Keepalived+haproxy实现Openstack高可用原理及分析
转载: https://zhuanlan.zhihu.com/p/31600602
高可用OpenStack(Queen版)
https://www.cnblogs.com/netonline/p/9210520.html
openstack-高可用部署
https://www.cnblogs.com/zhaopei123/category/1783683.html
OpenStack HA实现
HA方案基本要求
在通过Haproxy+keepalived实现Openstack HA的方案中,首先应分析Openstack的各类节点的服务。
在Openstack的部署环境中,可以分为以下几类节点:
l 控制节点:安装各种 API 服务和内部工作组件(worker process),同时部署数据库、Rabbit和Memcache的组件
l 网络节点:安装 Neutron L3 Agent,L2 Agent,LBaas,VPNaas,FWaas,Metadata Agent 等 Neutron 组件,在现有的方案中,和控制节点放在了同一台服务器上。
l 存储节点:安装 Cinder volume 以及 Swift 组件,在现有的方案中,和控制节点放在了同一台服务器上。
l 计算节点:安装 Nova-compute 和 Neutron L2 Agent,在该节点上创建虚机。
要实现 OpenStack HA,一个最基本的要求是这些节点都是冗余的。根据每个节点上部署的软件特点和要求,每个节点可以采用不同的 HA 模式。但是,选择 HA 模式有个基本的原则:
1) 能 A/A 尽量 A/A,不能的话则 A/P (RedHat 认为 A/P HA 是 No HA);
2) 有原生(内在实现的)HA方案尽量选用原生方案,若没有则使用HA软件;
3) 需要考虑负载均衡;
4) 方案尽可能简单,不要太复杂;
Openstack服务分类
在openstack的控制节点的服务中,可以分为以下几种:
1) API 服务:包括 *-api, neutron-server,glance-registry, nova-novncproxy,keystone,httpd 等,这些服务均为无状态服务,由 HAProxy 提供负载均衡,将请求按照一定的算法转发。
2) 内部组件:包括 *-scheduler,nova-conductor,nova-cert 等。它们都是无状态的,因此可以在多个节点上部署,它们会使用 HA 的 MQ 和 DB。
3) RabbitMQ:跨三个节点部署 RabbitMQ 集群和镜像消息队列。可以使用 HAProxy 提供负载均衡,或者将 RabbitMQ host list 配置给 OpenStack 组件(使用 rabbit_hosts 和 rabbit_ha_queues 配置项)。
4) MariaDB:跨三个节点部署 Gelera MariaDB 多主复制集群。由 HAProxy 提供负载均衡。
5) HAProxy:向API、RabbitMQ及数据库提供负载均衡服务,一般部署三个节点的Haproxy,并由keepalived提供vip支持。
6) Memcached:它原生支持 A/A,只需要在 OpenStack 中配置它所有节点的名称即可,比如,memcached_servers = controller1:11211,controller2:11211。当 controller1:11211 失效时,OpenStack 组件会自动使用controller2:11211。
Keepalived配置
vrrp_script check_alive {
script "/check_alive.sh"
interval 2
fall 2
rise 10
}
vrrp_instance kolla_internal_vip_121 {
state BACKUP
nopreempt
interface enp8s0f0
virtual_router_id 121
priority 1
advert_int 1
virtual_ipaddress {
172.23.59.10 dev enp8s0f0
}
authentication {
auth_type PASS
auth_pass yw8v4g4hT4hVFWHl35NE1zPsqlg9r2J7Vpw4Mh7T
} track_script {
check_alive
}
}
参数解释:
state:包括MASTER、BACKUP,kolla-ansible中所有节点都使用了BACKUP是为避免MASTER 宕机恢复后抢夺BACKUP的VIP,减少vip在主机间的切换。
interface:keepalived使用的网卡
virtual_router_id:虚拟路由的唯一id,在同一个网段里,不能有两个相同的id。
priority:优先级,数字越大优先级越高
track_script:用以检测状态的脚本,kolla-ansible使用的是check_alive.sh
具体作用是监控haproxy是否还存活,用以决定是否要切换VIP
echo "show info" | socat /var/lib/kola/haproxy/haproxy.sock stdio
socat是连接两个流的管道,本例子就是haproxy.sock和stdio连接起来,两者之间可以 进行信息通信。stdio 把 "show info"发给haproxy.sock 后被haproxy接受处理,返回show info的处理结果,就是显示一些haproxy的信息。用以检测haproxy进程是否还存活着。
Haproxy配置
Haproxy配置中分成五部分内容,当然这些组件不是必选的,可以根据需要选择作为配置。
•global:参数是进程级的,通常和操作系统(OS)相关。这些参数一般只设置一次,如果配置无误,就不需要再次配置进行修改;
•default:配置默认参数的,这些参数可以被利用配置到frontend,backend,listen组件;
•frontend:接收请求的前端虚拟节点,Frontend可以根据规则直接指定具体使用后端的backend(可动态选择);
•backend:后端服务集群的配置,是真实的服务器,一个Backend对应一个或者多个实体服务器;
•listen:Frontend和Backend的组合体。
环境中Haproxy配置文件
global
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
log 100.2.30.41 5140 local1
maxconn 4000 #最大连接数
stats socket /var/lib/kolla/haproxy/haproxy.sock
defaults
log global
mode http
option redispatch
option httplog
option forwardfor
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
listen stats
bind 100.2.30.41:1984
mode http
stats enable
stats uri /
stats refresh 15s
stats realm Haproxy\ Stats
stats auth openstack:RgRyfTrTKTm1VpgJ9Yh7R9hRAwapT4ZOVGEjwdMD
listen rabbitmq_management
bind 100.2.30.40:15672
server node01 100.2.30.41:15672 check inter 2000 rise 2 fall 5
#每2000ms检查一次,成功2次标记为up,失败5次标记为down
server node02 100.2.30.42:15672 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:15672 check inter 2000 rise 2 fall 5
listen keystone_internal
bind 100.2.30.40:5000
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:5000 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:5000 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:5000 check inter 2000 rise 2 fall 5
listen keystone_admin
bind 100.2.30.40:35357
