Django(二)Model
Model(数据库模型)
Django用于对数据库进行操作的方式
数据库配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:



DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'books', #你的数据库名称 'USER': 'root', #你的数据库用户名 'PASSWORD': '', #你的数据库密码 'HOST': '', #你的数据库主机,留空默认为localhost 'PORT': '3306', #你的数据库端口 } }
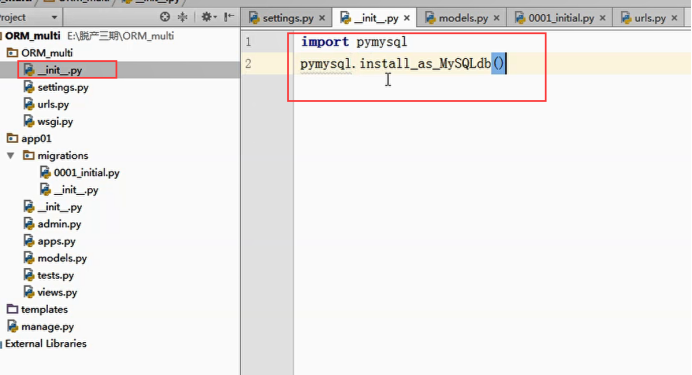
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。 设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。 然后,启动项目,会报错:no module named MySQLdb 这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql pymysql.install_as_MySQLdb() 问题解决!
ORM(对象关系映射模型)
ORM(object relation mapping,对象关系映射表),对数据库的操作转化为类和对象的概念,一个记录就是一个实例,一个表对应一个类
表与表之间的关系:一对一,一对多,多对多

优点:1 ORM使得我们的通用数据库交互变得简单易行,而且完全不用考虑该死的SQL语句。快速开发,由此而来。
2 可以避免一些新手程序猿写sql语句带来的性能问题。
缺点:1 性能有所牺牲,不过现在的各种ORM框架都在尝试各种方法,比如缓存,延迟加载登来减轻这个问题。效果很显著。
2 对于个别复杂查询,ORM仍然力不从心,为了解决这个问题,ORM一般也支持写raw sql。
3 通过QuerySet的query属性查询对应操作的sql语句
author_obj=models.Author.objects.filter(id=2) print(author_obj.query)
单表操作
创建表
创建django项目,新建名为app01的app,在app01的models.py中创建模型
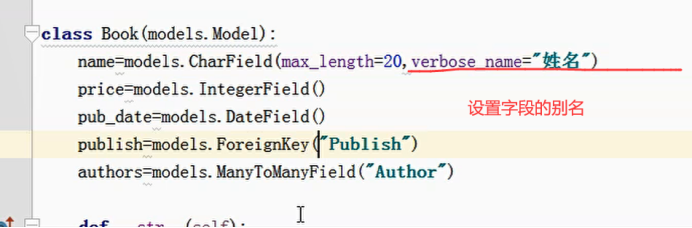
from django.db import models<br> class Publisher(models.Model): name = models.CharField(max_length=30, verbose_name="名称") address = models.CharField("地址", max_length=50) city = models.CharField('城市',max_length=60) state_province = models.CharField(max_length=30) country = models.CharField(max_length=50) website = models.URLField() class Meta: verbose_name = '出版商' verbose_name_plural = verbose_name def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=30) def __str__(self): return self.name class AuthorDetail(models.Model): sex = models.BooleanField(max_length=1, choices=((0, '男'),(1, '女'),)) email = models.EmailField() address = models.CharField(max_length=50) birthday = models.DateField() author = models.OneToOneField(Author) class Book(models.Model): title = models.CharField(max_length=100) authors = models.ManyToManyField(Author) publisher = models.ForeignKey(Publisher) publication_date = models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2,default=10) def __str__(self): return self.title
django的orm支持多种数据库,如果想将上述模型转为mysql数据库中的表,需要settings.py中
# 删除\注释掉原来的DATABASES配置项,新增下述配置 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 使用mysql数据库 'NAME': 'db1', # 要连接的数据库 'USER': 'root', # 链接数据库的用于名 'PASSWORD': '', # 链接数据库的用于名 'HOST': '127.0.0.1', # mysql服务监听的ip 'PORT': 3306, # mysql服务监听的端口 } }
在链接mysql数据库前,必须事先创建好数据库,数据库名必须与settings.py中指定的名字对应上
