【1.0】纯手撸Web框架
【一】Web框架本质
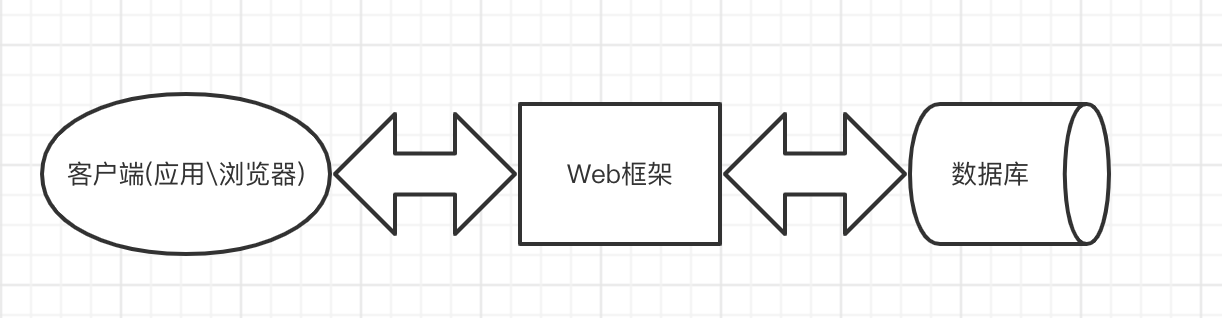
- web框架本质上可以看成是一个功能强大的socket服务端,用户的浏览器可以看成是拥有可视化界面的socket客户端。
- 两者通过网络请求实现数据交互,从架构层面上先简单的将Web框架看做是对前端、数据库的全方位整合
【二】纯手撸Web框架
- 前面的课程我们已经学习了网络编程并掌握了socket套接字编程
- 接下来我们就可以自己编写出一个简易的web框架
【1】原始版本
(1)服务端
# 【一】导入模块
import socket
# 【二】定义通信IP和端口
IP = '127.0.0.1'
PORT = 8082
# 【三】创建socket对象
server = socket.socket()
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 就是它,在bind前加
# 【四】监听端口
server.bind((IP, PORT))
# 【五】创建半连接池
server.listen(5)
while True:
# 【六】接收客户端链接和地址
sock, addr = server.accept()
# 【七】接收数据
data = sock.recv(1024)
print(f'这是来自客户端的信息 :>>>> {data.decode("utf-8")}')
# 【八】回送数据
sock.send(b'hello client')
(2)客户端
# 【一】导入模块
import socket
# 【二】定义通信IP和端口
IP = '127.0.0.1'
PORT = 8082
# 【三】创建连接对象
client = socket.socket()
client.connect((IP, PORT))
while True:
# 【四】发送数据
client.send(b"hello server")
# 【五】接收数据
data = client.recv(1024)
print(f"这是来自服务端的数据 :>>>> {data.decode('utf-8')}")
【2】浏览器发送请求
- 遵循HTTP协议
- 四大特性
- 数据格式
- 响应状态码
# 【一】导入模块
import socket
from _socket import SO_REUSEADDR, SOL_SOCKET
# 【二】定义通信IP和端口
IP = '127.0.0.1'
PORT = 8082
# 【三】创建socket对象
server = socket.socket()
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 就是它,在bind前加
# 【四】监听端口
server.bind((IP, PORT))
# 【五】创建半连接池
server.listen(5)
while True:
# 【六】接收客户端链接和地址
sock, addr = server.accept()
# 【七】接收数据
data = sock.recv(1024)
print(f'这是来自客户端的信息 :>>>> {data.decode("utf-8")}')
# 【八】回送数据
# 服务端响应的数据需要符合HTTP响应格式
sock.send(b'HTTP1.1 200 OK\r\n\r\n hello client')
【3】路由对应响应
- 基于不同的后缀相应不同的内容
GET /favicon.ico HTTP/1.1
Host: 127.0.0.1:8082
Connection: keep-alive
sec-ch-ua: "Not A(Brand";v="99", "Google Chrome";v="121", "Chromium";v="121"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36
sec-ch-ua-platform: "macOS"
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: no-cors
Sec-Fetch-Dest: image
Referer: http://127.0.0.1:8082/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
- 如何获取用户输入的url后缀
- HTTP请求数据
/favicon.ico直接忽略 不影响判断
- 利用字符串切割和索引取值获取相应数据
# 【一】导入模块
import socket
from _socket import SO_REUSEADDR, SOL_SOCKET
# 【二】定义通信IP和端口
IP = '127.0.0.1'
PORT = 8082
# 【三】创建socket对象
server = socket.socket()
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 就是它,在bind前加
# 【四】监听端口
server.bind((IP, PORT))
# 【五】创建半连接池
server.listen(5)
while True:
# 【六】接收客户端链接和地址
sock, addr = server.accept()
# 【七】接收数据
data = sock.recv(1024)
# print(f'这是来自客户端的信息 :>>>> {data.decode("utf-8")}')
# 【八】回送数据
# 服务端响应的数据需要符合HTTP响应格式
http_type = "HTTP1.1 200 OK\r\n\r\n"
# 将客户端请求相关数据先转成字符串
option = data.decode('utf8')
# 研究发现可以采用字符串切割获取路由
current_path = option.split(' ')[1]
# 根据后缀的不同返回不同的内容
if current_path == '/login':
data = f'{http_type} hello dream login!!!'
