为容器提供更好的隔离:沙箱容器技术概览
原文:Making Containers More Isolated: An Overview of Sandboxed Container Technologies
摘要
既然主流 IT 工业都在采用基于容器的基础设施(云原生方案),那么了解这一技术的短板就很重要了。Docker、LXC 以及 RKT 等传统容器都是共享主机操作系统核心的,因此不能称之为真正的沙箱。这些技术的资源利用率很高,但是受攻击面积和潜在的攻击影响都很大,在多租户的云环境中,不同客户的容器会被同样的进行编排,这种威胁就尤其明显。主机操作系统在为每个容器创建虚拟的用户空间时,不同容器之间的隔离是很薄弱的,这是造成上述问题的根本原因。基于这样的现状,真正的沙箱式容器,成为很多研发工作的焦点。多数方案都对容器之间的边界进行了重新架构,以增强隔离。本文覆盖了四个项目,分别来自于 IBM、Google、Amazon 以及 OpenStack,几个方案的目标是一致的:为容器提供更强的隔离。IBM Nabla 在 Unikernel 的基础上构建容器;Google 的 gVisor 为运行的容器创建一个特定的内核;Amazon 的 Firecracker 是一个超轻量级的沙箱应用管理程序;OpenStack 将容器置入特定的为容器编排平台优化的虚拟机之中。下面对几个方案的概述,有助于读者应对即将到来的转型机会。
目前的容器技术
容器是一种对应用进行打包、分享和部署的现代化方式。与把所有功能打包为单一软件的单体应用相反,容器化应用或微服务的设计目标是专注于单一任务。容器中包含要完成这一任务所需的所有依赖项目(包、库和一些二进制文件)。正因如此,容器化应用是平台无关的,能够在任何操作系统上运行,并不在意其版本或者已部署软件。这给开发人员带来了极大的方便,再也不用为不同的客户和平台准备不同版本的软件了。因此也有了一个不太准确的想法:把容器当成了“轻量级虚拟机”。当容器在主机上完成部署之后,每个容器的资源,例如文件系统、进程和网络栈都会被安置在一个虚拟的隔离环境之中,其它容器无法访问这一隔离环境。这个技术能够在一个集群内同时运行几百或几千个容器,容器化应用能够轻松的通过复制容器实例的方式进行伸缩。
目前容器技术的发展,得益于两项技术的进步:Linux 命名空间以及 Linux Control Group(cgroup)。命名空间虚拟隔离的用户空间,并且给应用分配独立的系统资源,例如文件系统、网络栈、进程号以及用户编号等。在这个隔离的用户空间中,PID = 1 的应用程序控制了文件系统的根,并可以用 root 的身份运行。这个抽象的用户空间允许每个应用都不受同一主机上运行的其它应用的影响。目前有六个可用的命名空间:mount、inter-process communication (ipc)、UNIX time-sharing system (uts)、process id (pid)、network 以及 user。另外还提议了两个额外的命名空间,分别是 time 和 syslog,但是 Linux 社区还在对其规范进行定义。Cgroups 为应用进行硬件的限制、优先级、审计和控制。CPU、内存、设备和网络都是硬件资源。当把命名空间和 cgroup 组合起来,我们就可以在单一主机上,安全的运行多个应用,并且其中的每个应用都有各自的隔离环境,这是容器的的根本。
