Linux网络IO并行化技术概览
过去的十年中互联网经历了爆发式的增长,这背后有什么技术平台起了最为关键的作用,我认为是Linux,即使在云计算流行的今天,它依然是最重要的一块基石。我们或许经常听到关于什么是最好的服务器编程语言、怎样是最好的架构设计的讨论,却从未听到有人讨论什么是最好的服务器操作系统,实际上它的地位早已重要到我们习惯地把它作为一个标准而非一个选择。从2001年2.4到2003年2.6,再到2011年3.0,以至今天的4.6,Linux在性能、稳定、易用等方面持续不断的提升。作为用户很多时候我们发现问题已不在于Linux能否跟上我们的需求,而在于我们能否及时了解掌握Linux的众多功能特性而加以利用。
本文主要来聊一聊关于Linux网络IO(协议栈)的相关技术。记得大约十年前,单box最大性能可以处理上万qps,十万并发连接,而如今单box可处理数十万qps,数百万并发连接。这里除了硬件性能的提升以外,内核的优化技术也起到很大作用。另外,这些优化特性并非总是默认有效或最佳的,时有需要tuning的场景,我在近几年工作中也多次碰到服务器性能问题而通过简单tuning可以有效改善,所以理解它们挺有必要。或许你已经听说过下面这些内核支持特性:中断亲和,多队列网卡、RPS、RFS、XFS、SO_REUSEPORT.. 对它们的介绍资料在网上也有不少,但我发现很少有从全局角度地系统性介绍,所以有了我总结此篇的动机。
首先对上面这些特性我认为可以归纳一个主线:并行化。因为网络协议栈处理,本质来说是CPU密集的计算,所以多年来各种关键优化补丁的共同思路,基本都是怎么充分利用多核的资源达到计算并行。为啥这么简单一个思路会搞出那么多概念呢,因为协议栈计算本身是一个复杂的分层的处理过程,在各个层各处理环节都有并行优化的空间,上述这些优化补丁正是在这些不同的层次的工作。下面我将按此脉络展开对这些技术点做一个介绍。
Linux协议栈
首先我们先回顾一下Linux协议栈的分层结构,如下图:

最底层是硬件网卡(NIC),它通常通过两个内存环型队列(rx_ring/tx_ring)加上中断机制与操作系统进行通讯。当NIC收到数据包后,它将数据包写入rx_ring并产生中断。CPU收到中断后OS将陷入中断处理程序中执行,这在Linux内核中叫Hard-IRQ。
在较老版内核中,网卡Hard-IRQ程序将数据包从rx_ring中取出并放入PerCPU的一个叫backlog的队列,然后发起一个Soft-IRQ来处理backlog队列 (内核将中断处理中无需实时同步完成的工作delay到一个准实时的异步时机去执行,这个异步机制即Soft-IRQ)。较新版的内核中,通常并不使用backlog队列,而是使用叫NAPI的改进机制,区别是Hard-IRQ不再直接读取每个数据包,而是直接启动Soft-IRQ,在Soft-IRQ中通过batch poll的方式将数据包从rx_ring中取出并处理 (可大大减少中断数)。
不管是backlog还是NAPI,它们都在Soft-IRQ上下文中执行,并把数据包提交给IP层进行处理(为简单我们都以TCP/IP协议为例)。IP层处理完分片和路由后将提交给传输层(TCP或UDP)进行处理。协议相关逻辑我们不在这里详述,最终它将此数据包放入对应的socket对象的接收队列中,并唤醒阻塞在socket上的进程。
用户态进程通过socket fd来操作内核中的socket对象,经常它会阻塞在socket相关的read/write或epoll/select的操作上。还需注意到Linux的文件机制允许多个进程通过各自的fd同时竞争操作同一个socket对象。典型地场景如,多个进程竞争accept一个listening的socket,再如,多个进程竞争读一个udp socket。
中断调度
协议栈对入包的软件部分处理,总是从硬中断(Hard-IRQ)处理开始的。关于中断处理你需要了解几个事实:
计算机系统中有很多不同作用的中断请求,由中断号唯一标识,比如每块网卡有自己的中断号
对每个中断号,系统都会注册一个handler(也就我们通常说的中断处理程序)
在Hard-IRQ handler中(如网卡中断处理程序)通常将无需立即完成的工作(如TCP/IP协议栈处理)通过Soft-IRQ异步地执行
Soft-IRQ顾名思义就是软件构造的类似的中断机制,它也根据用途区分不同的类型,并有对应的handler。它存在的主要意义是让中断对系统实时性的影响尽可能小
不管是Hard-IRQ还是Soft-IRQ handler,它们都是一段需要调度的执行流(就像线程一样),那么问题来了:如何高效地调度这些执行流在多核下运行,对系统性能非常关键。下面介绍一下目前的一些调度机制:
对同一个中断号的Hard-IRQ handler,在全局上是串行执行的,即同时只能在一个核上执行
对不同的中断号的Hard-IRQ handler,可以在不同的核上并行执行
某个中断号在哪个核上执行,通常由系统中的I/O APIC(高级可编程中断控制器)来决定,内核提供了配置接口(也有一种称为irqbalance的动态调整工具可选)
Hard-IRQ handler中发起的Soft-IRQ,一般在同一个core上执行
我们可以使用下面的命令观察系统中所有中断号以及它们在各core上的调度情况:
cat /proc/interrupts
下面回到网络IO的主题上,从网卡中断的角度看协议栈处理,如下图:

传统的网卡每块设备有一个中断号,它由上述的调度机制为每个中断请求分配给一个唯一的core来执行。在此场景下,你会发现协议栈处理的并行化是以网卡设备为粒度的。
如果只有单块网卡,就会发现中断处理CPU消耗集中于单个核上(记得默认对应的Soft-IRQ会在同一个core上执行);更坏的情况是,如果只有一个处理socket的应用进程,很可能你会看到所有CPU负载集中于一个core上(实际上进程调度策略会优化将唤醒的进度调度在相同的core上执行)。怎么优化?别着急下面的内容中会有很多方法。
如果有多块网卡,通常来因为利用多核并行而会获得性能的提升,如下图所示:

但我们也曾发现过例外,虽然两块网卡的中断请求被调度到2个core上,但它们是超线程技术对同一物理core虚拟出的2个逻辑core,并不能有效地并行处理。解决方法是手工配置中断亲和(绑定中断号与具体的core),如下命令:
echo 02 > /proc/irq/123/smp_affinity
多队列网卡
如前所述,传统的单网卡默认无法充分利用多核,即使是多网卡,在数量小于核数的情况下也是一样。于是产生了在今天广泛使用的多队列网卡(Multi-Queue NIC),在一些资料里这种技术也叫RSS(Receive-Side Scaling)。这种技术概括来说是从硬中断的层面支持了单网卡IO的并行,其工作原理如下图所示:

多队列网卡通过引入RX-Queue的机制,将输入流量水平分到多个“虚拟的网卡”也是RX-Queue,每个RX-Queue像一个独立设备一样有自己的中断号并可以独立并行地工作。RX-Queue的数量一般可以配置为与核数一致,这样可以充分利用多核资源。
值得注意的是,输入流量拆分到RX-Queue的算法是根据Hash(SrcIP, SrcPort, DstIP, DstPort)来计算的(可以试想下为什么是用hash而不是类似随机分发?对,主要是为了避免乱序)。如果出现大部分流量来自少量IP:Port的场景,多队列网卡并就爱莫能助了。
你可以使用前面提到的interrupts文件来观察多队列网卡的分发效果:
cat /proc/interrupts
这里也有篇文章较详细介绍了这个主题可作参考。
RPS
在没有多队列网卡的服务器上,比如一个典型的场景是虚拟机或云主机,如何优化网络IO呢?下面要介绍的是纯软件的优化方案:RPS & RFS, 这是在2.6.35内核加入的由Google工程师Tom Herbert开发的优化补丁。它的工作原理如下图所示:

RPS是工作在NAPI层(或者说在Soft-IRQ处理中接近入口的位置)的入流量分发机制,它利用了前面提到的Per-CPU的backlog队列来将数据包分发到目标core上。默认的分发算法与多队列机制类似,也是使用IP,Port四元组的哈希来映射到某一个core。与多队列机制类似,若是流量来自少量IP:Port的场景,负载将无法很好地均衡在多核上。我们目前在AWS虚拟机上普遍配置启用了RPS,优化效果还是非常明显。
配置RPS的方法也很简单:
echo ff > /sys/class/net/eth0/queues/rx-0/rps_cpus
更详细的配置说明可参考这里
如何观察RPS的分发效果呢?由于RPS分发会多做一次Soft-IRQ调度,我们可以通过观察Soft-IRQ的统计接口来观察调度效果:
cat /proc/softirqs | grep NET_RX
前面我们说到在没有多队列网卡的服务器,RPS可以发挥重要作用,那如果已经有多队列网卡了是否还需要RPS呢?根据我目前的经验来说,一般情况下有队列网卡的环境下配置RPS不会再有明显的提升。但我认为仍存在一些情况结合RPS是有意义的,比如队列数明显少于核数,再比如某些RFS(下面会介绍)可以优化的场景可以打开RPS+RFS。
如果你有兴趣看一下RPS的关键内核代码,可以查看这里。
这里也有篇文章介绍了一些内核实现细节可作参考。
RPS原理
流程对比
开启RPS/RFS后,网络数据接收流程对比:

从流程中可以看出,相比传统的被中断cpu处理数据包变为中断cpu将数据存入backlog,等待rps实现的软中断自行分配到映射到的cpu处理,进而交付给报文所属app正在运行的cpu处理。
代码实现
核心数据结构
/* This structure contains an instance of an RX queue. */
/* 网卡接收队列 */
struct netdev_rx_queue {
#ifdef CONFIG_RPS
struct rps_map __rcu *rps_map;//RPS cpu映射表
struct rps_dev_flow_table __rcu *rps_flow_table;//RFS流表
#endif
struct kobject kobj;
struct net_device *dev;
struct xdp_rxq_info xdp_rxq;
} ____cacheline_aligned_in_smp;
/*
* This structure holds an RPS map which can be of variable length. The
* map is an array of CPUs.
* RPS的映射图,即该网络设备可以被分发的CPU映射表。是一个可变长度的数组。
* 动态分配,其长度为len,即分配的cpu的个数
*/
struct rps_map {
unsigned int len;//cpus数组的长度
struct rcu_head rcu;
u16 cpus[0];//cpu数组
};
//根据CPU的个数分配的映射表内存大小
#define RPS_MAP_SIZE(_num) (sizeof(struct rps_map) + ((_num) * sizeof(u16)))
流程图
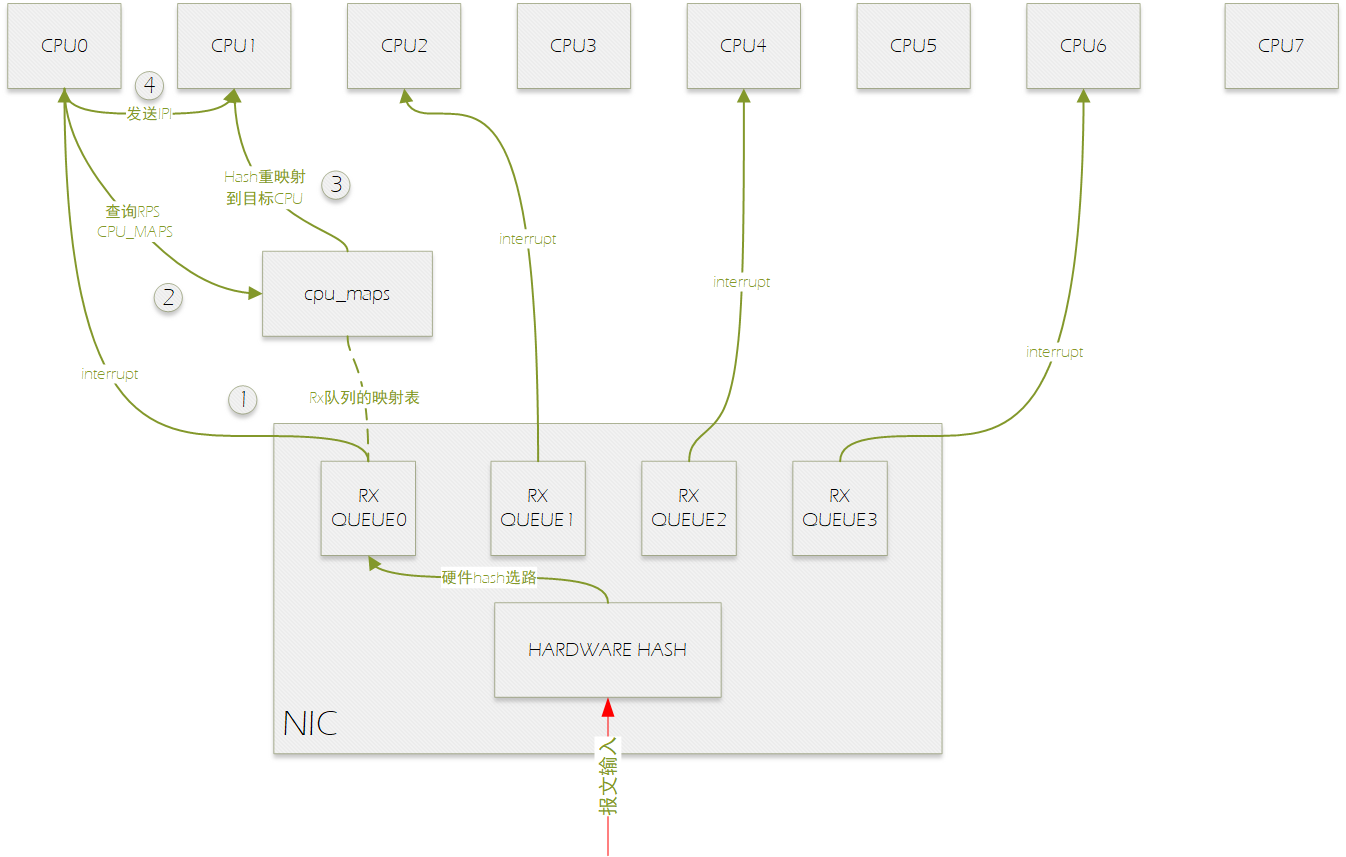
如上图所示,网卡有四个接收多列,分别绑定到cpu0,2,4,6上,报文输入处理流程如下:
0.报文进入网卡后,硬件hash选择RX QUEUE。
1.RX QUEUE0硬件中断CPU0。
2.CPU0在软中断中处理该报文时,进行RPS选择目标CPU进行处理,通过查询RXQUEUE0的rps_maps选择的目标CPU为CPU1。
3.将报文送到CP1的backlog虚拟NAPI报文输入队列中。
4.向CPU1发送IPI。
当新的数据到来,内核调用如下序列:
Hdd_rx_deliver_to_stack
->netif_receive_skb
->netif_receive_skb_internal


