【12.0】Fastapi中的数据库SQLAlchemy ORM 操作
【一】大型项目结构树
coronavirus
├─static # 静态文件
├─templates # 前端页面
├─__init__.py # 初始化文件
├─database.py # 数据库操作
├─models.py # 数据库表模型类
├─schemas.py # 响应体模型类
├─curd.py # 视图函数
└─main.py # 主程序启动入口
【1】创建数据库句柄(database.py)
- 创建链接数据库
- 创建链接数据库对象
- 建立数据库连接
【2】定义数据库字段(models.py)
- 定义数据库字段
- 数据库字段属性
【3】定义响应数据格式(schemas.py)
- 根据数据库的字段和属性
- 定义返回的响应体数据字段及格式和属性
【4】封装数据库操作(curd.py)
- 书写数据库的相关操作并进行封装
- 增删查改
【5】书写视图逻辑(main.py)
- 书写视图函数的相关逻辑
【二】创建数据库句柄(database.py)
coronavirus\database.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
# 定义数据库链接对象
SQLALCHEMY_DATABASE_URL = 'sqlite:///./coronavirus.sqlite3'
# mysql 数据库 或 postgresql 数据库的链接方法
# SQLALCHEMY_DATABASE_URL = 'postgresql://username:password@host:port/database_name'
# 定义引擎
engine = create_engine(
# 数据库地址
SQLALCHEMY_DATABASE_URL,
# 编码
encoding='utf-8',
# echo=True表示引擎将用repr()函数记录所有语句及其参数列表到日志
echo=True,
# 由于SQLAlchemy是多线程,指定check_same_thread=False来让建立的对象任意线程都可使用。
# 这个参数只在用SQLite数据库时设置
connect_args={"check_same_thread": False}
)
# 在SQLAlchemy中,CRUD都是通过会话(session)进行的,所以我们必须要先创建会话,每一个SessionLocal实例就是一个数据库session
# flush()是指发送数据库语句到数据库,但数据库不一定执行写入磁盘;
# commit()是指提交事务,将变更保存到数据库文件
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, expire_on_commit=True)
# 创建基本映射类 -- 生成数据库
Base = declarative_base(bind=engine, name='Base')
【三】定义数据库字段(models.py)
coronavirus\models.py
from sqlalchemy import Column, String, Integer, BigInteger, Date, DateTime, ForeignKey, func
from sqlalchemy.orm import relationship
from .database import Base
class City(Base):
# 数据库表名
__tablename__ = 'city'
# 定义主键 ID : 数字类型 主键 索引 自增
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
# 定义省份字段 : 字符串类型(长度) 唯一 是否可为空 注释
province = Column(String(100), unique=True, nullable=False, comment="省/直辖市")
# 定义国家字段 : 字符串类型(长度) 是否可为空 注释
country = Column(String(100), nullable=False, comment="国家")
# 定义国家代码字段 : 字符串类型(长度) 是否可为空 注释
country_code = Column(String(100), nullable=False, comment="国家代码")
# 定义国家人口字段 : 大整数类型 是否可为空 注释
country_population = Column(BigInteger, nullable=False, comment="国家人口")
# 'Data'是关联的类名;back_populates来指定反向访问的属性名称
data = relationship("Data", back_populates='city')
# 定义字段创建时间 : 时间类型 当数据创建或者更新时自动更新时间 注释
created_at = Column(DateTime, server_default=func.now(), comment='创建时间')
updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now(), comment='更新时间')
# 根据 country_code 排序 默认是正序,倒序加上.desc()方法(country_code.desc())
__mapper_args__ = {"order_by": country_code}
# 显示类对象的信息
def __repr__(self):
return f'{self.country}_{self.province}'
class Data(Base):
# 表名
__tablename__ = 'data'
# 定义主键 ID : 数字类型 主键 索引 自增
id = Column(Integer, primary_key=True, index=True, autoincrement=True)
# 定义外键字段 关联国家ID : 数字类型 外键关联(表.字段) 注释
# ForeignKey里的字符串格式不是类名.属性名,而是表名.字段名
city_id = Column(Integer, ForeignKey('city.id'), comment='所属省/直辖市')
# 定义字段 日期 : 数字类型 是否可为空 注释
date = Column(Date, nullable=False, comment='数据日期')
# 定义字段 确诊数 : 大数字类型 默认值 是否可为空 注释
confirmed = Column(BigInteger, default=0, nullable=False, comment='确诊数量')
# 定义字段 死亡数 : 大数字类型 默认值 是否可为空 注释
deaths = Column(BigInteger, default=0, nullable=False, comment='死亡数量')
# 定义字段 痊愈数 : 大数字类型 默认值 是否可为空 注释
recovered = Column(BigInteger, default=0, nullable=False, comment='痊愈数量')
# 'City'是关联的类名;back_populates来指定反向访问的属性名称
city = relationship('City', back_populates='data')
# 定义字段创建时间 : 时间类型 当数据创建或者更新时自动更新时间 注释
created_at = Column(DateTime, server_default=func.now(), comment='创建时间')
updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now(), comment='更新时间')