虚拟机和容器之间的区别是,虚拟机是硬件层的虚拟化,而容器是操作系统级的。虚拟机管理器(VMM)为每个虚拟机模拟一个硬件环境,容器运行时则为每个容器模拟一个操作系统。虚拟机共享主机的物理硬件,容器会共享主机操作系统的内核以及物理硬件。因为容器从主机上共享的资源更多,它们对存储、内存以及 CPU 的利用比虚拟机更加有效。然而共享越多,其代价就是容器之间、容器和主机之间的信任边界就越模糊。图 1 中描述了虚拟机和容器的架构差异。
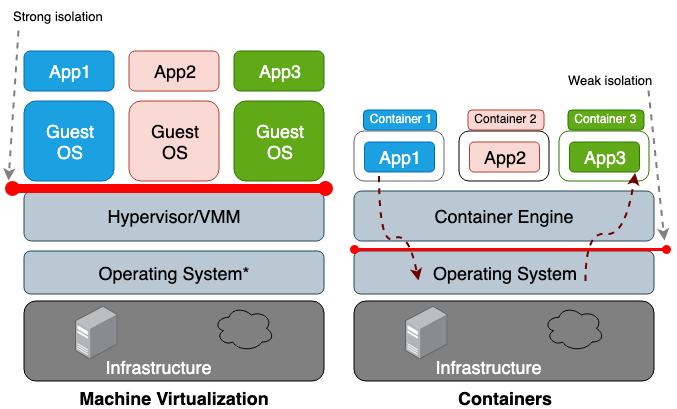
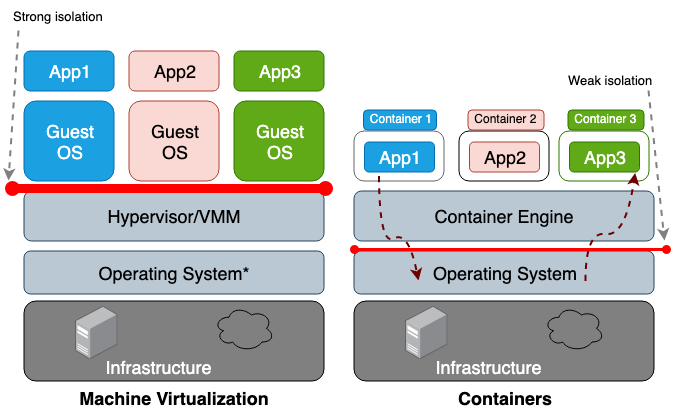
相对于命名空间隔离技术而言,虚拟化硬件隔离通常会有更好的安全边界。容器(进程)中逃出的攻击者,往往比虚拟机中逃出的攻击者具有更大的威胁。命名空间和 cgroup 的弱隔离是造成这种风险的原因。Linux 为每个进程中加入新的属性字段,通过这种方式实现了命名空间和 cgroup。这些在 /proc 文件系统中的字段会告诉主机操作系统,一个进程是否能看到其它进程,或者这个进程能够使用的 CPU 或内存的预算。如果从主机操作系统上查看运行中的进程和线程(例如 top 和 ps 命令),容器进程看起来和主机上的其它进程都是很相似的。一般来说 LXC 或者 Docker 这样的传统容器,在同一主机上运行时,会共享统一主机的同一内核,因此不能称其为沙箱。例如 CVE-2014-3519、CVE-2016-5195、CVE-2016-9962、CVE-2017-5123 以及 CVE-2019-5736,都会从容器中越狱而出。多数内核漏洞都适用于容器逃逸,这是因为内核漏洞通常会导致权限升级,最终允许受攻击的进程在原命名空间之外获得控制权。除了经由软件漏洞进行的攻击之外,错误的配置,例如部署一个具备过高权限(例如 CAP_SYS_ADMIN、privileged)的容器,或者关键挂载点(例如 /var/run/docker.sock)都可能引发容器逃逸。想在多租户集群中部署容器、或者把包含有敏感数据的容器和其它不受信容器部署在同一主机上,就要考虑一下发生灾难性后果的可能性了。
这些安全性方面的担忧,促使研究人员为容器构建了更强的信任边界。具体的解决方式就是创建一个真正的沙箱容器,尽可能的从主机操作系统中隔离开来。多数解决方案都是一种混合架构,在虚拟机的强信任边界和容器的高效率之间尝试取得平衡。在成文之时,还没有任何一个项目成熟到能够成为标准,但未来的容器发展毫无疑问地会采纳其中一些有用的概念。本文的剩余部分会讨论几个有前途的项目,并对它们的特点进行比较。
