perf 系统调用
-
perf top
用于实时显示当前系统的性能统计信息。该命令主要用来观察整个系统当前的状态,比如可以通过查看该命令的输出来查看当前系统最耗时的内核函数或某个用户进程
linux系统下可以使用perf性能分析工具,做热点函数分析,perf安装命令yum install perf。perf常用的热点函数定位命令如下:
- 进程级:perf top -p <pid>
- 线程级:perf top -t <tid>
-
perf record
perf record -a -e cycles -o cycle.perf -g sleep 10
-a 对所有 CPU 采样 -o 输出文件名,如果不指定,默认生成 perf.data -g 额外记录函数调用关系 sleep 10 采样 10s
perf record -F 99 -p 13204 -g -- sleep 30
perf record表示记录 -F 99表示每秒99次 -p 13204是进程号,即对哪个进程进行分析 -g 表示记录调用栈 sleep 30 如上所述则是持续30秒。
perf record命令可以统计每个调用栈出现的百分比,然后从高到低排列。
一样地,perf record 可以加 -p 表示跟踪单个进程,也可以不加表示跟踪整个系统。


perf record记录程序运行数据,会在当前目录生成 perf.data文件,这个文件可以用 perf report来进行解析和展示,它也是默认读取的当前目录下的 perf.data。
-
perf report
perf report -n --stdioperf report -i <file>
-i 指定 perf record 生成的 perf data 文件,如果不指定 -i 则默认分析 perf.data 文件。 –max-stack=0 只输出第一层函数调用 –stdio 输出到标准输出

