recv send skb
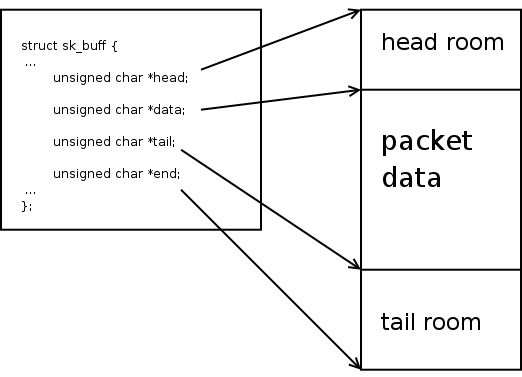
这部分线性buffer 由以上四个指针控制,分割成三个部分,这四个指针都指向线性buffer 中的位置:
- head 到data 之间,称为headroom.
- data 到tail 之间,存放包的数据。
- tail 到end 之间,称为tailroom.
由于 TCP/IP 协议族是一种分层的协议,传输层、网络层、链路层,都有自己的协议头,因此 TCP/IP 协议栈对于数据包的处理是比较复杂的。为了提高处理效率,
避免数据移动、拷贝,sk_buffer 在对数据 buffer 管理的时候,在 packet data 之上和之下,都预留了空间。如果需要增加协议头,只需要从 head room 中拿出一块空间即可,
而如果需要增加数据,则可以从 tail room 中获得空间。这样,整个内存只分配一次空间,此后 协议的处理,只需要挪动指针。
对于刚刚通过alloc_skb() 方法申请出来的skb,head,tail,data 三个指针都指向同一位置,而tail 和end 之间有一段根据alloc_skb(len, flag) 方法的参数申请出来的空间。
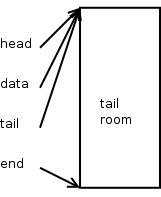
为了给协议头预留空间,可以使用skb_reserve(skb, head_len)方法,该方法会根据参数将data 指针后移,扩展headroom.
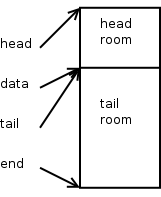
可以通过skb_put(skb, data_len) 方法移动tail 指针,扩展用户数据空间。该方法同时会增加skb->len.
这些空间都是从tailroom “挤”出来的,因此需要保证tailroom 有足够的空间。另外要注意skb_put() 只能在没有page 的数据的情况下调用。
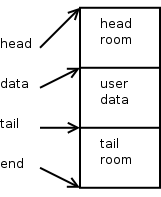
为了添加协议头的内容,需要调用skb_push()方法,这个方法和skb_put()类似,但它是从headroom 挤出空间,data 指针会往前移动,它同样会增加skb->len.
添加一个四层头:
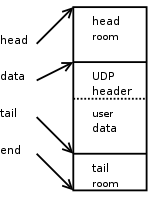
再添加一个三层头:
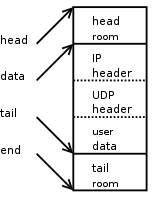
以上是对于没有page buffer,只有线性buffer 时的操作,对于比较大的包,还需要用到线性buffer 以外的部分。对于部分驱动来讲,有一个copybreak 的字段,当包的大小大于copybreak 时,只将起始一部分数据放入skb->data(协议头等),而剩余部分会存放于page buffer. 后续添加数据时应该不再调用skb_put()方法,否则数据顺序是有问题的。
skb_is_nonlinear() 方法可以帮助判断是否存在page buffer,对于有page buffer 的skb 来讲,之前已经提到skb->data_len 用于指示这部分数据的大小,而之前刚刚提到的通过skb_put() 和skb_push() 方法添加进去的数据的大小就是skb->len-skb->data_len,也就是skb_headlen()。
struct skb_shared_info { atomic_t dataref; unsigned int nr_frags; unsigned short tso_size; unsigned short tso_segs; struct sk_buff *frag_list; skb_frag_t frags[MAX_SKB_FRAGS]; };
我们只要把 end 从 char* 转换成skb_shared_info* ,就能访问到这个结构
Linux 提供一个宏来做这种转换:
#define skb_shinfo(SKB) ((struct skb_shared_info *)((SKB)->end))
那么,这个隐藏的结构用意何在?