我们会从 Unikernel 开始,它是最早的一个单一目标虚拟机的尝试,它把应用和最小化的操作系统库打包成为单一镜像。很多致力于创建安全、低耗的最优化虚拟机镜像的未来项目,都以 Unikernel 的概念为基础。然后我们会看看 IBM 的 Nabla,这个项目的目标是像容器一样的运行 Unikernel 应用;接下来是 Google gVisor,它在用户空间的内核中运行容器。在这两个类 Unikernel 项目之后,我们把目光转向以虚拟机为基础的容器方案,Amazon 的 Firecracker 以及 OpenStack Kata。最后一节的结论中,会对所有的方案进行比较。
Unikernel
虚拟化技术让云计算成为可能。Xen 以及 KVM 这样的 VMM 是 AWS 和 GCP 的基石之一。虽然现代 VMM 能在单一集群内处理几百个虚拟机,然而传统的通用操作系统构建出来的虚拟机通常没有为在虚拟化环境中的运行进行优化。通用操作系统的设计目标是尽可能支持更多类型的应用程序,所以它的核心会包含所有类型的驱动、协议以及调度器。然而当前云中运行的虚拟机通常是被单一应用独占的,例如 DNS、代理服务器或者数据库。每个应用都只依赖于一小部分内核功能,闲置的内核功能不但浪费了系统资源,还扩大了攻击面积。更多的代码,就要面对更多的安全和隐患和 Bug。这种现状促使计算机科学家们用最小化的内核功能来支持单一应用,从而设计出了单一用途的操作系统。
操作系统研究者们在 90 年代提出了 Unikernel 的概念。Unikernel 是一个特别的单寻址空间的虚拟机镜像,能够直接运行在 VMM 上。它把应用程序及其依赖的内核功能打包到一个镜像之中。 Nemesis和 Exokernel 是 Unikernel 最早的两个学术项目。图 2 描述了 Unikernel 虚拟机镜像创建和部署的过程。

Unikernel 把内核拆分为多个库,只将应用依赖的库打包到镜像里。跟虚拟机类似,Unikernel 在虚拟机 VMM 上工作。低耗的 Unikernel 能够快速的启动和扩容。Unikernel 的突出特点就是安全、低耗、高度优化和快速启动。Unikernel 镜像只包含应用依赖的库,如果不做特别要求,其中甚至连 Shell 都没有,这就减小了受攻击面积。不但是攻击者缺乏落脚点,就算是有定制失误的镜像,其影响范围也只在它自己的实例之中。Unikernel 镜像只有几兆,因此能在几十毫秒内完成启动,还可以在单一主机上运行几百个实例。用单一寻址空间代替多数现代操作系统中使用的多级页表,Unikernel 应用的内存访问延迟比虚拟机中更低。由于应用是在构建镜像时进行编译的,编译器能够进行更多的静态类型检查,从而优化二进制文件的效率。