–stdio 参数可以让 perf report 标准输出进行展示,这个我比较喜欢,总觉得比 tui 的模式一个一个站看看要方便很多。 –no-children 是以自底向上的模式真是统计数据,这里需要说明一下的是,一般profiler最终展示堆栈统计数据,都会提供两种模式,一种叫 TopDown,就是从调用栈的根(C/C++一般就是 _start -> __libc_start_main -> main)从上至下进行分解,每个函数分支占用了多少资源占用比例;另外一种就是 BottomUp,这种方式下profiler会挑选各个占用资源最多的叶子函数,这里叶子的意思就是它没有子函数调用了。 –no-children就是后面这种方式,不过个人感觉还是 TopDown 的方式比较直观,能从宏观上进行把控,BottomUp 直接掉进细节里面去了,这种方式对付简单的程序还好,但是复杂的系统就比较麻烦了
[root@bogon ~]# perf record -F 99 -p 14060 -g -o neturon.perf -- sleep 5 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.021 MB neturon.perf (5 samples) ] [root@bogon ~]# perf report -n --stdio -i neturon.perf # To display the perf.data header info, please use --header/--header-only options. # # # Total Lost Samples: 0 # # Samples: 5 of event 'cycles:ppp' # Event count (approx.): 55785 # # Children Self Samples Command Shared Object Symbol # ........ ........ ............ ....... ................. .................................. # 100.00% 0.00% 0 haproxy [unknown] [k] 0x0000ffffeb73fe5f | ---0xffffeb73fe5f 0xaaaaaddd42e8 __libc_start_main main 0xaaaaaddd6528 | --99.82%--0xaaaaadde1e30 100.00% 0.00% 0 haproxy haproxy [.] 