MySQL数据库小结
【一】登陆
mysql -uroot -p123456
【二】服务启动和停止
【1】Windows
(1)方式一
- 计算机
- 右击管理
- 服务【右击计算机管理---中间服务与应用程序---双击服务---下面点击标准---即可查看每个软件是否启动服务的状态(可以直接输入要查询的软件名称,再回车键即可)。】
(2)管理员身份(cmd)
- 启动
net start 服务名
net start MySQL
- 停止
net stop 服务名
net stop MySQL
- 重启
net restart 服务名
net restart MySQL
【2】MacOS
- 启动
sudo /usr/local/mysql/support-files/mysql.server start
- 停止
sudo /usr/local/mysql/support-files/mysql.server stop
- 重启
sudo /usr/local/mysql/support-files/mysql.server restart
【三】MySQL服务的登陆和退出
【1】MySQL自带的客户端
- 通过mysql自带的客户端【搜索框搜mysql,找到command Line Client程序进入】只限于root用户
【2】通过windows自带的客户端【cmd窗口进入】
(1)登录
mysql 【-h主机名 -P端口号 】-u用户名 -p密码
- 示例
mysql -h localhost -P 3306 -root -p 123456
# {若是本机登入方式为:mysql -u用户名 -p密码}
(2)退出
exit
quit
【四】常用命令
【1】查询当前使用的数据库版本?
select version();
- 上面的方法是在mysql界面输入的代码,若在没有登入mysql时,如何查询?>
mysql -V
【2】查询当前使用的是哪个数据库?
select database();
【3】查看现有的数据库有哪些?
show databases;
【4】查看某数据库有哪些表?
show tables;
【5】对某个数据库进行操作,先进入数据库?
use 数据库名;
(1)数据库都有哪些表格?
show tables;
(2)每张表格的表结构如何?
desc 表名称;
(3)查看某张表的所有数据?
select * from 表名称;
【6】查看其它数据库中的表?
show tables from <数据库名称>;
【7】查看表的创建语句
show create table <表名称>;
【8】将查询的字段重命名?
- as可以省略
select empno as '员工编码',ename as '员工姓名',sal*12 as '年薪'from emp;
【9】如何查询某个字段非空(为空)值?
select empno,ename,comm from emp where comm is not null;
select empno,ename,comm from emp where comm is null;
【10】导入数据文件
source D:\bjpowernode.sql
【五】MySQL支持哪些运算符?
| 运算符 | 说明 |
|---|---|
| = | 等于 |
| <>或!= | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| between ... and ... | 两个值之间,等同于 >= and <= |
| is null | 为null (is not null 不为空) |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个 or (not in 不在这个范围内) |
| not | not 可以取非,主要用在is或in中 |
| like | like称为模糊匹配,支持 % 或下划线匹配 (% 匹配任意个字符) |
-
补充
-
and的优先级高于or。
-
between...and...当数值时为闭区间,且and前面的数值必须比后面大。若为字符,区间为前闭后开。
-
【六】数据排序
【1】作用
- 通过哪个或哪些字段进行排序
【2】说明
- 排序采用 order by 子句
- order by 后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔
- order by默认采用升序(asc)
- 如果存在 where 子句,那么 order by 必须放到 where 语句后面。
- 如果采用多个字段排序,如果根据第一个字段排序重复了,会根据第二个字段排序;降序(desc)
【3】按照薪水由小到大排序(系统默认由小到大)
- 单个字段排序
select * from emp order by sal;
select * from emp where job='MANAGER' order by sal;
select * from emp order by sal desc;
- 多个字段排序:
select * from emp order by job desc,sal desc;
【七】处理函数
【1】单行处理函数
(1)介绍
| 函数名 | 解释 | 用法 |
|---|---|---|
| lower | 转换小写 | lower(要转换字段名称) |
| upper | 转换大写 | upper(要转换字段名称) |
| substr | 取子串 | substr(被截取字段名称,起下标,截取长度) |
| length | 取长度 用法: | length(字段名称) |
| trim | 去除空格 | trim(字符串) |
| str_to_date | 将字符串转换成日期 | str_to_date("日期字符串","日期格式") |
| date_format | 格式化日期 | date_format(日期类型数据,"日期格式") |
| format | 设置千分位 | |
| round | 四舍五入 | round(要四舍五入的数字,四舍五入到哪一位),默认保留整数位 |
| rand | 生成 0~1 随机数 | rand() |
| ifull | 将 null 转换成一个具体的值 | ifull(字段名称,将要替换的值) |
- 数据处理函数是该数据本身特有的,有些函数可能在其它数据库不起作用;
(2)**Lower **
- 用法:lower(要转换字段名称)
select lower(ename) as ename from emp;
**(3)upper **
- 用法:upper(要转换字段名称)
select upper(ename) from emp;
**(4)substr **
- **取字符串 **
- 用法:substr(被截取字段名称,起启下标,截取长度)
select * from emp where substr(ename,2,1)='a';
select substr(ename,2,3) from emp;
- 查找所有 '名字中第二个字母为A的人名
select ename from emp where ename Like '_A%';
select ename from emp where substr(ename,2,1)='A';
(5)length函数
-
取字段长度
-
用法:length(字段名称)
select length(ename) from emp;
(6)trim
-
去除首尾空格
-
作用:trim函数去除首尾空格,不会去除中间空格
-
用法:trim(字符串)
select ename from emp where job=trim(' CLERK');
(7)round
-
四舍五入
-
用法:round(要四舍五入的数字,四舍五入到哪一位),默认保留整数位
(8)rand
-
生成随机数
-
用法:rand()
-
生成一个0-1的随机数;
-
eg:生成0-100以内的一个随机数
-
select round( rand()*100 );
(9)ifnull
-
空值处理函数
-
用法:ifnull(字段名称,将要替换)
-
结论:在数据库中,有Null参与数学运算的结果一定为Null;为了防止计算结果出现Null,建议先使用ifnull函数预先处理。
-
select ename,ifnull(comm,100) from emp;
select ename,sal+ifnull(comm,0) from emp;
- eg:补助为空值的,月补助升薪为100;计算年薪为多少(工资+补助)*12
select ename,(sal+ifnull(comm,100))*12 as '年薪' from emp;
(10)case…when…then…else…end
-
条件函数
-
匹配工作岗位,当为MANAGER时,薪水上调10%,当为SALESMAN时,薪水上调50%,其它岗位薪水不变
select ename,sal,job,(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal from emp;
(11)str_to_date
ps:在开发中,日期表示方式不通用,一般使用“日期字符串”来表示日期。
mysql默认日期格式:%Y-%m-%d。
-
作用:将‘日期字符串’转换为‘日期类型’数据。一般主要运用在插入操作中(插入表中的数据)
-
用法:str_to_date(‘日期字符串’,‘日期格式’)
-
执行结果:DATE类型。
-
eg:查询出1981-12-03入职的员工
select * from emp where hiredate=str_to_date('12-03-1981','%m-%d-%Y');
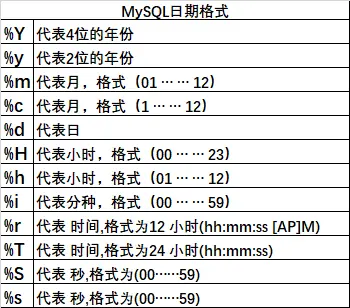
- str_to_date函数通常使用在插入操作中;
- 字段DATA类型,不接收varchar类型,需要先通过该函数将varchar变成data再插入数据。
- 如何再插入表中数据时,使用str_to_date函数:
(12)data_format
-
将日期转换为特定格式字符串
-