Unikernel.org 维护了一个 Unikernel 项目的列表。即便是具有这样鲜明的特点,Unikernel 还是没有获得太多关注。Docker 2016 年收购了一家 Unikernel 的初创公司,大家认为 Docker 可能要把容器打包到 Unikernel 里面。三年后,还是没有出现任何集成的迹象。进展缓慢的重要原因之一就是,还没有成熟的构建 Unikernel 应用的成熟工具,大多数 Unikernel 应用只能在特定 VMM 中运行。另外要把应用移植到 Unikernel 上,可能需要针对不同语言进行定制,并且手动选择依赖的内核库。Unikernel 中的监控和排错即使能做得到,也会对性能造成很大影响。所有这些限制,都降低了开发者向 Unikernel 迁移的意愿。容器和 Unikernel 有很多相似之处。它们都是单一用途的只读镜像,意味着镜像中的组件无法更新或补丁,要更新应用就必须更新镜像。今天的 Unikernel 有点像前 Docker 时代:没有容器运行时可用,开发者必须使用 chroot、unshare 和 cgroup 等基础工具来把应用放入沙箱。
IBM Nabla
IBM 的研究者们提出了 Unikernel as process 的点子:Unikernel 应用以进程的形式在特定的虚拟机系统中运行。IBM 的 Nabla Containers 项目,用面向 Unikernel 的 Nabla Tender 替换了 QEMU 这样的通用 VMM,进一步强化了 Unikernel 的信任边界。Unikernel 和通用 VMM 之间的 Hypercall 还是一个很大的受攻击面积,所以针对 Unikernel 的 VMM 可以使用更少的系统调用,从而显著的提高安全性。Nabla Tender 拦截 Unikernel 发送给 VMM 的 Hypercall,并翻译为系统调用。Linux Seccomp 策略会阻断所有 Tender 不需要的系统调用。Unikernel 和 Nabla Tender 以用户空间进程的形式在主机上运行。图 3 展示了 Nabla 在 Unikernel 应用和主机之间创建瘦接口的过程。

研究者声称,Nabla Tender 和主机的通信使用了不到 7 个系统调用。由于系统调用是用户空间进程和操作系统内核之间的桥梁,越少的系统调用,就越难攻击到核心。把 Unikernel 运行为进程还有个好处就是使用 gdb 这类基于进程的调试器进行调试。
为了和容器编排平台对接,Nabla 还提供了符合 OCI 运行时标准的 Nabla 运行时 runnc。OCI 运行时标准规范了运行时客户端(例如 Docker 和 Kubelet)以及运行时(例如 Runc)之间的 API。Nabla 还提供了一个镜像构建器,用于创建能够使用 runnc 运行的 Unikernel 镜像。Unikernel 和传统容器的文件系统之间存在差异,因此 Nabla 没有遵循 OCI 的镜像标准,换句话说, Docker 镜像和 runnc 是不兼容的。在本文写作期间,这个项目还在早期试验阶段,还有一些功能缺失,例如加载/访问主机文件系统的能力、加入多网卡的能力(Kubernetes 需要)或者从其它 Unikernel 镜像进行引用的能力。
Google gVisor
