; 213 :
231 / 353 \r 265 r \f M 331 g 265 001 030 017 x 4
364 343 I = . 202 342 K g 375 302 034 342 \a I d
D \0 361 \a o i 341 u 366 034 [ 4 252 335 304 341
w 353 w \0 \b N a m e F \0 361 024 y 032
210 203 B 367 z S 2 / c O 246 265 3 322 001 021
334 351 215 372 206 325 357 035 k m 0 034 002 1 = 257
\t , \0 001 H \0 365 & 370 370 004 2 335 236 e 326
g / 032 214 252 s R 277 \0 \t c o u n t .
t x t 001 w 267 225 004 E 270 371 275 + 253 F 313
377 023 { 333 \0 023 m i n m a x _ 317 \0 361
- i d x 004 331 y 321 P 235 225 362 z j 203 +
341 027 ~ 205 > \0 \r p a r t i t i o n
. d a t 004 y 372 307 f ? 301 036 L H 337 342
203 031 207 334 K \0 \v p r i m a r > \0 375
$ ' 317 b ? ) 027 317 271 312 020 ' 237 0 ; 223
004 257 \0 016 s k p _ i d x _ a . i d
x 2 036 216 | B v 202 264 373 200 312 031 h < 327
316 v J 001 q \0 \a 2 \0 \0 323 \0 360 003 030 374
273 A 371 323 242 Z 306 235 341 200 204 [ 266 312 x \0
2.2.2 partition.dat
分区信息文件,用来保存当前分区下分区表达式最终生成的值(或者干脆理解成partition_id),使用二进制格式进行存储.
$ od -An -l partition.dat
200001
2.2.3 columns.txt
$ cat columns.txt
columns format version: 1
3 columns:
`Id` UInt64
`Birthday` Date
`Name` String
2.2.4 count.txt
该分区数据行数
$ cat count.txt
3
2.2.5 default_compression_codec.txt
数据压缩算法
$ cat default_compression_codec.txt
CODEC(LZ4)
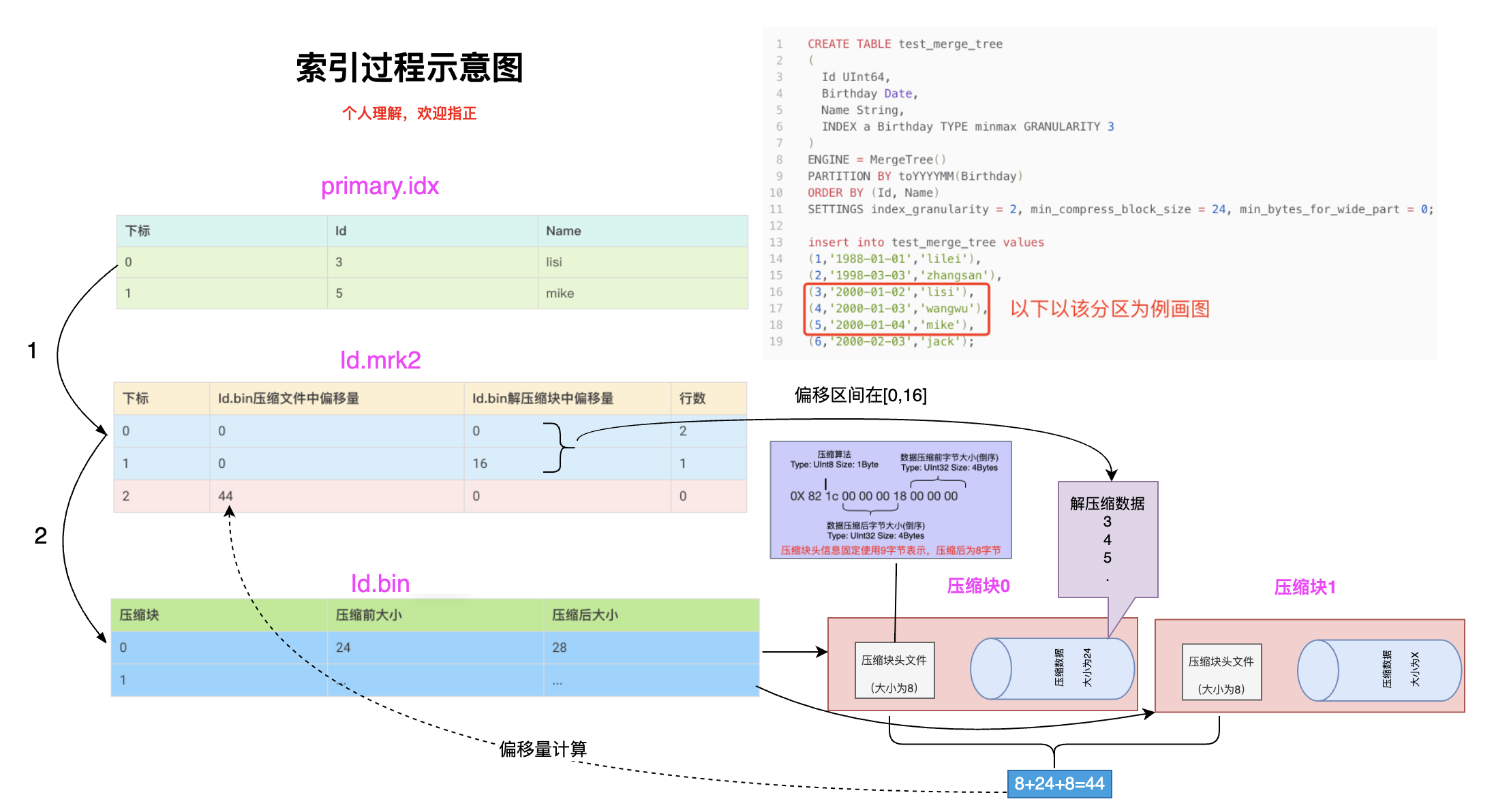
2.2.6 primary.idx
# od -An -td4 -w4 primary.idx
$ hexdump -C primary.idx
00000000 03 00 00 00 00 00 00 00 04 6c 69 73 69 05 00 00 |.........lisi...|
00000010 00 00 00 00 00 04 6d 69 6b 65 05 00 00 00 00 00 |......mike......|
00000020 00 00 04 6d 69 6b 65 |...mike|
00000027
# 该分区的三条数据
(3,'2000-01-02','lisi'),
(4,'2000-01-03','wangwu'),