sock.send(data.encode('utf-8'))
elif current_path == '/register':
data = f'{http_type} hello dream register'
sock.send(data.encode('utf-8'))
else:
data = f'{http_type}404 dream error'
sock.send(data.encode('utf-8'))
【4】小结
- 纯手撸框架缺陷:
- socket代码过于重复(每次搭建服务端都需要反复造轮子)
- 针对HTTP请求数据没有完善的处理方式(目前只能定向切割)
- 无法实现服务端的并发
【三】基于wsgiref模块搭建web框架
【1】模块封装功能
from wsgiref import simple_server
def run(request, response):
"""
:param request: 请求相关的数据
:param response: 响应相关的数据
:return: 返回给客户端的展示数据
"""
response('200 OK', []) # 固定编写 无需掌握
return [b'hello dream']
if __name__ == '__main__':
'''服务端监听的IP和端口'''
IP = '127.0.0.1'
PORT = 8080
'''创建一个服务端对象'''
server = simple_server.make_server(IP, PORT, run)
'''监听本机8080端口 一旦有请求访问 自动触发run方法的执行'''
server.serve_forever()
# 模块封装了socket代码并将请求数据处理成诸多k:v键值对
【2】路由对应响应
from wsgiref import simple_server
def run(request, response):
"""
:param request: 请求相关的数据
:param response: 响应相关的数据
:return: 返回给客户端的展示数据
"""
response('200 OK', []) # 固定编写 无需掌握
# run函数体中添加下列代码
current_path = request.get("PATH_INFO")
if current_path == '/login':
return [b'hello login html']
elif current_path == '/register':
return [b'hello register html']
return [b'404 error']
if __name__ == '__main__':
'''服务端监听的IP和端口'''
IP = '127.0.0.1'
PORT = 8080
'''创建一个服务端对象'''
server = simple_server.make_server(IP, PORT, run)
'''监听本机8080端口 一旦有请求访问 自动触发run方法的执行'''
server.serve_forever()
# 模块封装了socket代码并将请求数据处理成诸多k:v键值对
【四】优化方案
【1】优化方案思路
(1)问题
- 如果网站很多,必须人为的添加elif
- 每个分支下的功能根据业务逻辑的不同可能会比较复杂的逻辑
(2)函数优化
-
将匹配和功能封装成 元组和函数
-
但是还是会存在问题
- 所有的代码全部放在一个py文件过于冗余
- 不便于后期管理维护
(3)模块优化
- 根据功能的不同拆分成不同的py文件
urls.py 对应关系的存储
views.py 业务逻辑的编写
-
以后要想新增功能 只需要在urls.py中添加对应关系 view.py中编写函数
-
但还是会存在新的问题
- 业务函数的代码中 可能会频繁的使用到不同的html页面
(4)模版优化
- 为了避免文件类型的混乱 单独开设一个文件夹存储所有的html文件
templates文件夹 存储项目所需的html文件
- 但还是会存在新的问题
- 项目中的html文件 也有可能需要用到css、js、第三方框架文件
(5)静态优化
- html所学的css、js、第三方框架代码都是写完之后很少做改动的文件
- 所以可以统一存放在某个文件夹下
static文件夹 存储项目所需的'静态文件'(后续再讲)
【2】优化方案实现
(1)路由和响应模块化
- 当有很多路由和响应的情况下不可能无限制编写if判断语句,应该设置对应关系并动态调用
from wsgiref import simple_server
def register(request):
return 'register'
def login(request):
return 'login'
def error(request):
