第9章 HBase操作
HBase集群建立在Hadoop集群基础之上,而且依赖于ZooKeeper,所以在搭建HBase集群之前需要把Hadoop集群搭建起来,并且搭建好ZooKeeper集群。Hadoop与ZooKeeper集群的搭建在前面章节已讲解过,在此不再赘述。
9.1 集群环境搭建
HBase集群搭建的详细步骤如下(也可以参考官网http://hbase.apache.org/book.html#quickstart):
1.上传解压HBase安装包
将hbase-1.2.4-bin.tar.gz上传到centos01服务器的/opt/softwares目录并将其解压到目录/opt/modules/,解压命令如下:
[hadoop@centos01 softwares]$ tar -zxf hbase-1.2.4-bin.tar.gz -C /opt/modules/
2.hbase-env.sh文件配置
修改HBase安装目录/conf下的配置文件hbase-env.sh,配置关联的JDK,加入以下代码:
export JAVA_HOME=/opt/modules/jdk1.8.0_101
如果需要使用HBase自带的ZooKeeper,则去掉该文件中的注释 # export HBASE_MANAGES_ZK=true即可。
3.hbase-site.xml文件配置
修改HBase安装目录/conf下的配置文件hbase-site.xml,加入以下代码:
<configuration>
<property><!--需要与HDFS namenode端口一致-->
<name>hbase.rootdir</name>
<value>hdfs://centos01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property><!--ZooKeeper节点列表 -->
<name>hbase.zookeeper.quorum</name>
<value>centos01,centos02,centos03</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/modules/hbase-1.2.4/zkData</value>
</property>
</configuration>
上述参数解析如下:
hbase.rootdir:HBase的数据存储目录,由于HBase数据存储在HDFS上,所以要写HDFS的目录,注意端口要和Hadoop的fs.defaultFS端口一致。配置好后,HBase数据就会写入到这个目录中,且目录不需要手动创建,HBase启动的时候会自动创建。
hbase.cluster.distributed:设置为true代表开启完全分布式。
hbase.zookeeper.quorum:设置依赖的ZooKeeper节点,此处加入所有ZooKeeper集群即可。
hbase.zookeeper.property.dataDir:设置ZooKeeper的配置、日志等数据存放目录。
另外,还有一个属性hbase.tmp.dir,是设置HBase临时文件存放目录,不设置的话,默认存放在/tmp目录,该目录重启就会清空。
4.regionservers文件配置
regionservers文件列出了所有运行HBase的服务器,即HRegionServer。对该文件的配置与Hadoop中对slaves文件的配置相似,需要在文件中的每一行指定一台服务器,当HBase启动时会读取该文件,将文件中指定的所有服务器启动。当HBase停止的时候,也会同时停止它们。
本例中,我们将三个节点都作为运行HRegionServer的服务器,因此,我们需要作出如下修改:
修改HBase安装目录下的/conf/regionservers文件,去掉默认的localhost,加入如下内容:
centos01
centos02
centos03
5.拷贝hbase到其它节点。
centos01节点配置完成后,需要拷贝整个HBase安装目录文件到集群的其它节点,拷贝命令如下:
[hadoop@centos01 modules]$ scp -r hbase-1.2.4/ hadoop@centos02:/opt/modules/
[hadoop@centos01 modules]$ scp -r hbase-1.2.4/ hadoop@centos03:/opt/modules/
6.启动与测试
启动HBase集群之前,需要先启动Hadoop集群:
sbin/start-all.sh
然后执行如下命令,启动HBase集群。启动HBase集群的同时,会将ZooKeeper集群也同时启动。
bin/start-hbase.sh
HBase启动日志如下:
[hadoop@centos01 hbase-1.2.4]$ bin/start-hbase.sh
centos02: starting zookeeper, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-zookeeper-centos02.out
centos03: starting zookeeper, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-zookeeper-centos03.out
centos01: starting zookeeper, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-zookeeper-centos01.out
starting master, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-master-centos01.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
centos03: starting regionserver, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-regionserver-centos03.out
centos02: starting regionserver, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-regionserver-centos02.out
centos01: starting regionserver, logging to /opt/modules/hbase-1.2.4/bin/../logs/hbase-hadoop-regionserver-centos01.out
centos02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
centos02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