作用:将‘日期类型’转换为特定格式的‘日期字符串’类型。该函数主要用于查询操作中,以特定格式展示给客户。
-
用法: date_format(日期类型数据,‘日期格式’)
-
执行结果:字符串varchar类型(具有特定格式)
-
eg:查询员工的入职日期,以‘10-12-1980’的格式显示到窗口中;
select ename,job,date_format(hiredate,'%m-%d-%Y') from emp;
- eg;查询员工的入职日期,以‘10/12/1980’的格式显示到窗口中;
select ename,job,date_format(hiredate,'%m/%d/%Y')hiredate from emp;
【2】分组函数/聚合函数/多行处理函数
(1)介绍
| 函数名 | 说明 |
|---|---|
| sum | 求和 |
| avg | 求平均值 |
| max | 求最大值 |
| min | 求最小值 |
| count | 计数 |
- 注意:
- 分组函数自动忽略空值,不需要手动增加where条件排除空值;
- 分组函数不能直接使用在where关键字后面;
(2)sum函数
- 作用:求某一列的和,null会自动被忽略;
- 用法: sum(字段名称)
- eg:取得薪水的合计;
select sum(sal) from emp;
- 取得补助的合计;
select sum(comn) from emp;
- 取得总共薪水(工资+补助)合计;
select sum(sal+comn) from emp;
# null参与的计算结果都为 null ,数值为null时,聚合函数会自动忽略,用ifnull函数处理
select sum(sal+ifnull(comn,0)) from emp;
(3)avg函数
- 作用:求某一列的平均值
- 用法:avg(字段名称)
- eg:取得平均薪水;
select avg(sal) from emp;
(4)max函数
- 作用:取得某一列的最大值
- 用法:max(字段名称)
- eg:取得最高薪水?
select max(sal) from emp;
- eg:取得最晚入职的员工?
select max(hiredate) from emp;
(5)min函数
- 作用:取得某一列最小值
- 用法:min(字段名称)
- eg:取得最低薪水?
select min(sal) from emp;
(6)count函数
-
作用:取得某字段值不为null的记录总数
-
用法:count(字段名称) 或 count(*)
-
注意:
-
count(*)表示取得所有记录,忽略 null ,为 null 的值也会取。
-
count(字段名称),不会统计为 null 的记录。
-
-
eg:取得所有员工数?
select count(*) from emp;
- eg:取得补助不为空的所有员工数?
select count(comm) from emp;
select count(*) from emp where comm is not null;
- eg:查询出补助comm为 null 值的数量?
select count(*) from emp where comm is null;
(7)组合聚合函数
- 可以将这些聚合函数都放到 select 中一起使用。
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;
(8)distinct函数
- 作用:将查询结果中某一字段的的重复记录去除掉
- 用法:distinct 字段名称或 distinct 字段名称, 字段名称 … …
- 注意:distinct只能出现在所有字段最前面,后面如果有多个字段则为多字段联合去重复值。
- eg:查询该公司有哪些工作岗位?
select distinct job from emp;
- 查询该公司有几个工作岗位?
select count(distinct job) from emp;
- 去除部门编号deptno和工作岗位job重复的记录
select distinct deptno,job from emp;
【八】分组查询
【1】前言
(1)作用
- 通过哪个或哪些字段进行分组
(2)用法
- group by 字段名称
(3)重点结论
- 若一条DQL语句中有group by子句,那么select 关键词后面只能紧跟 分组函数 + 参与分组的字段;
- 切记,where后面不能跟分组函数。
- 如果使用了 order by ,order by 必须放到 group by后面;(select语句中,order by 为最后)
【2】按照单个字段分组
- eg1:找出每个工作岗位的最高薪水?涉及
- group by、max(sal)
select job,max(sal) from emp group by job;
- eg2:计算每个工作岗位的最高薪水,并且按照由低到高进行排序?
select job,max(sal) from emp group by job order by max(sal);
- eg3:计算每个部门的平均薪水?
