基于智能网卡(Smart Nic)的Open vSwitch卸载方案简介
一、Smart Nic简介
1.1 Smart Nic产生的背景
目前,以Open vSwitch(OVS)为代表的虚拟交换机(vSwitch)以其灵活而丰富的功能支持(如OpenFlow、QOS、VLAN/VXLAN encap/decap)被业界广泛接受,大量应用于云计算多租户场景以及容器场景中。广泛的业务层需求致使数据中心快速增长,数据流量日益激增,vSwitch的收发包瓶颈也日益凸显出来,虽然可以通过软件加速套件(例如dpdk),在一定程度上增强转发性能,但是仍存在以下几个问题:
首先,vSwitch会大量占用宿主机计算资源,尤其是当吞吐增大时,为保证转发质量,vSwitch通常会绑定多个CPU核,这会额外占用大量宝贵的CPU资源,无形之中增加了企业运行成本和能源消耗,这些CPU资源原本可以在其它业务和应用中进行更合理的利用。
其次,虽然可以通过CPU Affinity以及IRQ Affinity等优化手段提高转发性能,但是vSwitch依然面临着性能上的瓶颈,难以满足当前快速增长的高网络带宽应用需求。因此,进一步加速vSwitch势在必行。
最后,业务/应用需求和软件实现上的矛盾,促成了Smart Nic的出现,以Smart Nic为代表的硬件卸载(Hardware Offload)方案被提出并得以广泛推进。
Smart Nic技术诞生的初衷是以比普通CPU低得多的成本来实现对各种虚拟化功能的支持,如sriov,overlay encap/decap,以及部分vSwitch处理逻辑的offload。而且,Hardware Acceleration方案具有天生的处理速度快、性能稳定等优势。除此之外,网卡作为数据流进出的首道关卡,还可以实现监控、嗅探、以避免网络攻击、实现安全隔离的作用。
1.2 Smart Nic和Normal Nic区别
相比于Normal Nic,Smart Nic在很多方面做了改进,例如:
1. Hardware Offload/Acceleration功能
-
区别于Normal Nic,Smart Nic不仅负责L2转发,通过增加额外的处理逻辑还可以实现部分vSwitch的功能。基于Hardware Offload,能够offload部分网络流量(例如基于Tc Flower Offload功能),以及支持对网络数据包header的处理(例如Push/Pop VLAN Tag、VXLAN Encap/Decap等),减小CPU负载,提高网络吞吐;
-
Connection Tracking Offload可以实现L3/L4 Firewall功能;
-
Header Re-write Offload功能,能够对packet header进行set/copy/add操作,可以实现routing、nat等功能;
2. 可编程功能
Smart Nic具备可编程能力,除了实现高性能网络转发以后,还可以实现诸如流表规则匹配,封包过滤,NVMe等功能。表1列出了Smart Nic部分功能的使用场景,以及控制平面/数据平面的功能分工[2]。

表1. Smart Nic部分功能使用场景
1.3 Smart Nic架构
目前几种主流的Smart Nic架构各不相同,大致可以分为ASIC Based、FPGA Based、以及SOC Based三种类型。下图1从性能价格比、操作难易程度、灵活性等几个方面对这三种硬件架构做了简单比较[1]。从图中可以看出,ASIC架构Smart Nic(例如mallanox connectX-5系列)成本低廉且性能优异,这种类型的Smart Nic一般都有可编程接口,但由于处理逻辑在ASIC上固化,控制的灵活空间会比较小;与之相比,基于FPGA的Smart Nic(例如napath NT100E3-1-PTP系列)灵活性则更高,但是成本略高并且编程难度较大;SOC架构(即含有专用CPU,例如mellanox BlueField系列)提供了性能和可操控性的平衡,使用这种架构的一般是各大厂商的自研网卡。
目前,在解决传统的vSwitch性能瓶颈方面,业界还没有一个非常完美的Smart Nic方案,各个方案的实现也是各有千秋,并没有形成一个统一的方案。比如,AWS采用基于通用ARM的方案、Azure采用基于FPGA的方案、华为云采用基于专用网络处理器(NP)的方案、阿里云采用基于可编程ASIC芯片的方案等。
图1. Smart Nic不同架构对比

