Python语法入门
昨日回顾
引言
- 我们学习python语言是为了控制计算机、让计算机能够像人一样去工作
- 所以在python这门语言中,所有语法存在的意义都是为了让计算机具备人的某一项技能,这句话是我们理解后续所有python语法的根本。
【一】变量
【1】什么是变量
- 变量就是可以变化的量,量指的是事物的状态
- 比如人的年龄、性别,游戏角色的等级、金钱等等
【2】为什么要有变量
- 为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的
- 详细地说:
- 程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化'
- 详细地说:
【3】变量的使用
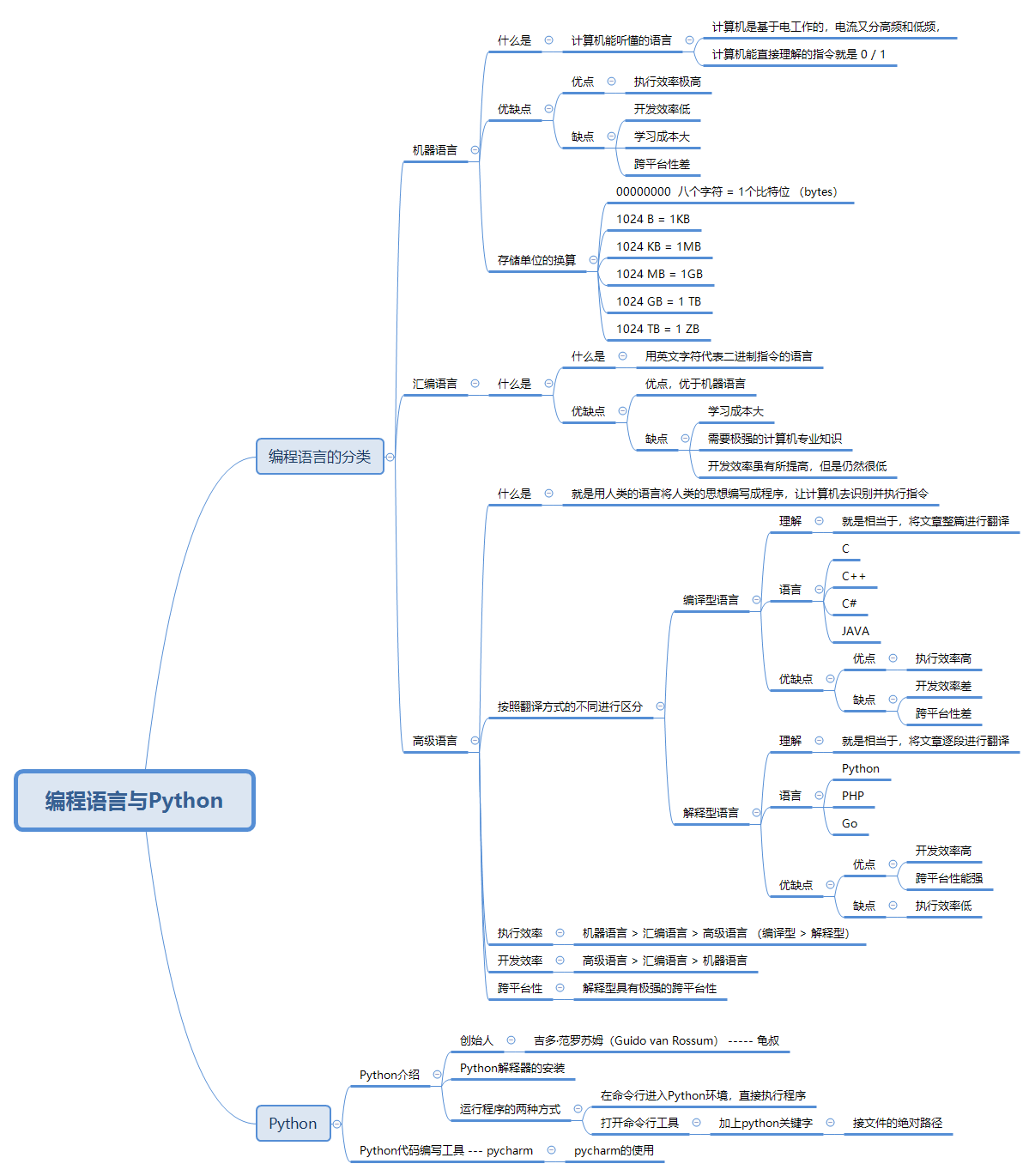
(1)变量的定义与调用
-
变量的定义由三部分组成,如下图
-
定义规范示例
name = 'ly' # 记下人的名字为'ly' sex = '男' # 记下人的性别为男性 age = 18 # 记下人的年龄为18岁 salary = 30000.1 # 记下人的薪资为30000.1元 -
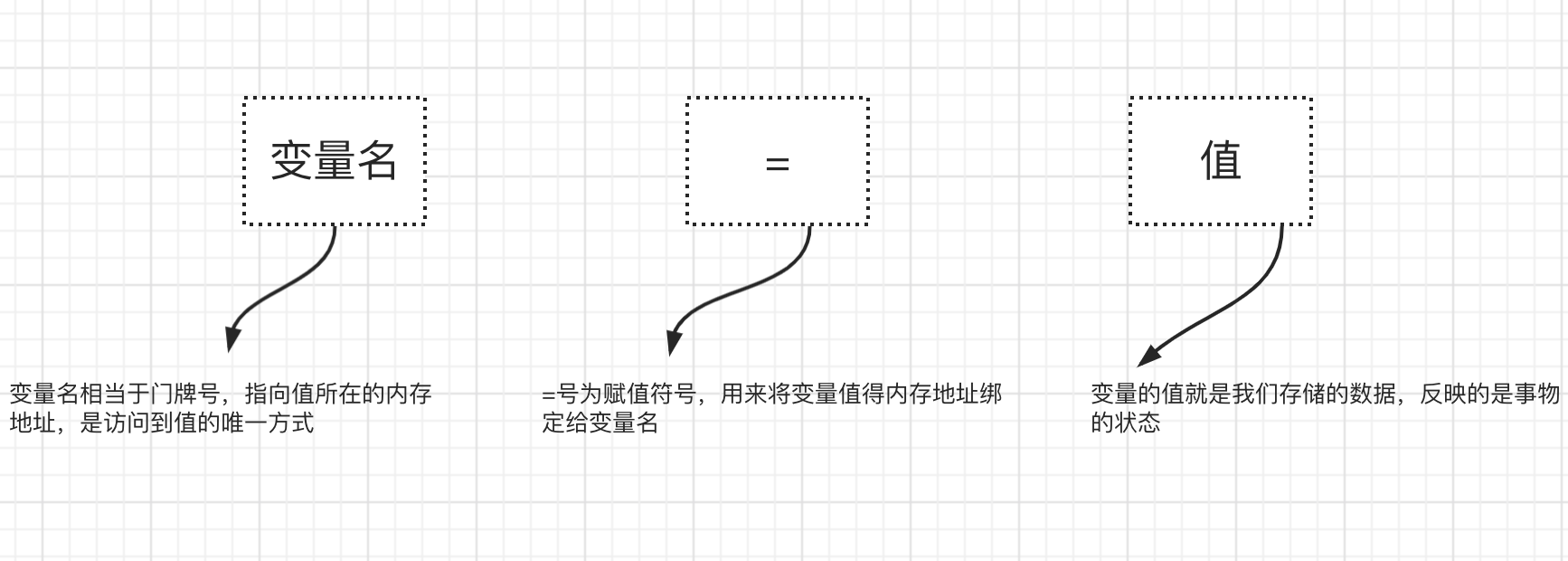
解释器执行到变量定义的代码时会申请内存空间存放变量值
- 然后将变量值的内存地址绑定给变量名
- 以变量的定义age=18为例,如下图
-
通过变量名即可引用到对应的值:
-
通过变量名即可引用到值,我们可以结合print()功能将其打印出来 print(age)
-