select deptno,avg(sal) from emp group by deptno;
【3】按照多个字段分组
- eg1:计算出不同部门不同岗位的最高薪水,并按照部门排序
select deptno,job,max(sal) from emp group by deptno,job order by deptno;
- eg2:找出每个工作岗位的最高薪水,除MANAGER之外
select job,max(sal) from emp where job<>'MANAGER'group by job;
【4】对分组后的数据进行筛选--having
(1)作用
-
如果想对分组的数据再进行过滤,需要使用having子句。
-
where 和 having 都是为了完成数据的过滤,它们后面都是添加条件;
(2)where 与 having 区别
- where 是在 group by之前完成筛选;
- having 是在 group by 之后完成筛选;
(3)示例
- eg:找出每个工作岗位的平均薪水,要求显示平均薪水大于2000的;
select job,avg(sal) from emp group by job having avg(sal)>2000;
(4)错误示例
- But:以下的写法是错误的!!!
- where关键字后面不能直接使用分组函数,这与SQL语句的执行顺序有关系,它会先执行 from emp,然后再进行 where 条件过滤,where条件过滤结束之后再执行 group by 分组,之后才会显示出查询结果。
select job,avg(sal) from emp where avg(sal) group by job;
(5)注意
- 能够在where在过滤的数据不要放到having中进行过滤,否则影响SQL语句的执行效率。
【5】select语句总结
select ... from ...where ... group by ... having ... order by ...
- 关键字顺序不能变
| 关键字 | 说明 |
|---|---|
| select | 查询需要的字段 |
| from | 从某张表中检索数据 |
| where | 经过条件进行筛选 |
| group by | 根据条件分组 |
| having | 分组后不满意再对数据进行筛选 |
| order by | 排序输出结果 |
【九】连接查询
【1】什么是连接查询?
- 连接查询是指在多个关系表之间进行数据查询的操作,通过使用JOIN关键字将两个或多个表中的数据关联起来,并返回结果集。
【2】根据年代分类
(1)SQL92【1992】
- SQL标准化组织制定的第一个版本的标准SQL语言,发布于1992年。
- 它包括基本的数据类型、SQL语句、集合操作等基本元素,主要用于单个数据库的管理。
(2)SQL99【1999
- SQL标准化组织在1999年发布的第二个版本的标准SQL语言
- 更新了SQL92的许多功能和语法,增加了更多的数据类型和函数,支持更多的数据库系统。
- SQL99新增功能与SQL92比较:
- 更好的完整性约束,如触发器、视图等
- 支持更多复杂的数据类型,如XML、JSON等
- 更强大的事务处理能力,如嵌套事务、隔离级别等
- 更好的性能优化,如索引统计信息、并行执行等
- 更强的安全性,如角色、权限等
- 更新的语法:
- 使用标准的关键字和符号,如GROUP BY、HAVING、UNION ALL等
- 支持更复杂的表达式,如子查询、函数调用等
- 支持更灵活的数据类型转换,如CAST和CONVERT等
- 支持更强大的集合操作,如INTERSECT、EXCEPT等
(3)92语法和99语法的区别
92语法中的from后面多表相互连接是用逗号,后用查询条件是用where。
而99语法中的from后面多表相互连接的是用join,后面查询条件前用 on。
- 在从句中连接表的方式不同,92语法使用逗号分隔,99语法使用JOIN关键字。
- WHERE子句的位置不同,92语法WHERE子句放在最后,99语法WHERE子句可以放在ON子句之前或者之后。
- ON子句的使用不同,92语法没有ON子句,而99语法需要使用ON子句来指定连接条件。
- 不同的集合操作关键字,如92语法使用DISTINCT,而99语法使用GROUP BY。
【3】根据连接方式分类
(1)内连接:
- 等值连接
- 非等值连接
- 自连接
(2)外连接
- 左外连接(左连接)
- 右外连接(右连接)
(3)全连接【很少使用】
- 内连接含义:
- 只连接匹配的行
- 即A表与B表相连接,能够匹配的记录查询出来。
- 外连接含义:
- A表和B表能够完全匹配的记录查询出来之外
- 将其中一张表的记录无条件的完全查询出来
- 对方表没有匹配的记录时,会自动模拟出null值与之匹配;
- 外连接的查询结果条数 >= 内连接的查询结果条数。
❗小知识点:在进行多表连接查询的时候,尽量给表起别名,这样mysql容易识别某个字段具体取自于哪张表。
【4】数据准备
(1)当多张表进行连接查询,若没有任何条件进行限制,会发生什么现象?