它至少有两个目的:
1、 用于管理 paged data
2、 用于管理分片
下图展示了一个很大的数据块,linux内核是如何利用不同的struct sk_buff来把它组织起来的:
而struct sk_buff中的len字段的含义为:
len = l(1) + l(2) + l(3) + l(n+1);
data_len = l(2) + l(3) + l(n+1);
所以线性数据的长度 l(1) = skb->len - skb->data_len;
data_len 中存放的是非线性的数据,也就是整体上不是连续的数据;
l(1) 表示的是线性的数据,是连续的。

skb = queue->rx_skbuff[entry]; if (unlikely(!skb)) { netdev_err(bp->dev, "inconsistent Rx descriptor chain\n"); bp->dev->stats.rx_dropped++; queue->stats.rx_dropped++; break; } /* now everything is ready for receiving packet */ queue->rx_skbuff[entry] = NULL; len = ctrl & bp->rx_frm_len_mask; netdev_vdbg(bp->dev, "gem_rx %u (len %u)\n", entry, len); skb_put(skb, len);
skb_put(skb, len); dma_unmap_single(&bp->pdev->dev, addr, bp->rx_buffer_size, DMA_FROM_DEVICE); skb->protocol = eth_type_trans(skb, bp->dev);
skb_put(skb, len);
/** * skb_put - add data to a buffer * @skb: buffer to use * @len: amount of data to add * * This function extends the used data area of the buffer. If this would * exceed the total buffer size the kernel will panic. A pointer to the * first byte of the extra data is returned. */ void *skb_put(struct sk_buff *skb, unsigned int len) { void *tmp = skb_tail_pointer(skb); SKB_LINEAR_ASSERT(skb); skb->tail += len; skb->len += len; if (unlikely(skb->tail > skb->end)) skb_over_panic(skb, len, __builtin_return_address(0)); return tmp; }
include/linux/skbuff.h:605:#define NET_SKBUFF_DATA_USES_OFFSET 1
#ifdef NET_SKBUFF_DATA_USES_OFFSET static inline unsigned char *skb_tail_pointer(const struct sk_buff *skb) { return skb->head + skb->tail; } static inline void skb_reset_tail_pointer(struct sk_buff *skb) { skb->tail = skb->data - skb->head; } static inline void skb_set_tail_pointer(struct sk_buff *skb, const int offset) { skb_reset_tail_pointer(skb); skb->tail += offset; } #else /* NET_SKBUFF_DATA_USES_OFFSET */ static inline unsigned char *skb_tail_pointer(const struct sk_buff *skb) { return skb->tail; } static inline void skb_reset_tail_pointer(struct sk_buff *skb) { skb->tail = skb->data; } static inline void skb_set_tail_pointer(struct sk_buff *skb, const int offset) { skb->tail = skb->data + offset; } #endif /* NET_SKBUFF_DATA_USES_OFFSET */
eth_type_trans
/** * eth_type_trans - determine the packet's protocol ID. * @skb: received socket data * @dev: receiving network device * * The rule here is that we * assume 802.3 if the type field is short enough to be a length. * This is normal practice and works for any 'now in use' protocol. */ __be16 eth_type_trans(struct sk_buff *skb, struct net_device *dev) { unsigned short _service_access_point; const unsigned short *sap; const struct ethhdr *eth; skb->dev = dev; skb_reset_mac_header(skb); eth = (struct ethhdr *)skb->data; skb_pull_inline(skb, ETH_HLEN); if (unlikely(!ether_addr_equal_64bits(eth->h_dest, dev->dev_addr))) { if (unlikely(is_multicast_ether_addr_64bits(eth->h_dest))) { if (ether_addr_equal_64bits(eth->h_dest, dev->broadcast)) skb->pkt_type = PACKET_BROADCAST; else skb->pkt_type = PACKET_MULTICAST; } else { skb->pkt_type = PACKET_OTHERHOST; } } /* * Some variants of DSA tagging don't have an ethertype