【补充】数据库的三大范式
【面试题】数据库的三大范式
参考博客:数据库的范式设计
【什么是范式】
-
范式就是我们在设置数据库的表时,一些共同需要遵守的规范
-
掌握这些设计时的范式,可以让我们在项目之初,设计库的表结构更加合理和优雅
【三大范式之间的关系】
-
三大范式之间,是逐级递进的关系,也就是说后一个范式是在前一个范式的基础上推行。
-
我们举一个形象的例子来说
- 我们吃饭的时候
- 第一步是买菜
- 第二步是炒菜
- 第三步才是吃菜
-
这三者之间不能颠倒,后者都是建立在前者之上的,顺序不能颠倒。
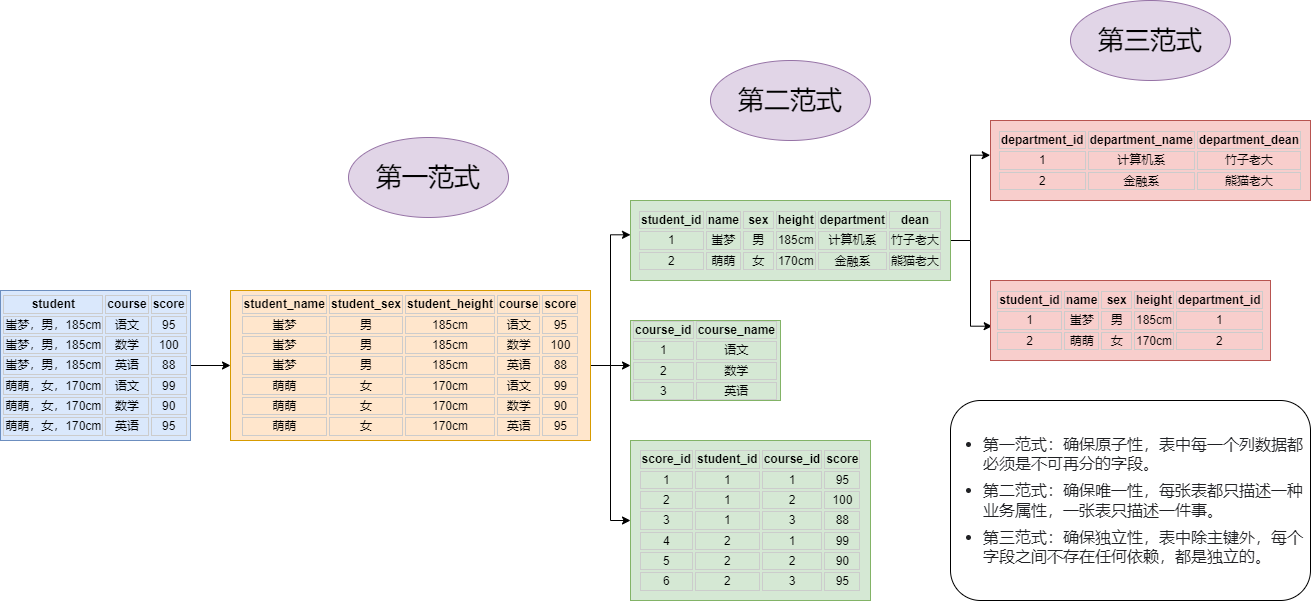
【1NF】第一范式
【0】什么是第一范式
- 表库设计时,主要是为了确保原子性,也就是存储的数据具有不可再分性。
- 注意
- 这里的原子性不等同于MySQL特点中的原子性
- MySQL特性之原子性
- 指事务是操作数据库的基本单位,要么全部执行成功,要么全部失败回滚
- 这样做确保了数据库在任何情况下都能保持一致的状态,不会出现中间数据
- 第一范式的原子性
- 指一个字段不可再分割,其中不能包含其他更小的数据单元
- 也就是说,一个字段的数据不能再被进一步分解为更小的数据单元
- 为了更好的理解上述所说的原子性,我们以一个例子来说明
【1】基表
- 比如我们有一张 student 表
- 表结构和内容如下
+----------------------+--------+-------+
| student | course | score |
+----------------------+--------+-------+
| 蚩梦,男,185cm | 语文 | 95 |
| 蚩梦,男,185cm | 数学 | 100 |
| 蚩梦,男,185cm | 英语 | 88 |
| 萌萌,女,170cm | 语文 | 99 |
| 萌萌,女,170cm | 数学 | 90 |
| 萌萌,女,170cm | 英语 | 95 |
+----------------------+--------+-------+
| student | course | score |
|---|---|---|
| 蚩梦,男,185cm | 语文 | 95 |
| 蚩梦,男,185cm | 数学 | 100 |
| 蚩梦,男,185cm | 英语 | 88 |
| 萌萌,女,170cm | 语文 | 99 |
| 萌萌,女,170cm | 数学 | 90 |
| 萌萌,女,170cm | 英语 | 95 |
- 在上述的学生表中,有一个字段是
student,我们可以明显的看出,它不符合我们规定的第一范式要求- 即一个字段的数据不能再被进一步分解为更小的数据单元
student这一列的数据仍然可以再继续拆分成姓名、性别和身高三个字段
【2】基于第一范式优化
+--------------+-------------+----------------+--------+-------+
| student_name | student_sex | student_height | course | score |
+--------------+-------------+----------------+--------+-------+
| 蚩梦 | 男 | 185cm | 语文 | 95 |
| 蚩梦 | 男 | 185cm | 数学 | 100 |
| 蚩梦 | 男 | 185cm | 英语 | 88 |
| 萌萌 | 女 | 170cm | 语文 | 99 |
| 萌萌 | 女 | 170cm | 数学 | 90 |
| 萌萌 | 女 | 170cm | 英语 | 95 |
+--------------+-------------+----------------+--------+-------+
| student_name | student_sex | student_height | course | score |
|---|---|---|---|---|
| 蚩梦 | 男 | 185cm | 语文 | 95 |
| 蚩梦 | 男 | 185cm | 数学 | 100 |
| 蚩梦 | 男 | 185cm | 英语 | 88 |
| 萌萌 | 女 | 170cm | 语文 | 99 |
| 萌萌 | 女 | 170cm | 数学 | 90 |