centos03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
centos03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
centos01: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
centos01: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
HBase启动完成后,查看各节点Java进程:
[hadoop@centos01 hbase-1.2.4]$ jps
12544 DataNode
13584 HQuorumPeer
13074 NodeManager
12916 ResourceManager
14661 Jps
14311 HMaster
12745 SecondaryNameNode
12428 NameNode
14447 HRegionServer
[hadoop@centos02 zookeeper-3.4.9]$ jps
13632 DataNode
13761 NodeManager
14199 HRegionServer
14343 Jps
14093 HQuorumPeer
[hadoop@centos03 zookeeper-3.4.9]$ jps
8994 DataNode
9458 HQuorumPeer
9114 NodeManager
9546 HRegionServer
9679 Jps
从上述查看结果中可以看出,centos01节点上出现了HMaster、HQuorumPeer和HRegionServer进程,centos02和centos03节点上出现了HQuorumPeer和HRegionServer进程。这说明启动成功了。
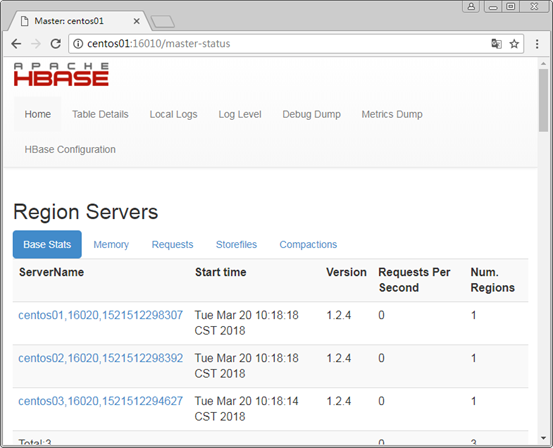
HBase1.0以后的Web端访问默认端口变为了16010,浏览器地址输入http://centos01:16010,查看HBase的运行状态,如下图所示。
9.2 HBase Shell命令操作
HBase 为用户提供了一个非常方便的命令行操作方式,我们称之为HBase Shell。
HBase Shell 提供了大多数的 HBase 命令,通过 HBase Shell 用户可以方便地创建、删除及修改表,还可以向表中添加数据、列出表中的相关信息等。
在启动 HBase 之后,我们可以通过下面的命令进入 HBase Shell 之中:
[hadoop@centos01 hbase-1.2.4]$ bin/hbase shell
下面通过实际操作来介绍HBase Shell的使用。
1.创建表
创建表t1,列族f1,命令如下:
create 't1','f1'
2.添加数据
向表t1中添加一条数据,rowkey为row1,列name的值为zhangsan。命令如下:
put 't1','row1','f1:name','zhangsan'
再向表t1中添加一条数据,rowkey为row2,列age为18。命令如下:
put 't1','row2','f1:age','18'
3.扫描表
扫描表t1,查看数据描述,命令如下:
scan 't1'
执行结果如下:
hbase(main):005:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=1509344793600, value=zhangsan
row2 column=f1:age, timestamp=1509345245541, value=18
2 row(s) in 0.0450 seconds
可以看到,表t1中已经存在两条已添加的数据了。
4.修改表
修改row1中的name值,将zhangsan改为lisi,仍然使用put命令:
put 't1','row1','f1:name','lisi'
再扫描表t1,此时row1中name的值已经变为了“lisi”:
hbase(main):002:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=1509345996225, value=lisi
row2 column=f1:age, timestamp=1509345245541, value=18
2 row(s) in 0.1000 seconds
5.删除特定单元格
删除表中rowkey为row1的行的name单元格,命令如下:
delete 't1','row1','f1:name'
扫描表t1,发现rowkey为row1的行不存在了,因为row1只有一个name单元格,name被删除了,row1一整行也就不存在了。
hbase(main):006:0> scan 't1'
ROW COLUMN+CELL
row2 column=f1:age, timestamp=1509345245541, value=18
1 row(s) in 0.0750 seconds
6.删除一整行数据
删除rowkey为row2的行中所有单元格,命令如下:
deleteall 't1','row2'
扫描表t1,发现owkey为row2的行已不存在了:
hbase(main):008:0> scan 't1'
ROW COLUMN+CELL
0 row(s) in 0.0250 seconds
7.删除整张表
删除整张表,需要先禁用表,然后再删除表。例如,删除表t1,命令如下:
disable 't1'
drop 't1'
9.3 Java API操作
使用HBase Java API可以对表进行创建、添加数据、修改删除数据等。本例在eclipse中编写Java API进行测试,测试前需先启动HBase集群。
9.3.1 创建Java工程
在eclipse中新建maven项目hbasedemo,然后在项目pom.xml中加入hbase的客户端jar包依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.4</version>
</dependency>
加入以后发现pom.xml报如下错误:
Missing artifact jdk.tools:jdk.tools:jar:1.7
原因是,pom.xml中加入的hbase客户端jar包隐式依赖tools.jar包,而tools.jar并未存在于maven仓库中,tools.jar包是JDK自带的。因此我们需要在pom.xml中继续引入tools.jar包,代码如下:
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope> <!—需要配置好环境变量JAVA_HOME-->
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
此时问题得到解决。
