月考解释版
【一】填空题
1、Python安装扩展库常⽤的是___⼯具
-
Python安装扩展库常用的是pip工具。
-
pip是Python中的一个包管理工具,可以帮助用户完成Python扩展库的安装、升级、卸载等操作。
-
用户只需要在命令行中输入pip命令加上相应的参数就可以完成相应的操作。
-
比如,要安装一个新的Python扩展库,可以使用"pip install 库名"命令。
2、在Python中__表⽰空类型
-
在Python中,None表示空类型。
-
它是Python中的一个内建常量,表示一个空值或者空对象。
-
它通常用于初始化变量、作为函数的默认返回值,以及在条件语句中作为判断条件等场景。
-
可以通过判断变量是否为None来判断它是否已经被赋值,从而避免变量未被赋值导致的程序错误。
-
需要注意的是,None不同于False或者0,因为它是一个完全不同的对象,只有在布尔值判断时才会被转化为False。
3、列表、元组、字符串是Python的_____(有序?⽆序)序列
-
列表、元组和字符串都是Python的有序序列。
-
其中,有序序列指的是它们的元素按照一定的顺序排列,并且可以通过索引或切片进行访问和修改。
-
与之相对的是无序序列,如字典和集合,它们的元素没有固定的顺序,不支持索引和切片。
-
在Python中,列表和字符串是可变序列,也就是说它们的元素可以被修改,而元组是不可变序列,一旦被创建就不能被修改,只能通过创建新的元组来实现。
4、查看变量类型的Python内置函数是__ __
-
查看变量类型的Python内置函数是
type()。 -
可以通过
type(变量名)来获取变量的类型。 -
例如,
type(3)会返回<class 'int'>,表示该变量是一个整型。
5、查看变量内存地址的Python内置函数是__ __ _
-
查看变量内存地址的Python内置函数是
id()。 -
可以通过
id(变量名)来获取变量的内存地址。 -
例如,
id(3)会返回一个整数,表示整型变量3在内存中的地址。 -
注意,不同的解释器和不同的机器可能会返回不同的地址值。
6、Python运算符中⽤来计算整商的是_____
-
Python运算符中用来计算整商的是
//。 -
它会将两个操作数的商向下取整为整数,并返回结果。
-
例如,
9 // 2的结果为4,因为 9 / 2 的商为 4.5,向下取整后为 4。 -
需要注意的是,这个运算符只能用于数字类型的操作数。
7、Python运算符中⽤来计算集合并集的是___
-
Python运算符中用来计算集合并集的是
|。 -
在Python中,
|运算符可以用于计算两个集合的并集,它返回一个新集合,其中包含两个集合中所有不重复的元素。 -
例如,对于两个集合 A 和 B,它们的并集可以用
A | B来计算。
8、表达式[1, 2, 3]*3的执⾏结果为__ __ __
-
表达式
[1, 2, 3]*3的执行结果为[1, 2, 3, 1, 2, 3, 1, 2, 3] -
即列表
[1, 2, 3]中的元素重复出现了三次,形成了一个新的包含九个元素的列表。 -
这是因为
*运算符在列表中表示重复操作。
9、语句x = 3==3, 5执⾏结束后,变量x的值为__ ___
-
执行语句
x = 3==3, 5后,变量x的值为(True, 5)。 -
这是因为
,运算符在 Python 中具有较低的优先级,因此先进行了比较运算3==3,其结果为True,然后将其与整数 5 一同赋值给变量x,最终x的值为元组(True, 5)。
10、已知 x = 3,那么执⾏语句 x += 6 之后,x的值为_______
-
执行语句
x += 6相当于将变量x的值与 6 相加后再赋值给x, -
因此在已知
x = 3的情况下 -
执行
x += 6后,x的值变为9。 -
因此,表达式的值为
9。
11、已知 x = 3,并且id(x)的返回值为 496103280,那么执⾏语句 x += 6 之后,表达式 id(x) == 496103280 的值为**___`*
- 针对本题
x = 3
print(id(x))
# 140735833966320
x += 6
print(id(x))
# 140735833966512
-
在已知
x = 3且id(x) == 496103280的情况下,执行语句x += 6后,变量x的值变为9。 -