(5,'2000-01-04','mike'),
# $ hexdump -C primary.idx
# 00000000 03 00 00 00 00 00 00 00 09 68 61 6e 6d 65 69 6d |.........hanmeim|
# 00000010 65 69 05 00 00 00 00 00 00 00 06 77 61 6e 67 77 |ei.........wangw|
# 00000020 75 05 00 00 00 00 00 00 00 06 77 61 6e 67 77 75 |u.........wangwu|
# 00000030
MergeTree表会按照主键字段生成primary.idx,200001_3_3_0分区下数据有:
(3,'2000-01-02','lisi')
(4,'2000-01-03','wangwu')
(5,'2000-01-04','mike')
所以主键分别为:(3, lisi)、(4,wangu)、(5,mike)
index_granularity被设置为2,所以每隔2行生成一条索引值,所以:
第一条索引(3, lisi):
Id为3,又Id为UInt64,使用8字节0x03,如下图 03 00 00 00 00 00 00 00
Name为lisi, 又Name为String类型可变长,会先用1字节描述string长度,长度为4, 所以第9列为04,后边为lisi的ASCII码6c 69 73 69
第二条索引为(5,mike):同理

primary.idx表示成如下:

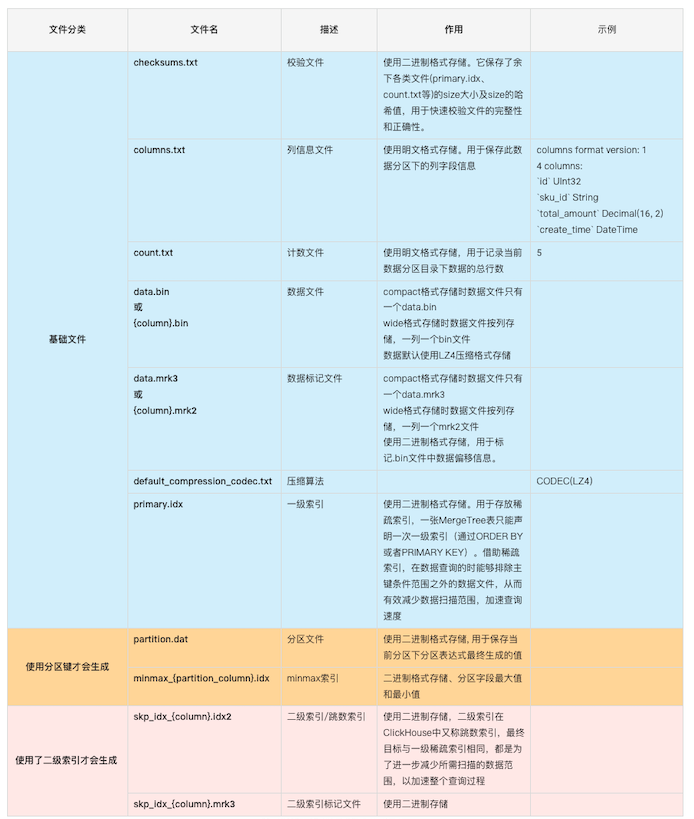
2.2.7 {column}.mrk2
一个{column}.bin文件有1至多个数据压缩块组成,mark2数据标记文件格式比较固定,primary.idx文件中的每个索引在此文件中都有一个对应的Mark,有三列:
- Offset in compressed file,8 Bytes,代表该标记指向的压缩数据块在bin文件中的偏移量。
- Offset in decompressed block,8 Bytes,代表该标记指向的数据在解压数据块中的偏移量。
- Rows count,8 Bytes,行数,通常情况下其等于index_granularity。

所以通过primary.idx中的索引寻找mrk2文件中对应的Mark非常简单,如果要寻找第n(从0开始)个index,则对应的Mark在mrk2文件中的偏移为n*24,从这个偏移处开始读取24 Bytes即可得到相应的Mark。
Id.mrk2
$ hexdump -C Id.mrk2
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 10 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 |................|
00000030 2c 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |,...............|
00000040 00 00 00 00 00 00 00 00 |........|
00000048
$ od -An -l Id.mrk2
0 0
2 0
16 1
44 0
0
id.mrk2的内容表示成如下形式:
- 因为一共有3条数据,index_granularity = 2,所以第一条索引有2行数据第二条索引有1行数据。
- Id UInt64占用8字节,所以解压缩块中便移量分别为0,16
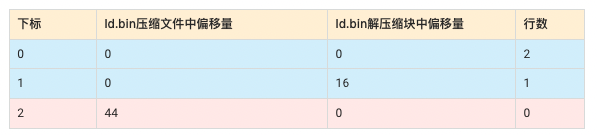
Name.mrk2