field * at all, so we check here whether one of those tagging * variants has been configured on the receiving interface, * and if so, set skb->protocol without looking at the packet. * The DSA tagging protocol may be able to decode some but not all * traffic (for example only for management). In that case give it the * option to filter the packets from which it can decode source port * information. */ if (unlikely(netdev_uses_dsa(dev)) && dsa_can_decode(skb, dev)) return htons(ETH_P_XDSA); if (likely(eth_proto_is_802_3(eth->h_proto))) return eth->h_proto; /* * This is a magic hack to spot IPX packets. Older Novell breaks * the protocol design and runs IPX over 802.3 without an 802.2 LLC * layer. We look for FFFF which isn't a used 802.2 SSAP/DSAP. This * won't work for fault tolerant netware but does for the rest. */ sap = skb_header_pointer(skb, 0, sizeof(*sap), &_service_access_point); if (sap && *sap == 0xFFFF) return htons(ETH_P_802_3); /* * Real 802.2 LLC */ return htons(ETH_P_802_2); }
skb_reset_mac_header
static inline void skb_reset_mac_header(struct sk_buff *skb) { skb->mac_header = skb->data - skb->head; }
skb_pull_inline(skb, ETH_HLEN); 移动data指针
void *skb_pull(struct sk_buff *skb, unsigned int len); static inline void *__skb_pull(struct sk_buff *skb, unsigned int len) { skb->len -= len; BUG_ON(skb->len < skb->data_len); return skb->data += len; } static inline void *skb_pull_inline(struct sk_buff *skb, unsigned int len) { return unlikely(len > skb->len) ? NULL : __skb_pull(skb, len); }
skb->data和dma映射
static void gem_rx_refill(struct macb_queue *queue) { unsigned int entry; struct sk_buff *skb; dma_addr_t paddr; struct macb *bp = queue->bp; struct macb_dma_desc *desc; while (CIRC_SPACE(queue->rx_prepared_head, queue->rx_tail, bp->rx_ring_size) > 0) { entry = macb_rx_ring_wrap(bp, queue->rx_prepared_head); /* Make hw descriptor updates visible to CPU */ rmb(); queue->rx_prepared_head++; desc = macb_rx_desc(queue, entry); if (!queue->rx_skbuff[entry]) { /* allocate sk_buff for this free entry in ring */ skb = netdev_alloc_skb(bp->dev, bp->rx_buffer_size); if (unlikely(!skb)) { netdev_err(bp->dev, "Unable to allocate sk_buff\n"); break; } /* now fill corresponding descriptor entry */ paddr = dma_map_single(&bp->pdev->dev, skb->data, bp->rx_buffer_size, DMA_FROM_DEVICE); if (dma_mapping_error(&bp->pdev->dev, paddr)) { dev_kfree_skb(skb); break; } queue->rx_skbuff[entry] = skb; if (entry == bp->rx_ring_size - 1) paddr |= MACB_BIT(RX_WRAP); desc->ctrl = 0; /* Setting addr clears RX_USED and allows reception, * make sure ctrl is cleared first to avoid a race. */ dma_wmb(); macb_set_addr(bp, desc, paddr); /* properly align Ethernet header */ skb_reserve(skb, NET_IP_ALIGN); } else { desc->ctrl = 0; dma_wmb(); desc->addr &= ~MACB_BIT(RX_USED); } }
gem_rx_refill 先进行dma映射,后进行 skb_reserve