# 根据 country_code 排序 默认是正序,倒序加上.desc()方法
__mapper_args__ = {"order_by": date.desc()} # 按日期降序排列
# 显示类对象的信息
def __repr__(self):
return f'{repr(self.date)}:确诊{self.confirmed}例'
- 补充 SQLAlchemy教程 参考
- SQLAlchemy的基本操作大全
- Python3+SQLAlchemy+Sqlite3实现ORM教程
- SQLAlchemy基础知识 Autoflush和Autocommit
【四】定义响应数据格式(schemas.py)
coronavirus\schemas.py
from datetime import date as date_
from datetime import datetime
from pydantic import BaseModel
# 定义创建数据的格式
class CreateData(BaseModel):
# 前端传入 创建时间
date: date_
# 确诊数
confirmed: int = 0
# 死亡数
deaths: int = 0
# 痊愈数
recovered: int = 0
# 定义创建城市数据的格式
class CreateCity(BaseModel):
# 省份
province: str
# 国家
country: str
# 国家代码
country_code: str
# 国家人口
country_population: int
# 定义读取数据的格式
class ReadData(CreateData):
# 主键 id
id: int
# 城市代码
city_id: int
# 创建时间
updated_at: datetime
# 更新时间
created_at: datetime
# 定义配置:允许使用 orm 语句
class Config:
orm_mode = True
class ReadCity(CreateCity):
# 主键 id
id: int
# 创建时间
updated_at: datetime
# 更新时间
created_at: datetime
# 定义配置:允许使用 orm 语句
class Config:
orm_mode = True
【五】封装数据库操作(curd.py)
coronavirus\curd.py
from sqlalchemy.orm import Session
from coronavirus import models, schemas
# 查询城市的数据
def get_city(db: Session, city_id: int):
# 通过数据库对象 查询模型表中的 City 模型 ,过滤出 City.id == 输入的城市ID 的数据取出来
return db.query(models.City).filter(models.City.id == city_id).first()
# 通过省份查询城市数据
def get_city_by_name(db: Session, name: str):
return db.query(models.City).filter(models.City.province == name).first()
# 获取到指定范围内的城市数据 -- 分页操作
def get_cities(db: Session, skip: int = 0, limit: int = 10):
return db.query(models.City).offset(skip).limit(limit).all()
# 创建城市数据
def create_city(db: Session, city: schemas.CreateCity):
# 初始化城市数据对象
db_city = models.City(**city.dict())
# 提交数据库
db.add(db_city)
# 执行事务
db.commit()
# 刷新数据
db.refresh(db_city)
# 将创建好的城市对象返回
return db_city
# 获取到指定城市的指定范围内的数据
def get_data(db: Session, city: str = None, skip: int = 0, limit: int = 10):
# 是否根据城市进行数据查询
if city:
return db.query(models.Data).filter(
# 外键关联查询,这里不是像Django ORM那样Data.city.province
models.Data.city.has(province=city))
# 不按城市查询则 根据 模型类中的数据格式 进行数据查询切片并返回
return db.query(models.Data).offset(skip).limit(limit).all()
# 创建城市详细数据
def create_city_data(db: Session, data: schemas.CreateData, city_id: int):
# 初始化城市详细数据对象
db_data = models.Data(**data.dict(), city_id=city_id)
# 提交数据库
db.add(db_data)
# 执行事务
db.commit()
# 刷新数据
db.refresh(db_data)
# 将创建好的城市详细对象返回
return db_data
【六】书写视图逻辑(main.py)
【1】准备
projects\coronavirus\main.py
from typing import List
from starlette import status
import requests
from fastapi import APIRouter, Depends, HTTPException, BackgroundTasks, Request
from fastapi.templating import Jinja2Templates
from pydantic import HttpUrl
from sqlalchemy.orm import Session
from coronavirus import curd, schemas
from coronavirus.database import engine, Base, SessionLocal
from coronavirus.models import City, Data
# 创建子路由
application = APIRouter()
# 创建前端页面配置
templates = Jinja2Templates(directory='./coronavirus/templates')
# 初始化数据库引擎对象
Base.metadata.create_all(bind=engine)
projects\coronavirus\__init__.py
from .main import application
projects\run.py
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
import uvicorn
from turtorial import app03, app04, app05, app06, app07, app08
from coronavirus import application
# from fastapi.exceptions import RequestValidationError
# from fastapi.responses import PlainTextResponse
# from starlette.exceptions import HTTPException as StarletteHTTPException
app = FastAPI(