select e.ename,d.dname from emp e,dept d;
- 结论:若两张表进行连接查询的时候没有任何条件限制,最终的查询结果总数是两张表记录的乘积,该现在称为笛卡尔积现象。所以在使用表连接时,添加限制条件。
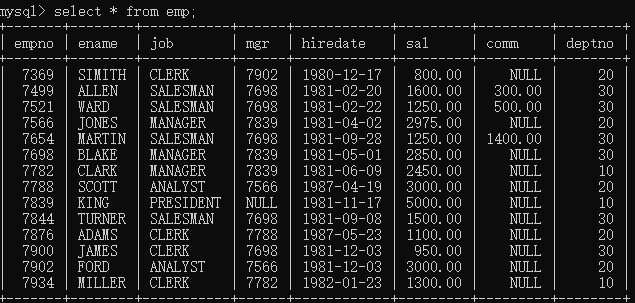
(2)以下为三张表具体信息内容
- emp员工信息表
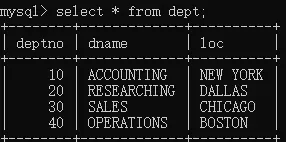
- dept部门信息表
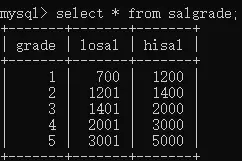
- salgrade工资表
【5】内连接和外连接案例
(1)内连接中的等值连接
- 案例1:查询每一个员工所在的部门名称,要求最终显示员工姓名和对应的部门名称。(两张表查询)
[1]SQL92语法
eg:select e.ename,d.dname from emp e,dept d where e.xx=d.xx
select e.ename,d.dname from emp e**,**dept d where e.deptno=d.deptno;
[2]SQL99语法
select e.ename,d.dname from emp e inner join dept d on e.deptno=d.deptno;
# //inner 可以省略
select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno;
#(重点掌握)
(2)内连接中的非等值连接
- 案例2:找出每一个员工对应的工资等级,要求显示员工姓名、工资、工资等级。(两张表查询)
[1]SQL92语法
select e.ename,e.sal,s.grade from emp e , salgrade s where e.sal between s.losal and s.hisal;
[2]SQL99语法
select e.ename,e.sal,s.grade from emp e inner join salgrade s on e.sal between s.losal and s.hisal;
# //inner 可以省略
select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
# (重点掌握)
(3)内连接中的自连接
-
案例3:找出每一个员工的上级领导,要求显示员工姓名及对应的领导姓名。(一张表查询)
-
92语法和99语法,主要是将join改为逗号,on 改为 where
[1]SQL92语法
select a.ename empname,b.ename leadername from emp a , emp b where a.mgr=b.empno;
[2]SQL99语法
select a.ename empname,b.ename leadername from emp a inner join emp b on a.mgr=b.empno;
# //inner 可以省略
select a.ename empname,b.ename leadername from emp a join emp b on a.mgr=b.empno;
# (重点掌握)
(4)外连接
- 案例4:找出每一个员工对应的部门名称,要求部门名称全部显示。(给表起别名,a为员工表,b为领导表,两张表查询)
- 可以发现员工信息表中的部门编号只有10-30,没有出现40,即要求把部门名称全部显示的话,员工表需要对应空值。
[1]右外连接
select a.ename,a.deptno,b.dname from emp a right outer join dept b on a.deptno=b.deptno;
# //outer可以省略
[2]左外连接
select a.ename,a.deptno,b.dname from dept b left outer join emp a on a.deptno=b.deptno;
[3]补充案例
- 案例5:找出每一个员工对应的领导名,要求显示所有员工。
select a.ename empname,b.ename leadername from emp a left outer join emp b on a.mgr=b.empno;
# //outer可省略
- 案例6:找出每一个员工对应的部门名称,以及该员工对应的工资等级,要求显示员工姓名、部门名、工资,工资等级。(三张表查询,以下自设表别名,a为员工表,b为部门表,c为工资等级表)
select a.ename,b.dname,a.sal,c.grade from emp a join dept b on a.deptno=b.deptno join salgrade c on a.sal between c.losal and c.hisal;
注意:使用多张表查询时,from后面可跟多个join ,join前面的表跟后面的表分别建立连接。
[4]为什么 inner 和 outer 可以省略,加上去有什么好处?