由于 Python 对于小整数对象有缓存机制,在 Python 中,小整数对象
-5到256之间的对象都是被提前创建好并缓存的,因此它们的 id 是固定的。 -
而对于其他整数对象,它们的 id 是不确定的,可能随着运行环境和时间的不同而发生变化。
-
因此,在 Python 3.7 及之前的版本中,
id(9)的返回值可能不等于496103280;而在 Python 3.8 及之后的版本中,id(9)的返回值可能等于496103280。 -
总之,由于整数对象的 id 是不确定的,因此表达式
id(x) == 496103280的值也是不确定的。
12、已知 x = 3,那么执⾏语句 x *= 6 之后,x的值为____
-
在执行语句
x *= 6后,变量x的值将会被更新为18。 -
这是因为
x *= 6相当于x = x * 6,即将变量x的值乘以6后再赋值给变量x。 -
因此,执行后
x的值为18。
13、表达式“[3] in [1, 2, 3, 4]”的值为____
-针对本题
- 我的理解是列表无法匹配另一个列表的子列表 可以使用 3 in [1, 2, 3, 4] ---> True
print([3] in [1, 2, 3, 4])
# False
-
表达式
3 in [1, 2, 3, 4]返回的值为True。 -
这是因为
in运算符用于检查是否包含某个元素,如果包含则返回True,否则返回False。 -
在这里,列表
[1,2,3,4]包含元素3,因此该表达式的结果为True。
14、列表对象的sort()⽅法⽤来对列表元素进⾏原地排序,该函数返回值为 ()
sort()方法对于列表是原地排序,即在原列表对象上排序,不会返回任何值,因此sort()方法的返回值为None。
15、假设列表对象aList的值为[3, 4, 5, 6, 7, 9, 11, 13, 15, 17],那么切⽚aList[3:7]得到的值是**____
-
切片
aList[3:7]包括索引为3到索引为6的元素,不包括索引为7的元素。 -
因此得到的值为
[6, 7, 9, 11]。
16、任意长度的Python列表、元组和字符串中最后⼀个元素的下标为____
-
最后一个元素的下标为
-1。在Python中,可以使用负数作为索引来访问序列的倒数元素 -
例如:
aList[-1]访问列表aList的最后一个元素。
17、Python语句''.join(list('hello world!'))执⾏的结果是________
-
Python语句
''.join(list('hello world!'))执行的结果是字符串'hello world!'。 -
这段代码先将字符串
'hello world!'转化成列表['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!'] -
然后再用空字符串
''作为连接符,将其中的每个元素按顺序连接成一个新的字符串。 -
最终的结果就是
'hello world!'。
18、转义字符’\n’的含义是_______
-
转义字符
\n表示换行符,用于在字符串中表示一个新行的开始。 -
当遇到字符串中的
\n时,程序会自动将其替换为一个可见的换行符。 -
这在多数编程语言和文本编辑器中都是通用的。
19、Python语句list(range(1,10,3))执⾏结果为_______
-
Python语句
list(range(1,10,3))执行结果为[1, 4, 7]。 -
这是因为
range(start, stop, step)函数返回一个由start开始、不超过stop的整数序列,步长为step。 -
在上述例子中,
start值为1,stop值为10(不包括10),步长为3,因此序列为1、4、7。 -
调用
list()函数将其转换为列表后,输出结果即为[1, 4, 7]。
20、 Python 中异常处理时,通常把可能发⽣异常的代码放在___语句中。
-
Python 中异常处理时,通常把可能发生异常的代码放在
try语句中。 -
try语句后面可以跟一个或多个except语句,用于捕捉并处理可能发生的异常。 -
如果
try语句块中的代码执行过程中出现异常,程序将跳转到第一个匹配该异常类型的except语句中进行处理。 -
如果没有匹配的