NAPI驱动收包进行报文RPS分发
int netif_receive_skb(struct sk_buff *skb) { trace_netif_receive_skb_entry(skb); return netif_receive_skb_internal(skb); } static int netif_receive_skb_internal(struct sk_buff *skb) { int ret; ...... rcu_read_lock(); #ifdef CONFIG_RPS if (static_key_false(&rps_needed)) { struct rps_dev_flow voidflow, *rflow = &voidflow; //获取目的CPU int cpu = get_rps_cpu(skb->dev, skb, &rflow); if (cpu >= 0) { //将报文压入虚拟的napi设备收包队列 ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail); rcu_read_unlock(); return ret; } } #endif //没有是能RPS的话,直接上送上层协议处理,进入软中断中。 ret = __netif_receive_skb(skb); rcu_read_unlock(); return ret; }
非NAPI驱动收包进行报文RPS分发
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
......
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
//获取处理的目的CPU
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
//将报文压入虚拟的napi设备收包队列
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
//没有RPS的话,直接压入本cpu的虚拟napi收包队列中
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
get_rps_cpu函数主要是为了返回为处理报文配置的cpu,确保此报文将来会被期望的cpu执行处理。

sock_flow_table是保存在内中种的一张全局的hash表,用于映射socket和cpu。这里是保证了软中断会发生在应用期望的cpu核心上。flow_table,这个是针对设备的,每个设备队列都含有一个rps_dev_flow_table结构(这个表主要是保存了上次处理相同链接上的skb所在的cpu),这个hash表中每一个元素包含了一个cpu id