- 可以省略,因为区分内连接与外连接不是依靠这两个关键字,而是看SQL语句中的left/right关键字;
- 加上left、right关键字增强SQL语句的可读性。
【6】多张表进行表连接的语法格式
select ... from A表 join B表 on 连接条件1 join C表 on 连接条件2;
- 原理:A表和B表通过连接条件1连接之后,A表再和C表通过连接条件2进行连接;
【十】子查询
【1】含义
select 语句嵌套 select 语句。
【2】关键字语法
- select子句可出现在select、from、where关键字后面
select … (select)…
from …(select)…
where …(select)…
【3】子查询--出现在where后面
-
案例1:找出薪水比公司平均薪水高的员工,要求显示员工名和薪水
-
having也可以用where。
-
这里需要注意的是,where后面不能直接跟分组函数,所以需要分开写;
-
下面另一种方法,可以用一行代码即可查询出来---where后面的子查询。
(1)方式一
select avg(sal) from emp;
select ename,sal from emp having sal>2073.214286;
(2)方式二
select ename,sal from emp where sal>(select avg(sal) from emp);
【4】子查询--出现在from后面
- 案例2:找出每个部门的平均薪水,并且要求显示平均薪水的薪水等级
(1)解决思路
- 第一步,找出每个部门的平均薪水。
select deptno,avg(sal) as avgsal from emp group by deptno;
- 第二步,将上面的查询结果当做临时表t,t表和salgrade s 表进行表连接
- 条件:t.avg(sal) between s.losal and s.hisal (t.avg(sal)要重命名,因为avg本意为分组函数)
select t.deptno,t.avgsal,s.grade from salgrade s join t on t.avgsal between s.losal and s.hisal;
以上如果直接粘贴到mysql,会显示t表不存在,所以,将第一步的看成一个整体,粘贴到 from后面的t表前面。
(2)正确代码
select
t.deptno,t.avgsal,s.grade
from
salgrade s
join
(select deptno,avg(sal) as avgsal from emp group by deptno) t
on
t.avgsal between s.losal and s.hisal;
select t.deptno, t.avgsal, s.grade from ( select avg(sal) as avgsal,deptno from emp group by deptno) t join salgrade s on t.avgsal between s.losal and s.hisal;
【5】总结
- PS:主要是根据现有的数据信息,利用子查询转换成想要的数据信息。
【错误总结】
【1】命令行进入MySQL报错
(1)问题说明
- 通过windows自带的客户端【cmd窗口进入】打开出现错误
ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: NO)
(2)解决办法
- 则需要添加环境变量,操作如下:
- 右击计算机属性
- 点击高级系统设置
- 选中系统变量Path路径
- 然后点击编辑—添加mysql所在的路径(路径到bin截止)
- 上面的用户名变量新建
- 变量名:path
- 变量值:C:\Program Files\MySQL\MySQL Server 8.0\bin
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17995450

 浙公网安备 33010602011771号
浙公网安备 33010602011771号