except语句,异常将向上传递给调用者,直到被处理为止。try-except语句的一般形式如下:
try:
# 可能发生异常的代码
except Exception1:
# 处理 Exception1 异常
except Exception2:
# 处理 Exception2 异常
else:
# 如果没有发生异常执行的代码
finally:
# 无论是否发生异常最后都要执行的代码
-
其中
Exception1和Exception2是异常类型,可以是任何内置或自定义异常类。 -
else语句块中的代码将在try语句块中的代码执行完毕之后,且没有发生任何异常时被执行。 -
finally语句块中的代码将始终被执行,无论try语句块中的代码是否发生了异常。
21、 Python 中对两个整数进⾏整除时,使⽤的符号为_____。
-
在 Python 中对两个整数进行整除操作时,使用的符号为
//。 -
例如,表达式
7 // 3的结果为2,即7除以3的商向下取整后的结果。 -
要注意的是,如果被除数和除数都是整数,则使用
/进行除法操作会得到浮点数结果。 -
如果要进行地板除法操作,即将商向下取整,则需要使用
//运算符。
22、已知a = [1, 2, 3]和b = [1, 2, 4],那么id(a[1])==id(b[1])的执⾏结果为___
a = [1, 2, 3]
b = [1, 2, 4]
print(id(a[1]) == id(b[1]))
# True
23、切⽚操作list(range(6))[::2]执⾏结果为____
-
切片操作
list(range(6))[::2]的含义是从0到5之间的整数列表进行切片,步长为2,即每两个元素取一个。 -
所以这个操作的执行结果应该是包含0、2、4三个元素的列表,即
[0, 2, 4]。
24、表达式 'ab' in 'acbed' 的值为____
-
表达式
'ab' in 'acbed'的值为False。 -
因为字符串
'acbed'中不包含子串'ab',所以该表达式的值为False。
25、假设n为整数,那么表达式 n&1 == n%2 的值为_____
-
假设n为整数,表达式
n&1 == n%2的值为True。 -
这是因为
n&1是n和1的与运算,结果只有在n为奇数时才为1,否则为0; -
n%2是n除以2的余数,结果只有在n为奇数时候才为1,否则为0。 -
所以,当n为奇数时,两个表达式的结果都为1;
-
当n为偶数时,两个表达式的结果都为0。因此,该表达式的值为
True。
26、语句 x = (3,) 执⾏后x的值为_______
-
语句
x = (3,)执行后,x的值为一个只包含一个元素3的元组,即x = (3,)。 -
需要注意的是,如果省略逗号,则会被认为是一个普通的整数而不是元组,如
x = (3)则x的值为整数3。
27、语句 x = (3) 执⾏后x的值为____
-
语句
x = (3)执行后,x的值为整数3,而不是一个元组。 -
需要注意的是,只有在元组中只包含一个元素时,需要在这个元素后面加上逗号,才能表示这是一个元组,否则会被当做其他类型的数据来处理。
-
因此,如果想要定义一个只有一个元素的元组,应该按如下所示的方式定义:
x = (3,)。
28、已知x=3和y=5,执⾏语句 x, y = y, x 后x的值是
-
执行语句
x, y = y, x后,变量x的值将会是5。 -
这是因为,这条语句交换了x和y的值:将y的值赋给了x,将x的值赋给了y。
-
因此,最终x的值是之前y的值,即5。
-
同样地,y的值是之前x的值,即3。
-
所以,经过这条语句的执行后,x的值为5,y的值为3。
29、字典对象的___⽅法可以获取指定“键”对应的“值”,并且可以在指定“键”不存在的时候返回指定值,如果不指定则返回None
- 字典对象的
get方法可以获取指定“键”对应的“值”,并且可以在指定“键”不存在时返回指定值(如果不指定则返回None)。其函数签名如下:
get(key[, default])
-
其中,
key为要查找的字典键;default为可选参数,表示在指定的键不存在时返回的默认值,默认值为None。 -
例如:
my_dict = {'a': 1, 'b': 2, 'c': 3}
# 获取 'a' 对应的值,输出 1
print(my_dict.get('a'))