$ hexdump -C Name.mrk2
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 0c 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 11 00 00 00 00 00 00 00 |................|
00000040 00 00 00 00 00 00 00 00 |........|
00000048
$ od -An -l Name.mrk2
0 0
2 0
12 1
0 17
0
Name.mrk2的内容表示成如下形式:
- 因为一共有3条数据,index_granularity = 2,所以第一条索引有2行数据第二条索引有1行数据。
- Name是String类型为可变长类型,String类型实际占用长度=1字节表示字符串长度+字符串实际长度,所以lisi占用5字节(1+4),wangwu占用7字节(1+6),mike占用5字节(1+4),那么前两条索引在解压缩块中偏移量分别是0,12
(3,'2000-01-02','lisi'),
(4,'2000-01-03','wangwu'),
(5,'2000-01-04','mike'),
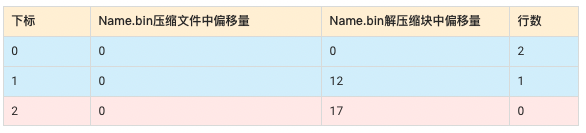
Birthday.mrk2
$ hexdump -C Birthday.mrk2
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 04 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 06 00 00 00 00 00 00 00 |................|
00000040 00 00 00 00 00 00 00 00 |........|
00000048
$ od -An -l Birthday.mrk2
0 0
2 0
4 1
0 6
0
Birthday.mrk2的内容表示成如下形式:
- 因为一共有3条数据,index_granularity = 2,所以第一条索引有2行数据第二条索引有1行数据。
- Birthday为Date类型,为UInt16实现占用2字节,所以解压缩块中便移量分别为0,4
2.2.8 {column}.bin
{column}.bin文件由若干数据块组成,默认使用LZ4压缩格式。用于存储某一列数据,由于MergeTree采用列式存储,Wide模式存储时,每个字段都有独立的bin文件。{column}.bin文件存储如下:

[column].bin文件查看:
- 第一行16个字节是该文件的checksum值
- 第二行(以Id.bin为例)
- 第一个字节是0x82,是默认的LZ4算法
- 第2个到第5个字节是压缩后的数据块的大小,这里是小端模式,Int32占4个字节, 倒着就是 00 00 00 1c = 28
- 第6个字节到第9个字节是压缩前的数据块大小,同理00 00 00 18=24
- 与 clickhouse-compressor --stat < Id.bin得到的结果一致
$ hexdump -C Id.bin
00000000 4e 3f c4 34 37 15 5c 29 f5 34 ff b5 0e cc ea 1f |N?.47.\).4......|
00000010 82 1c 00 00 00 18 00 00 00 22 03 00 01 00 12 04 |........."......|
00000020 07 00 90 00 05 00 00 00 00 00 00 00 |............|
0000002c