0x0000aaaaaddd42e8 | ---0xaaaaaddd42e8 __libc_start_main main 0xaaaaaddd6528 | --99.82%--0xaaaaadde1e30 100.00% 0.00% 0 haproxy libc-2.17.so [.] __libc_start_main | ---__libc_start_main main 0xaaaaaddd6528 | --99.82%--0xaaaaadde1e30 100.00% 0.00% 0 haproxy haproxy [.] main | ---main 0xaaaaaddd6528 | --99.82%--0xaaaaadde1e30 100.00% 0.00% 0 haproxy haproxy [.] 0x0000aaaaaddd6528 | ---0xaaaaaddd6528 | --99.82%--0xaaaaadde1e30 99.82% 99.82% 1 haproxy haproxy [.] 0x0000000000021e30 | ---0xffffeb73fe5f 0xaaaaaddd42e8 __libc_start_main main 0xaaaaaddd6528 0xaaaaadde1e30 99.82% 0.00% 0 haproxy haproxy [.] 0x0000aaaaadde1e30 | ---0xaaaaadde1e30 0.18% 0.18% 4 haproxy [kernel.kallsyms] [k] finish_task_switch 0.18% 0.00% 0 haproxy haproxy [.] 0x0000aaaaade430fc 0.18% 0.00% 0 haproxy libc-2.17.so [.] epoll_pwait 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] __sys_trace_return 