xv6book阅读 chapter3
页表是硬件提供进程间隔离的方法之一,并通过它来实现虚拟地址和物理地址之间的转换,通过页表可以决定进程能够访问物理内存的哪些部分,xv6提供了一些小技巧,比如在不同的地址空间中可以映射相同的trampoline page,trampoline是用来辅助用户模式进入内核模式的,所以它可被共用。
1 分页硬件
RISC-V指令(特权指令和非特权指令)操作虚拟地址。机器的RAM或物理内存是用物理地址索引的。RISC-V页表硬件通过将每个虚拟地址映射到物理地址来连接这两种地址。
两个需要知道的东西:
- 页表项(PTE),在页表中,包含着对应物理地址的信息
- 页框号(PPN),位于页表项中。物理内存被划分为固定大小的页框(通常4kb),当发生虚拟地址到物理地址的映射时,使用页表项(PTE)中的页框号字段,将虚拟页映射到物理内存中的相应页框。
qemu模拟的是64位机器,但是虚拟地址只使用64尾的低39位来做地址转换,而一个页表中包含的页表项(PTE)有227个,每个PTE包含一个44位的页框号(PPN)和一些标志位。分页硬件使用39位的前27位来查找页表项,转换后生成一个56位的物理地址,前44位为页框号,后12位来自原始虚拟地址,通常表示指令的页内偏移量,而且必须是12,因为212=4096。转换过程如下所示:

虚拟地址的前25位通常不用于转换。对于一个进程来说,239的虚拟地址空间足够了,256的物理空间也已经足够大了,物理空间是56位还是其它取决于硬件的设计师,只不过在qemu中设计的是56位大小。
上述介绍的是简化的一级页表模型,实际的riscv中用的是三级页表,三级页表的记录方式更加高效。当虚拟地址空间较大时,单级页表会很庞大,这将占用大量内存,即使虚拟空间中只有一小部分被使用。另外单级页表中线性搜索也是一件效率极差的事情,不如多级页表的查找效率。
rsicv中每一级页表中存2^9=512个页表项,每个页表项占64位也就是8字节,即每一级目录只需要占用一个物理页,每一个页表条目对应下一级的一个页表目录,指令物理地址搜索过程为:在顶层页目录L2中查找下一级页表目录的物理位置,中层L1中继续寻找下一级页表位置,最后在L0底层页目录中查找指令的物理页框号,即实际物理地址。在转换过程中如果任何一个pte不存在,分页硬件都将引发一个页面错误异常,交给内核处理。
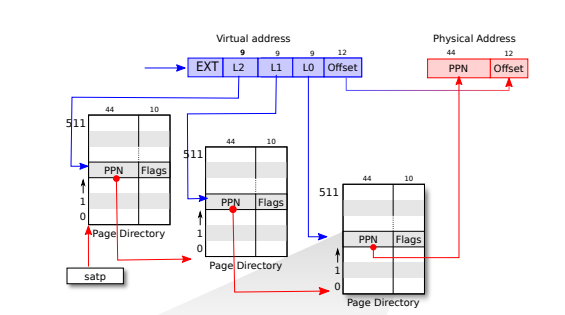
当进程只使用从虚拟地址0开始的几个页面,就只需要三个页面目录就可以。而L2的条目1~511都是无效的,则对于L2来说省下了511个页不需要分配,而对于下级页表而言,有511*512个页不需要进行分配了,即省下了许多对于映射关系的存储。
然而三级页表还是有缺点,它意味着CPU要从内存中加载三个PTE来实现指令的虚拟地址到物理地址转换,为减缓这样的开销,rixcv的CPU会将页表项缓存在外置缓冲区TLB中,TLB 的主要功能是缓存最近的虚拟地址到物理地址的映射,从而避免每次内存访问都要查找完整的页表。
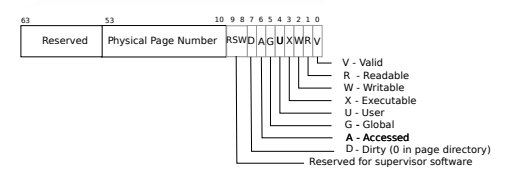
每个PTE都包含标志位,这些标志位告诉分页硬件如何允许使用关联的虚拟地址。PTE_V指示PTE是否存在:如果没有设置,对该页的引用将导致异常(即不允许);PTE_R控制是否允许指令读到该页;PTE_W控制是否允许指令写入页;PTE_X控制CPU是否可以将页面的内容解释为指令并执行它们;PTE_U控制是否允许用户模式下的指令访问页面;如果不配置PTE_U,则该PTE只能在管理员模式下使用。标志和所有其他与页面硬件相关的结构在(kernel/riscv.h)中定义。
