从零开始学算法(二)——回溯
首先介绍“回溯”算法的应用。
“回溯”算法主要用于搜索,有时“回溯算法”也叫“回溯搜索”。这里“搜索”的意思是“查找所需要的解”。我们每天使用的“搜索引擎”就是帮助我们在庞大的互联网上搜索我们需要的信息。而这里的“回溯”指的是“状态重置”,可以理解为“回到过去”、“恢复现场”,是在编码的过程中,是为了节约空间而使用的一种技巧。而回溯其实是“深度优先遍历”特有的一种现象。之所以是“深度优先遍历”,是因为我们要解决的问题通常是在一棵隐式的树上完成的。
“全排列”就是一个非常经典的“回溯”算法的应用。我们知道,N 个数字的全排列一共有 N!N! 这么多个。
大家可以尝试一下在纸上写 3 个数字、4 个数字、5 个数字的全排列,相信不难找到这样的方法。
例如数组 [1, 2, 3] 的全排列。
我们先写以 1 开头的全排列,它们是:[1, 2, 3], [1, 3, 2];
再写以 2 开头的全排列,它们是:[2, 1, 3], [2, 3, 1];
最后写以 3 开头的全排列,它们是:[3, 1, 2], [3, 2, 1]。
我们只需要按顺序枚举每一位可能出现的情况,已经选择的数字在接下来要确定的数字中不能出现。按照这种策略选取就能够做到不重不漏,把可能的全排列都枚举出来。
在枚举第一位的时候,有 3 种情况。
在枚举第二位的时候,前面已经出现过的数字就不能再被选取了;
在枚举第三位的时候,前面 2 个已经选择过的数字就不能再被选取了。
这样的思路,我们可以用一个树形结构来表示。
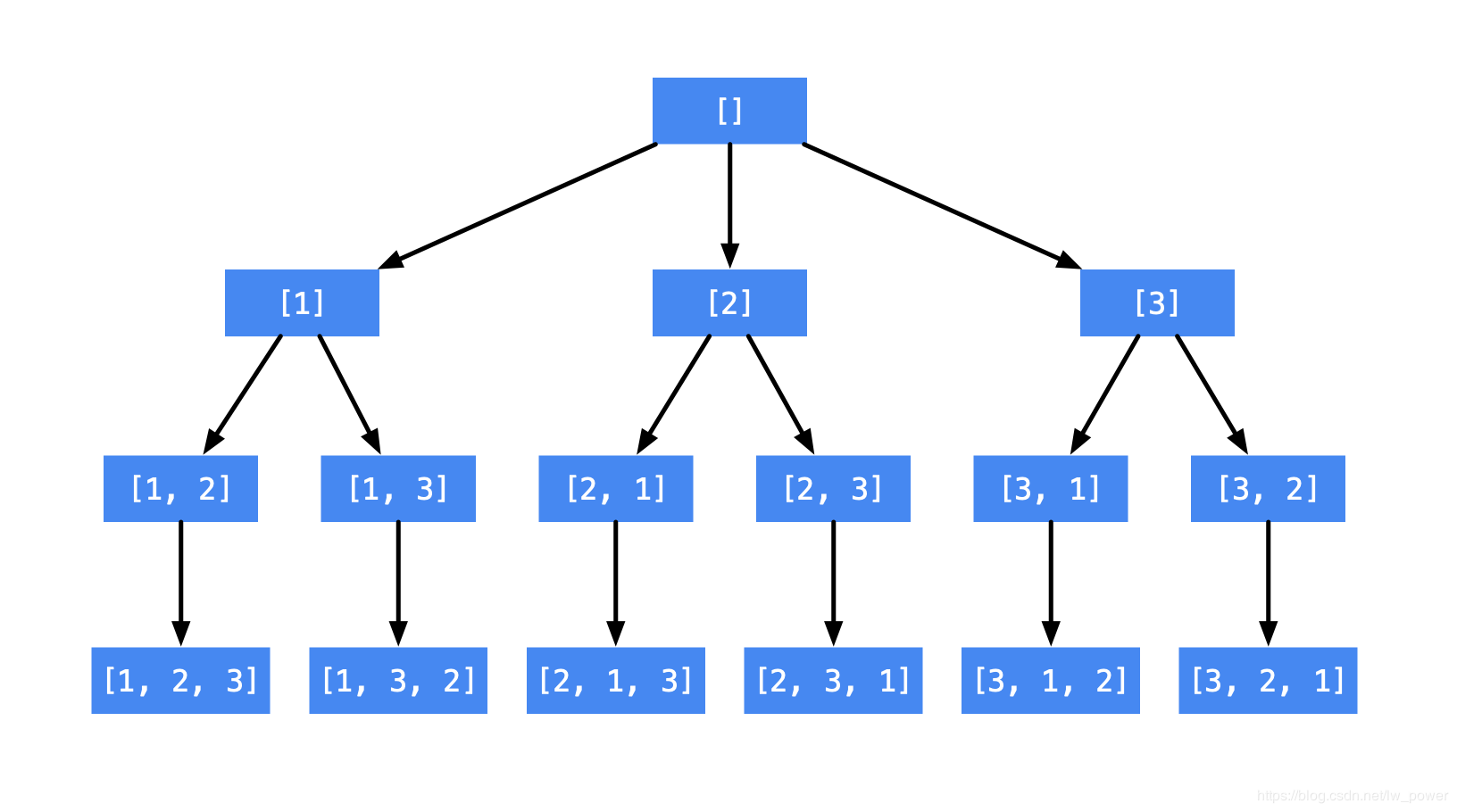
使用编程的方法得到全排列,就是在这样的一个树形结构中进行编程,具体来说,就是执行一次深度优先遍历,从树的根结点到叶子结点形成的路径就是一个全排列。
同样是遍历,我们很自然提出疑问,广度优先遍历是否可以。答案是:当然可以,有些搜索问题的确是使用广度优先遍历解决的的。
这里使用深度优先遍历的原因是:1、编码方便;2、全局使用同一份状态变量,避免资源浪费;3、深度优先遍历在执行的过程中,状态不会发生跳跃,状态转移非常容易。
下面我们解释如何编码:
1、首先这棵树除了根结点和叶子结点以外,每一个结点做的事情其实是一样的,即在已经选了一些数的前提,我们需要在剩下还没有选择的数中按照顺序依次选择一个数,这显然是一个递归结构;
2、递归的终止条件是,数已经选够了,因此我们需要一个变量来表示当前递归到第几层,我们把这个变量叫做 depth;