# 获取 'd' 对应的值,由于 'd' 不存在,返回 None
print(my_dict.get('d'))
# None
# 获取 'd' 对应的值,由于 'd' 不存在,返回默认值 -1
print(my_dict.get('d', -1))
# -1
30、字典对象的_____⽅法返回字典中的“键-值对”列表
- 字典对象的
items方法可以返回字典中的“键-值对”列表,其函数签名如下:
items()
-
该方法会返回一个包含所有“键-值对”的元组列表。每个元组包含两个元素,第一个元素是键,第二个元素是对应的值。
-
例如:
my_dict = {'a': 1, 'b': 2, 'c': 3}
# 获取键-值对列表,输出 [('a', 1), ('b', 2), ('c', 3)]
print(my_dict.items())
# dict_items([('a', 1), ('b', 2), ('c', 3)])
- 需要注意的是,Python 3 中
items()返回的是一个“字典视图”,不是列表。- 但是可以像列表一样遍历它或者将其转化为列表使用。
31、字典对象的____⽅法返回字典的“键”列表
- 字典对象的
keys方法可以返回字典的“键”列表,其函数签名如下:
keys()
-
该方法会返回一个由字典的所有键组成的列表。
-
例如:
my_dict = {'a': 1, 'b': 2, 'c': 3}
# 获取键列表,输出 ['a', 'b', 'c']
print(my_dict.keys())
# dict_keys(['a', 'b', 'c'])
- 需要注意的是,Python 3 中
keys()返回的是一个“字典视图”,不是列表。但是可以像列表一样遍历它或者将其转化为列表使用。
32、字典对象的______⽅法返回字典的“值”列表
- 字典对象的
values()方法返回字典的“值”列表。- 该方法可以用于获取包含字典中所有值的可迭代对象。例如:
my_dict = {'name': 'Alice', 'age': 25, 'gender': 'female'}
values_list = my_dict.values() # 获取字典的值列表
print(values_list) # 输出 dict_values(['Alice', 25, 'female'])
- 需要注意的是,在 Python 3 中,
values()方法返回的是一个字典视图(dictionary view),它会动态地跟随字典内容的变化而自动更新。- 如果需要得到一个静态的值列表,可以使用
list()函数将字典视图转换为列表:
- 如果需要得到一个静态的值列表,可以使用
my_dict = {'name': 'Alice', 'age': 25, 'gender': 'female'}
values_list = list(my_dict.values()) # 获取字典的静态值列表
print(values_list) # 输出 ['Alice', 25, 'female']
33、已知 x = {1:2},那么执⾏语句 x[2] = 3之后,x的值为____
- 执行语句
x[2] = 3后, 字典x将新增一个键值对,其键为2,值为3。因此,执行完后,x的值为{1:2, 2:3}。
34、表达式set([1, 1, 2, 3])的值为________
-
set([1, 1, 2, 3])这个表达式的作用是将列表[1, 1, 2, 3]转换成集合。 -
由于集合不包含重复元素,因此结果会去除列表中的重复元素后得到
{1, 2, 3}。 -
因此,表达式
set([1, 1, 2, 3])的值为{1, 2, 3}。
35、已知 x = {'a':'b', 'c':'d'},那么表达式 'a' in x 的值为_____
- 给定字典
x = {'a':'b', 'c':'d'}。 - 表达式
'a' in x的作用是判断字典x中是否存在 key 为'a'的键。 - 由于
x中包含键'a'- 因此
'a' in x的值为True。
- 因此
36、Python 中上下⽂管理器使⽤的关键字是____。
- Python 中上下文管理器通常使用
with关键字。- 使用上下文管理器可以自动获取和释放资源,方便代码的编写和管理。
- 例如:
with open('file.txt', 'r') as f:
# do something with the file
- 在上面的代码中,
with语句通过创建上下文管理器open('file.txt', 'r')- 使我们可以通过变量
f访问file.txt文件 - 在代码块结束后,Python 会自动关闭文件以释放资源。
- 使我们可以通过变量
37、已知 x = {'a':'b', 'c':'d'},那么表达式 'b' in x.values() 的值为______
-
表达式
'b' in x.values()的值为 True。 -
这是因为
'b'是字典x中的一个值,判断值是否在字典中可以用in关键字x.values()函数返回所有的值组成的列表,即['b', 'd']。- 在这个列表中查找值
'b'返回 True。
38、表达式 0 or 5 的值为_____
-
表达式
0 or 5的值为 5。 -
这是因为 or 运算符会从左向右依次对两个值进行求值,
- 如果第一个值为 False,则返回第二个值;
- 如果第一个值为 True,则直接返回第一个值。在Python中
- 0视为 False,而非 0(包括空字符串 ""、空列表 []、空字典 {} 等)都视为 True。
- 因此,表达式
0 or 5的第一个值为 False,返回第二个值 5。
39、表达式 3 and not 5 的值为_____
表达式 3 and not 5 的值为 False。
在 Python 中,and 运算符会返回第一个 False 值或最后一个值(如果所有的值都是 True),而not 运算符用于对布尔值进行取反操作。因此,not 5 的结果是 False,而 3 and False 的结果也是 False。
40、表达式 3 ** 2 的值为_____
-
表达式
3 ** 2的值为9。 -
双星号(**)是Python中的幂运算符,用于求某个数的n次方。
- 在表达式
3 ** 2中,表示计算 3 的 2 次方,即 3 的平方,其结果为 9。
- 在表达式
41、表达式 3 * 2的值为___
-
表达式
3 * 2的值为6。 -
乘号(*)是Python中的乘法运算符,用于计算两个数的积。
- 在表达式
3 * 2中,表示计算 3 乘 2,即 3 和 2 的乘积,其结果为 6。
- 在表达式
42、已知字符串 x = 'hello world',那么执⾏语句 x.replace('hello', 'hi')之后,x的值为___
-
执行语句
x.replace('hello', 'hi')之后,x 的值仍然为'hello world'。 -
replace()方法是用于字符串替换的内置方法。- 在执行
x.replace('hello', 'hi')时,它会将字符串 x 中所有匹配的子串'hello'替换为字符串'hi',并返回一个新字符串对象。 - 因此,在上述语句中得到的结果应该被赋值给变量 x,即
x = x.replace('hello', 'hi')。
- 在执行
-
如果想改变原始字符串的值,可以直接对变量 x 进行重新赋值,例如:
x = 'hello world'
x = x.replace('hello', 'hi')
print(x) # 输出: 'hi world'
43、已知列表 x = [1, 2, 3],那么执⾏语句 x.pop(0) 之后,x的值为_____
- 执行语句
x.pop(0)会删除列表 x 的第一个元素,并返回被删除的元素值。- 因此,执行完该语句后,列表 x 的值为
[2, 3]。 - 同时,返回值为
1。
- 因此,执行完该语句后,列表 x 的值为
- 示例代码如下:
x = [1, 2, 3]
deleted_value = x.pop(0)
print(x) # 输出: [2, 3]
print(deleted_value) # 输出: 1
44、已知列表 x = [1, 2, 3],那么执⾏语句 x.insert(0, 4) ,x的值为___
- 执行语句
x.insert(0, 4)会在列表 x 的第一个位置(即下标为 0 的位置)插入元素值为4的元素。- 因此,执行完该语句后,列表 x 的值为
[4, 1, 2, 3]。
- 因此,执行完该语句后,列表 x 的值为
- 示例代码如下:
x = [1, 2, 3]
x.insert(0, 4)
print(x) # 输出: [4, 1, 2, 3]