title='FastAPI Tutorial and Coronavirus Tracker API Docs',
description='FastAPI教程 新冠病毒疫情跟踪器API接口文档,项目代码:https://github.com/liaogx/fastapi-tutorial',
version='1.0.0',
docs_url='/docs',
redoc_url='/redocs',
)
# mount表示将某个目录下一个完全独立的应用挂载过来,这个不会在API交互文档中显示
# .mount()不要在分路由APIRouter().mount()调用,模板会报错
# path 访问路由
# app 挂载文件对象 StaticFiles from fastapi.staticfiles import StaticFiles
# directory 指定具体的文件目录
# name 别名
app.mount(path='/static', app=StaticFiles(directory='./coronavirus/static'), name='static')
# # 重写HTTPException异常处理器
# @app.exception_handler(StarletteHTTPException)
# async def http_exception_handler(request, exc):
# """
# :param request: 这个参数不能省
# :param exc:
# :return:
# """
# return PlainTextResponse(str(exc.detail), status_code=exc.status_code)
#
#
# @app.exception_handler(RequestValidationError) # 重写请求验证异常处理器
# async def validation_exception_handler(request, exc):
# """
# :param request: 这个参数不能省
# :param exc:
# :return:
# """
# return PlainTextResponse(str(exc), status_code=400)
# 将其他app添加到主路由下
# app03 : app名字
# prefix :自定义路由地址
# tags :自定义路由标题 (默认是default)
app.include_router(app03, prefix='/chapter03', tags=['第三章 请求参数和验证'])
app.include_router(app04, prefix='/chapter04', tags=['第四章 响应处理和FastAPI配置'])
app.include_router(app05, prefix='/chapter05', tags=['第五章 FastAPI的依赖注入系统'])
app.include_router(app06, prefix='/chapter06', tags=['第六章 安全、认证和授权'])
app.include_router(app07, prefix='/chapter07', tags=['第七章 FastAPI的数据库操作和多应用的目录结构设计'])
app.include_router(app08, prefix='/chapter08', tags=['第八章 中间件、CORS、后台任务、测试用例'])
app.include_router(application, prefix='/coronavirus', tags=['新冠病毒疫情跟踪器API'])
def main():
# run:app : 启动文件:app名字
# host :IP
# port : 端口
# reload : 自动重启
# debug :debug 模式
# worker : 开启的进程数
uvicorn.run('run:app', host='127.0.0.1', port=8999, reload=True, debug=True, workers=1)
if __name__ == '__main__':
main()
【2】创建视图函数(部分)
from typing import List
import requests
from fastapi import APIRouter, Depends, HTTPException, BackgroundTasks, Request
from fastapi.templating import Jinja2Templates
from pydantic import HttpUrl
from sqlalchemy.orm import Session
from starlette import status
from coronavirus import curd, schemas
from coronavirus.database import engine, Base, SessionLocal
from coronavirus.models import City, Data
# 创建子路由
application = APIRouter()
# 创建前端页面配置
templates = Jinja2Templates(directory='./coronavirus/templates')
# 初始化数据库引擎对象
Base.metadata.create_all(bind=engine)
# 创建子依赖对象
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
# 创建城市
@application.post('/create_city', response_model=schemas.ReadCity)
async def create_city(city: schemas.CreateCity, db: Session = Depends(get_db)):
'''
:param city: 前端传入的符合 CreateCity 格式的城市数据
:param db: 数据库操作对象,基于子依赖的数据库操作
:return:
'''
# 判断是否存在当前城市 --- 根据前端传入的城市名字进行过滤
db_city = curd.get_city_by_name(db=db, name=city.province)
# 存在则主动抛出异常
if db_city:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail='City is already registered!'
)
# 不存在则创建
return curd.create_city(db=db, city=city)
# 查询城市数据
@application.get('/get_city/{city}', response_model=schemas.ReadCity)
async def get_city(city: str, db: Session = Depends(get_db)):
'''
:param city: 路径参数,路径中的城市名
:param db: 数据库对象,依赖子依赖
:return:
'''
# 使用数据库对象查询数据
db_city = curd.get_city_by_name(db=db, name=city)
# 校验数据是否存在
if db_city is None:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail='City not found!'
