【5.0】Pandas描述性统计
【一】Python Pandas描述性统计
- 描述统计学(descriptive statistics)是一门统计学领域的学科,主要研究如何取得反映客观现象的数据,并以图表形式对所搜集的数据进行处理和显示,最终对数据的规律、特征做出综合性的描述分析。
- Pandas 库正是对描述统计学知识完美应用的体现,可以说如果没有“描述统计学”作为理论基奠,那么 Pandas 是否存在犹未可知。下列表格对 Pandas 常用的统计学函数做了简单的总结:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
-
从描述统计学角度出发,我们可以对 DataFrame 结构执行聚合计算等其他操作,比如 sum() 求和、mean()求均值等方法。
-
在 DataFrame 中,使用聚合类方法时需要指定轴(axis)参数。下面介绍两种传参方式:
- 对行操作,默认使用 axis=0 或者使用 “index”;
- 对列操作,默认使用 axis=1 或者使用 “columns”。
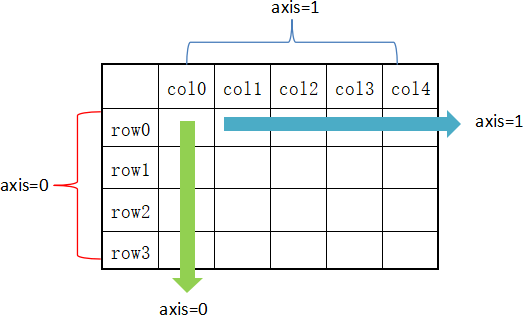
- 从图 1 可以看出,axis=0 表示按垂直方向进行计算,而 axis=1 则表示按水平方向。
- 下面让我们创建一个 DataFrame,使用它对本节的内容进行演示。
【二】创建一个 DataFrame 结构
- 创建一个 DataFrame 结构,如下所示:
【三】sum()求和
【1】axis=0
- 在默认情况下,返回 axis=0 的所有值的和。示例如下:
- 注意:
- sum() 和 cumsum() 函数可以同时处理数字和字符串数据。
- 虽然字符聚合通常不被使用,但使用这两个函数并不会抛出异常;
- 而对于 abs()、cumprod() 函数则会抛出异常,因为它们无法操作字符串数据。
【2】axis=1
- 下面再看一下 axis=1 的情况,如下所示
【四】mean()求均值
【五】std()求标准差
- 返回数值列的标准差
- 标准差是方差的算术平方根,它能反映一个数据集的离散程度。
- 注意,平均数相同的两组数据,标准差未必相同。
【六】数据汇总描述
- describe() 函数显示与 DataFrame 数据列相关的统计信息摘要。
-
describe() 函数输出了平均值、std 和 IQR 值(四分位距)等一系列统计信息。
-
通过 describe() 提供的include能够筛选字符列或者数字列的摘要信息。
-
include 相关参数值说明如下:
-
object: 表示对字符列进行统计信息描述;
-
number:表示对数字列进行统计信息描述;
-
all:汇总所有列的统计信息。
-
- 最后使用
all参数,看一下输出结果
__EOF__

本文作者:Chimengmeng
本文链接:https://www.cnblogs.com/dream-ze/p/17726182.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/dream-ze/p/17726182.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17726182.html
