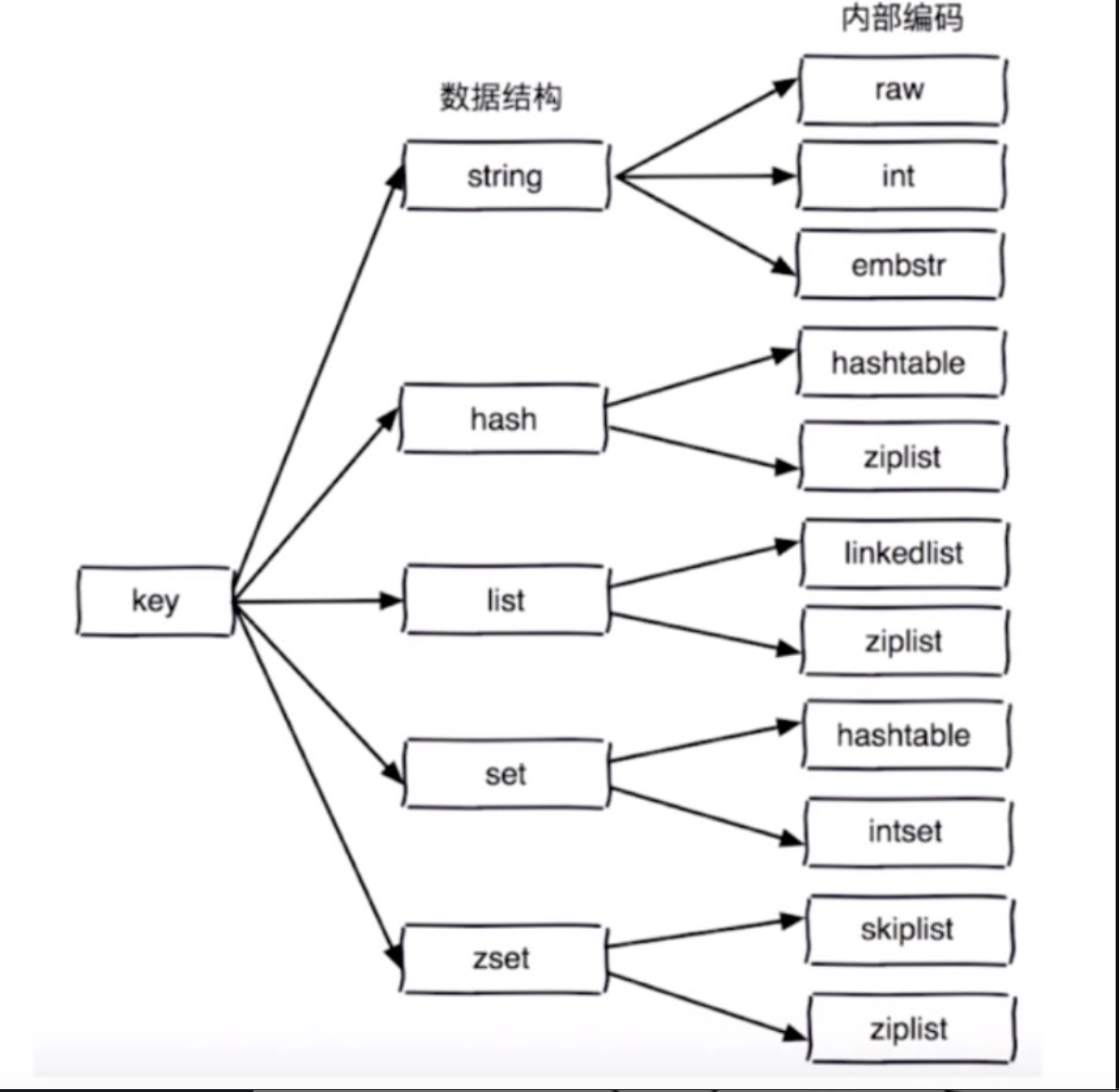
【5.0】Redis五大数据类型
【图解Redis数据结构】
【Redis单线程架构】
【1】单线程架构
- 一个瞬间只会执行一条命令
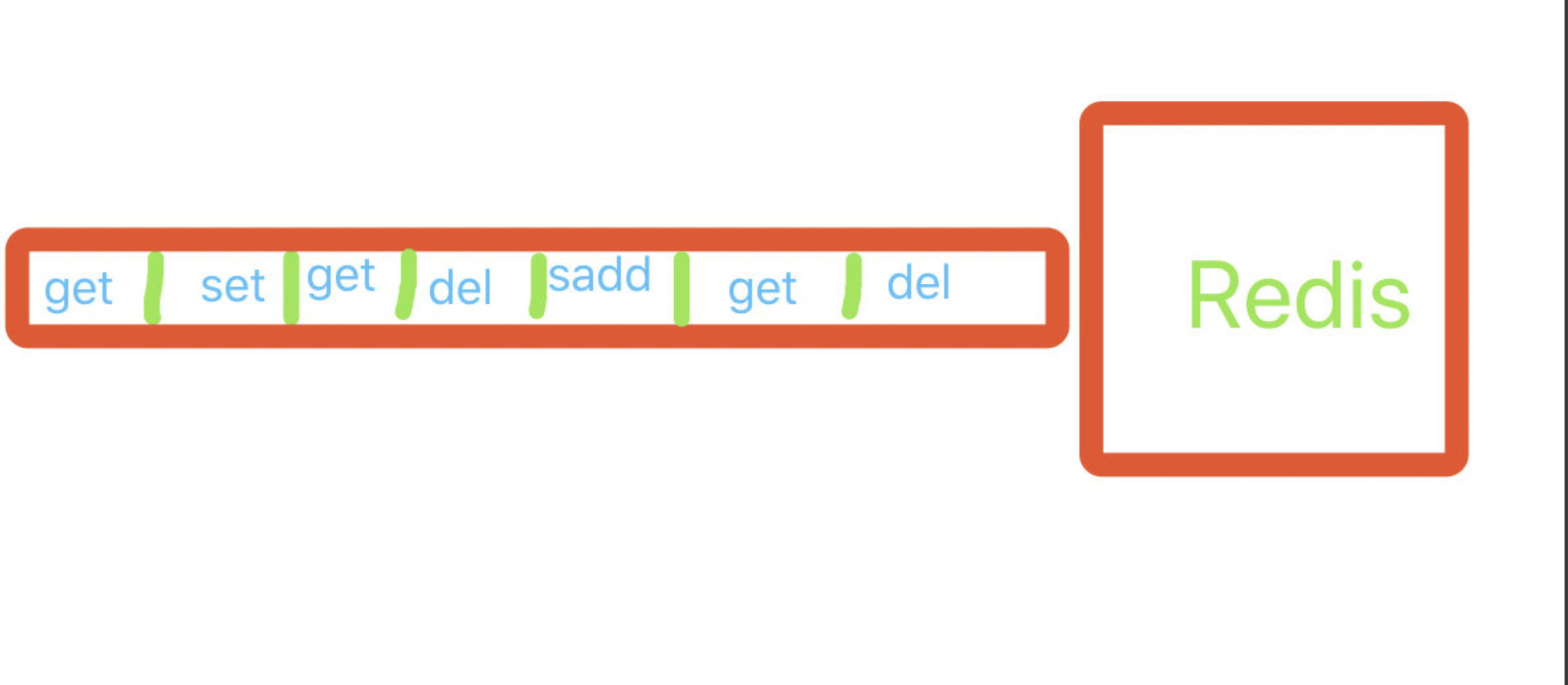
- Redis的主要任务是处理来自客户端的请求并执行命令。
- 在任意时刻,Redis只会处理一条命令,通过串行执行命令保证了数据的一致性。
- Redis在内部使用事件驱动(epoll)的非阻塞I/O模型,以提高网络通信的效率,同时Redis自身实现了事件处理,不会花费过多时间在网络I/O上。
- 由于单线程架构避免了线程间切换和竞态消耗,它能够更有效地利用CPU资源,从而提高整体性能。
【2】单线程为什么这么快
- 1 纯内存
- 2 非阻塞IO (epoll),自身实现了事件处理,不在网络io上浪费过多时间
- 3 避免线程间切换和竞态消耗
- 纯内存:
- Redis主要将数据存储在内存中,因为内存的读写速度远远快于磁盘和其他存储介质,从而使得Redis能够达到很高的读写性能。
- 非阻塞I/O(epoll):
- Redis使用非阻塞I/O模型进行网络通信,减少了等待I/O的时间,提高了响应速度。
- 避免线程间切换和竞态消耗:
- 单线程架构避免了多线程间的切换开销和并发控制的竞争状况,减少了性能损耗。
【3】注意
- 1 一次只运行一条命令
- 2 拒绝长慢命令
- keys,flushall,flushdb,慢的lua脚本,mutil/exec,operate,big value
- 3 其实不是单线程(在做持久化是另外的线程)
- -fysnc file descriptor
- -close file descriptor
- 一次只运行一条命令:
- 由于Redis是单线程的,所以在任意时刻只能处理一条命令。
- 这意味着如果发出多个命令,Redis将按照顺序依次执行,不能并行处理。
- 拒绝长慢命令:
- 为了保证线程的快速响应,Redis会拒绝执行一些耗时较长的命令,如
KEYS、FLUSHALL、FLUSHDB、慢的Lua脚本、MULTI/EXEC等。 - 这些命令可能会对性能产生较大影响。
- 为了保证线程的快速响应,Redis会拒绝执行一些耗时较长的命令,如
- 其实不是单线程(在做持久化是另外的线程):
- 尽管Redis主要采用单线程架构,但在执行持久化操作时(例如RDB快照和AOF日志文件的写入),Redis会启动额外的线程执行相关任务,如文件同步和关闭文件描述符等。
【一】字符串类型
【1】字符串键值结构
key value
hello world 可以很复杂,如json格式字符串
counter 1 数字类型
bits 10101010 二进制(位图)
#字符串value不能大于512m,一般建议100k以内
#用于缓存,计数器,分布式锁...