<1> CharField #字符串字段, 用于较短的字符串. #CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. <2> IntegerField #用于保存一个整数. <3> FloatField # 一个浮点数. 必须 提供两个参数: # # 参数 描述 # max_digits 总位数(不包括小数点和符号) # decimal_places 小数位数 # 举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段: # # models.FloatField(..., max_digits=5, decimal_places=2) # 要保存最大值一百万(小数点后保存10位)的话,你要这样定义: # # models.FloatField(..., max_digits=19, decimal_places=10) # admin 用一个文本框(<input type="text">)表示该字段保存的数据. <4> AutoField # 一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段; # 自定义一个主键:my_id=models.AutoField(primary_key=True) # 如果你不指定主键的话,系统会自动添加一个主键字段到你的 model. <5> BooleanField # A true/false field. admin 用 checkbox 来表示此类字段. <6> TextField # 一个容量很大的文本字段. # admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框). <7> EmailField # 一个带有检查Email合法性的 CharField,不接受 maxlength 参数. <8> DateField # 一个日期字段. 共有下列额外的可选参数: # Argument 描述 # auto_now 当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳. # auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间. #(仅仅在admin中有意义...) <9> DateTimeField # 一个日期时间字段. 类似 DateField 支持同样的附加选项. <10> ImageField # 类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field, # 如果提供这两个参数,则图片将按提供的高度和宽度规格保存. <11> FileField # 一个文件上传字段. #要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting, #该格式将被上载文件的 date/time #替换(so that uploaded files don't fill up the given directory). # admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) . #注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤: #(1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件. # (出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对 # WEB服务器用户帐号是可写的. #(2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django # 使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT). # 出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField # 叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径. <12> URLField # 用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且 # 没有返回404响应). # admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框) <13> NullBooleanField # 类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项 # admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据. <14> SlugField # "Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs # 若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在 # 以前的 Django 版本,没有任何办法改变50 这个长度. # 这暗示了 db_index=True. # 它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate # the slug, via JavaScript,in the object's admin form: models.SlugField # (prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields. <13> XMLField #一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径. <14> FilePathField # 可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的. # 参数 描述 # path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目. # Example: "/home/images". # match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名. # 注意这个正则表达式只会应用到 base filename 而不是 # 路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif. # recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录. # 这三个参数可以同时使用. # match 仅应用于 base filename, 而不是路径全名. 那么,这个例子: # FilePathField(path="/home/images", match="foo.*", recursive=True) # ...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif <15> IPAddressField # 一个字符串形式的 IP 地址, (i.e. "24.124.1.30"). <16># CommaSeparatedIntegerField # 用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