9.3.2 创建表
(1)在maven项目hbasedemo中新建Java类HBaseCreateTable.java,在main函数中写入创建表的代码,如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
public class HBaseCreateTable{
public static void main(String[] args) throws Exception {
//创建Hadoop配置对象
Configuration conf=HBaseConfiguration.create();
//指定ZooKeeper集群地址
conf.set("hbase.zookeeper.quorum", "192.168.170.128:2181,192.168.170.129:2181,192.168.170.130:2181");
//创建连接对象Connection
Connection conn=ConnectionFactory.createConnection(conf);
//得到数据库管理员对象
Admin admin=conn.getAdmin();
TableName tableName=TableName.valueOf("t1");
//创建表描述,并指定表名
HTableDescriptor desc=new HTableDescriptor(tableName);
//创建列族描述
HColumnDescriptor family=new HColumnDescriptor("f1");
//指定列族
desc.addFamily(family);
//创建表
admin.createTable(desc);
System.out.println("create table success!!");
}
}
(2)右键运行main函数,输出create table success!!信息,则说明创建成功。
(3)在HBase集群的centos01节点上,输入hbase shell进入Shell命令行模式,然后输入list命令查看当前HBase中的所有表,效果如下:
hbase(main):007:0> list
TABLE
t1
从输出结果中我们可以看到,表t1已创建成功。
9.3.3 添加数据
(1)在maven项目hbasedemo中新建Java类HBasePutData.java,在main函数中写入添加三条数据的代码,如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class HBasePutData{
public static void main(String[] args) throws Exception {
//创建Hadoop配置对象
Configuration conf=HBaseConfiguration.create();
//指定ZooKeeper集群地址
conf.set("hbase.zookeeper.quorum", "192.168.170.128:2181,192.168.170.129:2181,192.168.170.130:2181");
//创建数据库连接对象Connection
Connection conn=ConnectionFactory.createConnection(conf);
//Table负责与记录相关的操作,如增删改查等
TableName tableName=TableName.valueOf("t1");
Table table=conn.getTable(tableName);
Put put = new Put(Bytes.toBytes("row1"));// 设置rowkey
//添加列数据,指定列族、列名与列值
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("xiaoming"));
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes("20"));
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("address"), Bytes.toBytes("beijing"));
Put put2 = new Put(Bytes.toBytes("row2"));// 设置rowkey
//添加列数据,指定列族、列名与列值
put2.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("xiaoming2"));
put2.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes("22"));
put2.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("address"), Bytes.toBytes("beijing2"));
Put put3 = new Put(Bytes.toBytes("row3"));// 设置rowkey
//添加列数据,指定列族、列名与列值
put3.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes("25"));
put3.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("address"), Bytes.toBytes("beijing3"));
//执行添加数据
table.put(put);
table.put(put2);
table.put(put3);
//释放资源
table.close();
System.out.println("put data success!!");
}
}
上方代码中,新建了三个Put对象,每个Put对象包含需要添加的一条数据。
(2)右键运行main函数,输出put data success!!信息,则说明数据添加成功。
(3)在HBase集群的centos01节点上,输入hbase shell进入Shell命令行模式,然后输入scan 't1'命令扫描表t1中的数据,结果如下:
hbase(main):017:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:address, timestamp=1514533573439, value=beijing
row1 column=f1:age, timestamp=1514533573439, value=20
row1 column=f1:name, timestamp=1514533573439, value=xiaoming
row2 column=f1:address, timestamp=1514533573514, value=beijing2
