HDFS核心概念与架构
HDFS简介
HDFS是Hadoop项目的核心子项目,在大数据开发中通过分布式计算对海量数据进行存储与管理,它基于流数据模式访问和处理超大文件的需求而开发,可以运行在廉价的商用服务器上,为海量数据提供了不怕故障的存储方法,进而为超大数据集的应用处理带来了很多便利。
HDFS的特点:
支持大型数据集
遵循简单一致性模型
运行于廉价的商用服务器上
不适合低延迟数据访问
存储大量小文件的效率不高
不支持多用户写入、不支持修改文件
HDFS数据存储架构
一个HDFS集群由一个元数据节点(NameNode)和一些数据节点(DataNode)组成,NameNode是一个用来管理文件命名空间的主服务器,DataNode则用来管理对应节点的数据存储。

一个HDFS集群由一个元数据节点(NameNode)和一些数据节点(DataNode)组成,NameNode是一个用来管理文件命名空间的主服务器,DataNode则用来管理对应节点的数据存储。
默认将一个文件块复制三份分别存放。

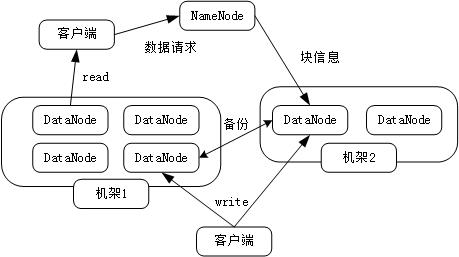
HDFS数据读写特点:一次写入,多次读取。
HDFS主要组件
数据块(Block):HDFS中最基本的存储单位,默认64M(128M)。
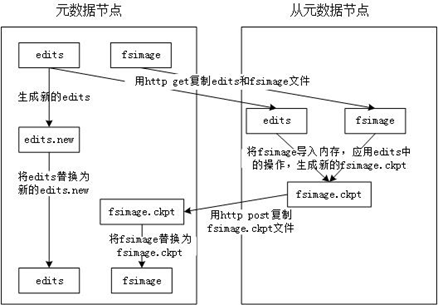
NameNode和DataNode:NameNode存储文件元数据信息,DataNode存储实际文件数据。 从元数据节点(SecondaryNameNode):定期将NameNode中的元数据进行合并。它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间。
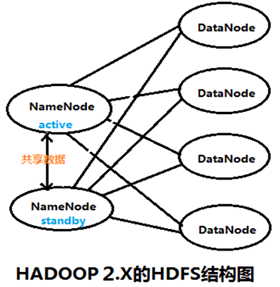
BackupNode:对NameNode中的元数据进行备份。
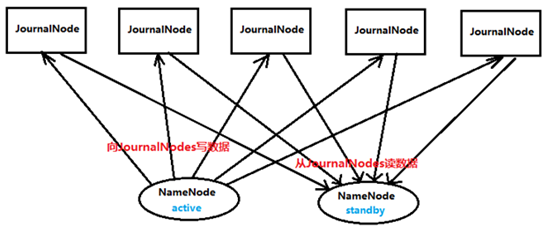
JournalNode:两个NameNode为了同步数据,会通过一组JournalNode的独立进程进行相互通信。
HDFS数据读写
客户端从HDFS中读取数据的过程如下图:
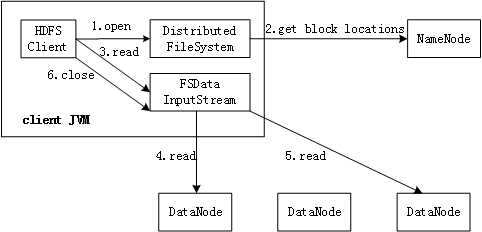
客户端从HDFS中写入数据的过程如下图:


原创文章,转载请注明出处!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号