【2】常用命令
(1)基本使用get,set,del
get name #时间复杂度 o(1)
set name dream #时间复杂度 o(1)
del name #时间复杂度 o(1)
(2)其他使用incr,decr,incrby,decrby
incr age #对age这个key的value值自增1
decr age #对age这个key的value值自减1
incrby age 10 #对age这个key的value值增加10
decrby age 10 #对age这个key的value值减10
- 小结
- 统计网站访问量(单线程无竞争,天然适合做计数器)
- 缓存mysql的信息(json格式)
- 分布式id生成(多个机器同时并发着生成,不会重复)
- 时间戳 + Redis 自增数字
(3)set,setnx,setxx
set name dream #不管key是否存在,都设置
setnx name dream #key不存在时才设置(新增操作)
set name dream nx #同上
set name dream xx #key存在,才设置(更新操作)
(4)mget mset
#批量获取key1,key2.。。时间复杂度o(n)
mget key1 key2 key3
#批量设置时间复杂度o(n)
mset key1 value1 key2 value2 key3 value3
- n次get和mget的区别
- n次get时间=n次命令时间+n次网络时间
- mget时间=1次网络时间+n次命令时间
(5)其他:getset,append,strlen
# 设置新值并返回旧值 时间复杂度o(1)
getset name dreamnb
# 将value追加到旧的value 时间复杂度o(1)
append name 666
# 计算字符串长度(注意中文) 时间复杂度o(1)
strlen name
(6)其他:incrybyfloat,getrange,setrange
# 为age自增3.5,传负值表示自减 时间复杂度o(1)
increbyfloat age 3.5
# 获取字符串制定下标所有的值 时间复杂度o(1)
getrange key start end
# 从指定index开始设置value值 时间复杂度o(1)
setrange key index value
【二】哈希类型
【1】哈希值结构
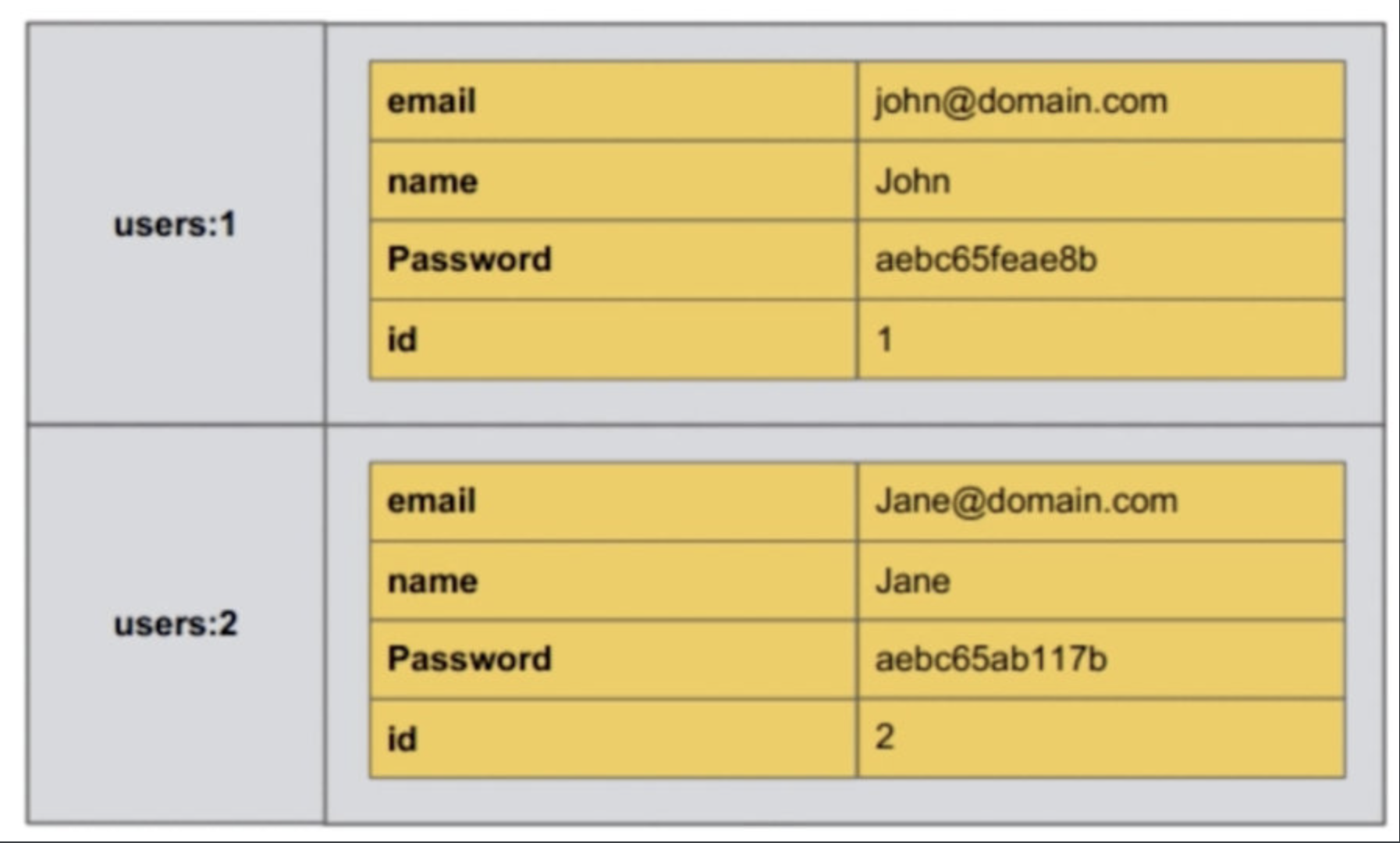
【2】重要api
(1)hget,hset,hdel
#获取hash key对应的field的value 时间复杂度为 o(1)
hget key field
#设置hash key对应的field的value值 时间复杂度为 o(1)
hset key field value
#删除hash key对应的field的值 时间复杂度为 o(1)