接下来进行cpu选择,skb中对应的hash值和sock mask计算确认想要运行的cpu在配置的范围之内(很可能此skb想要运行在cpu6,但是我们只配置了cpu 0-3作为报文处理cpu)
Tcp(应用所在)和next_cp(上一次分配数据给了那个cpu,本次分配给下一个cpu)分别从sock_flow_table和rps_flow_table计算出来,都是表示此报文接下来被哪个cpu处理。如果两者产生冲突,需要判断一**释中所说的情况。

1. tcpu未设置(等于RPS_NO_CPU)
2. tcpu是离线的
3. tcpu的input_queue_head大于rps_flow_table中的last_qtail 的话就调度这个skb到next_cpu(当前应用所在cpu负载过高,分配报文到其他空闲的cpu).而这里第三点input_queue_head大于rps_flow_table则说明在当前的dev flow table中的数据包已经发送完毕,否则的话为了避免乱序就还是继续使用tcpu。

Enqueye_to_backlog根据取得的softnet_data,防止数据到per-CPU(每个CPU维护一个per_cpu变量用于维持每个cpu运行时独立的上下文)维护的队列中。
static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; /*获取cpu相关的softnet_data变量*/ sd = &per_cpu(softnet_data, cpu); /*关中断*/ local_irq_save(flags); rps_lock(sd); /*如果input_pkt_queue的长度小于最大限制,则符合条件*/ if (skb_queue_len(&sd->input_pkt_queue) <= netdev_max_backlog) { /*如果input_pkt_queue不为空,说明虚拟设备已经得到调度,此时仅仅把数据加入 input_pkt_queue队列即可 */ if (skb_queue_len(&sd->input_pkt_queue)) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); return NET_RX_SUCCESS; } /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ /*否则需要调度backlog 即虚拟设备,然后再入队。napi_struct结构中的state字段如果标记了NAPI_STATE_SCHED,则表明该设备已经在调度,不需要再次调度*/ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); } goto enqueue; } /*到这里缓冲区已经不足了,必须丢弃*/ sd->dropped++; rps_unlock(sd); local_irq_restore(flags); atomic_long_inc(&skb->dev->rx_dropped); kfree_skb(skb); return NET_RX_DROP; }
Napi_schedule唤醒软中断。

static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; /*获取cpu相关的softnet_data变量*/ sd = &per_cpu(softnet_data, cpu); /*关中断*/ local_irq_save(flags); rps_lock(sd); /*如果input_pkt_queue的长度小于最大限制,则符合条件*/ if (skb_queue_len(&sd->input_pkt_queue) <= netdev_max_backlog) { /*如果input_pkt_queue不为空,说明虚拟设备已经得到调度,此时仅仅把数据加入 input_pkt_queue队列即可 */ if (skb_queue_len(&sd->input_pkt_queue)) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); return NET_RX_SUCCESS; } /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ /*否则需要调度backlog 即虚拟设备,然后再入队。napi_struct结构中的state字段如果标记了NAPI_STATE_SCHED,则表明该设备已经在调度,不需要再次调度*/ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); } goto enqueue; } /*到这里缓冲区已经不足了,必须丢弃*/ sd->dropped++; rps_unlock(sd); local_irq_restore(flags); atomic_long_inc(&skb->dev->rx_dropped); kfree_skb(skb); return NET_RX_DROP; }
软中断唤醒skb对应的cpu,处理数据backlog中的数据报文。之后进入BSD协议栈上报给用户空间。
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); }
RFS
RFS是在RPS分发机制基础上的一个扩展。它尝试解决这么一个问题,即然我在软件层面做数据包的分发,能不能比硬件多队列方案的近似随机的Hash分发方式更智能更高效一些呢?比如按Hash分发的一个问题就是,准备接收这个数据包的进程所在core很可能跟按Hash选择的core不是同一个,这样会导致cache miss及cache line bouncing,在多核高并发场景这对性能影响会十分可观。
RFS尝试优化这个问题,它尽力将收到数据包分发给接收它的进程所在的core上,先看一下原理图:

首先RFS会维护一张全局的路由表(图中SockFlowTable),表中记录了一个FlowHash(四元组的Hash值)到对应CPU核的路由项。表项怎么建立呢?是在进程调用某socket的recvmsg系统调用(也包括recv/recvfrom)时,将该socket的FlowHash值(由最后一次收到包的FlowHash决定)与当前的CPU核关联起来。在RPS做包转发时,实际它会先判断是否启用了RFS,并且能找到有效的RFS路由项,否则的话仍使用默认RPS逻缉进行转发。
另外RFS还维护一张Per-Queue的局部路由表(图中Per-Queue FlowTable),它有什么用呢?主要作用是为了在全局路由表发生变化时,避免原路由路径上的包还没有被完全处理完而导致的乱序。它的原理并不复杂,在局部路由表中会记录某FlowHash(实际实现是FlowHash的hash)最后一次包转发时的关联CPU核,同时会记录当时该核对应的backlog队列的队尾标号(qtail)。当下次转发该flow上下一个包时,如果全局路由给出的CPU核发生了变化,则判断当前backlog队列的队首标号是否大于qtail,如果是说明上一次转发的包已经被处理完了,可以安全地切换到全局路由给出的新的CPU核,否则的话为了保证有序仍选择上一次使用的CPU核。
从原理上可以看出,在每个socket有唯一的进程/线程处理时RFS会有较好地效果,同时,对于在同一进程/线程内多路复用操作多个socket的场景,建议结合绑定进程/线程到固定CPU核的方式可以进一步发挥RFS的作用(让转发路由规则固定,进一步减少cache line bouncing)。
RFS的配置也比较简单,有两处,一个是全局路由表的大小,另一个是局部路由表的大小(一般设为前者大小/RX-Queue数),如下例:
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
更详细的配置说明可参考这里。
如果有兴趣看一下它的实现,可从这里(记录路由)和这里(查询路由)入手。
实现原理
/* * The rps_sock_flow_table contains mappings of flows to the last CPU * on which they were processed by the application (set in recvmsg). */ struct rps_sock_flow_table { unsigned int mask; u16 ents[0]; }; #define RPS_SOCK_FLOW_TABLE_SIZE(_num) (sizeof(struct rps_sock_flow_table) + \ ((_num) * sizeof(u16)))
结构体 rps_sock_flow_table 实现了一个hash表,RFS会将其声明一个全局变量用于存放所有sock对应的CPU。
/* * The rps_dev_flow structure contains the mapping of a flow to a CPU, the * tail pointer for that CPU's input queue at the time of last enqueue, and * a hardware filter index. */ struct rps_dev_flow { u16 cpu; //此链路上次使用的cpu u16 filter; unsigned int last_qtail; //此设备队列入队的sk_buff的个数 }; #define RPS_NO_FILTER 0xffff /* * The rps_dev_flow_table structure contains a table of flow mappings. */ struct rps_dev_flow_table { unsigned int mask; struct rcu_head rcu; struct rps_dev_flow flows[0]; //实现hash表 }; #define RPS_DEV_FLOW_TABLE_SIZE(_num) (sizeof(struct rps_dev_flow_table) + \ ((_num) * sizeof(struct rps_dev_flow)))
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size, int flags) { struct sock *sk = sock->sk; int addr_len = 0; int err; sock_rps_record_flow(sk); //设置CPU id err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT, flags & ~MSG_DONTWAIT, &addr_len); if (err >= 0) msg->msg_namelen = addr_len; return err; } EXPORT_SYMBOL(inet_recvmsg);
当有数据包进行了响应后,会调用get_rps_cpu()选择合适的CPU id。其关键代码如下:

3117 hash = skb_get_hash(skb);
3118 if (!hash)
3119 goto done;
3120
3121 flow_table = rcu_dereference(rxqueue->rps_flow_table); //设备队列的hash表
3122 sock_flow_table = rcu_dereference(rps_sock_flow_table); //全局的hash表
3123 if (flow_table && sock_flow_table) {
3124 u16 next_cpu;
3125 struct rps_dev_flow *rflow;
3126
3127 rflow = &flow_table->flows[hash & flow_table->mask];
3128 tcpu = rflow->cpu;
3129
3130 next_cpu = sock_flow_table->ents[hash & sock_flow_table->mask]; //得到用户程序运行的CPU id
3131
3132 /*
3133 * If the desired CPU (where last recvmsg was done) is
3134 * different from current CPU (one in the rx-queue flow
3135 * table entry), switch if one of the following holds:
3136 * - Current CPU is unset (equal to RPS_NO_CPU).
3137 * - Current CPU is offline.
3138 * - The current CPU's queue tail has advanced beyond the
3139 * last packet that was enqueued using this table entry.
3140 * This guarantees that all previous packets for the flow
3141 * have been dequeued, thus preserving in order delivery.
3142 */
3143 if (unlikely(tcpu != next_cpu) &&
3144 (tcpu == RPS_NO_CPU || !cpu_online(tcpu) ||
3145 ((int)(per_cpu(softnet_data, tcpu).input_queue_head -
3146 rflow->last_qtail)) >= 0)) {
3147 tcpu = next_cpu;
3148 rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
3149 }
3150
3151 if (tcpu != RPS_NO_CPU && cpu_online(tcpu)) {
3152 *rflowp = rflow;
3153 cpu = tcpu;
3154 goto done;
3155 }
3156 }

