【5.0】路飞项目之数据库相关
【一】软件开发模式
【1】BBS
-
BBS(Bulletin Board System)是一种基于电子信息交流的系统,通常用于在线讨论和发布信息。BBS使用了瀑布开发模式。
-
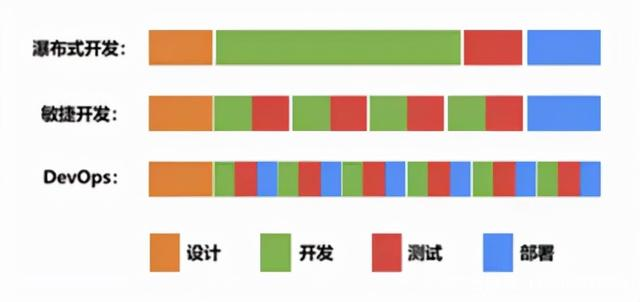
瀑布开发模式是一种线性的软件开发过程,按照固定的顺序依次完成需求分析、系统设计、编码、测试和运维等阶段。
-
在这个开发模式中,软件的开发过程是非迭代的,每个阶段只能在前一个阶段完成后才能开始。
-
设计创建所有表并直接迁移,后续没有再进行过修改,这符合瀑布开发模式的特点。
【2】路飞
- 路飞(Luffy)是一个项目或产品的具体名称,采用了敏捷开发的方式。
- 敏捷开发是一种以迭代、循序渐进的方式进行软件开发的方法。
- 它强调快速反馈、灵活适应变化和高度互动的特点。
- 在敏捷开发中,开发团队将产品需求分解为小的可交付的模块,每个模块都经过设计、开发、测试和上线等阶段。
- 根据提供的信息,先设计,然后逐步开发、测试和上线,符合敏捷开发的特点。
【二】前言
- 如果用户表想用 auth的user表扩写,在一开始就要定好
【三】MySQL数据库配置
【1】新建库
- 要新建一个库,可以使用mysql数据系统,并利用navicate等数据库管理工具进行创建
- 在命令行中也可以使用以下语句进行创建库:
create database luffy;
【2】建表
- 我们可以新建一个名为user的应用程序
- 并在该应用程序中扩展auth的user表以创建用户表。
from django.contrib.auth.models import AbstractUser
from django.db import models
# Create your models here.
class User(AbstractUser):
mobile = models.CharField(max_length=11, unique=True)
# 需要pillow包的支持
icon = models.ImageField(upload_to='icon', default='icon/default.png')
class Meta:
db_table = 'luffy_user' # 指定表名
verbose_name = '用户表' # 后台管理看到的中文
verbose_name_plural = verbose_name
def __str__(self): # 打印对象,显示的
return self.username
- 需要在项目中安装
pillow包
pip install pillow
- 如果想要扩展用户表并使用auth的user表,在开始时要确定好以下配置:
- 在
luffyCity\luffyCity\settings\dev.py文件中添加以下配置:
- 在
AUTH_USER_MODEL = 'user.User' # app名.表名
【3】用户创建及授权
- 为了提高数据库安全性
- 项目中的数据库用户不应使用root用户,而是应创建一个新的MySQL用户。
- 相比于root用户,新创建的MySQL用户权限较为有限,只授予luffy库的相关权限。
(1)进入数据库
- 使用以下命令登录MySQL数据库:
mysql -uroot -p1314521
(2)查看数据库列表
- 使用以下命令查看数据库列表:
show databases;
- 输出结果如下:
+--------------------+
| Database |
+--------------------+
| information_schema |
| luffy |
| mysql |
| performance_schema |
| sys |
+--------------------+
19 rows in set (0.00 sec)
(3)查看当前数据库有哪些用户
- 对于mysql 5.7版本,可以使用以下命令查看当前数据库的用户:
select user,host,password from mysql.user;
- 如果无法查询到结果,请尝试使用以下命令:
select user,host,authentication_string from mysql.user;
- 输出结果如下:
+---------------+-----------+-------------------------------------------+
| user | host | authentication_string |
+---------------+-----------+-------------------------------------------+
| root | localhost | *C2864CD5380E51682CE85D0D54D3AD556F9C1E08 |
| mysql.session | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| mysql.sys | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
+---------------+-----------+-------------------------------------------+
3 rows in set (0.00 sec)
(4)创建路飞用户(本地链接)
- 创建luffy用户,并授予其对luffy库中所有表的权限,并指定用户密码为Luffy123?