hdel key field
- 演示
hset user:1:info age 23
hget user:1:info ag
hset user:1:info name lqz
hgetall user:1:info
hdel user:1:info age
(2)hexists,hlen
#判断hash key 是否存在field 时间复杂度为 o(1)
hexists key field
#获取hash key field的数量 时间复杂度为 o(1)
hlen key
hexists user:1:info name
#返回数量
hlen user:1:info
(3)hmget,hmset
#批量获取hash key 的一批field对应的值 时间复杂度是o(n)
hmget key field1 field2 ...fieldN
#批量设置hash key的一批field value 时间复杂度是o(n)
hmset key field1 value1 field2 value2
(4)hgetall,hvals,hkeys
#返回hash key 对应的所有field和value 时间复杂度是o(n)
hgetall key
#返回hash key 对应的所有field的value 时间复杂度是o(n)
hvals key
#返回hash key对应的所有field 时间复杂度是o(n)
hkeys key
小心使用hgetall
- 计算网站每个用户主页的访问量
- hincrby user:1:info pageview count
- 缓存mysql的信息,直接设置hash格式
【3】hash vs string
(1)相似的api
| get | hget |
|---|---|
| set /sentnx | hset hsetnx |
| del | hdel |
| incr incrby dear decrby | hincrby |
| mset | hmset |
| mget | hmget |
(2)缓存三种方案
- 直接json格式字符串
- 每个字段一个key
- 使用hash操作
(4)其他操作
##其他操作 hsetnx,hincrby,hincrbyfloat
#设置hash key对应field的value(如果field已存在,则失败),时间复杂度o(1)
hsetnx key field value
#hash key 对英的field的value自增intCounter 时间复杂度o(1)
hincrby key field intCounter
#hincrby 浮点数 时间复杂度o(1)
hincrbyfloat key field floatCounter
【三】列表类型
【1】列表特点
- 有序队列,可以从左侧添加,右侧添加,可以重复,可以从左右两边弹出
【2】API操作
(1)插入操作
#rpush 从右侧插入