<1> null : 数据库中字段是否可以为空 <2> blank: django的 Admin 中添加数据时是否可允许空值 <3> default:设定缺省值 <4> editable:如果为假,admin模式下将不能改写。缺省为真 <5> primary_key:设置主键,如果没有设置django创建表时会自动加上: id = meta.AutoField('ID', primary_key=True) primary_key=True implies blank=False, null=False and unique=True. Only one primary key is allowed on an object. <6> unique:数据唯一 <7> verbose_name Admin中字段的显示名称 <8> validator_list:有效性检查。非有效产生 django.core.validators.ValidationError 错误 <9> db_column,db_index 如果为真将为此字段创建索引 <10>choices:一个用来选择值的2维元组。第一个值是实际存储的值,第二个用来方便进行选择。 如SEX_CHOICES= (( ‘F’,'Female’),(‘M’,'Male’),) gender = models.CharField(max_length=2,choices = SEX_CHOICES)
表的操作
增
from app01.models import * #create方式一: Author.objects.create(name='Alvin') #create方式二: Author.objects.create(**{"name":"alex"}) #save方式一: author=Author(name="alvin") author.save() #save方式二: author=Author() author.name="alvin" author.save()
在命令行中执行两条数据库迁移命令,即可在指定的数据库中创建表
$ python manage.py makemigrations $ python manage.py migrate # 注意: # 1、makemigrations只是生成一个数据库迁移记录的文件,而migrate才是将更改真正提交到数据库执行 # 2、数据库迁移记录的文件存放于app01下的migrations文件夹里 # 3、了解:使用命令python manage.py showmigrations可以查看没有执行migrate的文件
删
在表生成之后,如果需要增加、删除、修改表中字段,需要这么做
# 一:增加字段 #1.1、在模型类Employee里直接新增字段,强调:对于orm来说,新增的字段必须用default指定默认值 publish = models.CharField(max_length=12,default='人民出版社',null=True) #1.2、重新执行那两条数据库迁移命令 # 二:删除字段 #2.1 直接注释掉字段 #2.2 重新执行那两条数据库迁移命令 # 三:修改字段 #2.1 将模型类中字段修改 #2.2 重新执行那两条数据库迁移命令
对记录的操作
增
方式一 # 1、用模型类创建一个对象,一个对象对应数据库表中的一条记录 obj = Employee(name="Egon", gender=0, birth='1997-01-27', department="财务部", salary=100.1) # 2、调用对象下的save方法,即可以将一条记录插入数据库 obj.save() 方式二 # 每个模型表下都有一个objects管理器,用于对该表中的记录进行增删改查操作,其中增加操作如下所示 obj = Employee.objects.create(name="Egon", gender=0, birth='1997-01-27', department="财务部", salary=100.1)
删
删除单条记录 可以直接调用记录对象下的delete方法,该方法运行时立即删除本条记录而不返回任何值,如下 obj=Employee.objects.first() obj.delete() 删除QuerySet中的所有记录对象 queryset_obj=Employee.objects.filter(id__gt=5) rows=queryset_obj.delete() 需要强调的是管理objects下并没有delete方法,这是一种保护机制,是为了避免意外地调用 Employee.objects.delete() 方法导致所有的记录被误删除从而跑路。但如果你确认要删除所有的记录,那么你必须显式地调用管理器下的all方法,拿到一个QuerySet对象后才能调用delete方法删除所有 Employee.objects.all().delete()
改
直接修改单条记录
可以修改记录对象属性的值,然后执行save方法从而完成对单条记录的直接修改
# 1、获取记录对象 obj=Employee.objects.filter(name='Egon')[0] # 2、修改记录对象属性的值 obj.name='EGON' obj.gender=1 # 3、重新保存 obj.save()
修改QuerySet中的所有记录对象
QuerySet对象下的update()方法可以更QuerySet中包含的所有对象,该方法会返回一个整型数值,表示受影响的记录条数(相当于sql语句执行结果的rows)