grant all privileges on luffy.* to 'luffy'@'localhost' identified by 'Luffy123?';
(5)授予路飞用户权限(远程链接)
- 可以远程地链接
- 授予luffy用户对luffy库中所有表的权限,并指定用户密码为Luffy123?
grant all privileges on luffy.* to 'luffy'@'%' identified by 'Luffy123?';
(6)登陆路飞用户查看详情
- 接下来,我们可以使用以下命令使用luffy用户进行本地连接,并查看数据库详情:
mysql -uluffy -pLuffy123?
show database;
- 输出结果如下:
+--------------------+
| Database |
+--------------------+
| information_schema |
| luffy |
+--------------------+
2 rows in set (0.00 sec)
- 测试远程连接
mysql -uluffy -h ip -P port -pLuffy123?
- 例如
mysql -uluffy -h 192.168.139.1 -P 3306 -pLuffy123?
- 如果连接正常,则表示远程连接配置成功。
【4】配置后端配置文件
luffyCity\luffyCity\settings\dev.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'luffy', # 数据库名
'HOST': '192.168.139.1', # 远程数据库地址
'PORT': '3306', # 远程数据库端口
'USER': 'luffy', # 远程数据库用户名
'PASSWORD': 'Luffy123?', # 远程数据库密码
'CHARSET': 'utf8', # 远程数据库编码集
}
}
- 在以前使用
pymysql操作MySQL时,需要加上以下两行代码:
pip install pymysql
import pymysql
pymysql.install_as_MySQLdb()
-
这两行代码的作用是将
pymysql安装为Django中的MySQL数据库驱动。- 然而,在较高版本的Django 2中,这种方式可能会导致报错,需要修改源码来解决。
-
但是现在我们可以使用
mysqlclient来操作MySQL数据库。-
win:看人品,也有解决方案
-
mac:很难装,也有,比较麻烦
-
linux:有解决方案
-
-
安装
mysqlclient可以使用以下命令:
pip install mysqlclient
【5】迁移数据库
- 使用以下命令来生成数据库迁移文件
python ../../manage.py makemigrations
- 然后使用以下命令执行数据库迁移
python ../../manage.py migrate
- 登录到MySQL数据库,并使用以下命令切换到
luffy数据库
use luffy;
- 查看数据库中的表格
show tables;
+-----------------------------+
| Tables_in_luffy |
+-----------------------------+
| auth_group |
| auth_group_permissions |
| auth_permission |
| django_admin_log |
| django_content_type |
| django_migrations |
| django_session |
| luffy_user |
| luffy_user_groups |
| luffy_user_user_permissions |
+-----------------------------+
10 rows in set (0.00 sec)
【四】项目数据库之隐藏密码
【1】引言
- 在项目数据库中将MySQL的用户名和密码直接写死在代码中是一种常见的做法。
- 这种做法存在一些潜在的安全风险
- 如果代码泄露或被黑客获取,他们可以轻松地获取到MySQL的用户名和密码,并且可以通过远程登录的方式进入数据库,进行操控、窃取或篡改数据。
- 可以远程登录
- 脱裤(拖库)
- 所有数据会被黑客获取到
- 卖钱
【2】泄露例子
- 华住酒店就因为在源代码中将数据库用户名和密码写死,导致源代码泄露,从而使得他们的数据遭到黑客获取。
- 上海随身办,其中一个新员工把密钥放在他们的博客上,结果导致了数据泄露事件。
【补充】获取系统环境变量的值
【1】项目中的环境变量
- 配置完环境变量,重启一下pycharm
- 如果环境变量没配置,就用默认的
- 如果配置了,就用配置的(项目上线时候,运维配置环境变量---》运维配置的环境变量的值----》开发根本不知道)
import os
print(os.environ.items())
-
上述代码片段展示了如何使用Python的
os.environ模块来获取系统环境变量的值。 -
当我们配置完环境变量并且重启了PyCharm后,可以通过
os.environ.items()来查看当前系统环境变量的键值对。 -
具体操作如下:
-
首先,在操作系统中配置所需的环境变量。
-
在代码中导入
os模块。 -
使用
os.environ来访问系统环境变量,将其作为字典进行操作。 -
使用
items()方法获取环境变量字典的键值对列表。 -
最后,将环境变量的键值对打印输出。
-
- 需要注意的是
- 如果环境变量没有进行配置,那么
os.environ将返回系统的默认值。- 但一旦运维人员在项目上线时配置了环境变量并设置了具体的值
- 开发人员实际上对这些配置的环境变量并不知情
- 而是直接使用运维配置的环境变量值。
- 通过这种方式
- 我们可以动态地获取系统环境变量的值
- 以便根据配置的不同灵活地进行应用程序开发和部署。
user = os.environ.get("USER", 'luffy')
pwd = os.environ.get("PWD", 'Luffy123?')