| 萌萌 | 女 | 170cm | 英语 | 95 |
- 将
student字段拆分成三个字段后,我们可以明显的发现存储结构的设计更为合理和优雅 - 通过上述优化后,此时 这张表 符合了 第一范式的规范
【3】如果不去拆分列满足第一范式,会造成什么影响呢?
-
首先,就是我们录入的数据无法和数据库中的表形成合理和明确的一一对应关系
-
其次,当我们将表中的数据查询到时,我们仍然需要对我们查到的数据进行额外拆分优化
-
最后,在我们插入数据的时候,我们要按照数据库中的数据格式进行拼装存储
-
简单来书,我们使用不符合第一范式的表结构去做业务开发时,操作会比较麻烦一些,当我们进行符合第一范式的二次设计后,虽然表的字段变多了,但是数据结构变得清晰了很多
【4】第一范式(1NF)小结
- 第一范式,我们通常也叫 1NF
- 第一范式要求我们必须遵守原子性
- 即数据库表的每一列都是不可分割
- 每列的值具有原子性,不可再分割
- 每个字段的值都只能是单一值
- 即数据库表的每一列都是不可分割
【2NF】第二范式
【0】什么是第二范式
-
首先第二范式是在满足第一范式的基础上
- 第一范式我们已经能够理解了,那么我们再来看看第二范式
-
第二范式要求表中的所有列,其数据依赖于主键
- 即一张表只存储同一类型的数据,不能有任何一列数据与主键没有关系
【1】第一范式基表
- 表结构如下
+--------------+-------------+----------------+--------+-------+
| student_name | student_sex | student_height | course | score |
+--------------+-------------+----------------+--------+-------+
| 蚩梦 | 男 | 185cm | 语文 | 95 |
| 蚩梦 | 男 | 185cm | 数学 | 100 |
| 蚩梦 | 男 | 185cm | 英语 | 88 |
| 萌萌 | 女 | 170cm | 语文 | 99 |
| 萌萌 | 女 | 170cm | 数学 | 90 |
| 萌萌 | 女 | 170cm | 英语 | 95 |
+--------------+-------------+----------------+--------+-------+
【2】基于第二范式优化
(0)引入
- 虽然上述的表结构已经满足了数据库的第一范式
- 但我们也能明显的看到
course和score这两列数据,跟前面的几列数据实际上依赖并不大 - 并且这样的表结构也导致了前面几列的数据出现了大量冗余
- 那我们再对边结构进行优化
(1)结构优化
- 表一:
student
+------------+--------+------+--------+--------------+--------------+
| student_id | name | sex | height | department | dean |
+------------+--------+------+--------+--------------+--------------+
| 1 | 蚩梦 | 男 | 185cm | 计算机系 | 竹子老大 |
| 2 | 萌萌 | 女 | 170cm | 金融系 | 熊猫老大 |
+------------+--------+------+--------+--------------+--------------+
| student_id | name | sex | height | department | dean |
|---|---|---|---|---|---|
| 1 | 蚩梦 | 男 | 185cm | 计算机系 | 竹子老大 |
| 2 | 萌萌 | 女 | 170cm | 金融系 | 熊猫老大 |
- 表二:
course
+-----------+-------------+
| course_id | course_name |
+-----------+-------------+
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
+-----------+-------------+
| course_id | course_name |
|---|---|
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英语 |