为了告诉硬件使用页表,内核必须将根页表所在页(指的是多级页表的起始页表)的物理地址写入satp寄存器。每个CPU都有自己的节点。CPU将使用它自己的节点所指向的页表来翻译由后续指令生成的所有地址。每个CPU都有自己的页表,因此不同的CPU可以运行不同的进程,每个进程都有一个由自己的页表描述的私有地址空间。
通常,内核将所有物理内存映射到它的页表中,这样它就可以使用load/store指令读写物理内存中的任何位置。由于页目录位于物理内存中,内核可以通过使用标准存储指令写入PTE的虚拟地址来对页目录中PTE的内容进行编程。
关于术语的一些注意事项:物理内存是指DRAM中的存储单元。物理内存的每个字节都有一个地址,称为物理地址。指令只使用虚拟地址(无论特权还是非特权),分页硬件将其转换为物理地址,然后将其发送给DRAM硬件进行读取或写存储器。与物理内存和虚拟地址不同,虚拟内存不是物理对象,而是在磁盘(外存)上开辟的一块用于数据交换的空间。
2 内核地址空间
Xv6为每个进程维护一个页表,外加一个描述内核地址空间的页表,我们这次的主要任务将是为每个进程分配一个内核页表,而不是多个进程共用一个。在文件(kernel/memlayout.h)声明了xv6内核内存布局的常量。
QEMU模拟一台包含RAM(物理内存)的计算机,从物理地址0x80000000开始,至少持续到0x86400000, xv6将其称为PHYSTOP(最高内存),这些空间属于DRAM硬件。QEMU模拟还包括I/O设备,如磁盘接口。QEMU将设备接口作为位于物理地址空间0x80000000以下的内存映射控制寄存器公开给软件。内核可以通过读写这些特殊的物理地址直接与设备进行交互(DMA),即0x80000000以下的地址指向其它的硬件;这样的读写与设备硬件通信,而不是与RAM通信,其中包含ROM、中断控制(PLIC)、console和显示器交互的设备(UART0)、与磁盘交互设备(VIRTIO disk)。第4章解释了xv6如何与设备交互。
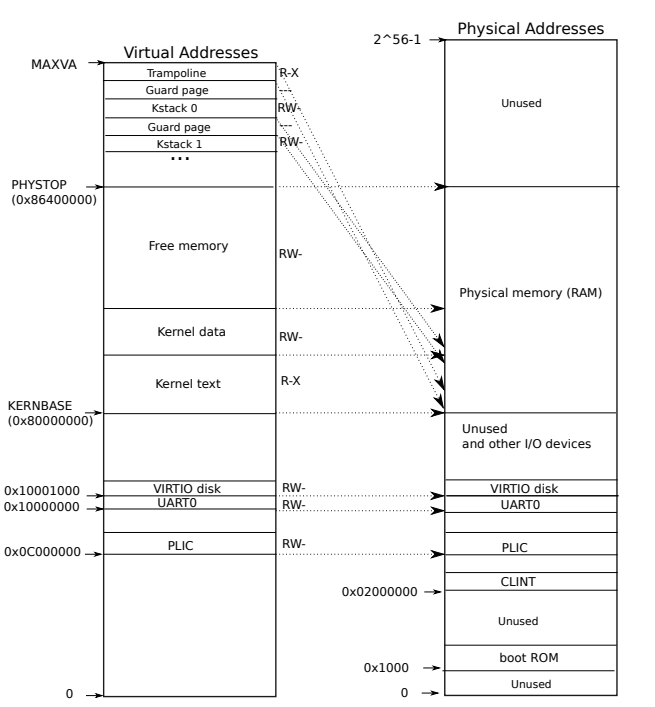
有几个内核虚拟地址不是直接映射的:
trampoline page它在虚拟地址空间的顶部有一个映射,并且这个映射被用户页表共享。同样,这个跳板页在内核的虚拟地址空间中有两个映射:一个在虚拟地址空间的顶部,另一个通过一种直接映射方式(即虚拟地址是多少,物理地址就是多少。这种设计可能涉及到一些复杂的内核操作和虚拟内存管理机制。- 内核堆栈页面,内核堆栈页面。每个进程都有自己的内核堆栈,内核堆栈在较高的位置被映射,这样xv6就可以在内核堆栈下面留下一个未映射的保护页。保护页的PTE是无效的(即:PTE_V未设置),也就是不会真的被映射,目的是内核溢出内核堆栈,会导致页面错误,内核要想办法处理。如果没有保护页,溢出的堆栈将覆盖其他内核内存,从而导致不正确的操作。
内核用权限PTE_R和PTE_X映射trampoline page和内核文本的页面。内核从这些页面读取并执行指令。内核用PTE_R和PTE_W权限映射其他页,这样它就可以读写这些页中的内存。保护页的映射无效。
3 代码:创建一个地址空间
大多数用于操作地址空间和页表的xv6代码在vm.c (kernel/vm.c:1)中。核心数据结构是pagetable_t,它实际上是一个指向RISC-V 根页表页面的指针;pagetable_t可以是内核页表,也可以是一个进程间页表。核心函数是walk和mappings,前者为虚拟地址查找PTE,后者为新的映射设置PTE。以kvm开头的函数操作内核页表;以uvm开头的函数操作用户页表;其他函数用于两者。Copyout和copyin将数据复制到作为系统调用参数的用户虚拟地址中;它们在vm.c中,因为它们需要显式地转换这些地址,以便找到相应的物理内存。