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'luffy', # 数据库名
'HOST': '192.168.139.1', # 远程数据库地址
'PORT': '3306', # 远程数据库端口
'USER': user, # 远程数据库用户名
'PASSWORD': pwd, # 远程数据库密码
'CHARSET': 'utf8', # 远程数据库编码集
}
}
【2】为什么一定要设置默认值
user = os.environ.get('USER', 'luffy')
pwd = os.environ.get('PWD', 'Luffy123?')
- 设置默认值是为了在获取环境变量时,能够应对一些特殊情况,
- 确保代码的正常执行。当使用
os.environ.get()方法获取环境变量时,如果环境变量不存在,或者未设置具体的值,该方法将会返回None。- 这可能会导致后续代码出现异常或错误。
- 为了避免这种情况,我们可以在
get()方法中设置一个默认值
- 例如在代码中的
user和pwd变量的例子中- 如果环境变量
USER和PWD没有设置具体的值- 那么它们的默认值将分别是'luffy'和'Luffy123?'。
- 这样即使环境变量没有被正确设置,代码也能够继续执行并使用默认值。
-
在企业级项目中的后端配置文件中,设置默认值是为了保证系统的正常运行和稳定性。
-
有以下几个原因:
-
安全性:
- 在设置配置项时,如果没有设置默认值,可能会导致敏感信息,默认为空,意味着没有任何限制。
- 而设置默认值可以确保即使没有正确配置环境变量或者配置文件,系统也能正常启动并使用默认值。
-
可靠性:
- 如果某个配置项没有设置默认值,在使用时没有进行有效的检查和处理,可能会导致程序崩溃或者异常情况。
- 通过设置默认值,可以避免系统因为配置项缺失而发生故障。
-
可维护性:
- 在多人开发或者项目迭代过程中,不同的开发人员可能会使用不同的配置项。
- 设置默认值可以确保即使没有进行个性化配置,系统仍然可以正常工作,简化了配置管理的复杂性。
-
兼容性:
- 在多个部署环境(例如开发环境、测试环境、生产环境等)中,可能存在不同的配置项需求。
- 通过设置默认值,可以确保系统在不同环境中具备基本的可用性,减少了配置项切换带来的问题。
-
-
总之,设置默认值有助于提高系统的容错能力和稳定性,保证系统可靠地运行。
【3】给环境变量设置失效时间
-
企业级项目中的环境变量一般是为了灵活配置和隔离不同环境所需的参数。
-