通过变量名age找到值18,然后执行print(18),输出:18
-
(2)变量的命名规范
变量的命名应该见名知意
-
如果我们要存储的数据18代表的是一个人的年龄,那么变量名推荐命名为:
- age age = 18
-
如果我们要存储的数据18代表的是一个人的等级,那么变量名推荐命名为:
- level level = 18
-
其他的命名规范如下
# 命名规范 1. 变量名只能是 字母、数字或下划线的任意组合 2. 变量名的第一个字符不能是数字 3. 关键字不能声明为变量名,常用关键字如下 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] # 错误示范如下 *a=123 $b=456 c$=789 2_name='lili' 123='lili' and=123 年龄=18 # 强烈建议不要使用中文命名 # 正确示范如下 age_of_ly=31 page1='首页' _class='终极一班'(3)变量名的风格
-
风格一:驼峰体
- 大驼峰:每个单词的首字母都大写,其余字母小写
- AgeOfTony = 56
- 小驼峰:每个单词的首字母都大写,只有第一个单词的首字母是小写
- numberOfStudents = 80
- 大驼峰:每个单词的首字母都大写,其余字母小写
-
风格二:
-
纯小写下划线:所有字母都小写,每个单词之间使用下划线分隔(在python中,变量名的命名推荐使用该风格)
- age_of_tony = 56
- number_of_students = 80
【4】变量的三大特性
#1、id (内存地址 - 内存编号)
- 反应的是变量在内存中的唯一编号,内存地址不同id肯定不同