45、语句 print(re.match('abc', 'defg')) 输出结果为_____
- 执行语句
re.match('abc', 'defg')使用正则表达式abc在字符串defg中进行匹配,由于在字符串defg中无法找到符合该正则表达式的子串 - 因此输出结果为
None(即没有匹配成功)。- 所以,执行语句
print(re.match('abc', 'defg'))输出结果为None。
- 所以,执行语句
- 需要注意的是,如果字符串中可以找到符合正则表达式的子串,则
re.match()会返回一个match对象,而不是None。
46、表达式 'C:\Windows\notepad.exe'.startswith('C:') 的值为_____
-
表达式
'C:\Windows\notepad.exe'.startswith('C:')的值为True。 -
该表达式可以判断字符串
'C:\Windows\notepad.exe'是否以子串'C:'开头。 -
由于该字符串的开头确实是
'C:',所以该表达式的值为True。- 需要注意的是,在 Python 中,反斜杠
\是转义字符 - 因此在表示 Windows 路径时要使用双反斜杠或者在字符串前加上
r前缀
- 需要注意的是,在 Python 中,反斜杠
-
例如
r'C:\Windows\notepad.exe'。
47、在循环语句中,__语句的作⽤是提前结束本层循环
-
在循环语句中,
break语句的作用是提前结束本层循环。 -
当程序执行到
break语句时,循环会立即停止,并且程序会跳出整个循环体,继续执行循环外的后续代码。需要注意的是,break语句只能用在循环语句(如for和while)中。 -
下面是一个简单的示例,展示了如何使用
break语句提前结束循环:
for i in range(1, 10):
if i == 5:
break
print(i)
# 1
# 2
# 3
# 4
- 在上述代码中,循环从 1 遍历到 9,当遍历到
i等于 5 时,执行break语句提前结束循环。
48、在循环语句中,___语句的作⽤是提前进⼊下⼀次循环
-
在循环语句中,
continue语句的作用是提前进入下一次循环。 -
当程序执行到
continue语句时,循环会立即跳过本次循环中剩余未执行的语句,直接进入下一次循环。需要注意的是,continue语句只能用在循环语句(如for和while)中。 -
下面是一个简单的示例,展示了如何使用
continue语句提前进入下一次循环:
for i in range(1, 6):
if i == 3:
continue
print(i)
# 1
# 2
# 4
# 5
- 在上述代码中,循环从 1 遍历到 5,当遍历到
i等于 3 时,执行continue语句,跳过本次循环中剩余未执行的语句,然后立即进入下一次循环。
49、已知 x = [3, 7, 5],那么执⾏语句 x = x.sort(reverse=True)之后,x的值为_____
-
执行语句
x = x.sort(reverse=True)之后,x的值为None。 -
这是因为在 Python 中,列表对象的
sort()方法没有返回值,它会就地修改原列表对象,并返回None。 -
因此,如果想要对列表进行排序,并将排序结果赋值给原变量
x,可以按照以下两种方式之一来实现: -
方式一:
- 使用sorted()函数
x = [3, 7, 5]
x = sorted(x, reverse=True)
print(x) # 输出 [7, 5, 3]
- 方式二:
- 先调用sort()方法对原列表进行排序,然后再次将结果赋值给原变量
x
- 先调用sort()方法对原列表进行排序,然后再次将结果赋值给原变量
x = [3, 7, 5]
x.sort(reverse=True)
print(x) # 输出 [7, 5, 3]
需要注意的是,以上两种方式都会覆盖掉原来的列表对象,因此在实际应用中需要谨慎处理。
50、已知 x = (3,),那么表达式 x * 3 的值为_____
-
执行表达式
x * 3后,结果为(3, 3, 3)。 -
在 Python 中,元组类型的
*运算符表示复制当前元组对象,生成一个新的元组对象。 -
对于本题中的