Google gVisor 是 GCP App Engine、Cloud Functions 和 CloudML 中使用的沙箱技术。Google 意识到在公有云基础设施中运行不受信容器的风险,以及虚拟机沙箱的低效,因此开发了用户空间的内核作为沙箱来运行不受信应用。gVisor 通过拦截所有从应用到主机内核的系统调用,并使用用户空间中 gVisor 的内核实现来处理这些调用。本质上来说,gVisor 是 VMM 和客户内核的组合,图 4 展示了 gVisor 的架构。

gVisor 在应用和主机之间建立了稳固的安全边界。这个边界限制了应用在用户空间的系统调用。无需依赖虚拟硬件,gVisor 以主机进程的方式运行,充当主机和应用之间的沙箱。哨兵实现了多数的 Linux 系统调用,尤其是内核功能,例如信号分发、内存管理、网络栈以及线程模型。哨兵已经实现了 319 个 Linux 系统调用中的 70% 多,用于为沙箱应用提供支持。哨兵和主机内核的通信只使用了不到 20 个 Linux 系统调用。gVisor 和 Nabla 有很相似的策略:保护主机。它们都使用了不到 10%的系统调用来和主机内核通信。gVisor 创建通用核心,而 Nabla 依赖的是 Unikernel,它们都是在用户空间运行特定的客户内核来支持沙箱应用的运行。
有人可能会奇怪,开源的 Linux 内核已经如此稳定,为什么 gVisor 还要重新实现一个。gVisor 的内核使用的是 Golang,其中的强类型安全以及内存管理都比 C 编写的 Linux 内核更安全。gVisor 的另外一个重要卖点就是它和 Docker、Kubernetes 以及 OCI 标准的紧密集成。把运行时修改为 gVisor runsc,就能拉取和运行大多数的 Docker 镜像了。在 Kubernetes 里,可以把整个 Pod(而非每个容器分别)运行在 gVisor 沙箱中。
gVisor 还在婴儿期,也一样有一些限制。gVisor 要拦截和处理沙箱应用中的系统调用,总要有一定开销,因此不适合系统调用繁重的应用。注意 Nabla 没有这个开销,这是因为 Unikernel 应用不进行系统调用。Nabla 只使用 7 个系统调用来处理 Hypercall。gVisor 没有直接的硬件访问(透传),所以如果应用需要硬件(例如 GPC)访问,就无法在 gVisor 上运行。最后,gVisor 没有实现所有的系统调用,因此使用了未实现系统调用的应用是无法在 gVisor 上运行的。
Amazon Firecracker
Amazon Firecracker 用于 AWS Lambda 和 AWS Fargate。它是一个 VMM,会创建轻量级虚拟机(MicroVM),特别适合多租户容器和无服务器场景。在 Firecracker 出现之前,Lambda 和 Fargate 都在每个客户独立的 EC2 虚拟机上运行,从而保证强隔离。虽然在公有云中,虚拟机的强隔离性要优于容器,但是使用通用的 VMM 和虚拟机来做应用沙箱是很不经济的。Firecracker 为云原生应用定制了 VMM,兼顾了安全和性能两方面问题。Firecracker VMM 为每个客户虚拟机提供了最小操作系统功能,并且模拟设备来增强安全和性能。可以用 Linux 内核以及 ext4 文件系统轻松的构建运行在 Firecracker 之上的虚拟机镜像,Amazon 在 2017 年开始开发 Firecracker,并在 2018 年开源。