)
# 数据存在
return db_city
# 查询多个城市的数据
@application.get('/get_cities', response_model=List[schemas.ReadCity])
async def get_cities(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
'''
:param skip: 起始位置
:param limit: 结束位置
:param db: 数据库对象,依赖子依赖
:return:
'''
cities = curd.get_cities(db=db, skip=skip, limit=limit)
return cities
# 创建数据
@application.post('/create_data', response_model=schemas.ReadData)
async def create_data_for_city(city: str, data: schemas.CreateData, db: Session = Depends(get_db)):
'''
:param city: 给那个城市创建数据
:param data: 城市的详细数据
:param db: 数据库对象,依赖子依赖
:return:
'''
# 查询当前城市是否存在
db_city = curd.get_city_by_name(db=db, name=city)
# 创建数据
data = curd.create_city_data(db=db, data=data, city_id=db_city.id)
return data
# 获取数据
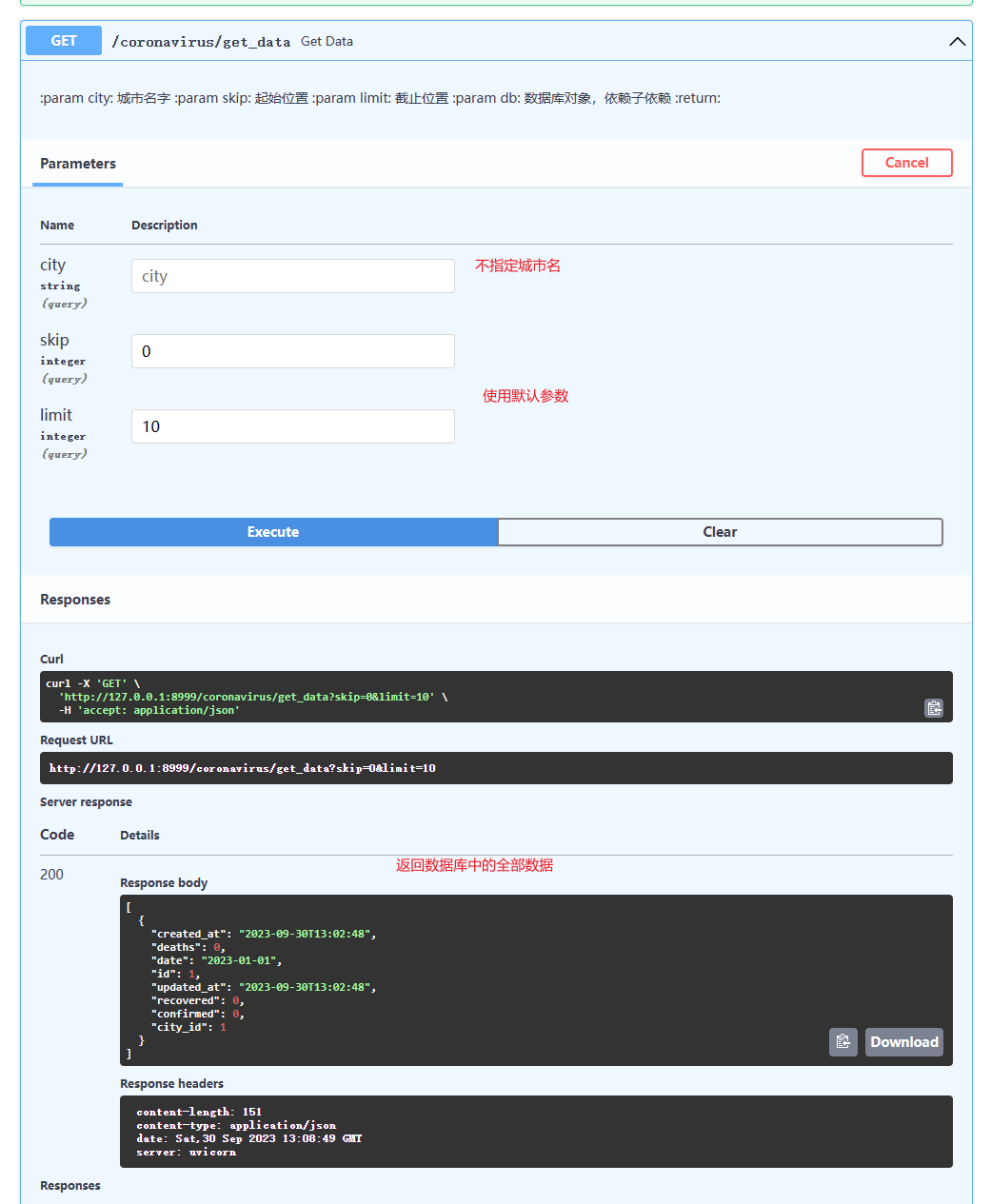
@application.get('/get_data')
async def get_data(city: str = None, skip: int = 0, limit: int = 10, db: Session = Depends(get_db)):
'''
:param city: 城市名字
:param skip: 起始位置
:param limit: 截止位置
:param db: 数据库对象,依赖子依赖
:return:
'''