#时间复杂度为o(1~n)
rpush key value1 value2 ...valueN
#lpush 从左侧插入
#linsert
#从元素value的前或后插入newValue 时间复杂度o(n) ,需要遍历列表
linsert key before|after value newValue
linsert listkey before b java
linsert listkey after b php
(2)删除操作
#从列表左侧弹出一个item 时间复杂度o(1)
lpop key
#从列表右侧弹出一个item 时间复杂度o(1)
rpop key
lrem key count value
#根据count值,从列表中删除所有value相同的项 时间复杂度o(n)
1 count>0 从左到右,删除最多count个value相等的项
2 count<0 从右向左,删除最多 Math.abs(count)个value相等的项
3 count=0 删除所有value相等的项
#删除列表中所有值a
lrem listkey 0 a
#从右侧删除1个c
lrem listkey -1 c
#按照索引范围修剪列表 o(n)
ltrim key start end
#只保留下表1--4的元素
ltrim listkey 1 4
(3)查询操作
#包含end获取列表指定索引范围所有item o(n)
lrange key start end
lrange listkey 0 2
#获取第一个位置到倒数第一个位置的元素
lrange listkey 1 -1
#获取列表指定索引的item o(n)
lindex key index
lindex listkey 0
lindex listkey -1
#获取列表长度
llen key
(4)修改操作
#设置列表指定索引值为newValue o(n)
lset key index newValue
#把第二个位置设为ppp
lset listkey 2 ppp
【3】实战
- 实现timeLine功能,时间轴,微博关注的人,按时间轴排列,在列表中放入关注人的微博的即可
- Redis 是一种内存数据库,它支持持久化,并可用于实现时间轴(timeline)功能,如微博关注系统。
- 在 Redis 中,我们可以使用有序集合(Sorted Set)来按时间轴排列微博,列表则用来存放关注的人发布的微博。
(1)创建一个有序集合
- 创建一个有序集合,用于存放所有微博的信息。
- 每个微博的分数可以使用时间戳来表示,以便按时间排序。
# 根据时间戳添加微博到有序集合中
ZADD timeline 1630495712 "微博内容1"
ZADD timeline 1630495715 "微博内容2"
(2)创建一个哈希表
- 创建一个哈希表,用于存放每个用户关注的人。
# 添加用户关注的人到哈希表中
HSET following_user:user1 user2 true