二、基于Smart Nic的OVS卸载方案
2.1 virtio纯软转发的方案
阿里云曾经提出过一个virtio纯软转发的方案。阿里云针对自身业务自主开发的AVS项目(和OVS有类似功能)在使用过程中,遇到了诸如AVS占用主机资源过多、业务需求导致的性能瓶颈等问题,也因此催生了Smart Nic项目,方案如下图2所示。结合了SRIOV和virtio的优劣,设计了一套基于纯软转发的方案[3,4]。
图2所示是阿里云的Smart Nic设计框架,卡上有一个标准的网卡ASIC和片上系统,片上系统自带内存和CPU,AVS模块整体offload到Smart Nic中。将快速路径(fast-path)和慢速路径(slow-path)进行分离,fast-path offload到ASIC中,AVS自身只负责slow-path包转发。
同时,阿里云结合自己的业务需求,在上层开发了一个基于DPDK的软件转发程序,AVS在网卡完成所有的策略、逻辑、路由、多队列等功能,将SRIOV的VF设备和virtio-net驱动接口进行一一映射,DPDK软件转发程序只需要完成VF和virtio-net的接口转换和报文传递。
该方案具有性能好、不占用主机资源、接口通用以及热迁移方便等优点,已经在阿里云上有了广泛的应用。

图2. 阿里云Smart Nic方案
2.2 基于代表口映射的方案
采用基于代表口映射方案的是Mellanox厂商,其生产的mellanox connectX系列网卡以高带宽、低延时、高性价比等著称。Mellanox提供的Smart Nic方案[5],如下图3 (a)所示,采用了embeded switch(eSwitch),将OVS的数据面offload到网卡中,控制面保持不变,以提供简便灵活的控制。
从图3(b)所示的数据包传输路径可知,普通OVS在做包转发处理时,首先在kernel space进行查表,如果lookup miss,则会发送netlink upcall信息到user space进行后续的查找(紫色线所示);user space查表,lookup hit以后,会将查表命中的flow table entry下发到kernel space进行缓存,以便后续报文在kernel space能直接hit,从而完成直接转发(黄色线所示),采用这种flow cache技术,能够减少频繁的内核态和用户态进程交互产生的性能开销,提高转发性能,进而提高吞吐;采用eSwitch这种ovs offload方案后,能够进一步优化转发性能,进一步缩短数据包的传输路径,当流缓存到网卡后,后续报文的解析、流表查找和转发等则会直接在网卡内部完成。值得注意的是,Mellanox的这种方案实现的是ovs的fastpath offload,而非full datapath offload。

图3. Mellanox Smart Nic方案
(a)基于eSwitch offload方案(b)OVS转发逻辑示意图
Mellanox Smart Nic提供了基于SRIOV的加速方案以及基于virtio的DPDK加速方案,后者现在尚未发布,预计2019年年末发布。图4是Mellanox 基于SRIOV的加速方案,可以看出,在SRIOV环境下,vf设备直接透传给vm使用,同时,vf设备建立起和rep代表口的一一映射关系(由Smart Nic实现完成),宿主机OVS需要配置hw-offload=true,打开hardware offload功能,以便OVS能够将内部流表通过TC下发到网卡内部的eSwitch,配置完成后,可以使用和普通OVS场景一样的方式,添加网桥,添加端口(rep代表口)到网桥上,对应的流表会下发到网卡内部,这样虚机之间的流量通信就可以在网卡内部完成,而不需要经过vSwitch的处理逻辑,减小了系统资源占用,同时相比传统的SRIOV场景,增添了更为丰富的控制功能。
图4. Mellanox SRIOV加速方案