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:35357 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:35357 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:35357 check inter 2000 rise 2 fall 5
listen glance_registry
bind 100.2.30.40:9191
server node01 100.2.30.41:9191 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:9191 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:9191 check inter 2000 rise 2 fall 5
listen glance_api
bind 100.2.30.40:9292
server node01 100.2.30.41:9292 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:9292 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:9292 check inter 2000 rise 2 fall 5
listen nova_api
bind 100.2.30.40:8774
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:8774 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8774 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8774 check inter 2000 rise 2 fall 5
listen nova_metadata
bind 100.2.30.40:8775
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:8775 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8775 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8775 check inter 2000 rise 2 fall 5
listen placement_api
bind 100.2.30.40:8780
http-request del-header X-Forwarded-Proto
server node01 100.2.30.41:8780 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8780 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8780 check inter 2000 rise 2 fall 5
listen nova_novncproxy
bind 100.2.30.40:6080
http-request del-header X-Forwarded-Proto if { ssl_fc }
http-request set-header X-Forwarded-Proto https if { ssl_fc }
server node01 100.2.30.41:6080 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:6080 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:6080 check inter 2000 rise 2 fall 5
listen neutron_server
bind 100.2.30.40:9696
server node01 100.2.30.41:9696 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:9696 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:9696 check inter 2000 rise 2 fall 5
listen horizon
bind 100.2.30.40:80
balance source #horizon服务需要使用source方式,用以保存连接
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:80 check inter 2000 rise 2 fall 2
server node02 100.2.30.42:80 check inter 2000 rise 2 fall 2
server node03 100.2.30.43:80 check inter 2000 rise 2 fall 2
listen cinder_api
bind 100.2.30.40:8776
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:8776 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8776 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8776 check inter 2000 rise 2 fall 5
listen heat_api
bind 100.2.30.40:8004
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:8004 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8004 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8004 check inter 2000 rise 2 fall 5
listen heat_api_cfn
bind 100.2.30.40:8000
http-request del-header X-Forwarded-Proto if { ssl_fc }
server node01 100.2.30.41:8000 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:8000 check inter 2000 rise 2 fall 5
server node03 100.2.30.43:8000 check inter 2000 rise 2 fall 5
(NOTE): This defaults section deletes forwardfor as recommended by:
(NOTE): This defaults section deletes forwardfor as recommended by:
# {+}https://marc.info/?l=haproxy&m=141684110710132&w=1+
defaults
log global
mode http
option redispatch
option httplog
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
listen mariadb
mode tcp
timeout client 3600s
timeout server 3600s
option tcplog
option tcpka
option mysql-check user haproxy post-41
bind 100.2.30.40:3306
server node01 100.2.30.41:3306 check inter 2000 rise 2 fall 5
server node02 100.2.30.42:3306 check inter 2000 rise 2 fall 5 backup
server node03 100.2.30.43:3306 check inter 2000 rise 2 fall 5 backup
此处为mariadb的Haproxy配置,可以看到,node02和node03有backup标识,引用官方解释
When "backup" is present on a server line, the server is only used in load balancing when all other non-backup servers are unavailable.