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] sys_epoll_pwait 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] sys_epoll_wait 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] schedule_hrtimeout_range 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] schedule_hrtimeout_range_clock 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] schedule 0.18% 0.00% 0 haproxy [kernel.kallsyms] [k] __sched_text_start # # (Cannot load tips.txt file, please install perf!) #
[root@bogon ~]# ps -elf | grep ping 4 S root 22924 22245 0 80 0 - 1784 poll_s 11:36 pts/1 00:00:00 ping 8.8.8.8 0 S root 22927 21295 0 80 0 - 1726 pipe_w 11:36 pts/0 00:00:00 grep --color ping [root@bogon ~]# perf trace record --call-graph dwarf -p 22924 -o ping.perf -- sleep 5 [ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.603 MB ping.perf (70 samples) ] [root@bogon ~]# perf report -n --stdio -i ping.perf # To display the perf.data header info, please use --header/--header-only options. #
Perf
众所周知,perf 是 Linux 系统下非常强大的性能工具,由 Linux 内核开发人员在不断演进和优化。除了可以分析 PMU (Performance Monitoring Unit) 硬件事件,内核事件等通用功能外,perf 还提供了其他“子模块”,比如 sched 分析调度器,timechart 根据负载特征可视化系统行为,c2c 分析可能存在的 false sharing (RedHat 在大量 Linux 的应用上,测试过这套 c2c 的开发原型,成功地发现了很多热点的伪共享缓存行问题。)等, 而 trace 则可用于分析系统调用,其功能非常强大,并保证了可以接受的开销—— 运行速度仅放慢 1.36 倍(dd 作为测试负载) 。我们一起看下几个常用的场景:
-
调用 syscall 数量的 top 排行榜
perf top -F 49 -e raw_syscalls:sys_enter --sort comm,dso --show-nr-samples![]() image
image从输出可以看到在采样期间,kube-apiserver 的调用 syscall 的次数最多。
-
显示超过一定延迟的系统调用信息
perf trace --duration 200![]() image
image从输出中可以看到进程名称、pid ,超过 200 ms 的具体系统调用参数和返回值。


-
统计某个进程一段时间内系统调用的开销
perf trace -p $PID -s![]() image
image从输出中可以看到各系统调用的次数,返回错误次数,总延迟,平均延迟等信息。

-
我们也可以进一步分析高延迟的调用栈信息
perf trace record --call-graph dwarf -p $PID -- sleep 10![]() image
image -
对一组任务进行 trace,比如后台有 2 个 bpf 工具在运行,我们想看下它们系统调用使用情况,就可以先将它们添加到 perf_event 这个 cgroup 下,再执行 perf trace:
mkdir /sys/fs/cgroup/perf_event/bpftools/ echo 22542 >> /sys/fs/cgroup/perf_event/bpftools/tasks echo 20514 >> /sys/fs/cgroup/perf_event/bpftools/tasks perf trace -G bpftools -a -- sleep 10![]() image
image


perf-trace 的使用就介绍到这里,更多的用法请参考 man 手册,从上面可以看到 perf-trace 的功能非常强大,根据 pid 或 tid 就可以进行过滤。但似乎没有对容器和 K8S 环境进行便捷的支持。不用着急,接下来介绍的这个工具就是针对容器和 K8S 环境的。
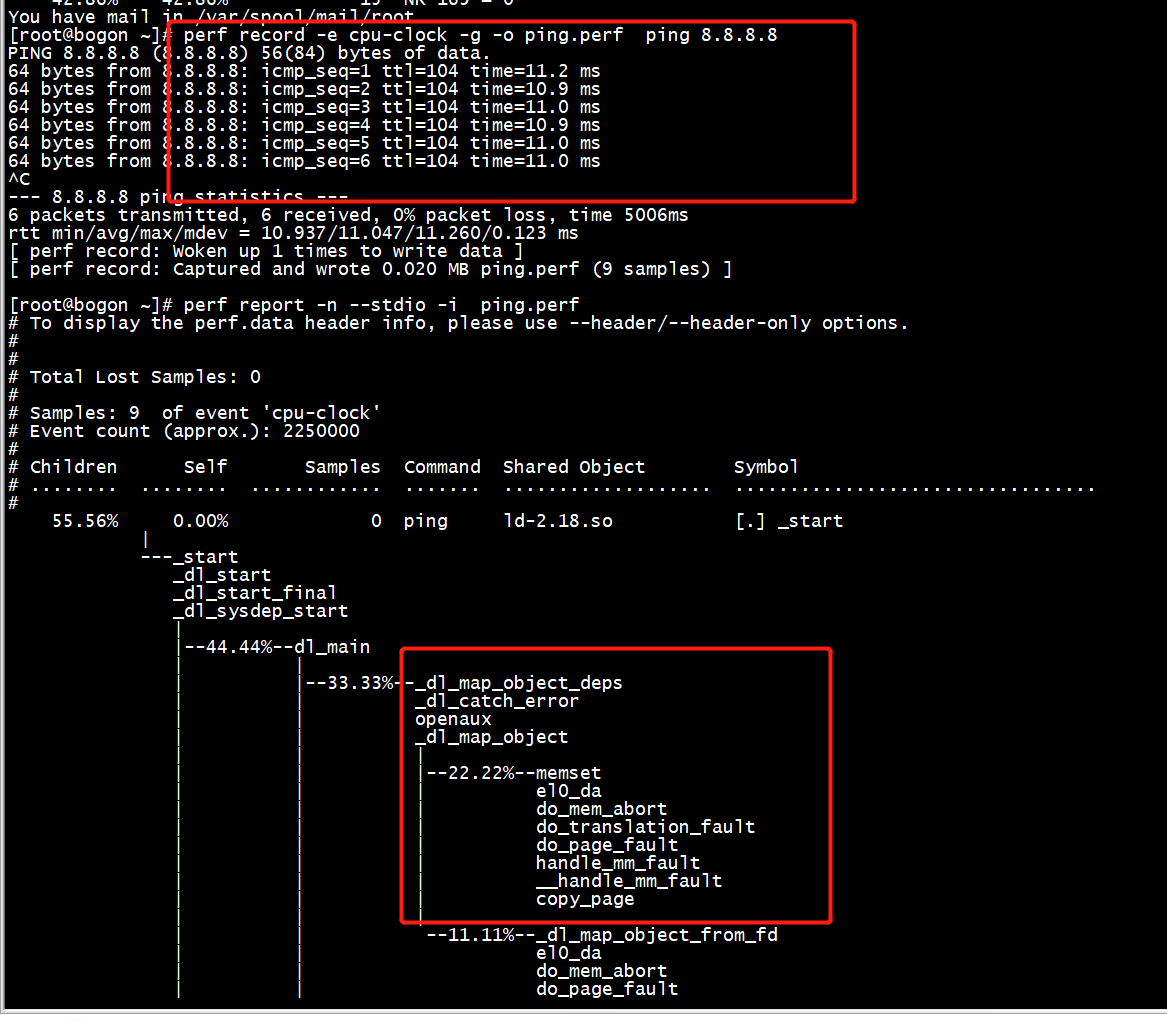
perf record -e cpu-clock -g -o ping.perf ping 8.8.8.8
-g选项是告诉perf record额外记录函数的调用关系,因为原本perf record记录大都是库函数,直接看库函数,大多数情况下,你的代码肯定没有标准库的性能好对吧?除非是针对产品进行特定优化,所以就需要知道是哪些函数频繁调用这些库函数,通过减少不必要的调用次数来提升性能
-e cpu-clock 指perf record监控的指标为cpu周期
perf report -i ping.perf
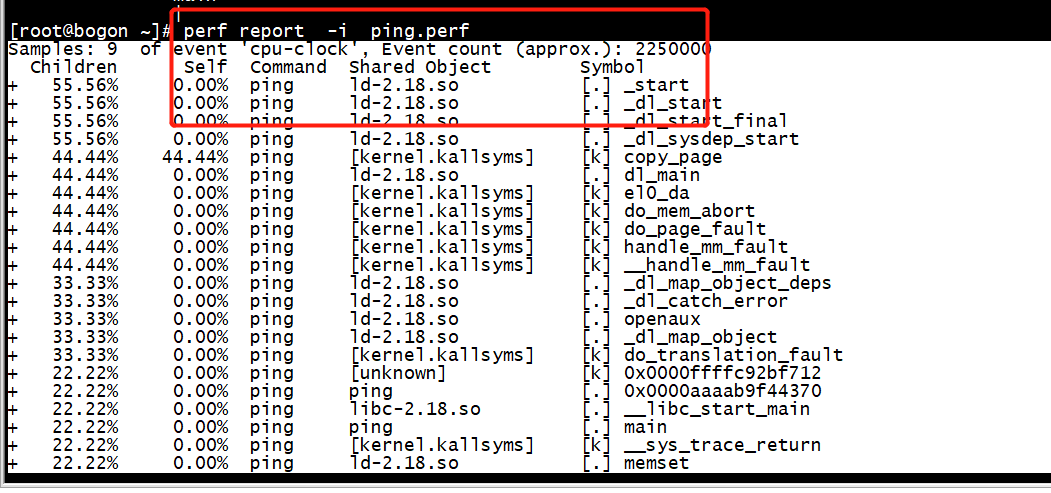
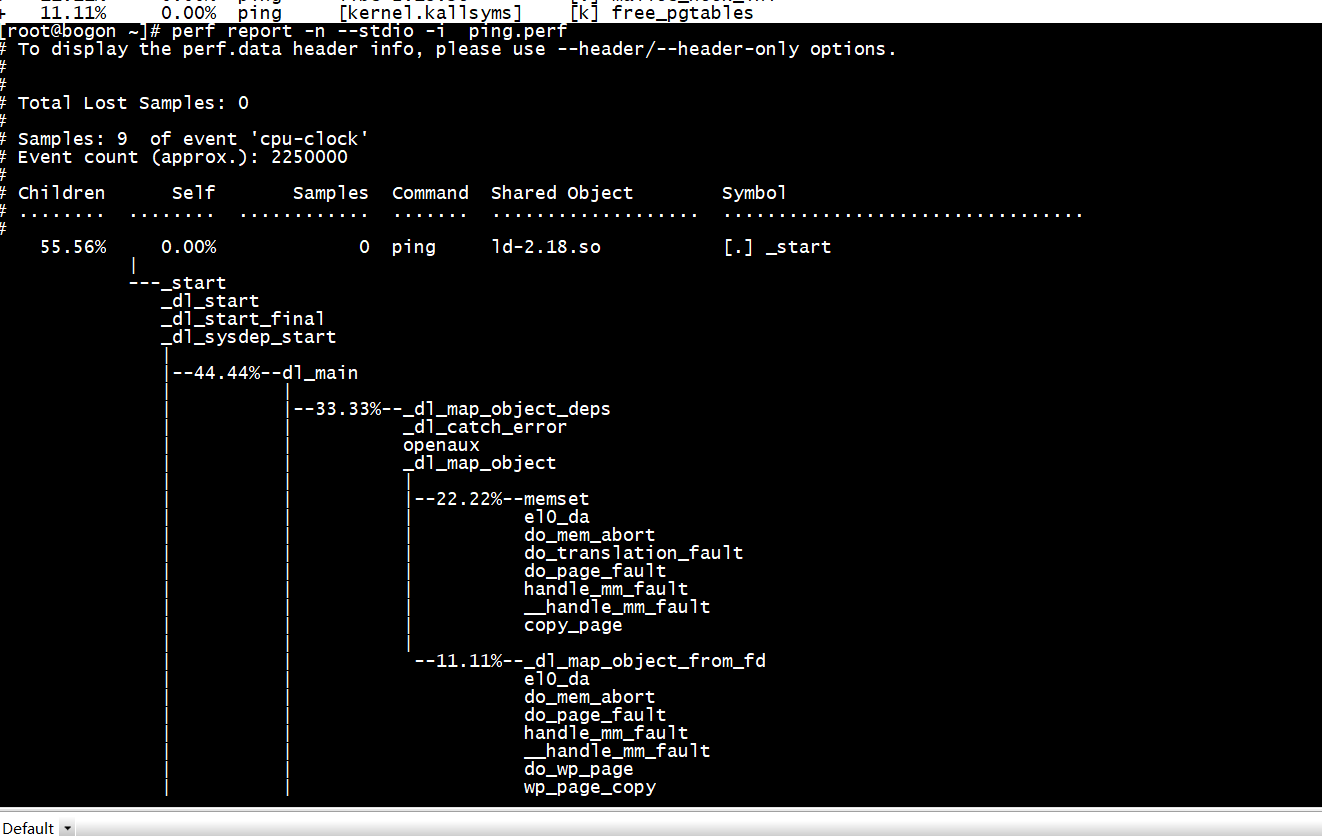
perf report -n --stdio -i ping.perf
perf record -a -g dd if=/data1/ -centos-arm64.iso of=/dev/null
[root@bogon ~]# perf stat -e context-switches ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=106 time=12.0 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=106 