【5.0】SQL语句操作MySQL数据库基础
【一】针对库的增删改查(文件夹)
【1】创建数据库
(1)语法
- 在磁盘上创建一个存储数据表的文件夹。
create database [if not exists] 数据库名 [character set 编码字符集];
- 注意:mysql中的编码字符集中utf-8,要换成utf8mb4。SQL语句中的中括号部分表示可选。
(2)示例
create databases db1;
# 设置库的默认编码create databases db1 charset='gbk';
【2】查看数据库
(1)语法
show databases; -- 查看所有数据库show databases like '%test%'; -- 查看名字中包含test的数据库 show create database 数据库名; -- 查看数据库的建库sql语句
(2)示例
# 查看所有库show databases; # 查看指定库 show create database db1;
【3】修改数据库
(1)语法
alter database 数据库名 [character set 编码字符集];
(2)示例
alter database db2 charset='utf8';
【4】删库
(1)语法
drop database [if exists] 数据库名;
(2)示例
drop database db2;
【二】针对表的增删改查(文件)
在操作表的时候要指定所在的库
【1】查看当前所在库的名字
(1)语法
select database(); -- 查看当前使用的数据库
(2)示例
select database();
【2】切换到指定库
(1)语法
use 数据库名; -- 切换数据库
(2)示例
use database db1;
切换数据库 注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
【3】创建表
- 数据表就相当于文件,文件有文件名,自然地,数据表也要有表名。
- 同样道理,数据表中的一条记录就相当于文件的一行内容。
- 只是不同的是,数据表需要定义表头(上图中的首行),称为表的字段名。
- 而且因为数据库的存储数据更加科学、严谨,所以需要创建表时要给每一个字段设置数据类型以及字段约束(完整性约束条件)。
(1)语法
create table [if not exists] 表名 (字段名1 数据类型[ ( 存储空间 ) 字段约束 ], 字段名2 数据类型[ ( 存储空间 ) 字段约束 ], 字段名3 数据类型[ ( 存储空间 ) 字段约束 ], ..... 字段名n 数据类型[ ( 存储空间 ) 字段约束 ], primary key(一个 或 多个 字段名) -- 注意,最后一段定义语句,不能有英文逗号的出现,否则报错。 ) [engine = 存储引擎 character set 字符集];
-
注意:
-
上面SQL语句中,小括号中的定义字段语句后面必须以英文逗号结尾,而最后一个字段的定义语句不能有英文逗号出现,否则报错。
-
在同一张数据表中,字段名是不能相同,否则报错!
-
创建数据表的SQL语句中,存储空间和字段约束是选填的,而字段名和数据类型则是必须填写的。
-
(2)示例
创建表指定字段
-- mysql中创建数据表要以 create table `表名`-- 表的字段信息必须写在 ( ) 小括号里面 create table classes ( -- 建议一行一个字段,id 就是字段名 -- int 表示设置字段值要以整数的格式保存到硬盘中, -- auto_increment表示当前字段值在每次新增数据时自动+1作为值保存 -- primary key,mysql中叫主键,表示用于区分一个数据表中不同行的数据的唯一性,同时还具备加快查询速度的作用 -- 注意:auto_increment与primary key 一般是配合使用的,对应的字段名一般也叫id,而且在一个数据表中只有一个字段能使用auto_increment primary key进行设置。 id int auto_increment primary key, -- 字段名:name -- varchar(10) 表示当前name这一列可以存储的数据是字符串格式,并且最多只能存10个字符 name varchar(10), -- 字段名:address -- varchar(100) 表示adderss这一列可以存储的数据是字符串格式,并且最多只能存100个字符 address varchar(100), -- 字段名:total -- int 表示当前total这一列的数据只能是整数,而且一个数据表中,整数的最大范围只能是42亿 total int );
- 上面的SQL语句就相当于创建了一个表格。
| id | name | address | total |
|---|---|---|---|
(3)练习一:创建学生表
create table student(id int auto_increment, -- 字段名:id,数据类型:int整型,auto_increment整数自动增长+1 name varchar(10), -- 字段名:name, 数据类型:varchar字符串(长度限制最多10个字符) sex int default 1, -- 字段名:sex,数据类型:int整型,默认值(default):1 相当于True classes int, -- 字段名:classes, 数据类型:int整型, age int, -- 字段名:age,数据类型:int整数, description text, -- 字段名:description,数据类型:text文本 primary key (id) -- 设置主键(id) 每个表必须都有主键,用以区分不同行的数据 );
(4)练习二:创建课程表
- 假设现在我们有一个课程表(courses),
- 里面需要保存课程编号(id),课程名(cource),授课老师(lecturer),教室(address)。
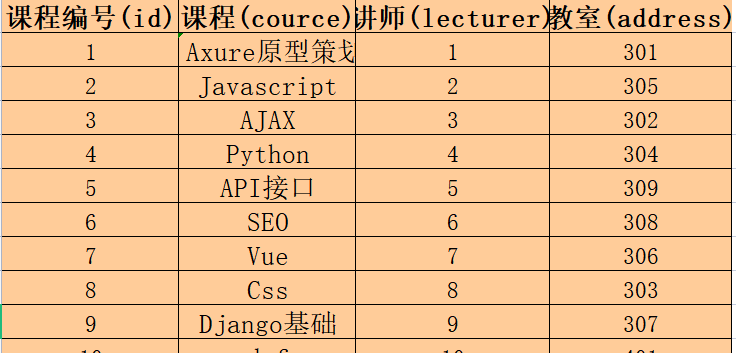
create table courses (id int auto_increment primary key comment "课程编号", course varchar(50) comment "课程名称", lecturer int comment "讲师编号", address int comment "教室编号" );
【4】查看当前库下面的所有表
(1)查看所有的表
- 列出当前数据库中所有的数据表
show tables;
(2)查看指定的表
show create table 表名;
(3)查看当前表的详细信息
- 以表格形式列出当前数据表的结构信息
describe 表名;
- 查看当前表的详细信息(简写)
desc t1;
(4)查看建表语句