- 表三:
score
+----------+------------+-----------+-------+
| score_id | student_id | course_id | score |
+----------+------------+-----------+-------+
| 1 | 1 | 1 | 95 |
| 2 | 1 | 2 | 100 |
| 3 | 1 | 3 | 88 |
| 4 | 2 | 1 | 99 |
| 5 | 2 | 2 | 90 |
| 6 | 2 | 3 | 95 |
+----------+------------+-----------+-------+
| score_id | student_id | course_id | score |
|---|---|---|---|
| 1 | 1 | 1 | 95 |
| 2 | 1 | 2 | 100 |
| 3 | 1 | 3 | 88 |
| 4 | 2 | 1 | 99 |
| 5 | 2 | 2 | 90 |
| 6 | 2 | 3 | 95 |
(3)小结
- 进过上述结构优化后,原来的
student表 被我们拆分成了三张表- 分别是
student、course、score三张表
- 分别是
- 每一张表中的
id字段作为自己的主键,其他字段都依赖于自己的主键 - 无论是哪张表都可以通过
id字段确定其他字段的值
【3】主键可以不用id,但最好是自增的主键ID,这跟索引有关
- 我们再细看经过优化后的三张表
- 原来的学生表有 6 条记录,其中 4 条是冗余数据
- 现在的学生表有 2 条记录,同时这张表只存储学生信息
- 经过这次优化后,每一张表都有了各自的业务属性,都具有了
唯一性- 也就是每张表只
描述一件事 - 不会存在一张表中会出现两个及以上业务属性
- 例如之前的学生表存储了学生信息和课程信息
- 也就是每张表只
【4】第二范式(2NF)小结
- 第二范式,我们通常也叫 2NF
- 第二范式(2NF)是在第一范式(1NF)的基础上建立起来得
- 满足第二范式(2NF)必须先满足第一范式(1NF)
- 第一范式要求我们必须遵守原子性
- 第二范式要求表中的所有列,其数据依赖于主键
- 即一张表只存储同一类型的数据,不能有任何一列数据与主键没有关系
- 如果表是单主键,那么主键以外的列必须完全依赖于主键,其它列需要跟主键有关系
- 如果表是复合主键,那么主键以外的列必须完全依赖于主键,不能仅依赖主键的一部分
- 即一张表只存储同一类型的数据,不能有任何一列数据与主键没有关系
【3NF】第三范式
【0】什么是第三范式
-
首先第三范式是在满足第二范式的基础上
- 第二范式我们已经能够理解了,那么我们再来看看第三范式
-
第三范式要求表中每一列数据不能与主键之外的字段有直接关系
- 表中的非主键列必须和主键直接相关而不能间接相关
- 非主键列之间不能相关依赖,不存在传递依赖
【1】第二范式基表
+------------+--------+------+--------+--------------+--------------+
| student_id | name | sex | height | department | dean |
+------------+--------+------+--------+--------------+--------------+
| 1 | 蚩梦 | 男 | 185cm | 计算机系 | 竹子老大 |
| 2 | 萌萌 | 女 | 170cm | 金融系 | 熊猫老大 |
+------------+--------+------+--------+--------------+--------------+
【2】基于第三范式优化
(1)引入
- 我们以学生表为例,学生表目前符合第一范式和第二范式。
- 但是我们观察后面两个字段
department相当于当前学生所属的院校dean相当于院系的院长
- 一般来说,一个学生的院长是谁取决于学生所在的院系
- 因此,最后的
dean字段与department字段明显存在依赖关系
- 因此,最后的
(2)结构优化
department
+---------------+-----------------+-----------------+