对于需要临时设置的环境变量,在系统重启时会失效,可以通过以下方式进行设置:
-
Windows
- 可以使用图形化界面进行设置,在“环境变量”对话框中添加或修改相应的环境变量,并确保勾选"用户变量"或"系统变量"。
- 若要临时设置环境变量,在命令提示符中输入
set VARIABLE_NAME=VALUE即可,该设置只在当前会话生效,系统重启时失效。
-
Mac/Linux
- 可以编辑用户主目录下的
.bash_profile文件或.zshrc文件(如果使用Zsh)来设置环境变量。.bash_profile文件:只在当前会话生效,关闭终端窗口后再次打开会话时就会失效。可以使用命令source .bash_profile使其立即生效。.zshrc文件:会永久生效,重新启动终端窗口也会保持有效。
- 可以编辑用户主目录下的
【4】临时设置环境变量
- 临时设置环境变量是在特定情况下临时修改环境变量的值,该设置只在当前会话生效。
- 临时设置:运维上线时候,手动设置,当前会话生效
- Windows
- 使用命令
set VARIABLE_NAME=VALUE来设置临时环境变量。- 例如:
set xx=xxx。
- 例如:
- 可以使用命令
echo %VARIABLE_NAME%来验证环境变量是否设置成功。
- 使用命令
- Mac/Linux
- 使用命令
export VARIABLE_NAME=VALUE来设置临时环境变量。- 例如:
export xx=xxx。
- 例如:
- 可以使用命令
echo $VARIABLE_NAME来验证环境变量是否设置成功。
- 使用命令
【5】 项目部署阶段
- 在项目部署阶段,需要进行一系列的准备工作,包括设置环境变量和执行shell脚本等。具体步骤如下:
- 打开一个命令窗口(如终端或命令提示符)。
- 根据操作系统进入相应的命令行界面。
- 设置环境变量:
- 根据项目需求,在命令窗口中使用适当的命令设置环境变量。
- 如前文所述,在不同操作系统中设置环境变量的方式有所不同。
- 执行shell脚本:
- 如果项目中有需要执行的shell脚本,可以使用适当的命令来运行。
- 例如,在Linux和macOS中,可以使用
sh命令或./来执行脚本文件。
- 打开一个命令窗口(如终端或命令提示符)。
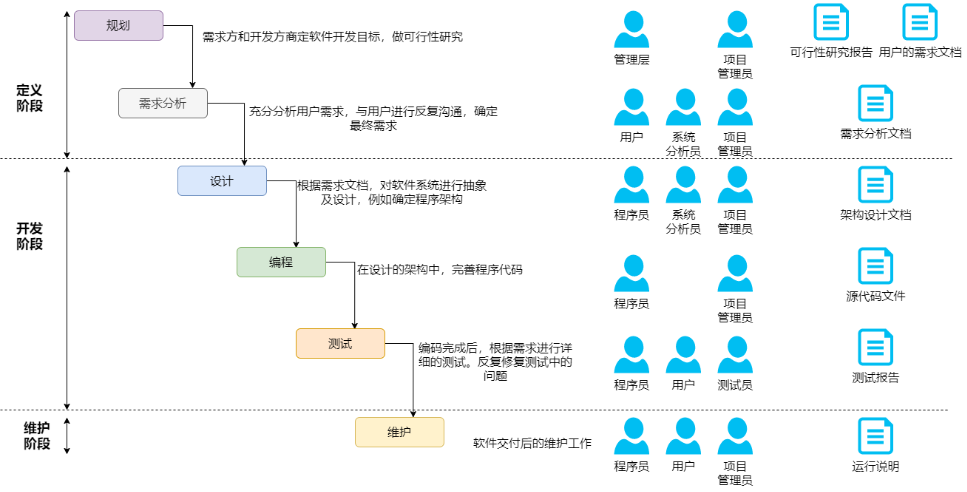
【补充】软件开发模式对比(瀑布、迭代、螺旋、敏捷)
【1】瀑布模式(Waterfall Model):
介绍:
- 瀑布模式是一种线性的开发模式,各个阶段按顺序依次执行,每个阶段严格依赖前一阶段的输出。
