MapReduce核心概念及架构
MapReduce简介
MapReduce常用于对大规模数据集(大于1TB)的并行运算,或对大数据进行加工、挖掘和优化等处理。 MapReduce将并行计算过程高度抽象到了两个函数map和reduce中,程序员只需负责map和reduce函数的编写工作,而并行程序中的其它复杂问题(如分布式存储、工作调度、负载均衡、容错处理等)均可由MapReduce框架代为处理,程序员完全不用操心。
MapReduce技术特征:
横向扩展,而非纵向扩展
失效被认为是常态
将处理向数据迁移
顺序处理数据
隐藏系统层细节
平滑无缝的可扩展性
MapReduce设计思想
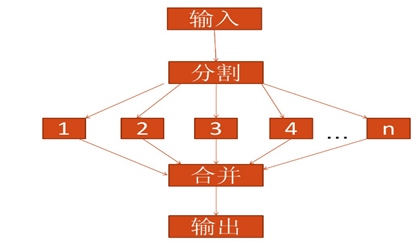
例如,求和:1+2+3+4+5+6+7+8+9+10=?,执行原理如下:
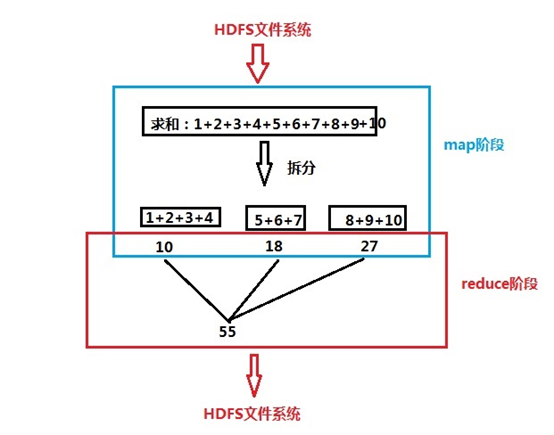
MapReduce工作原理
简述MapReduce的设计思想及使用MapReduce编写程序的步骤。(自己总结)
MapReduce处理大数据集的计算过程是将大数据集分解成为成百上千的小数据集,每个(或若干个)数据集分别由集群中的一个节点进行处理并生成中间结果,然后这些中间结果会进行合并,从而得到最终结果。
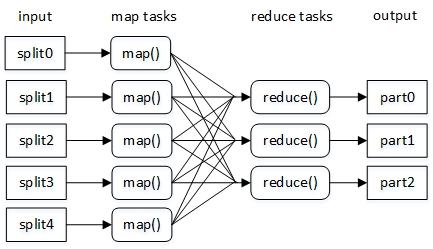
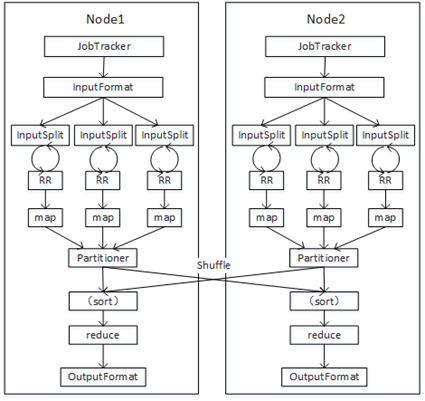
MapReduce任务流程
更多内容及Java+大数据个人原创视频,可关注公众号观看:

原创文章,转载请注明出处!!
原创文章,转载请注明出处!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号