Requests coming with a persistence cookie referencing the server will always be served though.
By default, only the first operational backup server is used, unless the "allbackups" option is set in the backend.
See also the "allbackups" option.
在服务器这一行添加了这个标识之后,只有当没有设置backup的标识的服务器不可用时才会转发给这台服务器。
在持续的,带有cookie的请求到来时,会一直使用同一台服务器。
默认情况下,只有第一台可用的服务器会被使用。
也就是说,默认情况下haproxy会把所有的请求发给node01。
1)当node01出现故障后,会把所有的请求发给node02,不会发给node03。
2)当node01,node02故障后,才会把请求发给node03。
3)在1)的情形下,node01恢复正常,但是,带有cookie的持续请求仍然只会发给node02,而不会被发给node01。
没有cookie的请求则被转发给node01。此时,重启vip所在的节点的haproxy,则所有的请求均转发到node01上。
HA工作过程

- 在三个控制节点的Openstack环境中,部署三个Keepalived服务,共同维护同一个VIP。每个Keepalived进程均执行以下任务:
1) 根据VRRP协议维护VIP
2) Master节点检查Haproxy工作状态,若检查发现Haproxy进程失效,则进入初始化状态,发出优先权级为0的VRRP通告信息,Slave节点变为Master节点,获得VIP
部署三个Haproxy服务,每个服务均可以单独工作,完成客户端请求转发。实际工作状态下,只有VIP所在的节点的Haproxy才会工作。当VIP出现漂移后,才会由其他节点的Haproxy进行转发。
如上图所示,在正常情况下,优先权级高的一个节点获得VIP,例如node01优先权级高,VIP在node01,此时,node01上Haproxy负责请求分发功能,客户端访问node01的Haproxy,然后经过一定的负载均横算法,分别转发给node01、node02和node03的相应的服务进行处理。
HA场景——节点宕机
1)当node01意外宕机,此时,node01上的Keepalived进程失效。Node02和node03上的主机超时定时器超时,发送VRRP通告信息,广播ARP地址信息。由于这两个节点的优先权级不同,优先权级高的node02节点会成为新的Master,获得VIP,此时,该节点Haproxy将会工作,负责请求转发功能。与此同时,Haproxy也会探测后端服务是否可用,由于node01宕机,在node01上的服务均不可用,Haproxy将不再把请求转发至node01上。对于数据库来说,Haproxy只会把请求转发至node02(原因已在Haproxy配置文件中解释)。
2)在node01宕机的情况下,若再次出现node02宕机,此时,node03上的主机超市定时器超时,node03发出VRRP通告,并广播ARP地址信息,由于仅有一个通告,故node03将获得VIP,该节点的HAproxy开始工作。由于node01和node02均已宕机,Haproxy会探测到后端服务仅一个可用,将会把请求只转发至node03上。此时,数据库则只使用node03。
3)在node01和node02同时宕机时,node03上的主机定时器超时,node03获得VIP,同时node03的Haproxy会检测到node01和node02的服务失效,将会把请求转发至node03。数据库同样只会转发至node03。
4)场景1)的情况下,当节点node01节点恢复时,由于设置了不抢占的参数,故VIP仍然由node02保持,node02上的Haproxy会探测到node01上服务已恢复,无状态的服务,例如api,neutron-server等会按照round-robin的规则进行请求的转发。而对于数据库来说,保存有cookies的连接仍然会转发至node02,直到cookie失效或者node02上的Haproxy重启。新的请求则会全部转发至node01。
5)在场景2)和场景3)的情况下,节点全部恢复,过程与场景4)类似,openstack的服务会按照规则进行转发,而数据库的连接与cookie有关。
HA场景——服务不可用
服务不可用的情况下,Haproxy可以通过定时的状态检测发现,检测不可用状态 后,不会再将请求转发至不可用的节点。
Questions:
- 同时为backup模式下,三个节点只有一个节点存活时,启动另外两个节点时, vip被抢占?