static inline int e100_rx_alloc_skb(struct nic *nic, struct rx *rx) { /*skb缓存的分配,是通过调用系统函数dev_alloc_skb来完成的,它同内核栈中通常调用alloc_skb的区别在于, 它是原子的,所以,通常在中断上下文中使用*/ if(!(rx->skb = dev_alloc_skb(RFD_BUF_LEN + NET_IP_ALIGN))) return -ENOMEM; /*初始化必要的成员 */ rx->skb->dev = nic->netdev; skb_reserve(rx->skb, NET_IP_ALIGN); /*这里在数据区之前,留了一块sizeof(struct rfd) 这么大的空间,该结构的 一个重要作用,用来保存一些状态信息,比如,在接收数据之前,可以先通过 它,来判断是否真有数据到达等,诸如此类*/ memcpy(rx->skb->data, &nic->blank_rfd, sizeof(struct rfd)); /*这是最关键的一步,建立DMA映射,把每一个缓冲区rx->skb->data都映射给了设备,缓存区节点 rx利用dma_addr保存了每一次映射的地址,这个地址后面会被用到*/ rx->dma_addr = pci_map_single(nic->pdev, rx->skb->data, RFD_BUF_LEN, PCI_DMA_BIDIRECTIONAL); if(pci_dma_mapping_error(rx->dma_addr)) { dev_kfree_skb_any(rx->skb); rx->skb = 0; rx->dma_addr = 0; return -ENOMEM; } /* Link the RFD to end of RFA by linking previous RFD to * this one, and clearing EL bit of previous. */ if(rx->prev->skb) { struct rfd *prev_rfd = (struct rfd *)rx->prev->skb->data; /*put_unaligned(val,ptr);用到把var放到ptr指针的地方,它能处理处理内存对齐的问题 prev_rfd是在缓冲区开始处保存的一点空间,它的link成员,也保存了映射后的地址*/ put_unaligned(cpu_to_le32(rx->dma_addr), (u32 *)&prev_rfd->link); wmb(); prev_rfd->command &= ~cpu_to_le16(cb_el); pci_dma_sync_single_for_device(nic->pdev, rx->prev->dma_addr, sizeof(struct rfd), PCI_DMA_TODEVICE); } return 0; }
e100_rx_alloc_skb先进行skb_reserve再dma映射
发送skb

This first diagram illustrates the layoutof the SKB data area and where in that area the various pointers in 'structsk_buff' point.
The rest of this page will walk throughwhat the SKB data area looks like in a newly allocated SKB. How to modify thosepointers to add headers, add user data, and pop headers.
Also, we will discuss how page non-lineardata areas are implemented. We will also discuss how to work with them.
skb= alloc_skb(len, GFP_KERNEL);

As you can see, the head, data, and tailpointers all point to the beginning of the data buffer. And the end pointerpoints to the end of it. Note that all of the data area is considered tailroom.
The length of this SKB is zero, it isn'tvery interesting since it doesn't contain any packet data at all. Let's reservesome space for protocol headers using skb_reserve()
skb_reserve(skb,header_len);

Typically, when building output packets,we reserve enough bytes for the maximum amount of header space we think we'llneed. Most IPV4 protocols can do this by using the socket value sk->sk_prot->max_header.
When setting up receive packets that anethernet device will DMA into, we typically call skb_reserve(skb, NET_IP_ALIGN). By default NET_IP_ALIGN is defined to '2'. This makes it so that, after theethernet header, the protocol header will be aligned on at least a 4-byteboundary. Nearly all of the IPV4 and IPV6 protocol processing assumes that theheaders are properly aligned.
Let's now add some user data to thepacket.
unsignedchar *data = skb_put(skb, user_data_len);
interr = 0;
skb->csum= csum_and_copy_from_user(user_pointer, data,
user_data_len, 0, &err);
if(err)
gotouser_fault;

skb_put() advances 'skb->tail' by the specified number of bytes, it alsoincrements 'skb->len' by that number of bytes as well. This routine must notbe called on a SKB that has any paged data. You must also be sure that there isenough tail room in the SKB for the amount of bytes you are trying to put. Bothof these conditions are checked for by skb_put() and an assertion failure will trigger if either rule is violated.