time=12.1 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=106 time=11.8 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=106 time=11.6 ms 64 bytes from 8.8.8.8: icmp_seq=5 ttl=106 time=11.7 ms ^C --- 8.8.8.8 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 11.645/11.870/12.121/0.211 ms Performance counter stats for 'ping 8.8.8.8': 10 context-switches 4.704210796 seconds time elapsed 0.000000000 seconds user 0.002517000 seconds sys [root@bogon ~]#
perf诊断ksoftirqd
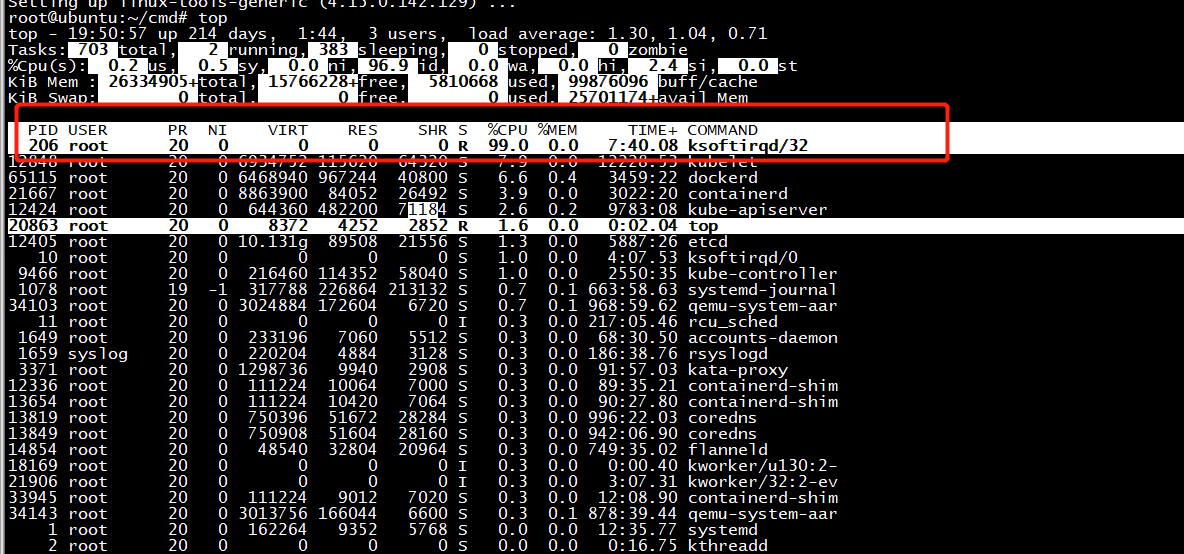
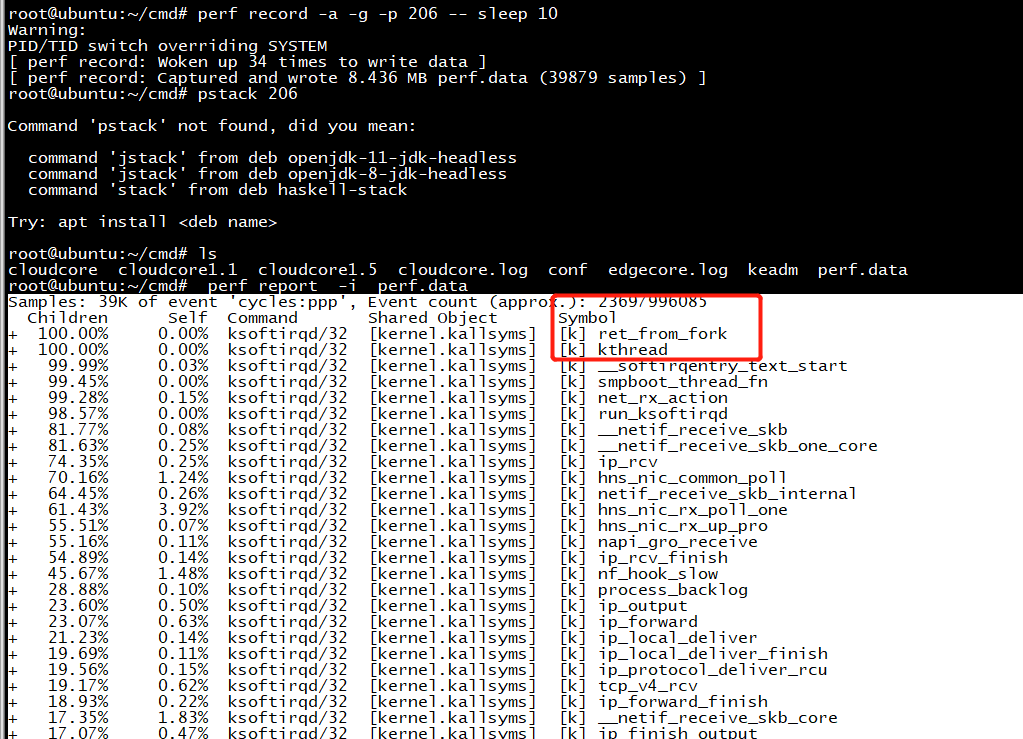
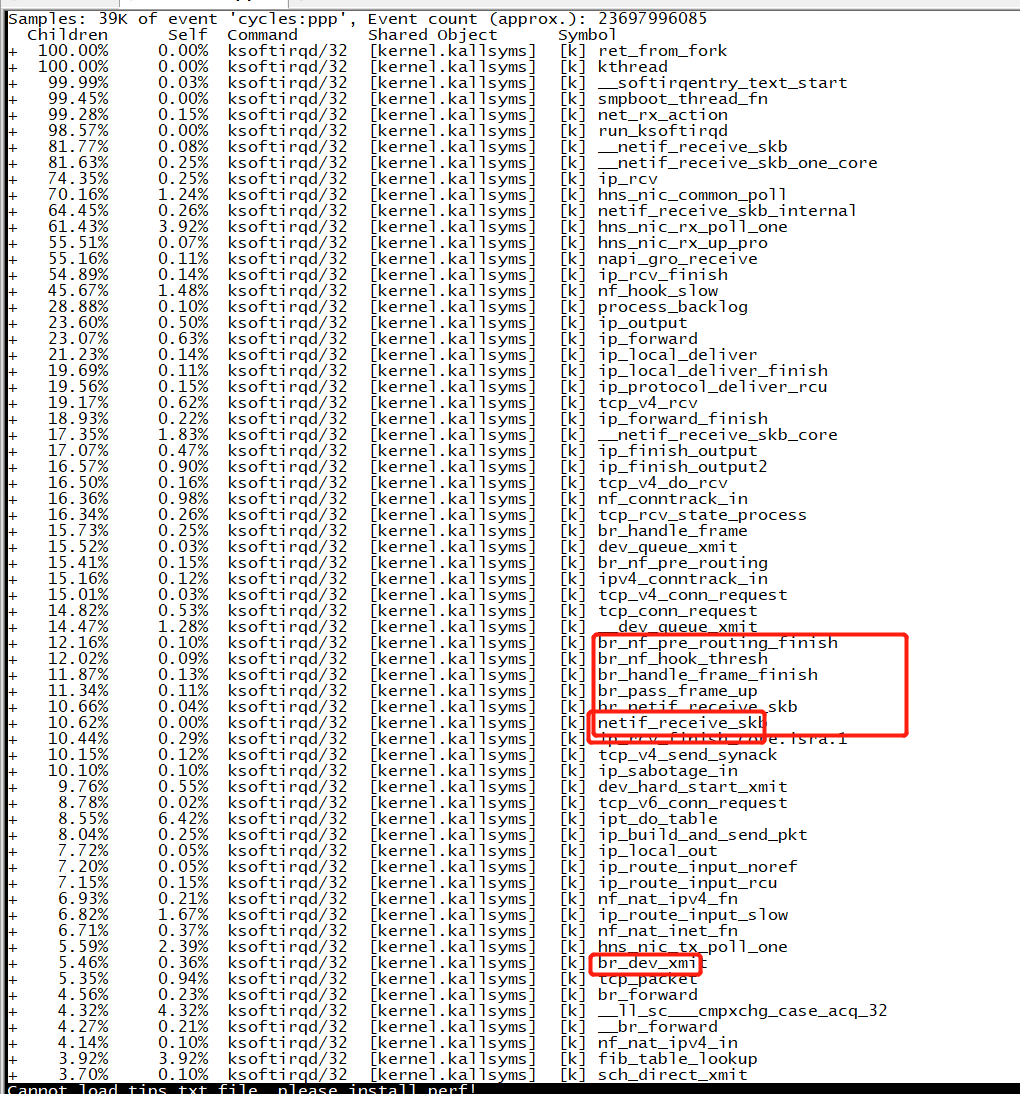
热点代码分析
perf record -g --call-graph=dwarf -F 99 -p 12424
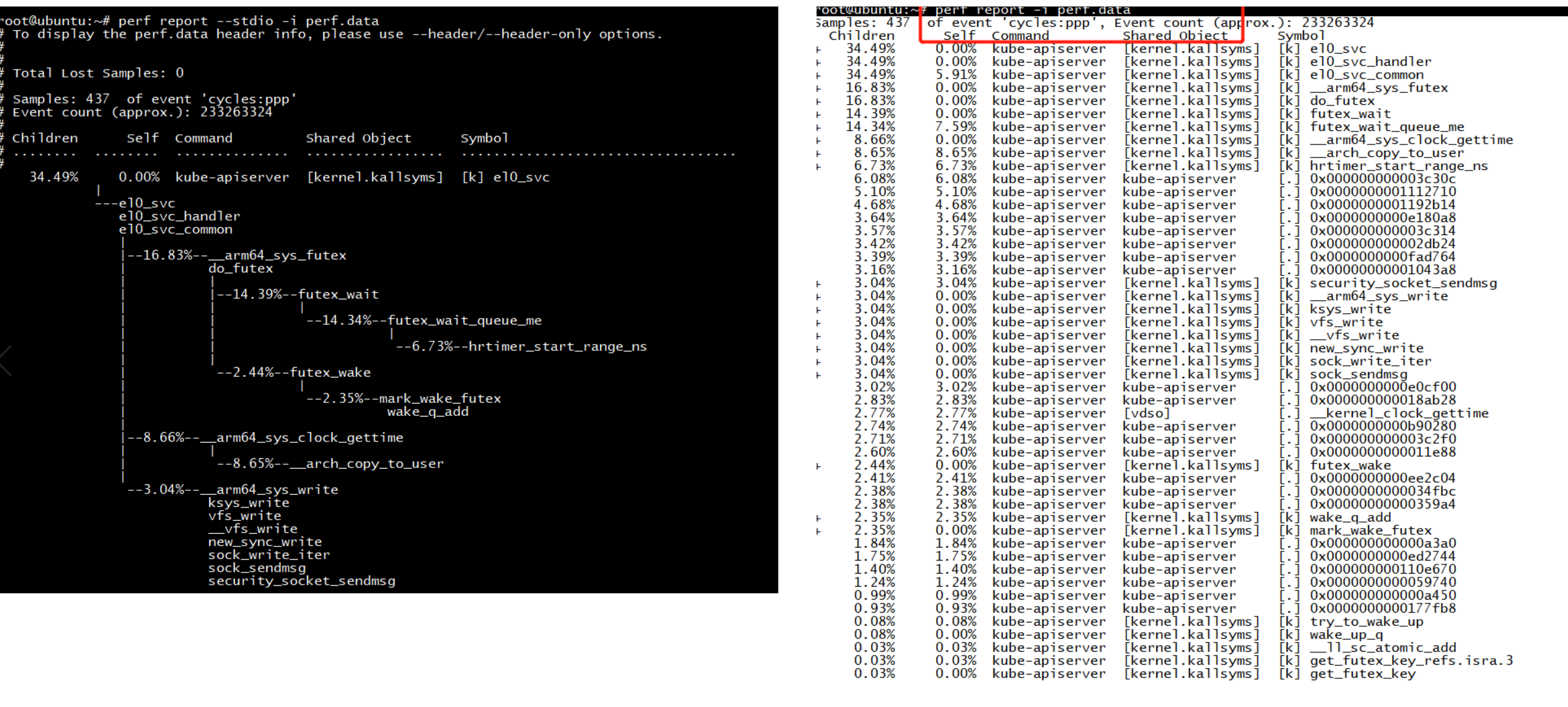
perf report -i perf.data vs perf report --stdio -i perf.data
代码展开
>perf report // 可以看到每个函数的耗时,看不到堆栈
或
> perf report -g // 详细
// 报告中可以使用方向键和enter键查询展开,或者使用如下方式自动全部展开
> perf report -g >1.txt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号