3117 hash = skb_get_hash(skb);
3118 if (!hash)
3119 goto done;
3120
3121 flow_table = rcu_dereference(rxqueue->rps_flow_table); //设备队列的hash表
3122 sock_flow_table = rcu_dereference(rps_sock_flow_table); //全局的hash表
3123 if (flow_table && sock_flow_table) {
3124 u16 next_cpu;
3125 struct rps_dev_flow *rflow;
3126
3127 rflow = &flow_table->flows[hash & flow_table->mask];
3128 tcpu = rflow->cpu;
3129
3130 next_cpu = sock_flow_table->ents[hash & sock_flow_table->mask]; //得到用户程序运行的CPU id
3131
3132 /*
3133 * If the desired CPU (where last recvmsg was done) is
3134 * different from current CPU (one in the rx-queue flow
3135 * table entry), switch if one of the following holds:
3136 * - Current CPU is unset (equal to RPS_NO_CPU).
3137 * - Current CPU is offline.
3138 * - The current CPU's queue tail has advanced beyond the
3139 * last packet that was enqueued using this table entry.
3140 * This guarantees that all previous packets for the flow
3141 * have been dequeued, thus preserving in order delivery.
3142 */
3143 if (unlikely(tcpu != next_cpu) &&
3144 (tcpu == RPS_NO_CPU || !cpu_online(tcpu) ||
3145 ((int)(per_cpu(softnet_data, tcpu).input_queue_head -
3146 rflow->last_qtail)) >= 0)) {
3147 tcpu = next_cpu;
3148 rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
3149 }
3150
3151 if (tcpu != RPS_NO_CPU && cpu_online(tcpu)) {
3152 *rflowp = rflow;
3153 cpu = tcpu;
3154 goto done;
3155 }
3156 }
2374 #ifdef CONFIG_RPS 2375 /* Elements below can be accessed between CPUs for RPS */ 2376 struct call_single_data csd ____cacheline_aligned_in_smp; 2377 struct softnet_data *rps_ipi_next; 2378 unsigned int cpu; 2379 unsigned int input_queue_head; //队列头,也可以理解为出队的位置 2380 unsigned int input_queue_tail; //队列尾,也可以理解为入队的位置 2381 #endif
2374 #ifdef CONFIG_RPS 2375 /* Elements below can be accessed between CPUs for RPS */ 2376 struct call_single_data csd ____cacheline_aligned_in_smp; 2377 struct softnet_data *rps_ipi_next; 2378 unsigned int cpu; 2379 unsigned int input_queue_head; //队列头,也可以理解为出队的位置 2380 unsigned int input_queue_tail; //队列尾,也可以理解为入队的位置 2381 #endif
XPS
作者也是Google的Tom Herbert,内核2.6.38被引入。XPS解决的是一个在多队列网卡场景下才存在的问题:默认情况下当协议栈处理到需要向一个网卡设备发包时,如果是多队列网卡(有多个TX-Queue),会使用四元组hash的方式选择一个TX-Queue进行发送。这里有一个性能损耗是,在多核的场景下,可能会存多个核同时向一个TX-Queue发送数据的情况,因为这个操作需要写相应的tx_ring等内存,会引发cache line bouncing的问题,带来系统整体性能的下降。而XPS提供这样一种机制,可以将不同的TX-Queue固定地分配给不同的CPU集合去操作,这样对于某一个TX-Queue,仅有一个或少数几个CPU核会去写,可以避免或大大减少冲突写带来的cache line bouncing问题。
设置XPS非常简单,与RPS类似,如下示例:
echo 11 > /sys/class/net/eth0/queues/tx-0/xps_cpus
echo 22 > /sys/class/net/eth0/queues/tx-1/xps_cpus
echo 44 > /sys/class/net/eth0/queues/tx-2/xps_cpus
echo 88 > /sys/class/net/eth0/queues/tx-3/xps_cpus
可以注意的是,根据原理,对于非多队列网卡设置XPS是没有意义和效果的。如果一个CPU核没有出现在任何一个TX-Queue的xps_cpus设置里,当该CPU核对该设备发包时,会退回使用默认hash的方式去选择TX-Queue。
如果你对它的实现有兴趣,可以从这里看起。
这里是一篇原作者对此的简介。
SO_REUSEPORT
前面我们讨论的都是协议栈偏底层的并行优化,然而在上层也就是socket层,同样有一个重要的优化补丁:SO_REUSEPORT socket选项(注意不要与SO_REUSEADDR搞混)。它的作者还是Tom Herbert~(本文应感谢该伙计:),在内核3.9被引入。
它解决了什么样的问题呢?考虑一个监听唯一端口的TCP服务器,如果想利用多核并发以提升总体吞吐,需要考虑使用多进程/多线程。一个简单直接的方法是多个进程竞争accept监听socket,你可能有经验这种方法的一个缺陷是,各个进程/线程无法保证负载均衡地accept到新socket。直接解决这个问题可能需要写比较麻烦的workaround(比如我们曾使用连接数表+sched_yield的方法来保证负载均衡)。还有一个流行的处理模式是,使用一个线程负责listen和accept,然后将socket负载均衡地dispatch到一个worker线程组,每个worker线程处理一个socket子集的IO。这种模式对于长连接服务还是比较适合的,但如果是有大量connect请求的短连接场景,单个线程accept将可能成为瓶颈。解决这个问题可能又需要考虑使用复杂的多线程竞争accept的方式,但依然有socket访问竞争、cache line bouncing等效率问题。
对于UDP服务器,也有类似的问题,单进程读容易达到单核瓶颈,多进程竞争读又会有一定的性能损耗。多进程竞争读的原理如下图所示:

SO_REUSEPORT很好地解决了多进程读写同一端口场景的2个问题:负载均衡和访问竞争。通过这个选项,多个用户进程/线程可以各自创建一个独立socket,但它们又共享同一端口,该端口的流量默认按四元组hash的方式分发各socket上(最新内核还支持使用bpf方式自定义分发策略),思路是不是非常熟悉。原理示意图如下:

使用此方式,TCP/UDP服务器编程模式都非常简单了,多进程/线程创建socket设置SO_REUSEPORT后bind,后面像单进程一样处理就可以了。同时性能也可获得明显提升,我们较早前一个经验是UDP改造后qps提升一倍。
如果你对它的实现有兴趣,可以从这里(UDP)和这里(TCP)看看源码。
这里有一篇介绍得也比较详细的文章。
总结
本文介绍了Linux内核关于网络IO并行化的一系列技术(多队列、RPS、RFS、XPS、SO_REUSEPORT),它们是在协议栈不同的层面,但都使用了类似的方法提升了网络IO的并行性,并尽量减少了cache line bouncing。这些出色的工具可以帮助我们在任何Linux平台上构建高性能的网络服务器。
http://kerneltravel.net/blog/2020/network_ljr9/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号