和 Unikernel 概念类似,只有一个功能和设备的小子集可以用于容器操作。和传统虚拟机对比,microVM 在受攻击面积、内存消耗和启动时间方面都很有优势。评估表明,Firecracker 的 microVM,运行在 2CPU 和 256G 内存的主机上,消耗不到 5MB 内存,启动大约用了 125ms。图 5 展示了 Firecracker 架构以及它的安全边界。
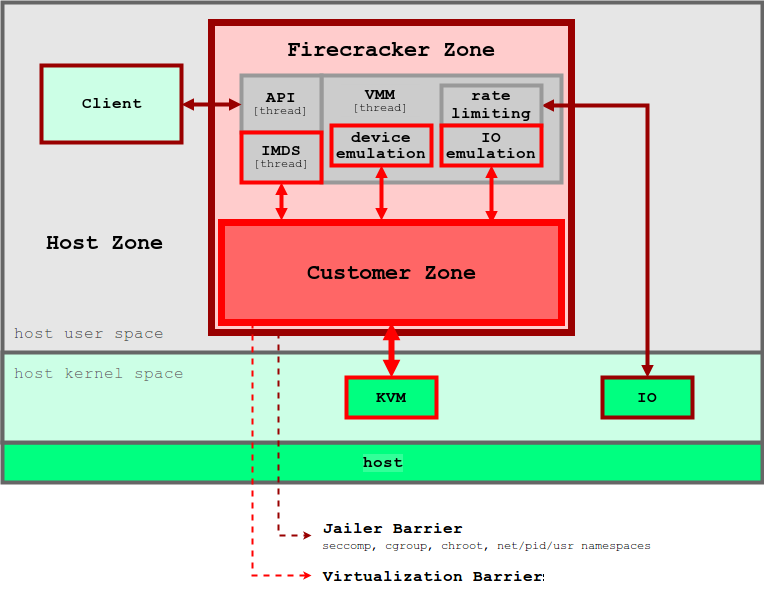
Firecracker VMM 依赖于 KVM,每个 Firecrfacker 实例都以用户空间进程的方式运行。每个 Firecracker 进程都被 seccomp、cgroup 和命名空间策略锁定,因此它的系统调用、硬件资源、文件系统和网络活动都被严格限制。每个 Firecracker 进程中都有多个线程。API 线程作为客户端和主机以及 microVM 之间的控制平面。VMM 线程呈现了一个 virtIO 设备的最小集(网络和块设备)。Firecracker 只提供了 4 个模拟设备给 microVM:virtio-block、virtio-net、串口控制台以及一个用于停止 microVM 的只有一个按钮的键盘。为了安全性考虑,虚拟机不提供和主机分享文件的机制。主机上的数据(例如容器镜像),通过块设备暴露给 microVM。虚拟机的网络接口由网桥上的 TAP 设备提供支持。所有的出栈数据包都会拷贝到 TAP 设备,并受 cgroup 策略的速率限制。安全边界的层次最大程度的降低了用户应用之间互相干扰的可能性。
目前为止,Firecracker 还没有完全和 Docker 以及 Kubernetes 完成集成。Firecracker 不支持硬件透传,所以需要 GPU 以及任何设备加速访问的应用都无法兼容。它限制了虚拟机和主机的文件共享以及网络模型。然而这个项目有强力的社区支持,应该很快会和 OCI 标准打通并支持更多应用。
OpenStack Kata
出于对传统容器安全性的担忧,Intel 在 2015 年启动了它们以虚拟机为基础的容器技术:Clear Container。Clear Container 依赖 Intel VT 的硬件虚拟化技术以及高度定制的 QEMU-KVM(qemu-lite)来提供高性能的基于虚拟机的容器。在 2017 年,Clear container 项目加入了 Hyper RunV,这是一个基于 hypervisor 的 OCI 运行时,从而启动了 Kata 容器项目。继承了 Clear Container 的所有财产,Kata 现在支持更多的基础设施和容器规范。
Kata 完整的集成了 OCI、CRI 以及 CNI,它支持多种网络模型以及可配置的客户内核,这样一些有特别网络需求或者内存版本限制的应用就可以得到支持了,图 6 展示了 Kata 和现有编排平台的交互。