HSET following_user:user1 user3 true
(3)获取当前用户关注的人发表的最新微博
- 获取当前用户关注的人发表的最新微博,更新时间轴。
# 获取当前用户关注的人
following_users = HGETALL following_user:user1
# 遍历关注的人,获取他们发表的最新微博
for following_user in following_users:
latest_weibo = ZRANGE timeline 0 0 # 获取有序集合中最新的微博
if latest_weibo:
HSET user1_timeline latest_weibo[0] true # 将最新的微博添加到用户时间轴中
- 通过上述步骤,我们可以将用户关注的人的最新微博添加到用户的个人时间轴中。
- 在具体场景中,可以将以上代码片段放入一个函数中,并根据实际需求进行功能扩展和优化。
【4】其他操作
#lpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1)
blpop key timeout
#rpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1)
brpop key timeout
#要实现栈的功能
lpush+lpop
#实现队列功能
lpush+rpop
#固定大小的列表
lpush+ltrim
#消息队列
lpush+brpop
【四】集合类型
【1】特点
- 无序,无重复,集合间操作(交叉并补)
【2】API操作
#向集合key添加element(如果element存在,添加失败) o(1)
sadd key element
#从集合中的element移除掉 o(1)
srem key element
#计算集合大小
scard key
#判断element是否在集合中
sismember key element
#从集合中随机取出count个元素,不会破坏集合中的元素
srandmember key count
#从集合中随机弹出一个元素
spop key
#获取集合中所有元素 ,无序,小心使用,会阻塞住
smembers key
#计算user:1:follow和user:2:follow的差集
sdiff user:1:follow user:2:follow
#计算user:1:follow和user:2:follow的交集
sinter user:1:follow user:2:follow
#计算user:1:follow和user:2:follow的并集
sunion user:1:follow user:2:follow
#将差集,交集,并集结果保存在destkey集合中
sdiff|sinter|suion + store destkey...