3、这些结点实际上表示了搜索(查找)全排列问题的不同阶段,为了区分这些不同阶段,我们就需要一些变量来记录为了得到一个全排列,我们进行到那一步了,在这里我们需要两个变量:
(1)已经选了哪些数,到叶子结点时候,这些已经选择的数就构成了一个全排列;
(2)一个布尔数组 used,初始化的时候都为 false 表示这些数还没有被选择,当我们选定一个数的时候,就将这个数组的相应位置设置为 true ,这样在考虑下一个位置的时候,就能够以 O(1)O(1) 的时间复杂度判断这个数是否被选择过,这是一种“以空间换时间”的思想。
我们把这两个变量称之为“状态变量”,它们表示了我们在求解一个问题的时候所处的阶段。
4、在非叶子结点处,产生不同的分支,这一操作的语义是:在还未选择的数中依次选择一个元素作为下一个位置的元素,这显然得通过一个循环实现。
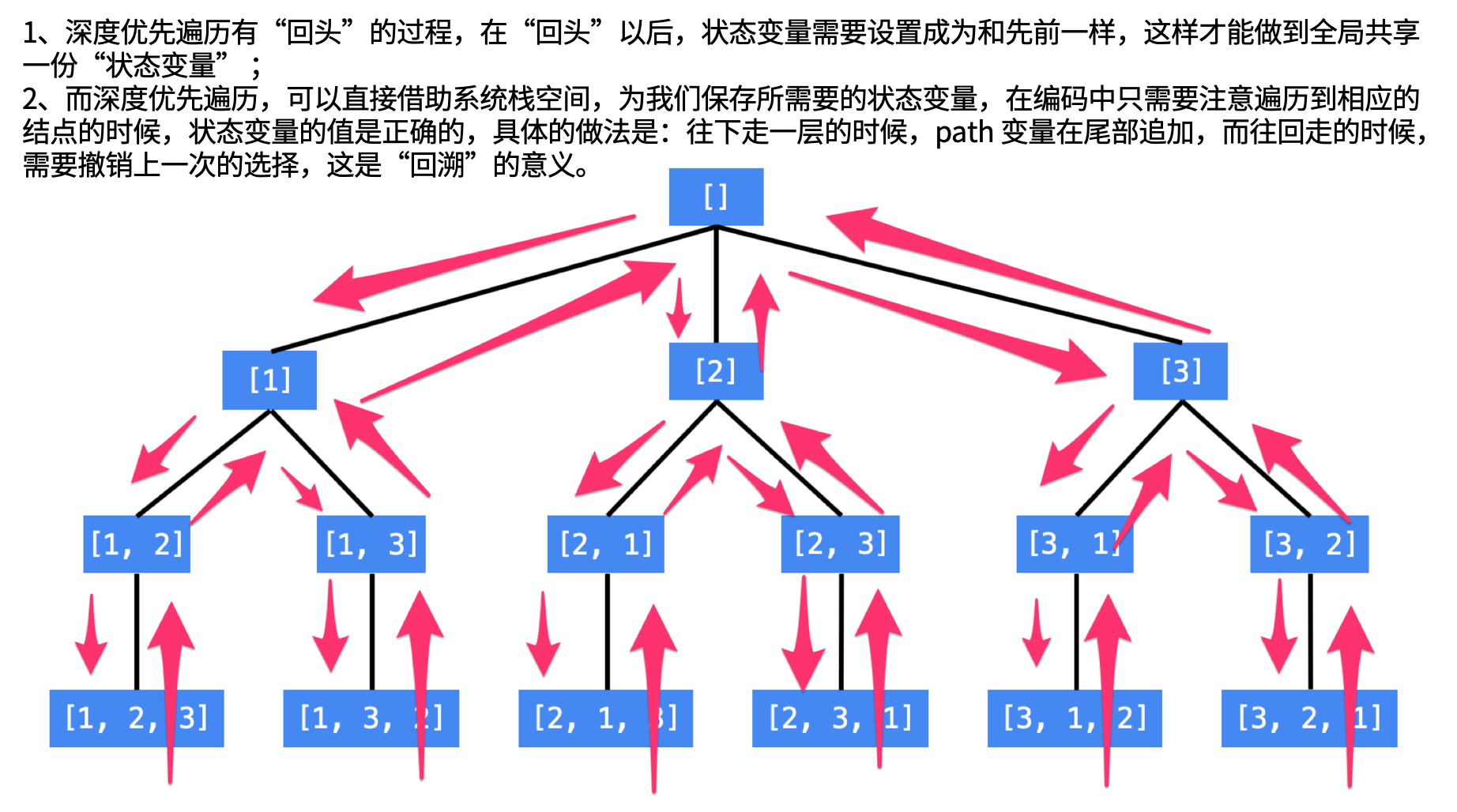
5、另外,因为是执行深度优先遍历,从较深层的结点返回到较浅层结点的时候,需要做“状态重置”,即“回到过去”、“恢复现场”,我们举一个例子。
从 [1, 2, 3] 到 [1, 3, 2] ,深度优先遍历是这样做的,从 [1, 2, 3] 回到 [1, 2] 的时候,需要撤销刚刚已经选择的数 3,因为在这一层只有一个数 3 我们已经尝试过了,因此程序回到上一层,需要撤销对 2 的选择,好让后面的程序知道,选择 3 了以后还能够选择 2。
这种在遍历的过程中,从深层结点回到浅层结点的过程中所做的操作就叫“回溯”
下面我们就来看看代码应该如何编写:
public class Solution { public List<List<Integer>> permute(int[] nums) { // 首先是特判 int len = nums.length; // 使用一个动态数组保存所有可能的全排列 List<List<Integer>> res = new ArrayList<>(); if (len == 0) { return res; } boolean[] used = new boolean[len]; List<Integer> path = new ArrayList<>(); dfs(nums, len, 0, path, used, res); return res; } private void dfs(int[] nums, int len, int depth, List<Integer> path, boolean[] used, List<List<Integer>> res) { if (depth == len) { res.add(new ArrayList<>(path)); return; } for (int i = 0; i < len; i++) { if (!used[i]) { path.add(nums[i]); used[i] = true; dfs(nums, len, depth + 1, path, used, res); // 注意:这里是状态重置,是从深层结点回到浅层结点的过程,代码在形式上和递归之前是对称的 used[i] = false; path.remove(depth); } } } public static void main(String[] args) { int[] nums = {1, 2, 3}; Solution solution = new Solution(); List<List<Integer>> lists = solution.permute(nums); System.out.println(lists); } }
其他一些适合回溯算法的题目
- 47. 全排列 II (思考一下,为什么造成了重复,如何在搜索之前就判断这一支会产生重复,从而“剪枝”。)
- 17 .电话号码的字母组合
- 22. 括号生成 (这是字符串问题,没有显式回溯的过程。这道题广度优先遍历也很好写,可以通过这个问题理解一下为什么回溯算法都是深度优先遍历,并且都用递归来写。)
- 39. 组合总和 (使用题目给的示例,画图分析。)
- 40. 组合总和 II
- 51. N皇后 (其实就是全排列问题,注意设计清楚状态变量。)
- 60. 第k个排列( 利用了剪枝的思想,减去了大量枝叶,直接来到需要的叶子结点。)
- 77. 组合( 组合问题按顺序找,就不会重复。并且举一个中等规模的例子,找到如何剪枝,这道题思想不难,难在编码。)
- 78. 子集 (为数不多的,解不在叶子结点上的回溯搜索问题。解法比较多,注意对比。)
- 90. 子集 II( 剪枝技巧同 47 题、39 题、40 题。)
- 93. 复原IP地址
- 784. 字母大小写全排列
转载自:liweiwei1419 链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-python-dai-ma-java-dai-ma-by-liweiw/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号