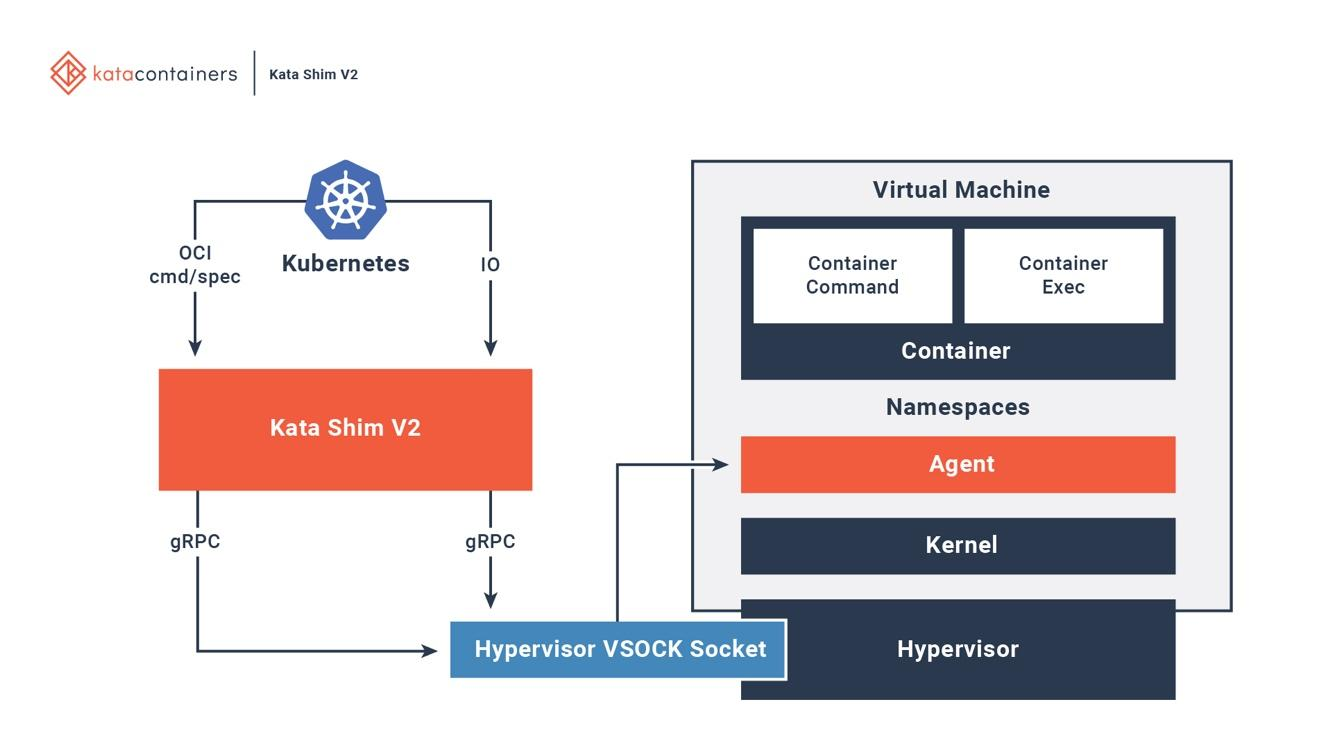
Kata 在主机上有一个 kata-runtime,用于配置新容器。在 Kata VM 中的每个容器,在主机上都有对应的 Kata Shim。Kata Shim 从客户端接收 API 请求(Docker 或 Kubelet),通过 VSock 转发请求到 Kata 虚拟机中的代理。Kata 作出很多优化启动时间的优化。NEMU 是一个轻量级的 QEMU,约有 80% 的设备和包被删除。VM-Templating 克隆一个运行中的 Kata VM 实例,并分享给其它新启动的 Kata VM。这一操作能够显著降低启动时间以及内存消耗,但是可能受到跨虚拟机的边缘通道攻击,例如 CVE-2015-2877。热插拔功能让虚拟机以最小资源启动(例如 CPU、内存、virtio block),并在有申请时加入额外的资源。
Kata 容器和 Firecracker 都是基于虚拟机的沙箱技术,也都是服务于云原生应用的。但是它们用不同的方法来实现目标。Firecarcker 用一个特定的 VMM 来给客户操作系统创建安全的虚拟化环境,而 Kata 是一个为运行容器而高度优化的轻量级虚拟机。有人已经尝试在 Firecracker VMM 上运行 Kata。这个项目还在试验阶段,也许会把两个项目的长处融为一体。
结论
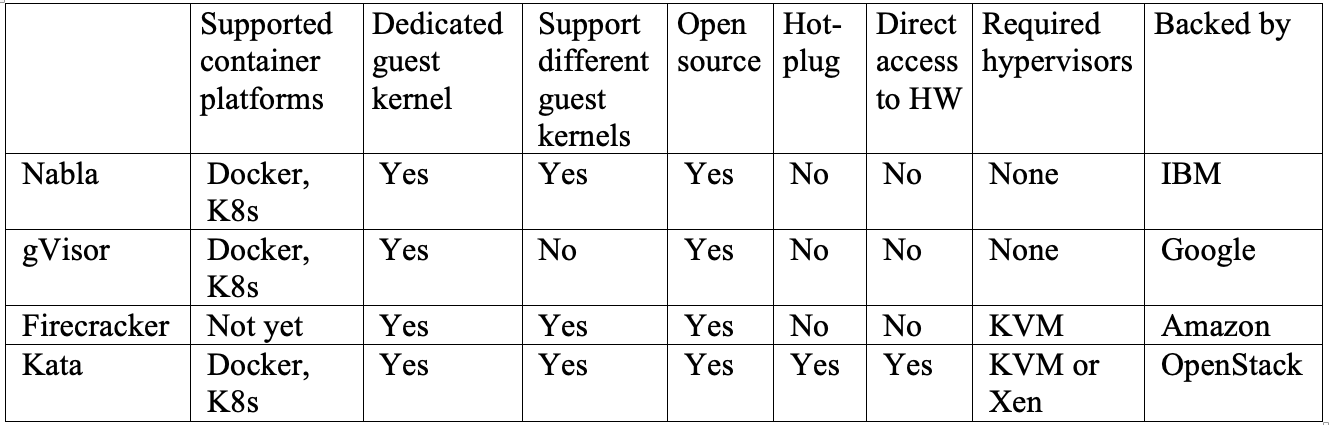
我们已经看了多个用于解决容器隔离问题的方案。IBM Nabla 是一个基于 Unikernel 的方案,把应用打包为特别的虚拟机。Google gVisor 是特制 VMM 和客户操作系统核心的结合,提供了应用和主机之间的安全界面。Amazon Firecracker 是一个特定的 VMM,为每个客户操作系统提供最小化的硬件和内核资源。Kata 是高度优化的虚拟机,内置了容器引擎,可以运行在 VMM 上。这些方案各有优劣,很难说那个更好。表格 1 中展示了一个针对重要功能的对比表。如果你有应用运行在 Unikernel 系统中,例如 MirageOS 或者 IncludeOS,Nabla 是最佳选择。gVisor 是目前和 Docker 和 Kubernetes 集成最好的,但是因为系统调用实现不完整,有些应用可能无法运行。Firecracker 支持自定义的客户操作系统镜像,所以如果你的应用需要在特定虚拟机上运行,它是你的最佳方案。Kata 兼容 OCI,在 KVM 以及 Xen 上都能运行。它可以简单的在混合环境中部署微服务。
虽然可能需要很长时间,才能看到有一个或多个解决方案最终被主流接受,但已经可以看到大多数云厂商已采取行动来解决这些问题。对于构建本地云原生平台的组织而言,它不是世界末日。快速修补、最小权限配置和网络分段等常见做法都可以有效地减少被攻击面。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号