row2 column=f1:age, timestamp=1514533573514, value=22
row2 column=f1:name, timestamp=1514533573514, value=xiaoming2
row3 column=f1:address, timestamp=1514533573524, value=beijing3
row3 column=f1:age, timestamp=1514533573524, value=25
3 row(s) in 0.3930 seconds
从输出结果中我们可以看到,表t1成功添加了三条数据,rowkey分别为row1、row2和row3,同属于列族f1,row1有三个字段address、age、name,row2有三个字段address、age、name,row3有两个字段address、age。
9.3.4 查询数据
在maven项目hbasedemo中新建Java类HBaseGetData.java,在main函数中写入查询数据的代码。例如,查询表t1中行键为row1的一整条数据,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Table;
/**根据rowkey查询一条数据,实测成功,直接右键运行即可**/
public class HBaseGetData{
public static void main(String[] args) throws Exception {
//创建Hadoop配置对象
Configuration conf=HBaseConfiguration.create();
//指定ZooKeeper集群地址
conf.set("hbase.zookeeper.quorum", "192.168.170.128:2181,192.168.170.129:2181,192.168.170.130:2181");
//获得数据库连接
Connection conn=ConnectionFactory.createConnection(conf);
//获取Table对象,指定查询表名,Table负责与记录相关的操作,如增删改查等
Table table = conn.getTable(TableName.valueOf("t1"));
//创建Get对象,根据rowkey查询,rowkey=row1
Get get = new Get("row1".getBytes());
//查询数据,取得结果集
Result r = table.get(get);
//循环输出每个单元格的数据
for (Cell cell : r.rawCells()) {
//取得当前单元格所属的列族名称
String family=new String(CellUtil.cloneFamily(cell));
//取得当前单元格所属的列名称
String qualifier=new String(CellUtil.cloneQualifier(cell));
//取得当前单元格的列值
String value=new String(CellUtil.cloneValue(cell));
//输出结果
System.out.println("列:" + family+":"+qualifier + "—————值:" + value);
}
}
}
右键运行main函数,控制台输出结果为:
列:f1:address—————值:beijing
列:f1:age—————值:20
列:f1:name—————值:xiaoming
与t1表中实际数据一致,则查询成功。
9.3.5 删除数据
(1)在maven项目hbasedemo中新建Java类HBaseDeleteData.java,在main函数中写入删除数据的代码。例如,删除表t1中行键为row1的一整条数据,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
/**根据rowkey查询一条数据,实测成功,直接右键运行即可**/
public class HBaseDeleteData{
public static void main(String[] args) throws Exception {
//创建Hadoop配置对象
Configuration conf=HBaseConfiguration.create();
//指定ZooKeeper集群地址
conf.set("hbase.zookeeper.quorum", "192.168.170.128:2181,192.168.170.129:2181,192.168.170.130:2181");
//获得数据库连接
Connection conn=ConnectionFactory.createConnection(conf);
//获取Table对象,指定表名,Table负责与记录相关的操作,如增删改查等
TableName tableName=TableName.valueOf("t1");
Table table=conn.getTable(tableName);
//创建删除对象Delete,根据rowkey删除一整条
Delete delete=new Delete(Bytes.toBytes("row1"));
table.delete(delete);
//释放资源
table.close();
System.out.println("delete data success!!");
}
}
(2)右键运行main函数,输出delete data success!!信息,则说明数据删除成功。
(3)在HBase集群的centos01节点上,输入hbase shell进入Shell命令行模式,然后输入scan 't1'命令扫描表t1中的数据,结果如下:
hbase(main):019:0> scan 't1'
ROW COLUMN+CELL
row2 column=f1:address, timestamp=1514533573514, value=beijing2
row2 column=f1:age, timestamp=1514533573514, value=22
row2 column=f1:name, timestamp=1514533573514, value=xiaoming2
row3 column=f1:address, timestamp=1514533573524, value=beijing3
row3 column=f1:age, timestamp=1514533573524, value=25
2 row(s) in 0.1080 seconds
从结果中我们可以看到,表t1中的rowkey为row1的行已经被删除了。
原创文章,转载请注明出处!!

原创文章,转载请注明出处!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号