答:不会被抢占,在默认的keepalived配置文件中设置了nopreempt参数
2. 数据库是否是多主,是否同时接受读写?
答:多主,但是根据上文的分析,正常情况下,各项服务只访问第一个节点。只有当发生故障时,才会访问第二和第三个节点。
3. Ceph HA
答:ceph集群本身具有高可用架构
7. 多个cinder-vlolume 接一个backend
答:在使用lvm作为后端时,无法实现cinder-volume服务的HA,在使用分布式存储ceph或者集中存储时,可以实现
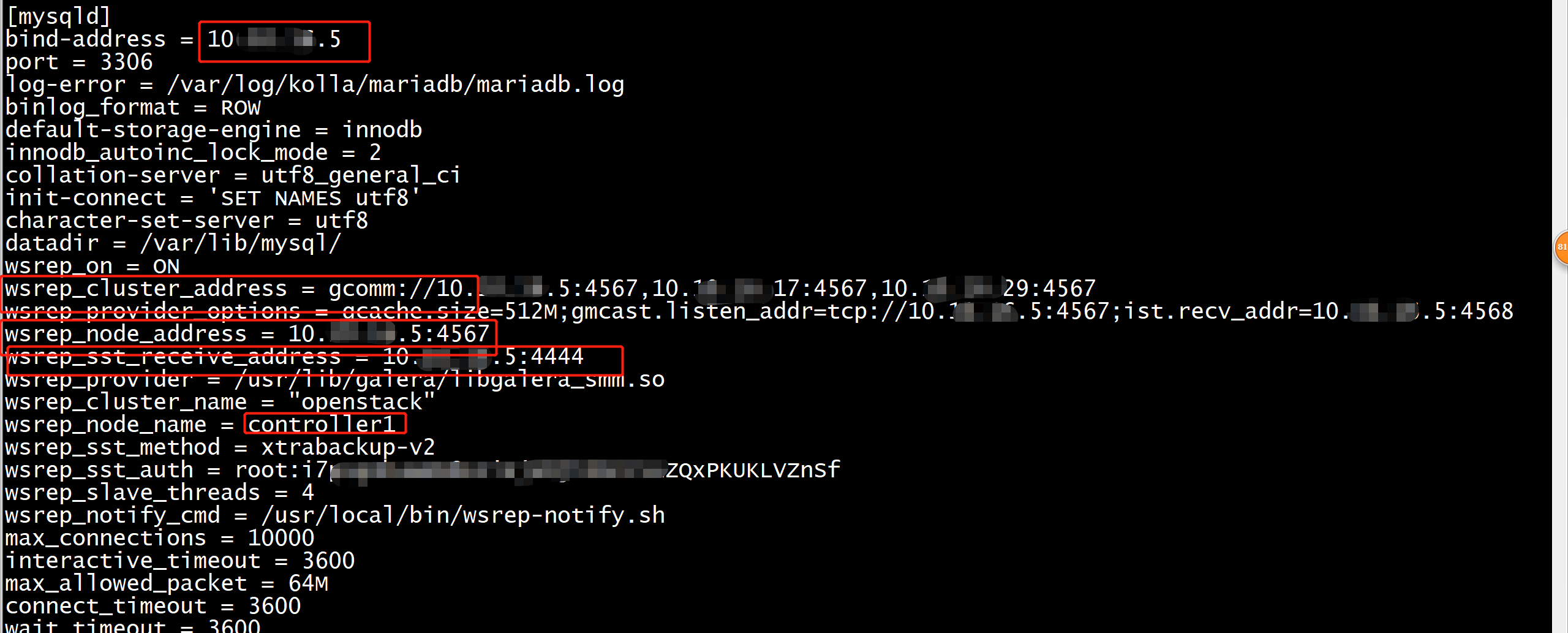
mysql集群重点
参考:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号