with open(r'templates/error.html', 'r', encoding='utf8') as f:
return f.read()
urls = (
('/login', login),
('/register', register)
)
def run(request, response):
# run函数体中添加下列代码
current_path = request.get("PATH_INFO")
func_name = None
for url_tuple in urls:
if current_path == url_tuple[0]:
# 先获取对应的函数名
func_name = url_tuple[1]
# 一旦匹配上了 后续的对应关系就无需在循环比对了
break
# for循环运行完毕之后 func_name也有可能是None
if func_name:
res = func_name(request)
else:
res = error(request) # 顺手将request也传给函数 便于后续数据的获取
return [res.encode('utf8')]
if __name__ == '__main__':
'''服务端监听的IP和端口'''
IP = '127.0.0.1'
PORT = 8080
'''创建一个服务端对象'''
server = simple_server.make_server(IP, PORT, run)
'''监听本机8080端口 一旦有请求访问 自动触发run方法的执行'''
server.serve_forever()
# 模块封装了socket代码并将请求数据处理成诸多k:v键值对
(2)根据功能划分模块
- 根据功能的不同拆分成不同的py文件
[1]views.py
- --存储路由与函数对应关系
# 功能函数
def register(request):
return 'register'
def login(request):
return 'login'
def index(request):
return 'index'
def error(request):
with open(r'templates/error.html', 'r', encoding='utf8') as f:
return f.read()
[2]urls.py
- --存储函数
from views import *
# 后缀匹配
urls = (
('/register', register),
('/login', login),
('/index', index),
)
[3]server.py
- --存储启动及分配代码
from wsgiref import simple_server
from urls import urls
from views import error
def run(request, response):
response('200 OK', [])
current_path = request.get("PATH_INFO")
func_name = None
for url_tuple in urls: # ('/register', register)
if current_path == url_tuple[0]:
func_name = url_tuple[1]
break
if func_name:
res = func_name(request)
else:
res = error(request)
return [res.encode('utf8')]
if __name__ == '__main__':
server = simple_server.make_server('127.0.0.1', 8080, run)
server.serve_forever()
总结:
拆分后好处在于要想新增一个功能,只需要在views.py中编写函数,urls.py添加对应关系即可
(3)模板文件与静态文件
[1]templates文件夹
- --存储html文件
[2]static文件夹
- --存储html页面所需静态资源(后续详细讲解或自行百度)
【五】动静态网页
【1】静态网页
(1)介绍
- 静态网页 是一种基本的网页形式,其中的数据和布局在编写 HTML 文件时就已经固定下来,不随用户的请求或时间的变化而改变。
- 静态网页内容主要包括 HTML、CSS 和 JavaScript 等前端技术构建的页面结构、样式和行为。
- 由于其内容不依赖于服务器端动态处理,因此它们具有以下特点
(2)特点
- 内容固定:页面上的所有数据(文本、图片、链接等)都直接写入 HTML 文件,不会因为用户的不同请求或时间的变化而变化。
- 无需服务器处理:当用户访问静态网页时,浏览器直接从服务器下载对应的 HTML 文件并显示内容,服务器主要负责存储和分发已存在的网页资源。
- 加载速度快:由于内容不需服务器进一步处理,所以加载速度较快。