The computed checksum is remembered in'skb->csum'. Now, it's time to build the protocol headers. We'll build a UDPheader, then one for IPV4.
structinet_sock *inet = inet_sk(sk);
structflowi *fl = &inet->cork.fl;
structudphdr *uh;
skb->h.raw= skb_push(skb, sizeof(struct udphdr));
uh= skb->h.uh
uh->source= fl->fl_ip_sport;
uh->dest= fl->fl_ip_dport;
uh->len= htons(user_data_len);
uh->check= 0;
skb->csum= csum_partial((char *)uh,
sizeof(struct udphdr), skb->csum);
uh->check= csum_tcpudp_magic(fl->fl4_src, fl->fl4_dst,
user_data_len, IPPROTO_UDP,skb->csum);
if(uh->check == 0)
uh->check= -1;

skb_push() will decrement the 'skb->data' pointer by the specified number ofbytes. It will also increment 'skb->len' by that number of bytes as well.The caller must make sure there is enough head room for the push beingperformed. This condition is checked for by skb_push() and an assertion failure will trigger if this rule is violated.
Now, it's time to tack on an IPV4 header.
structrtable *rt = inet->cork.rt;
structiphdr *iph;
skb->nh.raw= skb_push(skb, sizeof(struct iphdr));
iph= skb->nh.iph;
iph->version= 4;
iph->ihl= 5;
iph->tos= inet->tos;
iph->tot_len= htons(skb->len);
iph->frag_off= 0;
iph->id= htons(inet->id++);
iph->ttl= ip_select_ttl(inet, &rt->u.dst);
iph->protocol= sk->sk_protocol; /* IPPROTO_UDP in this case */
iph->saddr= rt->rt_src;
iph->daddr= rt->rt_dst;
ip_send_check(iph);
skb->priority= sk->sk_priority;
skb->dst= dst_clone(&rt->u.dst);

Just as above for UDP, skb_push() decrements 'skb->data' andincrements 'skb->len'. We update the 'skb->nh.raw' pointer to the beginningof the new space, and build the IPv4 header.
This packet is basically ready to bepushed out to the device once we have the necessary information to build theethernet header (from the generic neighbour layer and ARP).
Things start to get a little bit morecomplicated once paged data begins to be used. For the most part the ability touse [page, offset, len] tuples for SKB data came about sothat file system file contents could be directly sent over a socket. But, as itturns out, it is sometimes beneficial to use this for nomal buffering ofprocess sendmsg() data.
It must be understood that once paged datastarts to be used on an SKB, this puts a specific restriction on all future SKBdata area operations. In particular, it is no longer possible to do skb_put() operations.
We will now mention that there areactually two length variables assosciated with an SKB, len and data_len. The latter onlycomes into play when there is paged data in the SKB. skb->data_len tells how many bytes of paged datathere are in the SKB. From this we can derive a few more things:
- The existence of paged data in an SKB is indicated by skb->data_len being non-zero. This is codified in the helper routine skb_is_nonlinear() so that it the function you should use to test this.
- The amount of non-paged data at skb->data can be calculated as skb->len - skb->data_len. Again, there is a helper routine already defined for this called skb_headlen() so please use that.
The main abstraction isthat, when there is paged data, the packet begins at skb->data for skb_headlen(skb) bytes, thencontinues on into the paged data area for skb->data_len bytes. That is why it is illogicalto try and do an skb_put(skb) when there is pageddata. You have to add data onto the end of the paged data area instead.
Each chunk of paged data in an SKB isdescribed by the following structure:
struct skb_frag_struct {
structpage *page;
__u16page_offset;
__u16size;
};
There is a pointer to thepage (which you must hold a proper reference to), the offset within the pagewhere this chunk of paged data starts, and how many bytes are there.