- 开发过程划分为需求分析、系统设计、编码、测试和运维等阶段。
- 每个阶段的结果都在下一个阶段开始之前独立完成。
优点:
- 明确定义和规划,适用于需求稳定的项目,能够对进度和成本进行较好的控制。
- 阶段清晰:从计划到开发最后到上线运行,三个阶段非常清晰。
- 时间顺序:每个阶段顺序必须是从上到下,严格按照时间先后进行。
- 环环相扣:在每一个阶段都必须有产出物然后才能进入到下一个阶段进行。
- 黑盒模式:每个阶段都有各自的角色和分工,各自只关心自己的任务。比如需求阶段开发人员无需关注。
缺点:
- 缺乏灵活性,无法应对需求变化,不利于及时反馈和快速迭代。
- 需求隔离:由于各阶段的人员只能接触到自己工作范围内的东西,所以对客户需求的理解程度高低不等,开发人员更像是定义为流水线上的工人。
- 变更代价大:既然叫做瀑布,就意味着不应该走回头路。否则如果出现返工,付出的代价会很大。需求变更,编码人员会很强的抵触情绪。
- 束缚创造性:由于强调文档管理,所以管理人员会比较喜欢,但是他束缚了开发人员的创造性。
- 周期漫长:整个开发持续的生命周期很长,需求和设计的时间会耗费特别多,有时候会占用三分之一甚至更多时间,这样整个周期就会变长,大都在半年到一年左右的时间,所以更适合需求相对稳定的大项目。
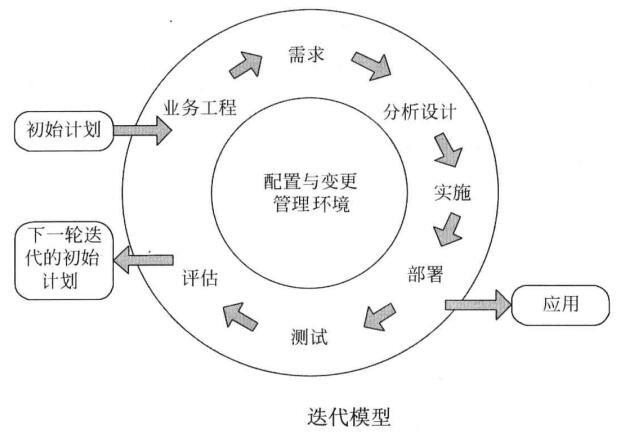
【2】迭代模式(Iterative Model):
介绍:
- 迭代模式是通过将开发过程划分为多个迭代周期来实现软件开发。
- 每个迭代周期包含需求收集、设计、开发、测试等阶段,并产生可交付的软件部分。
- 每个迭代周期之后会对之前的结果进行回顾和反馈,可以在后续迭代中进行修改和改进。
优点:
- 能够通过快速迭代获取实际用户反馈,及时适应需求变化,减少风险。
缺点:
- 每个迭代周期的时间和成本较难预测,对项目管理要求较高。
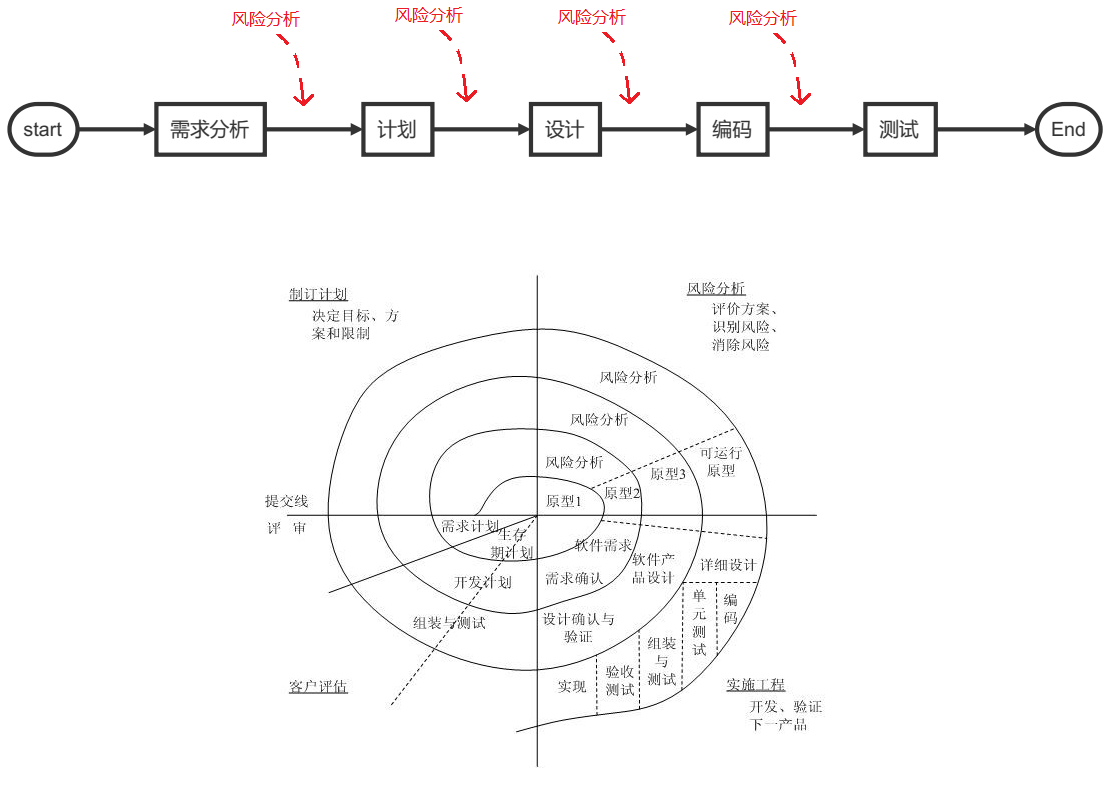
【3】螺旋模式(Spiral Model):
介绍:
- 螺旋模式是一种迭代的风险驱动开发模式,结合瀑布模式和迭代模式的特点。
- 按照轮回的方式执行需求分析、风险评估、开发和评审等阶段,具有反复循环的特征。
- 每个螺旋周期都会生成一个原型,用于验证需求、风险和技术解决方案。
优点:
- 风险驱动,能够在早期发现和解决问题,提高项目成功率。
缺点:
- 需要更多的资源和时间,对项目管理要求较高。
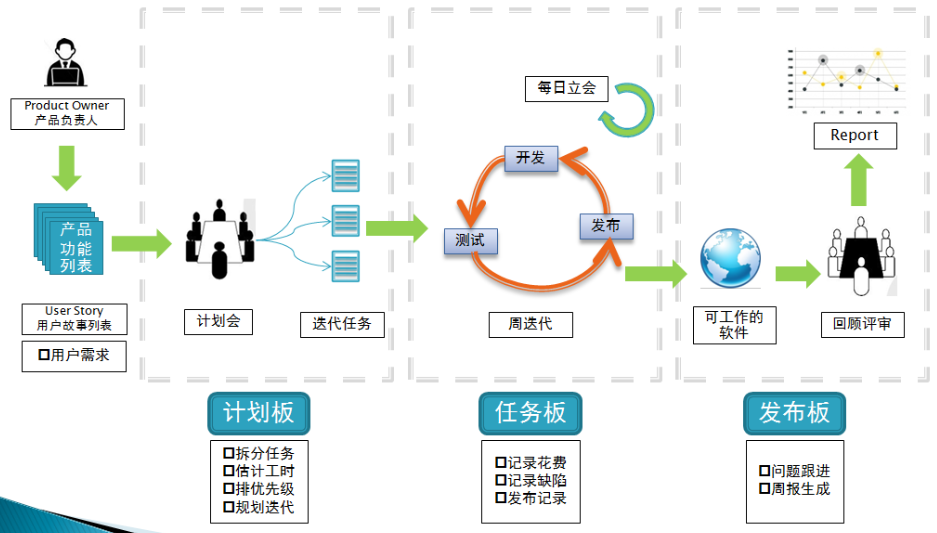
【4】敏捷模式(Agile Model):
介绍