x = (3,),它是一个长度为1的元组,其中唯一的元素是整数3。因此,执行x * 3运算,就相当于把元组(3,)复制3次,生成一个由3个元素为3的元组组成的新元组(3, 3, 3)。
51、下面程序的输出结果是:
x=True
y=False
z=False
if x or y and x:
print("yes")
else:
print("no")
-
这段代码的输出结果是
yes。 -
在 Python 中,逻辑运算符
and拥有更高的优先级比or,因此它会先运算y and x表达式,然后再将其结果与变量x的值进行或运算。对于这个表达式的运算过程,可以手动添加括号来进行更加明确的表示:
if x or (y and x):
print("yes")
else:
print("no")
-
变量
x的值为True,因此x or (y and x)的结果也为True,符合条件,所以代码会输出"yes"。 -
需要注意的是,如果表达式的运算顺序不确定,应该使用括号来明确表示运算的优先级。
【二】程序分析题
1、阅读下列程序代码,当⽤户分别输⼊ 15 和 35 时,程序执⾏结果为1535_。

num_1 = input("请输⼊第⼀个数: ")
num_2 = input("请输⼊第⼆个数: ")
print(num_1 + num_2)
# 请输⼊第⼀个数: 15
# 请输⼊第⼆个数: 35
# 1535
- 这段代码的输出结果并非两个输入数的和,而是两个输入数的字符串连接。
- 这是因为input()函数默认读取的数据类型是字符串类型,需要使用int()函数将输入的字符串转换为整数,然后再进行加法运算才能得到正确的结果。
2、阅读下列程序代码,该程序执⾏的结果为__24__。

sum = 0
for i in range(10):
if i // 3 == 2:
continue
sum = sum + i
print(sum)
# 24
-
这段代码的作用是对0到9的整数进行循环遍历,将除以3的余数为2的数跳过,其余数值累加起来,并输出最后的结果。
-
在本代码中,i // 3表示i除以3得到的商(整数部分)
- 如果商为2,则跳过当前循环,不再执行后面的语句,直接进入下一次循环。
-
sum = sum + i则表示将非除以3余数为2的i值进行累加,最终输出累加的结果。
-
因此,经过计算,最终的输出结果应该是24。
3、阅读下列程序代码,该程序执⾏的结果为____18__。

i = 1
while i < 6:
i = i + 1
else:
i = i * 3
print(i)
# 18
-
这段代码的作用是,使用while循环对i从1开始进行遍历,每次遍历加1,直到i大于等于6时退出循环。在循环结束后,对i乘以3,最终输出i的值。
-
根据代码,在while循环退出后,i将大于等于6,因此进入else语句块中,执行i = i * 3,将i乘以3,最终输出结果为18。
4、阅读下列程序代码,该程序执⾏的结果为______。

a = 10
b = 20
def func(temp_a, temp_b): # 定义函数
a, b = temp_b, temp_a
func(a, b) # 调⽤函数
print(a) # 打印结果
func(a, b)
# RecursionError: maximum recursion depth exceeded
# 无限递归:无解
- 这段代码定义了一个名为
func的函数,并传入两个参数temp_a和temp_b,函数内部使用temp_a和temp_b来操作两个全局变量a和b,然后再次调用自身函数。- 由于函数体内部没有什么终止条件,因此进入了无限循环(递归)
- 最终导致程序抛出"RecursionError: maximum recursion depth exceeded"异常。
- 这个异常表示,在Python中,递归调用所允许的最大嵌套层数已经达到或超过了限制。
- 因此,这段代码会进入一个无限递归状态,最终导致程序陷入假死状态,无法得到有效的处理结果。
5. 下列表达式输出的值是?
a = 10
b = 20
def func(temp_a, temp_b): # 定义函数
a, b = temp_b, temp_a
func(a, b)
print(a) # 打印结果
# 10
【三】编程题
1. 车牌区域划分,请根据车牌信息,分析出各省的车牌持有数量.