在内核的启动序列中(kernel/main.c),main调用kvminit (kernel/vm.c:54)来使用kvmmake (kernel/vm.c:20)创建内核的页表。这个调用发生在xv6在RISC-V上启用分页之前,因此地址直接指向物理内存。kvmmake首先分配一个物理内存页来存放根页表页,然后它调用kvmmap来设置内核所需的地址转换。这些地址转换包括内核的指令和数据、物理内存直到PHYSTOP(最大可用物理地址),以及实际设备的内存范围。Proc_mapstacks (kernel/proc.c:33)为每个进程分配一个内核堆栈。它调用kvmmap在KSTACK生成的虚拟地址上映射每个堆栈,这为无效的堆栈保护页留下了空间。
kvmmap (kernel/vm.c:127)调用mappages (kernel/vm.c:138),它将一系列虚拟地址的映射设置到相应的物理地址范围的页表中。它以页间隔为范围内的每个虚拟地址分别执行此操作。对于要映射的每个虚拟地址,映射调用遍历查找该地址的PTE的地址。然后初始化PTE以保存相关的物理页码、所需的权限(PTE_W、PTE_X和/或PTE_R)和PTE_V,以将PTE标记为有效(kernel/vm.c:153)。
walk (kernel/vm.c:81)模拟RISC-V分页硬件查找PTE以查找虚拟地址(参见三级页表图)。walk每次将3层页表下移9位。它使用每个级别的9位虚拟地址来查找下一级页表或最终页的PTE (kernel/vm.c:87)。如果PTE无效,则所需的页面尚未分配;如果设置了alloc参数,walk分配一个新的页表页,并将其物理地址放入PTE中,它返回页表树中最底层的PTE的地址(kernel/vm.c:97)。
上面的代码依赖于直接映射到内核虚拟地址空间的物理内存。例如,当walk下降页表的级别时,它从PTE (kernel/vm.c:89)中提取下一级页表的(物理)地址,然后使用该地址作为虚拟地址来获取下一级的PTE (kernel/vm.c:87)。
main调用kvminihart (kernel/vm.c:62)来安装内核页表。它将根页表页的物理地址写入寄存器satp。在此之后,CPU将使用内核页表转换地址。由于内核使用本体映射,所以下一条指令的当前虚拟地址将映射到正确的物理内存地址。
每个RISC-V CPU在TLB中缓存页表项,当xv6更改页表时,它必须告诉CPU使相应的缓存TLB项无效。如果没有,那么在稍后的某个时刻,TLB可能会使用旧的缓存映射,指向一个物理页面,该页面在此期间已分配给另一个进程,因此,一个进程可能会在其他进程的内存上乱涂乱画。RISC-V有一个指令保护。vma用来刷新当前CPU的TLB。Xv6执行防御。vma在kvminithart中重新加载satp寄存器后,在返回用户空间之前切换到用户页表的trampoline代码中(kernel/trampoline. s:79)。
为了避免刷新整个TLB, RISC-V cpu可能支持地址空间标识符(ASIDs)。然后内核可以只刷新特定地址空间的TLB项。
4 物理内存分配
内核必须在运行时为页表、用户内存、内核堆栈和管道缓冲区分配和释放物理内存。
xv6使用内核末尾和PHYSTOP之间的物理内存进行运行时分配。它一次分配和释放整个4096字节的页面,通过将链表贯穿页面本身来跟踪哪些页面是空闲的。分配包括从链表中删除一个页面;释放包括将释放的页面添加到列表中。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步