- 敏捷模式是一种基于迭代和自组织的软件开发方法,强调团队合作、快速交付和持续改进。
- 开发过程划分为多个迭代周期(通常为2-4周)。
- 每个迭代周期通过需求收集、设计、开发、测试和评审等环节,交付适用的软件部分。
特点:
- 「个体与交互」胜过「过程与工具」
- 「可以工作的软件」胜过「面面具到的文挡」
- 「客户协作」胜过「合同谈判」
- 「响应变化」胜过「遵循计划」
优点:
- 能够快速响应需求变化,实时反馈,保障客户满意度(更高的客户满意度)
- 提高团队合作和沟通效率(更高的团队满意度)
- 更快交付价值
- 更低的风险
- 拥抱变化
- 更好的质量
- 持续改进
缺点:
- 项目进展较快,对团队成员的技术能力和协作能力要求较高
- 很难进行准确的资源规划
- 很难准确的定义“轻量的“或必要的文档
- 很难把握整体产品的一致性
- 很难预测有限的终点
- 很难有效地进行度量
(1)迭代式开发生命周期
- 该生命周期方法将软件开发过程划分为若干个迭代周期,每个迭代周期通常是一个固定的时间段(如2周至4周)。
- 每个迭代周期内,团队通过一系列活动来完成需求分析、设计、开发、测试和发布等任务。
- 每个迭代周期都会产生一个可用且具备部分功能的产品版本,也称为迭代增量。
- 通过不断地迭代,系统逐步完善,同时团队可以更好地适应变化和用户反馈
- 迭代就是不断丰富细节的过程。
- 每一次的迭代,我们都应该让这个项目更加的清晰明了,细节也一步步地完善。

(2)增量式开发生命周期
- 该生命周期方法强调快速迭代和交付具备部分功能的产品版本。
- 与迭代式开发不同的是,增量式开发的每个阶段都会产生一个部分功能的增量,并且这些增量会被累积,最终形成完整的产品。
- 在增量式开发中,每个阶段的目标是实现特定的、独立的功能,而不是按照模块或组件进行划分。
- 这种方法可以提高团队对开发进度和需求变化的可见性,并且能够更早地将软件功能交付给用户
- 迭代的时候,有轮廓,不断完善细节。
- 增量,没有整体轮廓,上来就是细节完整的一个部分,不断地一部分一部分地完成,最终形成一个完整的产品。

(3)混合式开发生命周期
- 混合式开发生命周期是结合了迭代式和增量式开发的特点,灵活选择并结合两种方法中的最佳实践。
- 在混合式开发生命周期中,根据项目的特点和需求,灵活地选择使用迭代式或增量式开发,或者采用两者的结合方式。
- 这样可以使团队更好地应对变化、降低风险,并根据项目的具体情况灵活调整开发的策略和计划
【对比】
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17642690.html

