【1.0】数据库初识
【一】存储数据的演变过程
【1】文件存储
- 在早期,随意地存放到一个文件中、数据格式也是千差万别的,完全取决于个人
【2】软件开发目录规范
(1)概要
- 限制了存储数据的具体位置
- 建立专门的文件夹存储数据
(2)软件开发目录规范
- bin:主要存放主程序文件,例如main.py;
- conf:主要存放配置文件,例如settings.py;
- lib:主要存放公用函数或类库,例如common.py;
- core:主要存放核心模块代码,例如src.py;
- interface:主要存放用户界面代码,例如interface.py;
- db:主要存放数据库模块和操作脚本,例如moduls.py和db_hander.py;
- log:主要存放日志文件,例如logs.log;
- README.md:主要存放项目说明文档。
(3)数据存储在本地
- 假设上面是一个游戏
- 每一个人的游戏数据只会保存在本地
- 注册登录账号也只能在本地有效
(4)单机变成联网
- 然而,在现代互联网环境下,单机模式已经不能满足需求,需要将数据库服务端建立起来,将数据库保存部分统一到一个位置。
- 所有的数据操作都会经过这个总的数据库。
- 这样不仅可以实现数据共享,还可以保证数据的安全性和稳定性。
- 同时,也可以通过增加服务器集群等方式,提高系统的性能和可扩展性。
【二】数据库的本质
- 数据库其实就是一块基于网络通信的应用程序
- 每个人都有开发一块数据库的能力
【三】数据库的介绍
【1】关系型数据库
- MySQL
- Oracle
- db2
- access
- sql server
这些数据库都采用关系模型来组织数据,并且支持SQL查询语言。
【2】非关系型数据库
- Redis
- MongoDB
- Memcached
这些数据库不采用关系模型来组织数据,而是采用了其他的模型,例如键值对模型、文档模型、图形模型等。
【3】关系型(存储数据)
- 彼此之间有关联
- 存储数据的表型形式通常以表格形式存储
- 每个字段限制每个字段下的存储数据的格式例如字符串、数字、日期等。
- 同时,关系型数据库还支持各种数据操作,例如插入、删除、更新和查询等。
【4】非关系型(缓存数据)
- 存储数据通常是
K:V形式存储数据 - 非关系型数据库通常用于存储临时性的、高速访问的数据,这些数据通常以键值对的形式存储,其中“键”表示数据的唯一标识,“值”表示实际的数据内容。
- 由于非关系型数据库通常不提供事务支持和复杂的查询功能,因此不适合存储长期保存的历史数据。
【四】数据库的应用场景
【1】需求
- 假设现在你已经是某大型互联网公司的高级程序员,让你写一个火车票购票系统,来hold住十一期间全国的购票需求,你怎么写?
- 在同一时段抢票的人数如果太多,那么你的程序不可能运行在一台机器上,应该是多台机器一起分担用户的购票请求。
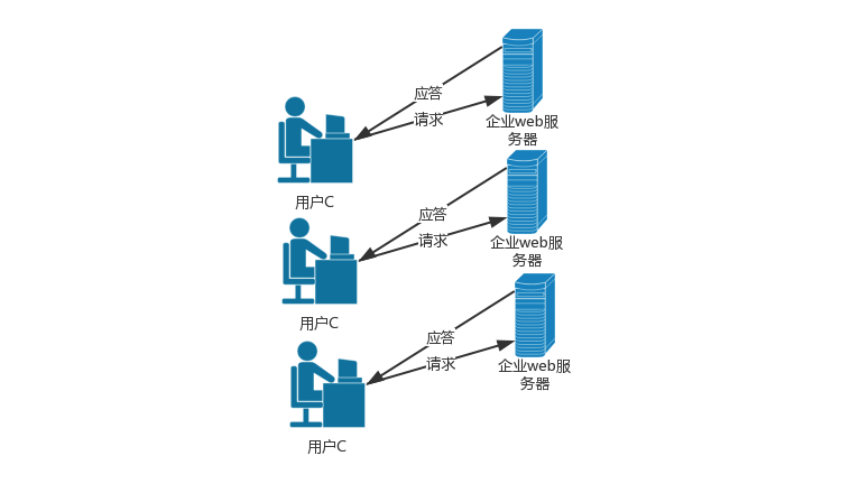
【2】实现需求
- 那么问题就来了,票务信息的数据存在哪里?存在文件里么?
- 如果存储在文件里,那么存储在哪一台机器上呢?是每台机器上都存储一份么?
- 首先,如果其中一台机器上卖出的票另外两台机器是感知不到的,
- 其次,如果我们将数据和程序放在同一个机器上,如果程序和数据有一个出了问题都会导致整个服务不可用。
- 最后,操作或修改文件中的内容对python代码来说是一件很麻烦的事。
- 基于上面这些问题,单纯的将数据存储在和程序同一台机器上的文件中是非常不明智的。
- 根据上面的例子,我们可以知道,将文件和程序存在一台机器上是很不合理的,同时,操作文件是一件很麻烦的事,所以我们可以使用数据库来存储数据。
__EOF__

本文作者:Chimengmeng
本文链接:https://www.cnblogs.com/dream-ze/p/17995395.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/dream-ze/p/17995395.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17995395


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)