#2、type (数据类型)
- 变量值的类型
#3、value (变量值)
- 变量值
查看变量的三大特性的方法
>>> x='Info Tony:18'
>>> id(x),type(x),x
4376607152,<class 'str'>,'Info Tony:18'
当变量值比较小的时候,有多个变量使用变量值的时候,多个变量名会指向同一个变量值所在的内存空间
'''小整数池的概念'''
【二】常量
(1)什么是常量
- 常量指在程序运行过程中不会改变的量
(2)为什么要有常量
- 在程序运行过程中,有些值是固定的、不应该被改变
- 比如圆周率 3.141592653…
在其他语言中,真正意义上的常量,中间是不能改变的,如果你改变,就报错,但是,在python中,无所谓,你改变也不报错!
在JavaScript语言中,就有真正意义的常量,中途不能修改,修改就报错
(3)常量的使用
- 在Python中没有一个专门的语法定义常量
- 约定俗成是用全部大写的变量名表示常量
- 如:PI=3.14159
- 所以单从语法层面去讲,常量的使用与变量完全一致。
【三】垃圾回收机制
解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题
- 当一个变量值没有用了(简称垃圾)就应该将其占用的内存给回收掉,那什么样的变量值是没有用的呢?
单从逻辑层面分析,我们定义变量将变量值存起来的目的是为了以后取出来使用,而取得变量值需要通过其绑定的直接引用(如x=10,10被x直接引用)或间接引用(如l=[x,],x=10,10被x直接引用,而被容器类型l间接引用)