三、基于Mellanox ConnectX-5 Smart Nic实践
3.1前置条件
-
Linux Kernel >= 4.13
-
Open vSwitch >= 2.8
-
Iproute >= 4.12
-
Mellanox ConnectX-5 Smart Nic
-
Mellanox ConnectX-5 FirmWare >= 16.21.0338
-
Mellanox Driver(based on the kernel version)
3.2 创建VF
-
使能SRIOV && VT-d,grub配置文添加内核参数intel_iommu=on;
-
创建VF口(假设网卡名为enp6s0f0);
# echo 0 > /sys/class/net/enp6s0f0/device/sriov_numvfs
# echo 2 > /sys/class/net/ enp6s0f0/device/sriov_numvfs
-
验证检查创建的VF口(假设生成的VF口分别为enp6s0f0_0和enp6s0f0_1);
# cat /sys/class/net/ enp6s0f0/device/sriov_totalvfs
# ip link show enp6s0f0
// 如果网卡或者创建VF口状态为down,则需要设置为up状态
# ip link set dev enp6s0f0 up
# ip link set dev enp6s0f0_0 up
# ip link set dev enp6s0f0_1 up3.3 配置Open vSwitch
-
将PF设备的eswitch模式从legacy更改为switchdev(假设pci号为04:00.0);
# echo switchdev > /sys/class/net/enp6s0f0/compat/devlink/mode
或者使用devlink工具,如下
# devlink dev switch set pci/0000:04:00.0 mode switchdev
-
Unbind VF(假设pci号分别为04:00.1,04:00.2);
# echo 0000:04:00.1 > /sys/bus/pci/drivers/mlx5_core/unbind
# echo 0000:04:00.2 > /sys/bus/pci/drivers/mlx5_core/unbind-
使能网卡的Hardware Offload功能;
# ethtool -K enp6s0f0 hw-tc-offload on
-
使能Open vSwitch的Hardware Offload功能;
# systemctl start openvswitch
# ovs-vsctl set Open_vSwitch . other_config:hw-offload=true
# systemctl restart openvswitch-
配置Open vSwitch;
# ovs-vsctl add-br ovs-sriov
# ovs-vsctl add-port ovs-sriov enp6s0f0
# ovs-vsctl add-port ovs-sriov enp6s0f0_0
# ovs-vsctl add-port ovs-sriov enp6s0f0_1
# ovs-dpctl show-
Openstack环境下创建port时,注意需要传入capability:switchdev参数;
# openstack port create --network net_1 --vnic-tpye=direct --binding-profile '{"capabilities":{"switchdev"}}' sriov_port1
# openstack port create --network net_1 --vnic-tpye=direct --binding-profile '{"capabilities":{"switchdev"}}' sriov_port2-
创建vm1和vm2,分别选定sriov_port1和sriov_port2,然后ping;
vm1# ping vm2
-
在rep口tcpdump抓取vm之间的icmp报文,如图5所示,只能抓到第一笔ping包以及arp request/reply包(vm1持续ping vm2,后续ping包和arp包都会经过网卡转发,rep口就抓不到包了),这说明后续虚机之间的流量offload到了网卡,在网卡中实现了转发,而不再经由OVS进行转发;

图5. 同节点虚机互ping时Representor口抓包结果
-
查看流表转发规则:可以看到已经offload到网卡上的流表;
# ovs-dpctl dump-flows type=offloaded
可以看到类似如下图6所示的输出结果:

图6. Offload到网卡上的流表示例
3.4 测试结果
下图是采用iperf跨节点打流测试获取的实验数据,分别对如下三种实验场景进行了测试:
-
传统SRIOV场景(即下图的legacy sriov),对应使用的是传统10G网卡;
-
开启Hardware Offload(fastpath offload)功能的Mellanox CX-5 25G网卡实验场景(为了进行对比测试,将interface speed配置为10G),其中又分为两类:
-
没有安全组的hardware offload场景(即下图的fastpath offload without sg),对应是传统sriov场景;
-
包含安全组的hardware offload场景(即下图的fastpath offload with sg),带有安全组的这种场景,包含了一些控制流,需要使用ovs的conntrack功能。
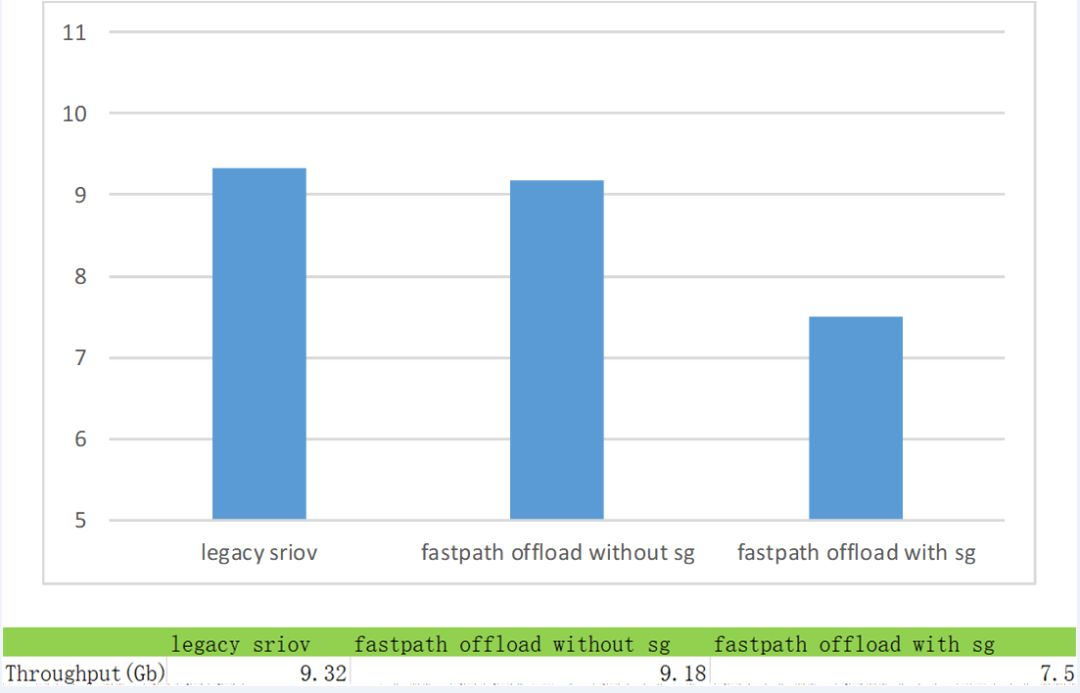
图6. 实验对比图
通过上图6的实验对比图可以看到,不带sg的fastpath offload场景下,网络吞吐为9.18Gbps,和传统的SRIOV场景(吞吐为9.32Gbps)相比,基本持平,这是因为Mellanox的这种方案是基于SRIOV加速的,因此转发速率逼近传统SRIOV场景下的性能,并没有较大的性能损耗;而带有sg的fastpath offload场景下,网络吞吐只达到7.5Gbps,性能出现了较大的下降,是因为Mellanox CX-5网卡在基于SRIOV加速的场景下,不支持ct_state,导致涉及到ct操作带有ct_state匹配字段的流表均不能通过TC下发到网卡中,这时仍然需要在内核态完成这些操作,也因此出现了性能较大损耗的问题。
传统的SRIOV场景,虚机流量经网卡转发,虽然传输路径短,转发性能很高,但是流量控制基本上脱离主机,无法进行控制;Mellanox CX-5网卡基于SRIOV加速流量转发,可以通过conntrack实现流量的控制,进而实现安全组功能,但是目前由于功能上的不完善,导致在开启安全组时,网络转发性能降低,网络吞吐下降。
由此也可以看出,Mellanox Smart Nic的Hardware Offload功能虽然很强大,但是仍然有一些不完善的地方,后续仍需要持续开展软硬件协同,以及进一步的对接和优化工作。
四、Smart Nic应用前景
当前,随着众多业务和应用上需求导致的数据流量激增,对虚拟网络性能的提高变得日益迫切。传统的一些虚拟交换技术难以满足当前快速增长的高网络带宽应用需求,Smart Nic能够实现众多的Hardware Offload功能,为CPU“减负”,释放宝贵的CPU资源,大大提高网络和应用性能,对网络虚拟化应用的性能有很大影响。
目前业内主流厂商都已经进行了Smart Nic的相关研发,有些Smart Nic方案也已经应用到了实际项目中。但是,各个厂商使用的Smart Nic 架构和方案不尽相同,Smart Nic方案目前也比较多,各个方案的实现各有利弊,并没有形成一个统一的方案。我们应用Smart Nic助力网络转型升级,更好地满足公有云、私有云业务需求。
五、参考链接
1. http://www.mellanox.com/blog/2018/08/defining-smartnic/
2. http://www.mellanox.com/blog/2018/09/why-you-need-smart-nic-use-cases/
3. https://yq.aliyun.com/articles/604505
4.https://static.sched.com/hosted_files/lc32018/57/Zero-Copy%20Optimization%20for%20DPDK%20vhost-user%20Receiving_Jing%20Chen.pdf
5. http://www.mellanox.com/blog/2018/09/why-you-need-smart-nic-use-cases/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号