The paged frags are organized into anarray in the shared SKB area, defined by this structure:
#define MAX_SKB_FRAGS (65536/PAGE_SIZE + 2)
struct skb_shared_info {
atomic_tdataref;
unsignedint nr_frags;
unsignedshort tso_size;
unsignedshort tso_segs;
structsk_buff *frag_list;
skb_frag_t frags[MAX_SKB_FRAGS];
};
The nr_frags member states howmany frags there are active in the frags[] array. The tso_size and tso_segs is used to convey information to the devicedriver for TCP segmentation offload. The frag_list is used to maintain a chain of SKBs organizedfor fragmentation purposes, it is _not_ used for maintaining paged data. Andfinally the frags[] holds the frag descriptorsthemselves.
A helper routine is available to help youfill in page descriptors.
void skb_fill_page_desc(struct sk_buff *skb,int i,
structpage *page,
intoff, int size)
This fills the i'th page vector to point to page at offset off of size size. It also updates the nr_frags member to be onepast i.
If you wish to simply extend an existingfrag entry by some number of bytes, increment the size member by that amount.
With all of the complications imposed bynon-linear SKBs, it may seem difficult to inspect areas of a packet in astraightforward way, or to copy data out from a packet into another buffer.This is not the case. There are two helper routines available which make thispretty easy.
First, we have:
void*skb_header_pointer(const struct sk_buff *skb, int offset, int len, void *buffer)
You give it the SKB, theoffset (in bytes) to the piece of data you are interested in, the number ofbytes you want, and a local buffer which is to be used _only_ if the data youare interested in resides in the non-linear data area.
You are returned a pointer to the dataitem, or NULL if you asked for an invalid offset and len parameter. Thispointer could be one of two things. First, if what you asked for is directly inthe skb->data linear data area, you are given a directpointer into there. Else, you are given the buffer pointer you passed in.
Code inspecting packet headers on theoutput path, especially, should use this routine to read and interpret protocolheaders. The netfilter layer uses this function heavily.
For larger pieces of data other thanprotocol headers, it may be more appropriate to use the following helperroutine instead.
int skb_copy_bits(const struct sk_buff *skb,int offset,
void *to, int len);
This will copy thespecified number of bytes, and the specified offset, of the given SKB into the 'to'buffer. This is used for copies of SKBdata into kernel buffers, and therefore it is not to be used for copying SKBdata into userspace. There is another helper routine for that:
int skb_copy_datagram_iovec(const structsk_buff *from,
int offset, struct iovec *to,
int size);
Here,the user's data area is described by the given IOVEC. The other parameters arenearly identical to those passed in to skb_copy_bits() above.
skb_reserve
一般用于alloc skb之后
/** * skb_reserve - adjust headroom * @skb: buffer to alter * @len: bytes to move * * Increase the headroom of an empty &sk_buff by reducing the tail * room. This is only allowed for an empty buffer. */ static inline void skb_reserve(struct sk_buff *skb, int len) { skb->data += len; skb->tail += len; }
e1000的中断
注意:e1000产生rx中断时,以太网数据包已经在系统内存中,即在skb->data里面 下面的中断处理过程就简略了,详细的看这里 do_IRQ() { 中断上半部 调用e1000网卡的rx中断函数 e1000_intr() 触发软中断 (使用NAPI的话) 中断下半部 依次调用软中断的所有handler 在net_rx_action中最终调用e1000的napi_struct.poll()钩子函数,即e1000_clean e1000_clean()最终调用 e1000_clean_rx_irq() } e1000_clean_rx_irq() { rx_desc = E1000_RX_DESC(*rx_ring, i); //获取rx bd status = rx_desc->status; skb = buffer_info->skb; buffer_info->skb = NULL; pci_unmap_single(pdev, //解除skb->data的DMA映射 buffer_info->dma, buffer_info->length, PCI_DMA_FROMDEVICE); length = le16_to_cpu(rx_desc->length); length -= 4; //以太网包的FCS校验就不要了 skb_put(skb, length); skb->protocol = eth_type_trans(skb, netdev); netif_receive_skb(skb); //skb进入协议栈 }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号