(3)实战
- 抽奖系统 :通过spop来弹出用户的id,活动取消,直接删除
- 点赞,点踩,喜欢等,用户如果点了赞,就把用户id放到该条记录的集合中
- 标签:给用户/文章等添加标签,sadd user:1:tags 标签1 标签2 标签3
- 给标签添加用户,关注该标签的人有哪些
- 共同好友:集合间的操作
(4)总结
- sadd:可以做标签相关
- spop/srandmember:可以做随机数相关
- sadd/sinter:社交相关
【五】有序集合类型
【1】特点
#有一个分值字段,来保证顺序
key score value
user:ranking 1 dream
user:ranking 99 dream2
user:ranking 88 dream3
#集合有序集合
集合:无重复元素,无序,element
有序集合:无重复元素,有序,element+score
#列表和有序集合
列表:可以重复,有序,element
有序集合:无重复元素,有序,element+score
6.2 API使用
#score可以重复,可以多个同时添加,element不能重复 o(logN)
zadd key score element
#删除元素,可以多个同时删除 o(1)
zrem key element
#获取元素的分数 o(1)
zscore key element
#增加或减少元素的分数 o(1)
zincrby key increScore element
#返回元素总个数 o(1)
zcard key
#返回element元素的排名(从小到大排)
zrank key element
#返回排名,不带分数 o(log(n)+m) n是元素个数,m是要获取的值
zrange key 0 -1
#返回排名,带分数
zrange player:rank 0 -1 withscores
#返回指定分数范围内的升序元素 o(log(n)+m) n是元素个数,m是要获取的值
zrangebyscore key minScore maxScore
#获取90分到210分的元素
zrangebyscore user:1:ranking 90 210 withscores
#返回有序集合内在指定分数范围内的个数 o(log(n)+m)
zcount key minScore maxScore
#删除指定排名内的升序元素
zremrangebyrank key start end o(log(n)+m)
#删除升序排名中1到2的元素
zremrangebyrank user:1:rangking 1 2
#删除指定分数内的升序元素 o(log(n)+m)
zremrangebyscore key minScore maxScore
#删除分数90到210之间的元素
zremrangebyscore user:1:ranking 90 210
6.3 实战
排行榜:音乐排行榜,销售榜,关注榜,游戏排行榜
6.4 其他操作
zrevrank #从高到低排序
zrevrange #从高到低排序取一定范围
zrevrangebyscore #返回指定分数范围内的降序元素
zinterstore #对两个有序集合交集
zunionstore #对两个有序集合求并集
6.5 总结
| 操作类型 | 命令 |
|---|---|
| 基本操作 | zadd/ zrem/ zcard/ zincrby/ zscore |
| 范围操作 | zrange/ zrangebyscore/ zcount/ zremrangebyrank |
| 集合操作 | zunionstore/ zinterstore |
【列表操作示例】
下面我会为你详细解释如何实现这些 Redis 实战操作,然后给出 Python 代码示例。
1. 抽奖系统
抽奖系统可以使用 Redis 的 SPOP 命令来实现。你可以使用一个 Redis 集合来存储参与抽奖的用户的 ID,然后使用 SPOP 命令来随机弹出一个用户的 ID。如果活动取消,你可以使用 DEL 命令来删除整个集合。
import redis
# 连接到 Redis 服务器
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 将用户ID添加到抽奖集合
r.sadd('lottery:participants', 'user_id_1')
r.sadd('lottery:participants', 'user_id_2')
# 弹出一个用户ID进行抽奖
winner = r.spop('lottery:participants')
print(f"The winner is: {winner.decode('utf-8')}")
# 如果活动取消,删除整个抽奖集合
r.delete('lottery:participants')
2. 点赞、点踩、喜欢等
对于点赞、点踩和喜欢等功能,你可以使用 Redis 的集合数据结构来存储用户的 ID。每条记录都对应一个集合,其中包含点赞、点踩或喜欢的用户的 ID。以下是一个示例:
import redis
# 连接到 Redis 服务器
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 用户点赞某篇文章
r.sadd('article:1:likes', 'user_id_1')
r.sadd('article:1:likes', 'user_id_2')