(3)示例
- 常见例子有:error.html、func.html等预定义的错误提示页面、功能说明页面等。
【2】动态网页
(1)介绍
- 动态网页则是在服务器端运行脚本语言(如 PHP、Python、JavaScript 或 Java 等)来生成和处理数据,然后再将处理后的数据以 HTML 格式发送至浏览器。
(2)特点
- 内容实时更新:页面上的数据可以根据用户的请求、数据库查询结果或其他服务器端逻辑动态生成,这意味着同一页面可以呈现不同的内容给不同的用户或在不同时间访问的用户。
- 需要服务器处理:当用户访问 动态网页时,服务器会根据请求执行相应的脚本程序,调用后台数据库进行查询、计算等操作,然后再将处理后的数据返回给浏览器,浏览器负责渲染这些动态内容。
- 数据交互性强:动态网页支持与用户交互,如表单提交、搜索功能等,能更好地满足用户实时需求和个性化体验。
(3)示例
- 展示当前时间:服务器端定时获取系统时间,动态生成包含当前时间的 HTML 内容发送给浏览器显示。
- 显示数据库数据:根据用户的请求,从数据库查询相关数据,生成带有动态内容的 HTML 页面供用户浏览。
【3】总结
- 静态网页适合用于内容较少且不需要频繁更新的场景,如关于我们、联系我们等基础介绍页面。
- 动态网页则更适用于需要实时交互、内容丰富且需要定期更新的场景,如新闻资讯、在线购物平台等,通过服务器端的动态处理,提供了更好的用户体验和更高的业务复杂性处理能力。
【六】Jinja2模板语法
【1】页面展示当前时间
(1)后端
def get_time(request):
# 1.获取当前时间
import time
c_time = time.strftime('%Y-%m-%d %X')
# 2.读取html文件
with open(r'templates/get_time.html','r',encoding='utf8') as f:
data = f.read()
# 3.思考:如何给字符串添加一些额外的字符串数据>>>:字符串替换
new_data = data.replace('random_str',c_time)
return new_data
(2)前端
<h1>展示后端获取的时间数据</h1>
<span>random_str</span>
【2】jinja2模板语法
(1)下载安装
- 第三方模块需要先下载后使用
pip3 install jinja2
(2)功能
- 支持将数据传递到html页面并提供近似于后端的处理方式简单快捷的操作数据
(3)views.py
from jinja2 import Template
def get_dict(request):
user_dict = {'name': 'dream', 'pwd': 123, 'hobby': 'read'}
new_list = [11, 22, 33, 44, 55, 66]
with open(r'templates/get_dict.html', 'r', encoding='utf8') as f:
data = f.read()
temp_obj = Template(data)
res = temp_obj.render({'user':user_dict,'new_list':new_list})
return res
(4)templates
- --get_dict.html
<h1>字典数据展示</h1>
<p>{{ user }}</p>
<p>{{ user.name }}</p>
<p>{{ user['pwd'] }}</p>
<p>{{ user.get('hobby') }}</p>
<h1>列表数据展示</h1>
<p>
{% for i in new_list%}
<span>元素:{{ i }}</span>
{% endfor %}
</p>
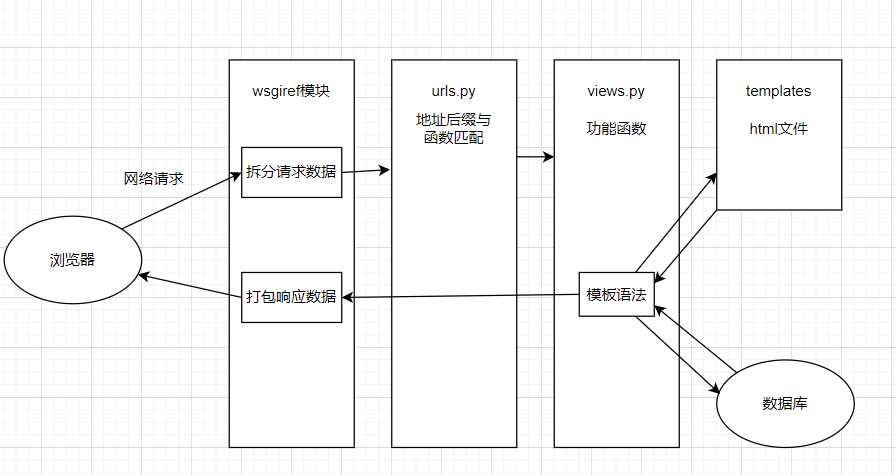
【七】框架请求流程
【八】关键字
【1】urls.py
- 后缀与函数名对应关系
- ('/index',register)
- 后缀专业名词称之为'路由'
- 函数名专业名词称之为'视图函数'
- urls.py专业名词称之为'路由层'
【2】views.py
- 专门编写业务逻辑代码
- 可以是函数 也可以是类
- 函数专业名词称之为'视图函数'
- 类专业名词称之为'视图类'
- views.py专业名词称之为'视图层'
【3】templates文件夹
- 专门存储html文件
- html文件专业名词称之为'模板文件'
- templates文件夹专业名词称之为'模板层'
【4】static文件夹
- 专门存储静态文件资源
- 页面所需css文件、js文件、图片文件、第三方文件可统称为'静态资源'
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/18036050