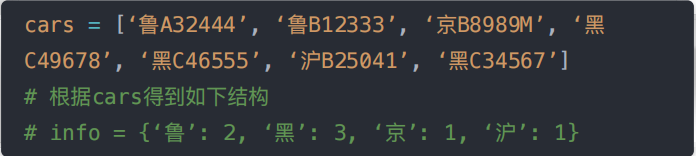
cars = ['鲁A32444', '鲁B12333', '京B8989M', '黑C49678', '黑C46555', '沪B25041', '黑C34567']
infos = {}
for info in cars:
if info.startswith('鲁'):
if '鲁' not in infos:
infos['鲁'] = 0
infos['鲁'] += 1
# print(infos)
elif info.startswith('京'):
if '京' not in infos:
infos['京'] = 0
infos['京'] += 1
elif info.startswith('黑'):
if '黑' not in infos:
infos['黑'] = 0
infos['黑'] += 1
elif info.startswith('沪'):
if '沪' not in infos:
infos['沪'] = 0
infos['沪'] += 1
print(infos)
# {'鲁': 2, '京': 1, '黑': 3, '沪': 1}
cars = ['鲁A32444', '鲁B12333', '京B****M', '黑C49678', '黑C46555', '沪B25041', '黑C34567']
infos = {}
for car in cars:
key = car[0] # 获取车牌号的第一个字符,即省份简称
if key in infos: # 如果该省份已经存在于字典中,则数量加1
infos[key] += 1
else: # 如果该省份不存在于字典中,则添加一个新的键值对,并将数量设为1
infos[key] = 1
print(infos) # 输出结果
# {'鲁': 2, '京': 1, '黑': 3, '沪': 1}
- 其中,
infos是一个空字典,表示最终的统计结果。 - 程序使用一个
for循环遍历整个车牌列表cars,对于每个车牌,都从第一个字符中获取省份简称key。- 然后,如果
key已经存在于infos中,则将其对应的值(即车牌数量)加1; - 否则,就将
key作为一个新的键添加到infos中,并将其对应的值设为1。
- 然后,如果
- 最终得到的
infos就是所要求的字典。
2. 统计字符串“Hello, welcome to my world.” 中字母 w 出现的次数。
sty = 'Hello, welcome to my world.'
count = 0
for line in sty:
if line == 'w':
count += 1
else:
print(f'当前字母:>>>{line}不符')
print(count)
# 2
- 你可以使用Python的字符串方法
count()统计字母w在给定字符串中出现的次数。具体方法如下:
s = "Hello, welcome to my world."
count = s.count('w')
print(count)
# 2
-
其中,
count表示字母w在给定字符串s中出现的次数。调用字符串的count()方法,并传入需要统计的字符作为参数即可。 -
注意事项:
count()方法区分大小写,如果需要忽略大小写,可以先将字符串转换为全大写或全小写再进行统计。
3.定义一个函数,输出1~100中偶数之和
def func_name():
n = 0
temp = 0
while True:
if n > 100:
break
if n % 2 == 0:
temp += n
n += 1
else:
print(f'当前不是偶数:>>>>{n}')
n += 1
continue
return temp
temp = func_name()
print(temp)
- 以下是Python代码实现,定义一个函数名为
sum_of_even_numbers()来计算1~100中偶数之和,并输出结果:
def sum_of_even_numbers():
# 定义变量来保存偶数之和
sum_of_evens = 0
# 遍历1~100中的每个数字
for i in range(1, 101):
# 如果当前数字是偶数,则加到偶数之和上面
if i % 2 == 0:
sum_of_evens += i
# 输出结果
print("1~100中的偶数之和为:", sum_of_evens)
sum_of_even_numbers()
# 1~100中的偶数之和为: 2550
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17492831.html