- 所以当一个变量值不再绑定任何引用时,我们就无法再访问到该变量值了,该变量值自然就是没有用的,就应该被当成一个垃圾回收。
毫无疑问,内存空间的申请与回收都是非常耗费精力的事情,而且存在很大的危险性,稍有不慎就有可能引发内存溢出问题
- 好在Cpython解释器提供了自动的垃圾回收机制来帮我们解决了这件事。
(1)什么是垃圾回收机制
- 垃圾回收机制(简称GC)是Python解释器自带的一种机制
- 专门用来回收不可用的变量值所占用的内存空间(在内存中,没有变量名指向的数据都是垃圾数据)
(2)为什么要有垃圾回收机制
- 程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃
- 因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
(3)GC原理
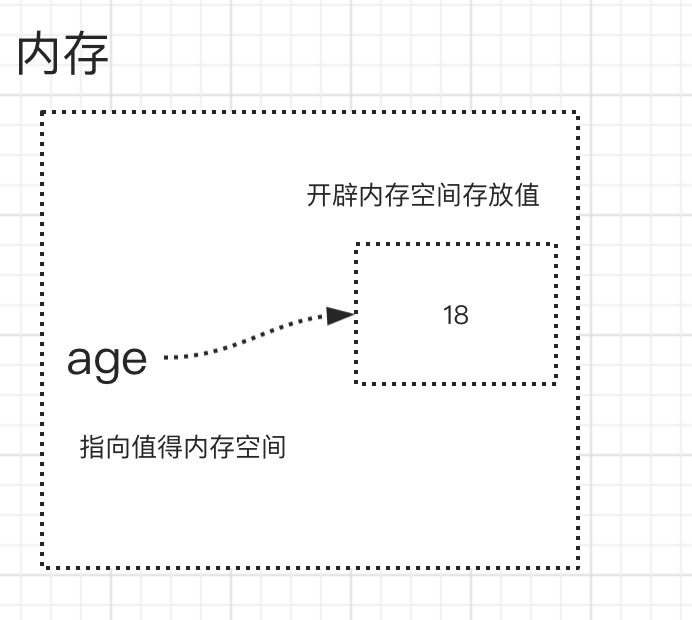
(3.1)堆区和栈区
-
在定义变量时,变量名与变量值都是需要存储的
-
分别对应内存中的两块区域:
- 堆区
- 变量名与值内存地址的关联关系存放于栈区
- 栈区
- 变量值存放于堆区,内存管理回收的则是堆区的内容,
- 堆区
-
示例
-
定义了两个变量x = 10、y = 20,详解如下图
-
当我们执行x=y时,内存中的栈区与堆区变化如下
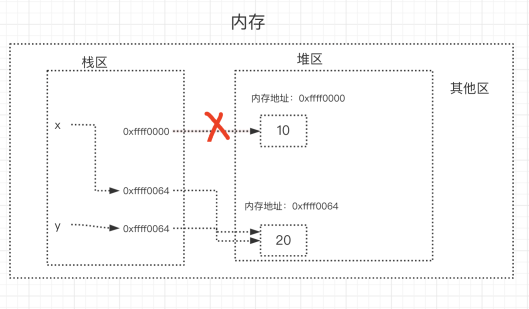
-
(3.2)直接引用和简介引用
-
直接引用指的是从栈区出发直接引用到的内存地址。
-