show create table 表名 \G;
【5】修改表
(1)修改表的字段类型
- modify(只能改类型不能改名字)
alter table 表名 modify 字段名 字段类型(宽度);
- change(名字类型都可)
alter table 表名 change 字段名 字段类型(宽度);
(2)修改表名字重命名
alter table 原表名 rename 新表名;
(3)添加字段
- 默认是尾部追加字段
alter table 表名 add 字段名 字段类型;
- 指定追加位置
alter table 表名 add 字段名 字段类型 after 原字段名;
- 指定头部添加字段
alter table 表名 add 字段名 字段类型 first;
(4)删除字段
alter table 表名 drop 字段名;
【6】删除表
- 删除表结构,并把数据一并删除,
- 使用需谨慎,强烈建议先备份后删除,或者直接改表名来代替删除操作。
(1)语法
drop table 表名;
(2)示例
drop table t1;
(3)特别提示
-
使用 DROP DATABASE 命令时要非常谨慎,
-
在执行该命令后,MySQL 不会给出任何提示确认信息。
-
DROP DATABASE 删除数据库后,数据库中存储的所有数据表和数据也将一同被删除,而且不能恢复。
-
因此最好在删除数据库之前先将数据库进行备份。
【7】以绝对路径的形式操作不同的库
create table db2.t1(id int);
【8】重置表信息
- 保留数据表结构,但是把数据表存储的数据以及数据表的状态回滚,
- 相当于删除原表,并新建一张一模一样的空数据表。
TRUNCATE table 表名;
【三】针对数据的增删改查(一行行数据)
操作数据要有明确的数据库下的数据表
【1】数据的增加
(1)语法
- INSERT…VALUES 语句
INSERT [INTO] <表名> [ <列名1> [ , … <列名n>] ] VALUES (值1) [… , (值n) ];
- 指定需要插入数据的列名。若向表中的所有列插入数据,则全部的列名均可以省略,直接采用 INSERT<表名>VALUES(…) 即可。
- INSERT 语句后面的列名称顺序可以不是 表定义时的顺序,即插入数据时,不需要按照表定义的顺序插入,只要保证值的顺序与列字段的顺序相同就可以。
- 使用 INSERT…VALUES 语句可以向表中插入一行数据,也可以插入多行数据;
- 插入多行数据
INSERT [INTO] <表名> [ <列名1> [ , … <列名n>] ] VALUES (值1…,值n),(值1…,值n), ... (值1…,值n); -- 用单条 INSERT 语句处理多个插入要比使用多条 INSERT 语句更快。
(2)示例
# 插入单条数据insert into t1 values(1,'dream'); # 插入多条数据 insert into t1 values(1,'dream')(2,'chimeng');
(3)练习
INSERT employee (name,gender,birthday,salary,department) VALUES("dream",1,"1985-12-12",8000,"教学部"), ("hope",1,"1987-08-08",5000,"保安部"), ("meng",1,"1990-06-06",20000,"销售部");
(4)练习
- 建表
CREATE TABLE emp(id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), gender ENUM("male","female","other"), age TINYINT, dep VARCHAR(20), city VARCHAR(20), salary DOUBLE(7,2) )character set=utf8;
- 插入单条数据
insert into user(name, age, selary) values('lisi', 18, 100);
- 插入多条数据
insert into user(name, age, selary) values('lisi', 18, 100), ('wan', 18, 100), ('wu', 18, 100);
- 批量添加信息
INSERT INTO emp (name,gender,age,dep,city,salary) VALUES("yuan","male",24,"教学部","河北省",8000), ("eric","male",34,"销售部","山东省",8000), ("rain","male",28,"销售部","山东省",10000), ("alvin","female",22,"教学部","北京",9000), ("George", "male",24,"教学部","河北省",6000), ("danae", "male",32,"运营部","北京",12000), ("Sera", "male",38,"运营部","河北省",7000), ("Echo", "male",19,"运营部","河北省",9000), ("Abel", "female",24,"销售部","北京",9000);
【2】数据的查看
数据量大的时候不建议使用
数据会冲击服务器导致瘫痪
(1)语法
SELECT *|field1,filed2 ... FROM tab_nameWHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数
- Mysql在执行sql语句时的执行顺序:
-- from where select group by having order by
(2)示例
# 查看全部数据select * from t1 # 根据指定字段查看数据 select name from t1;
【3】数据的更改
# 以限定调价修改指定字段的数据update t1 set name='mengmeng' where id > 1;
【4】删除数据
# 删除指定字段的数据delete from t1 where id > 1; # 删除指定字段的数据 delete from t1 where name='dream'; # 清空当前表的所有数据 delete from t1;
__EOF__

本文作者:Chimengmeng
本文链接:https://www.cnblogs.com/dream-ze/p/17995405.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/dream-ze/p/17995405.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17995405


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!