# 获取点赞该文章的用户数量
likes_count = r.scard('article:1:likes')
print(f"The article has {likes_count} likes")
# 获取点赞该文章的所有用户ID
liked_users = r.smembers('article:1:likes')
print(f"Users who liked the article: {liked_users}")
3. 标签
对于标签,你可以使用 Redis 的集合来存储用户或文章与标签的关系。每个用户或文章都可以有一个对应的标签集合。
import redis
# 连接到 Redis 服务器
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 为用户1添加标签
tags = ['标签1', '标签2', '标签3']
r.sadd('user:1:tags', *tags)
# 获取用户1的所有标签
user_tags = r.smembers('user:1:tags')
print(f"User 1's tags: {user_tags}")
4. 给标签添加用户
你可以为每个标签创建一个集合,其中包含关注该标签的用户的 ID。
import redis
# 连接到 Redis 服务器
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 用户1关注标签1
r.sadd('tag:1:followers', 'user_id_1')
r.sadd('tag:1:followers', 'user_id_2')
# 获取关注标签1的所有用户
tag_followers = r.smembers('tag:1:followers')
print(f"Users following tag 1: {tag_followers}")
5. 共同好友
要查找共同好友,你可以使用 Redis 的集合操作,如 SINTER 来查找两个用户的共同好友。
import redis
# 连接到 Redis 服务器
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 用户1的好友列表
r.sadd('user:1:friends', 'user_id_2', 'user_id_3', 'user_id_4')
# 用户2的好友列表
r.sadd('user:2:friends', 'user_id_1', 'user_id_3', 'user_id_5')
# 查找用户1和用户2的共同好友
common_friends = r.sinter('user:1:friends', 'user:2:friends')
print(f"Common friends between user 1 and user 2: {common_friends}")
这些示例展示了如何使用 Python 和 Redis 来实现抽奖系统、点赞、标签、标签关注以及查找共同好友等功能。你可以根据你的实际应用需求对这些示例进行扩展和修改。
【拓展】Redis 数据结构之 跳跃表
跳跃表(Skip List)是一种用于实现有序集合的数据结构,它在Redis中被用作有序集合的底层实现之一。跳跃表通过添加额外的索引层次来提高有序集合的查找效率。
在跳跃表中,元素被排列成多个层次,每一层都是一个有序的链表。最底层包含了所有元素,而每个更高级的层次都是前一层次的子集。每个元素都有一个指向下一层次的指针,在不同层次中能够快速地进行查找。
下面我们将详细介绍跳跃表的结构和操作:
-
跳跃表的结构:
- 每个节点都包含一个分值和值两部分,其中分值用于排序元素。
- 节点按照分值从小到大的顺序排列,如果两个节点的分值相同,则根据值的大小来决定顺序。
- 节点的层数是随机生成的,可用于加速查找过程。
-
跳跃表的操作:
- 插入操作:在跳跃表中插入一个新元素时,首先需要确定该元素应该插入哪个层次。然后在每个层次中找到正确的位置,并更新指针。如果某个层次中插入了一个新的节点,那么该层次上方的节点也有一定概率插入新的节点,以维持跳跃表的平衡性。
- 删除操作:删除一个元素时,需要在每个层次中找到对应的节点,并更新指针。
- 查询操作:通过比较查询值与节点的分值进行查找,在每个层次中进行逐层搜索,直到找到目标节点或达到边界。
下面是一个插入、删除和查询操作的示例代码:
# 导入Redis模块
import redis
# 连接到Redis数据库
r = redis.Redis(host='localhost', port=6379, db=0)
# 插入操作
r.zadd('my_sorted_set', {'member1': 1, 'member2': 2, 'member3': 3})
# 删除操作
r.zrem('my_sorted_set', 'member2')
# 查询操作
result = r.zrange('my_sorted_set', 0, -1)
print(result)
-
场景需求分析:
- 跳跃表适用于需要高效地进行范围查询的场景,例如查找某个范围内的元素或者查找排名在给定范围内的元素。
- 由于跳跃表使用了分层索引,请确保在插入大量数据时有足够的内存资源来存储索引。
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17691099.html