data = curd.get_data(city=city, skip=skip, limit=limit, db=db)
return data
【3】发起请求,测试接口
(1)启动项目
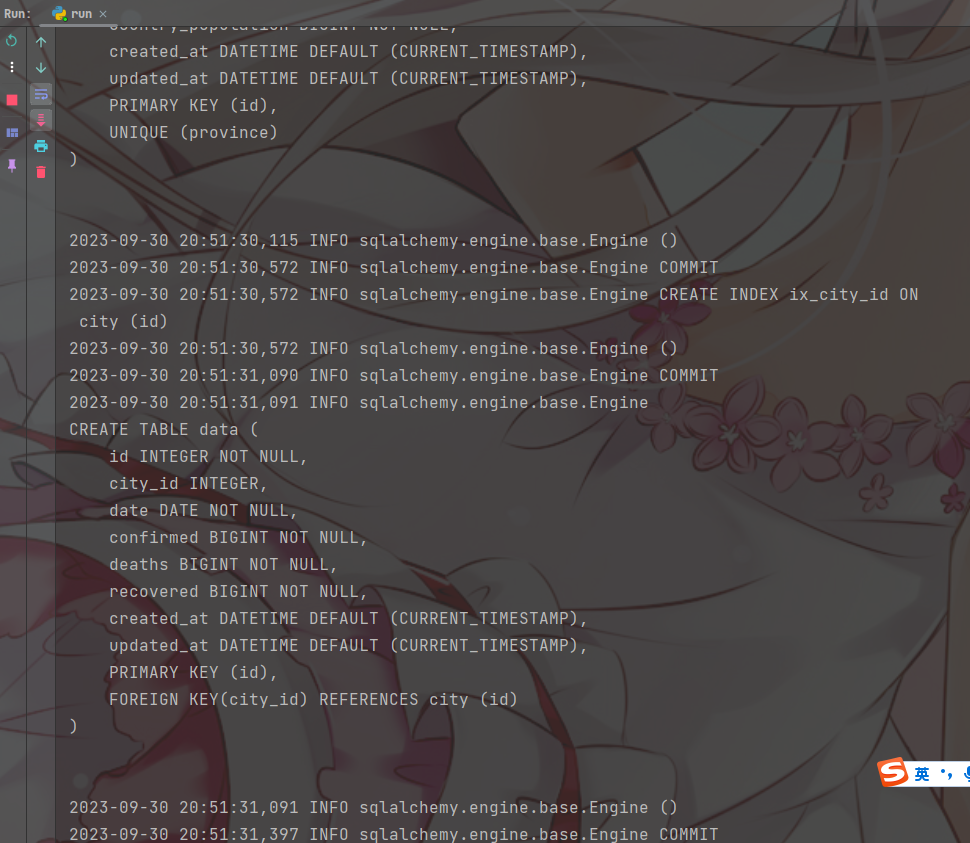
-
可以看到有很多SQL语句
- 这是因为我们在配置文件中配置了
# echo=True表示引擎将用repr()函数记录所有语句及其参数列表到日志 echo=True -
并且已经生成了数据库文件
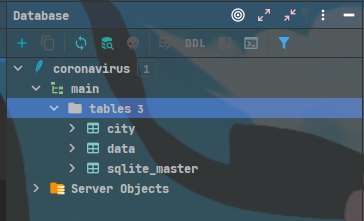
- 数据库中的表
(2)docs文档
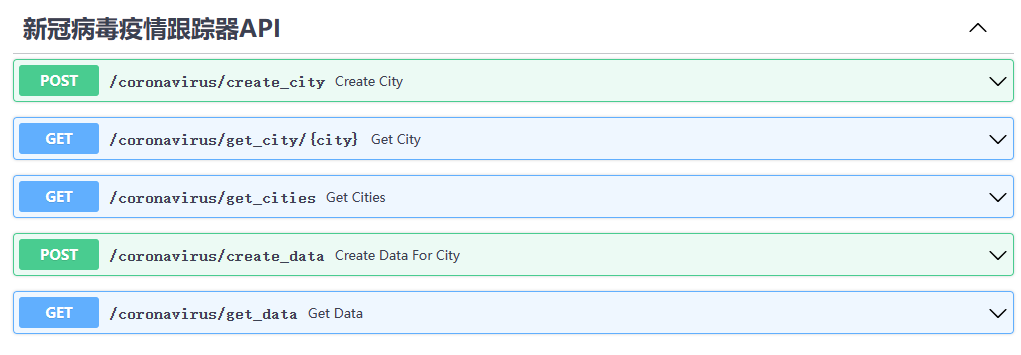
- 可以看到我们配置的接口已经存在了