# 该分区共有3条数据,ID是UInt64占8字节,所以压缩前一共是24字节,压缩后为什么是28更大了呢?
# 因为数据量小,压缩本身还有一些必要的信息要压缩,所以压缩后会比压缩前大
$ clickhouse-compressor --stat < Id.bin
# 压缩前大小 压缩后大小
24 28
$ hexdump -C Name.bin
00000000 2c b4 9c 0c 6a 6e e9 3c 80 7f 22 29 7e b2 6e c7 |,...jn.<..")~.n.|
00000010 82 1c 00 00 00 11 00 00 00 f0 02 04 6c 69 73 69 |............lisi|
00000020 06 77 61 6e 67 77 75 04 6d 69 6b 65 |.wangwu.mike|
0000002c
# 该分区共有3条数据,Name是String类型,可变长,但有一字节表示长度
# lisi=4 wangwu=7 mike=4, 1+4+1+6+1+4 = 17
$ clickhouse-compressor --stat < Name.bin
17 28
$ hexdump -C Birthday.bin
00000000 f7 7c 17 4b 90 d7 66 bf c6 f3 69 06 cf bc 92 0c |.|.K..f...i.....|
00000010 82 10 00 00 00 06 00 00 00 60 ce 2a cf 2a d0 2a |.........`.*.*.*|
00000020
$ clickhouse-compressor --stat < Birthday.bin
6 16
Id.bin数据压缩块的头信息简单表示如下:

2.2.9 minmax_Birthday.idx
minmax文件里面存放的是该分区里分区字段的最小最大值。分区字段Birthday的类型为Date,其底层由UInt16实现,存的是从1970年1月1号到现在所经过的天数。通过上面的INSERT语句我们可以知道Birthday的最小值为2000-01-02,最大值为2000-01-04。这两个时间转换成天数分别为10958和10960,再转换成16进制就是0x2ace和0x2ad0。
$ hexdump -C minmax_Birthday.idx
00000000 ce 2a d0 2a |.*.*|
00000004
$ od -An -td2 -w4 minmax_Birthday.idx
10958 10960
(3,'2000-01-02','lisi'),
(4,'2000-01-03','wangwu'),
(5,'2000-01-04','mike')
2.2.10 skp_idx_a.idx2
二级索引文件
$ hexdump -C skp_idx_a.idx2
00000000 a9 d1 d7 8f b3 70 a1 1c 84 6f ec 0e b7 01 9f a1 |.....p...o......|
00000010 82 0e 00 00 00 04 00 00 00 40 ce 2a d0 2a |.........@.*.*|
0000001e
2.2.11 skp_idx_a.mrk2
二级索引标记文件
$ hexdump -C skp_idx_a.mrk2
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 01 00 00 00 00 00 00 00 |........|
00000018
3. 索引过程
所以索引过程用一个图表示大概如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号