queryset_obj=Employee.objects.filter(id__gt=5) rows=queryset_obj.update(name='EGON',gender=1)
记录的基本查询
下述方法(除了count外)的返回值都是一个模型类Employee的对象,为了后续描述方便,我们统一将模型类的对象称为"记录对象",每一个”记录对象“都唯一对应表中的一条记录
# 1. get(**kwargs) # 1.1: 有参,参数为筛选条件 # 1.2: 返回值为一个符合筛选条件的记录对象(有且只有一个),如果符合筛选条件的对象超过一个或者没有都会抛出错误。 obj=Employee.objects.get(id=1) print(obj.name,obj.birth,obj.salary) #输出:Egon 1997-01-27 100.1 # 2、first() # 2.1:无参 # 2.2:返回查询出的第一个记录对象 obj=Employee.objects.first() # 在表所有记录中取第一个 print(obj.id,obj.name) # 输出:1 Egon # 3、last() # 3.1: 无参 # 3.2: 返回查询出的最后一个记录对象 obj = Employee.objects.last() # 在表所有记录中取最后一个 print(obj.id, obj.name) # 输出:9 Egon # 4、count(): # 4.1:无参 # 4.2:返回包含记录对象的总数量 res = Employee.objects.count() # 统计表所有记录的个数 print(res) # 输出:9 # 注意:如果我们直接打印Employee的对象将没有任何有用的提示信息,我们可以在模型类中定义__str__来进行定制 class Employee(models.Model): ...... # 在原有的基础上新增代码如下 def __str__(self): return "<%s:%s>" %(self.id,self.name) # 此时我们print(obj)显示的结果就是: <本条记录中id字段的值:本条记录中name字段的值>
下述方法查询的结果都有可能包含多个记录对象,为了存放查询出的多个记录对象,django的ORM自定义了一种数据类型Queryeset,所以下述方法的返回值均为QuerySet类型的对象,QuerySet对象中包含了查询出的多个记录对象
# 1、filter(**kwargs): # 1.1:有参,参数为过滤条件 # 1.2:返回值为QuerySet对象,QuerySet对象中包含了符合过滤条件的多个记录对象 queryset_res=Employee.objects.filter(department='技术部') # print(queryset_res) # 输出: <QuerySet [<Employee: <2:Kevin>>, <Employee: <5:Jack>>, <Employee: <6:Robin>>]> # 2、exclude(**kwargs) # 2.1: 有参,参数为过滤条件 # 2.2: 返回值为QuerySet对象,QuerySet对象中包含了不符合过滤条件的多个记录对象 queryset_res=Employee.objects.exclude(department='技术部') # 3、all() # 3.1:无参 # 3.2:返回值为QuerySet对象,QuerySet对象中包含了查询出的所有记录对象 queryset_res = Employee.objects.all() # 查询出表中所有的记录对象 # 4、order_by(*field): # 4.1:有参,参数为排序字段,可以指定多个字段,在字段1相同的情况下,可以按照字段2进行排序,以此类推,默认升序排列,在字段前加横杆代表降序排(如"-id") # 4.2:返回值为QuerySet对象,QuerySet对象中包含了排序好的记录对象 queryset_res = Employee.objects.order_by("salary","-id") # 先按照salary字段升序排,如果salary相同则按照id字段降序排 # 5、values(*field) # 5.1:有参,参数为字段名,可以指定多个字段 # 5.2:返回值为QuerySet对象,QuerySet对象中包含的并不是一个个的记录对象,而上多个字典,字典的key即我们传入的字段名 queryset_res = Employee.objects.values('id','name') print(queryset_res) # 输出:<QuerySet [{'id': 1, 'name': 'Egon'}, {'id': 2, 'name': 'Kevin'}, ......]> print(queryset_res[0]['name']) # 输出:Egon # 6、values_list(*field): # 6.1:有参,参数为字段名,可以指定多个字段 # 6.2:返回值为QuerySet对象,QuerySet对象中包含的并不是一个个的记录对象,而上多个小元组,字典的key即我们传入的字段名 queryset_res = Employee.objects.values_list('id','name') print(queryset_res) # 输出:<QuerySet [(1, 'Egon'), (2, 'Kevin'),), ......]> print(queryset_res[0][1]) # 输出:Egon
其他