| department_id | department_name | department_dean |
+---------------+-----------------+-----------------+
| 1 | 计算机系 | 竹子老大 |
| 2 | 金融系 | 熊猫老大 |
+---------------+-----------------+-----------------+
| department_id | department_name | department_dean |
|---|---|---|
| 1 | 计算机系 | 竹子老大 |
| 2 | 金融系 | 熊猫老大 |
student
+------------+--------+------+--------+---------------+
| student_id | name | sex | height | department_id |
+------------+--------+------+--------+---------------+
| 1 | 蚩梦 | 男 | 185cm | 1 |
| 2 | 萌萌 | 女 | 170cm | 2 |
+------------+--------+------+--------+---------------+
| student_id | name | sex | height | department_id |
|---|---|---|---|---|
| 1 | 蚩梦 | 男 | 185cm | 1 |
| 2 | 萌萌 | 女 | 170cm | 2 |
(3)小结
- 经过上述优化后,我们又将学生表拆成了 学生表 和 院系表 。
- 学生表只存储一个院系对应的
ID - 院系表存储院系相关的数据
- 学生表只存储一个院系对应的
- 通过以上优化,我们可以发现
- 学生表中的每个非主键字段与其他非主键字段之间都是相互独立的
- 彼此之间不存在任何依赖关系
- 所有的字段都依赖于主键
【3】如果不调整表结构会如何?
- 如果不调整上述结构,那么我们在操作数据表的时候就会发生如下问题
- 当一个院系院长换人后,需要修改学生信息表中的每一条数据
- 当一个院长离职后,需要删除院长的相关数据,包括学生表中的相关数据
- 由此,会引发很多意料之外的错误和数据异常,让整张表较难维护
【4】第三范式(3NF)小结
-
第三范式,我们通常也叫 3NF
- 第三范式(3NF)是在第二范式(2NF)的基础上建立起来得
- 满足第三范式(3NF)必须先满足第二范式(2NF)
-
第一范式要求我们必须遵守原子性
-
第二范式要求表中的所有列,其数据依赖于主键
- 即一张表只存储同一类型的数据,不能有任何一列数据与主键没有关系
- 如果表是单主键,那么主键以外的列必须完全依赖于主键,其它列需要跟主键有关系
- 如果表是复合主键,那么主键以外的列必须完全依赖于主键,不能仅依赖主键的一部分
- 即一张表只存储同一类型的数据,不能有任何一列数据与主键没有关系
-
第三范式要求表中每一列数据不能与主键之外的字段有直接关系
- 表中的非主键列必须和主键直接相关而不能间接相关
- 非主键列之间不能相关依赖,不存在传递依赖
【数据库三范式小结】
-
到这里就已经将库表设计的三范式做了直观阐述,总结如下:
-
第一范式:确保原子性,表中每一个列数据都必须是不可再分的字段。
-
第二范式:确保唯一性,每张表都只描述一种业务属性,一张表只描述一件事。
-
第三范式:确保独立性,表中除主键外,每个字段之间不存在任何依赖,都是独立的。
-
- 经过三范式的示例后,数据库中的表数量也逐渐多了起来,似乎设计符合三范式的库表结构,反而更加麻烦了对吗?
- 答案并非如此,因为在没有按照范式设计时,会存在几个问题:
- 整张表数据比较冗余,同一个学生信息会出现多条。
- 表结构特别臃肿,不易于操作,要新增一个学生信息时,需添加大量数据。
- 需要更新其他业务属性的数据时,比如院系院长换人了,需要修改所有学生的记录。
- 但按照三范式将表结构拆开后
- 假设要新增一条学生数据,就只需要插入学生相关的信息即可
- 同时如果某个院系的院长换人了,只需要修改院系表中的院长就行,学生表中的数据无需发生任何更改。
- 经过三范式的设计优化后,整个库中的所有表结构,会显得更为优雅,灵活性也会更强
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17995448