(3)测试接口--创建城市
- 接口测试
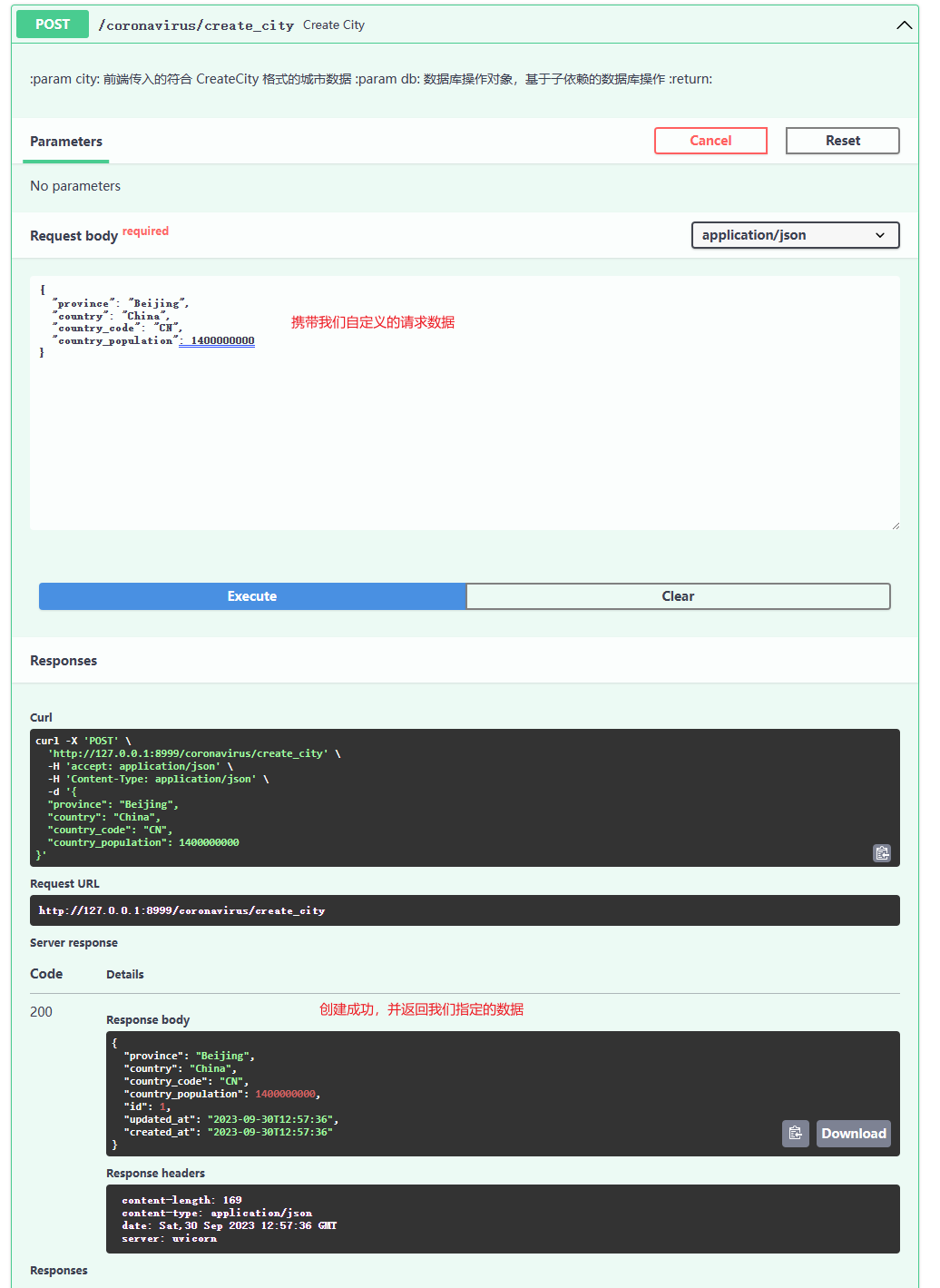
- 数据库查看
- 创建成功

(4)获取城市信息
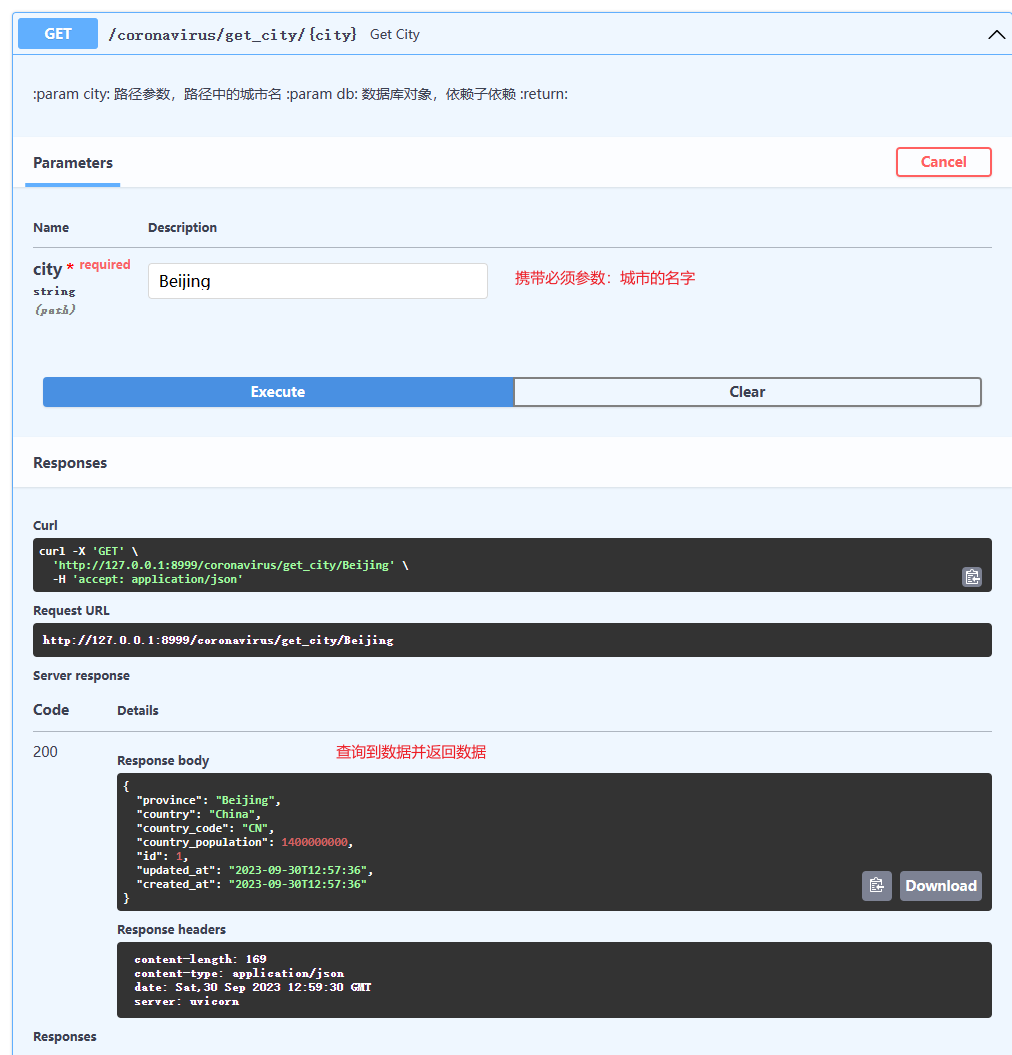
(5)获取多个城市的信息
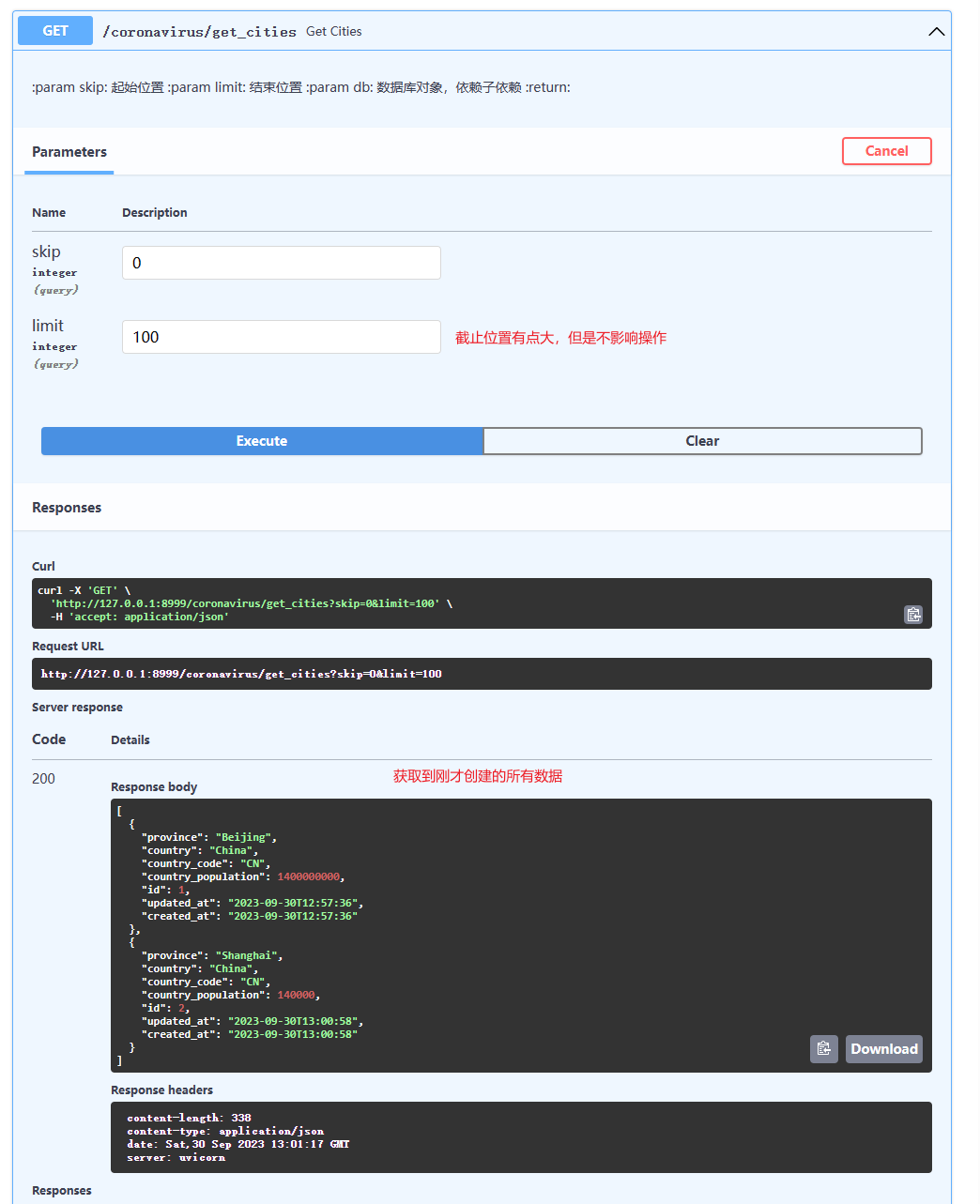
(6)创建城市的详细数据
- 测试接口
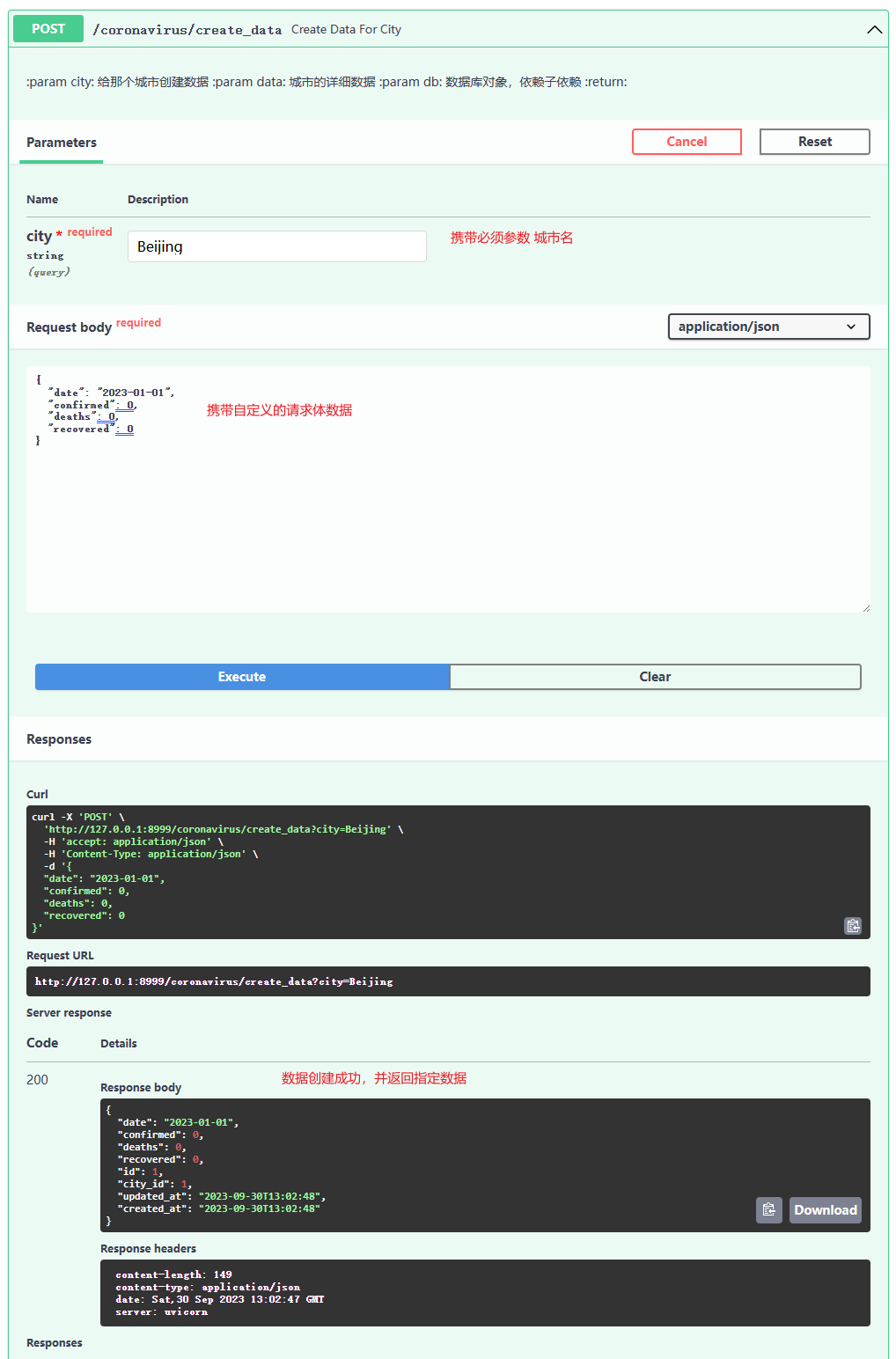
- 查看数据库
- 数据创建成功

(7)获取城市的详细信息
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17738898.html