# 1、reverse(): # 1.1:无参 # 1.2:对排序的结果取反,返回值为QuerySet对象 queryset_res = Employee.objects.order_by("salary", "-id").reverse() # 2、exists(): # 2.1:无参 # 2.2:返回值为布尔值,如果QuerySet包含数据,就返回True,否则返回False res = Employee.objects.filter(id=100).exists() print(res) # 输出:False # 3、distinct(): # 3.1:如果使用的是Mysql数据库,那么distinct()无需传入任何参数 # 3.2:从values或values_list的返回结果中剔除重复的记录对象,返回值为QuerySet对象 res = Employee.objects.filter(name='Egon').values('name', 'salary').distinct() print(res) # 输出:<QuerySet [{'name': 'Egon', 'salary': Decimal('100.1')}]> res1 = Employee.objects.filter(name='Egon').values_list('name', 'salary').distinct() print(res1) # 输出:<QuerySet [('Egon', Decimal('100.1'))]>
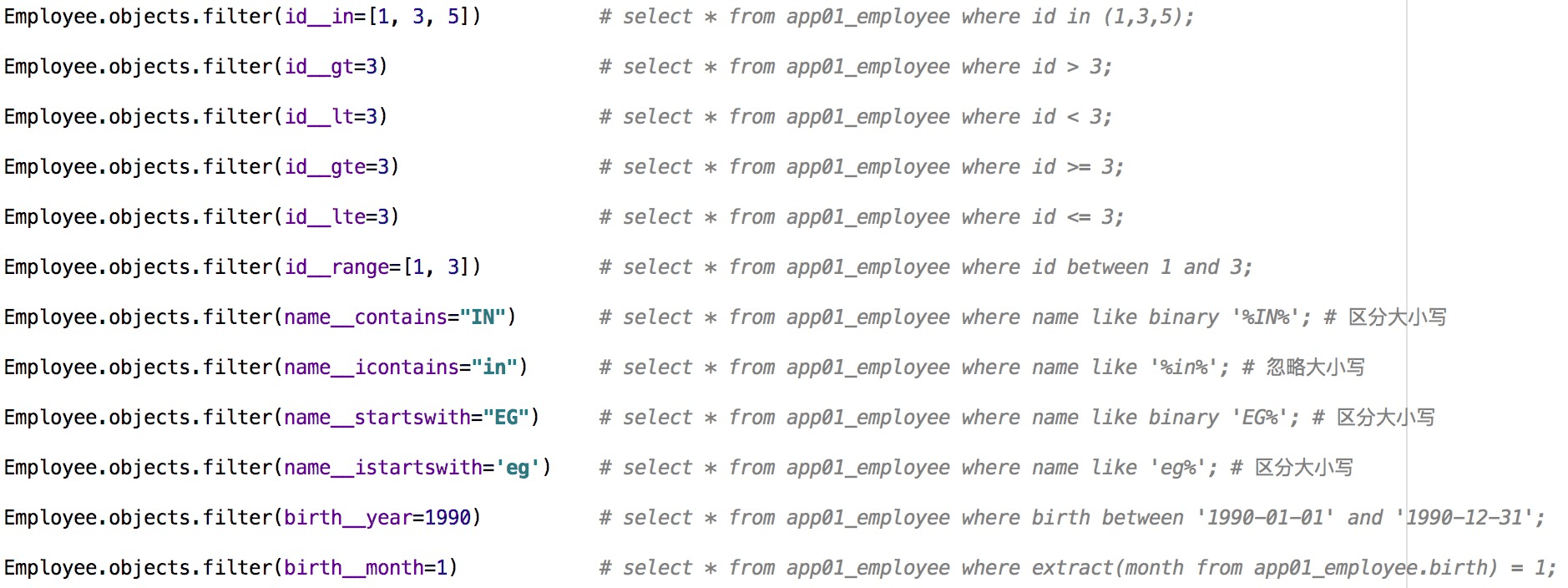
双划线的模糊查询

F和Q查询
F()查询
上面条件过滤时都是字段和值的比较,如果字段和另一个字段的值做比较,则需要F()查询
F() 的实例可以在查询中引用字段,来比较两个不同字段的值,
# 一张书籍表中包含字段:评论数commentNum、收藏数keepNum,要求查询:评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作
# 查询评论数大于收藏数2倍的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F('keepNum')*2)
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+30)
更新字段等于字段本身再拼接一个字符串应该这样做
from django.db.models.functions import Concat from django.db.models import Value Employee.objects.filter(nid__lte=3).update(name=Concat(F('name'),Value('_sb')))
Q()查询
filter()等方法中逗号分隔开的多个关键字参数都是逻辑与(AND) 的关系。 如果我们需要使用逻辑或(OR)来连接多个条件,就用到了Django的Q对象
可以将条件传给类Q来实例化出一个对象,Q的对象可以使用 & | ~ 进行组合
from django.db.models import Q Employee.objects.filter(Q(id__gt=5) | Q(name="Egon")) # 等同于sql:select * from app01_employee where id < 5 or name = 'Egon';
from django.db.models import Q Employee.objects.filter(~Q(id__gt=5) | Q(name="Egon")) # 等同于sql:select * from app01_employee where not (id < 5) or name = 'Egon';
当我们的过滤条件中既有or又有and,则需要混用Q对象与关键字参数,但Q对象必须位于所有关键字参数的前面
from django.db.models import Q Employee.objects.filter(Q(id__gt=5) | Q(name="Egon"),salary__lt=100) # 等同于sql:select * from app01_employee where (id < 5 or name = 'Egon') and salary < 100;
聚合查询
聚合查询aggregate()是把所有查询出的记录对象整体当做一个组,我们可以搭配聚合函数来对整体进行一个聚合操作
from django.db.models import Avg, Max, Sum, Min, Max, Count # 导入聚合函数 # 1. 调用objects下的aggregate()方法,会把表中所有记录对象整体当做一组进行聚合 res1=Employee.objects.aggregate(Avg("salary")) # select avg(salary) as salary__avg from app01_employee; print(res1) # 输出:{'salary__avg': 70.73} # 2、aggregate()会把QuerySet对象中包含的所有记录对象当成一组进行聚合 res2=Employee.objects.all().aggregate(Avg("salary")) # select avg(salary) as salary__avg from app01_employee; print(res2) # 输出:{'salary__avg': 70.73} res3=Employee.objects.filter(id__gt=3).aggregate(Avg("salary")) # select avg(salary) as salary__avg from app01_employee where id > 3; print(res3) # 输出:{'salary__avg': 71.0}
多表操作
多表操作时在filter中使用__双下划线而不能用点.进行跨表
多对一









多对多

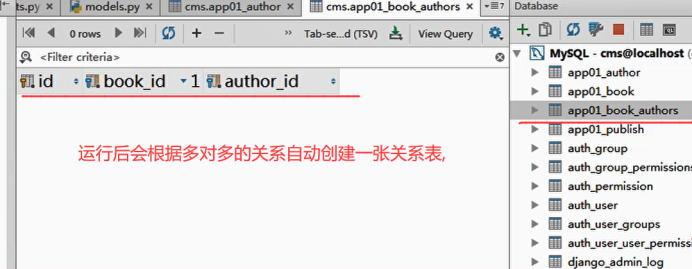


可以通过对象,也可以通过filter value __

注意
filter之后只是创建了queryset对象,并没有对数据库进行查询操作
只有在需要调用queryset对象时django才对数据库进行操作,并将查询的结果保存到缓存中,以供后面使用
django这样的惰性机制提高了效率,但是操作时要注意重新赋值的问题zh

参考文章
https://www.cnblogs.com/xiaoyuanqujing/articles/11643894.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号