间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。
l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用
x = 10 # 值10被变量名x直接引用
l1 = [x, l2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引用
- 图解
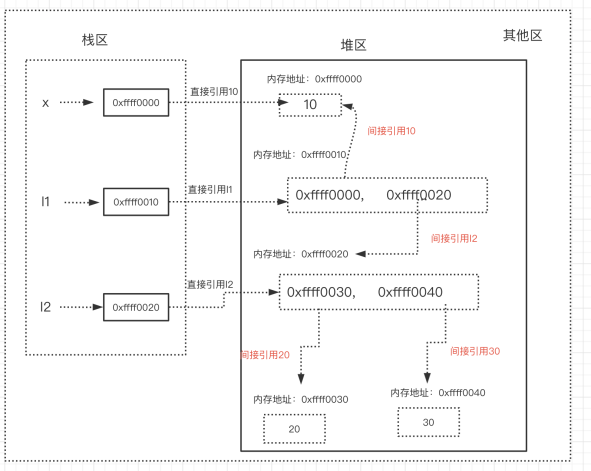
(4)垃圾回收机制原理分析
引用计数为主,垃圾回收、分代回收为辅。
- Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。
- 在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
(4.1)引用计数
- 引用计数就是:变量值被变量名关联的次数
- 如:age=18
- 变量值18被关联了一个变量名age,称之为引用计数为1
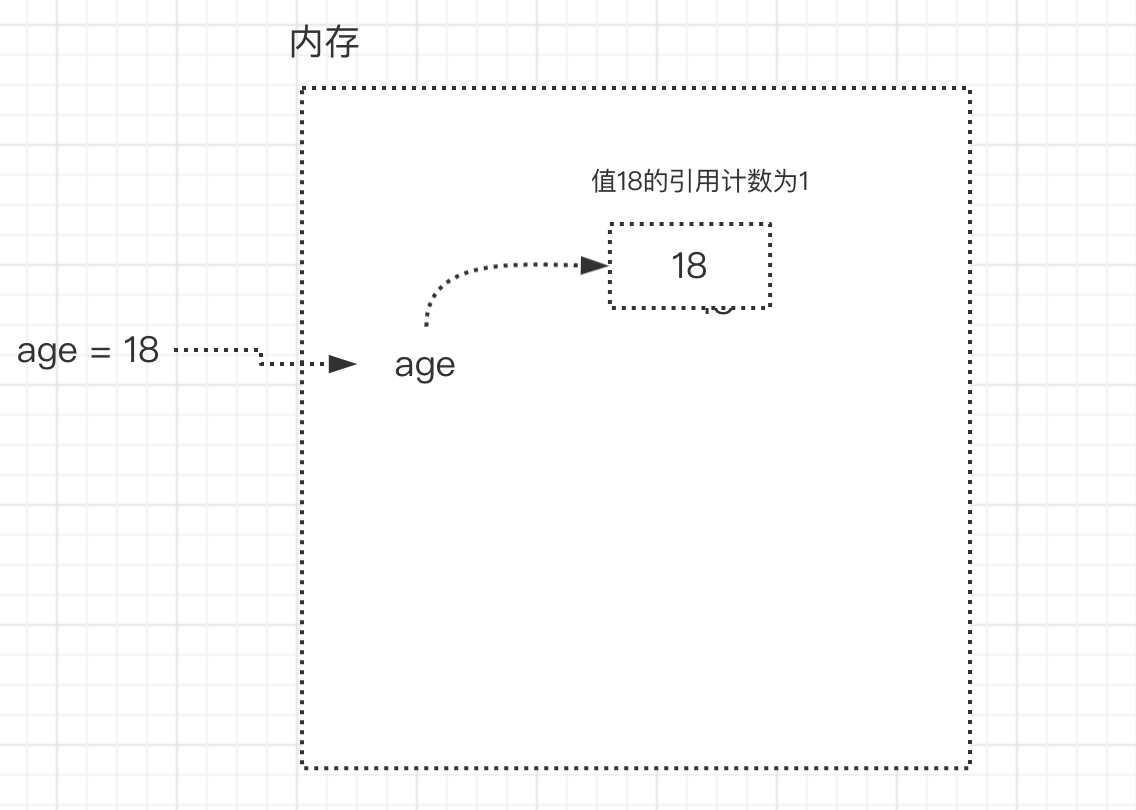
- 引用计数增加:
- age=18 (此时,变量值18的引用计数为1)
- m=age (把age的内存地址给了m,此时,m,age都关联了18,所以变量值18的引用计数为2)
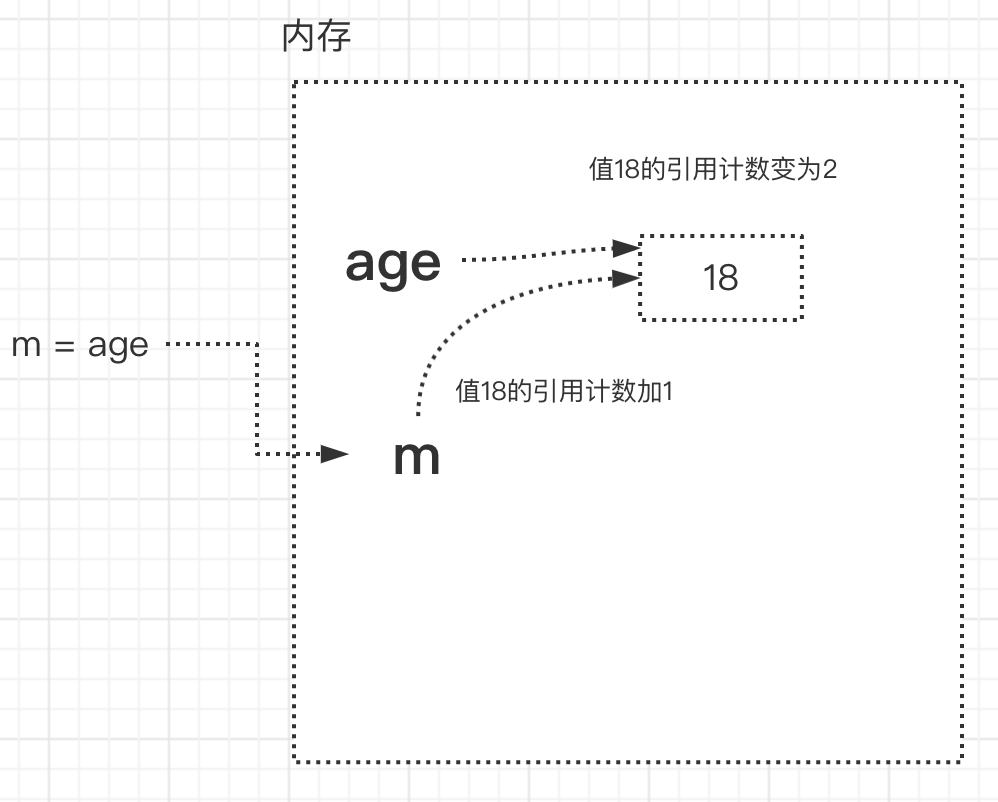
-
引用计数减少:
- age=10(名字age先与值18解除关联,再与3建立了关联,变量值18的引用计数为1)
-
del m(del的意思是解除变量名x与变量值18的关联关系,此时,变量18的引用计数为0)
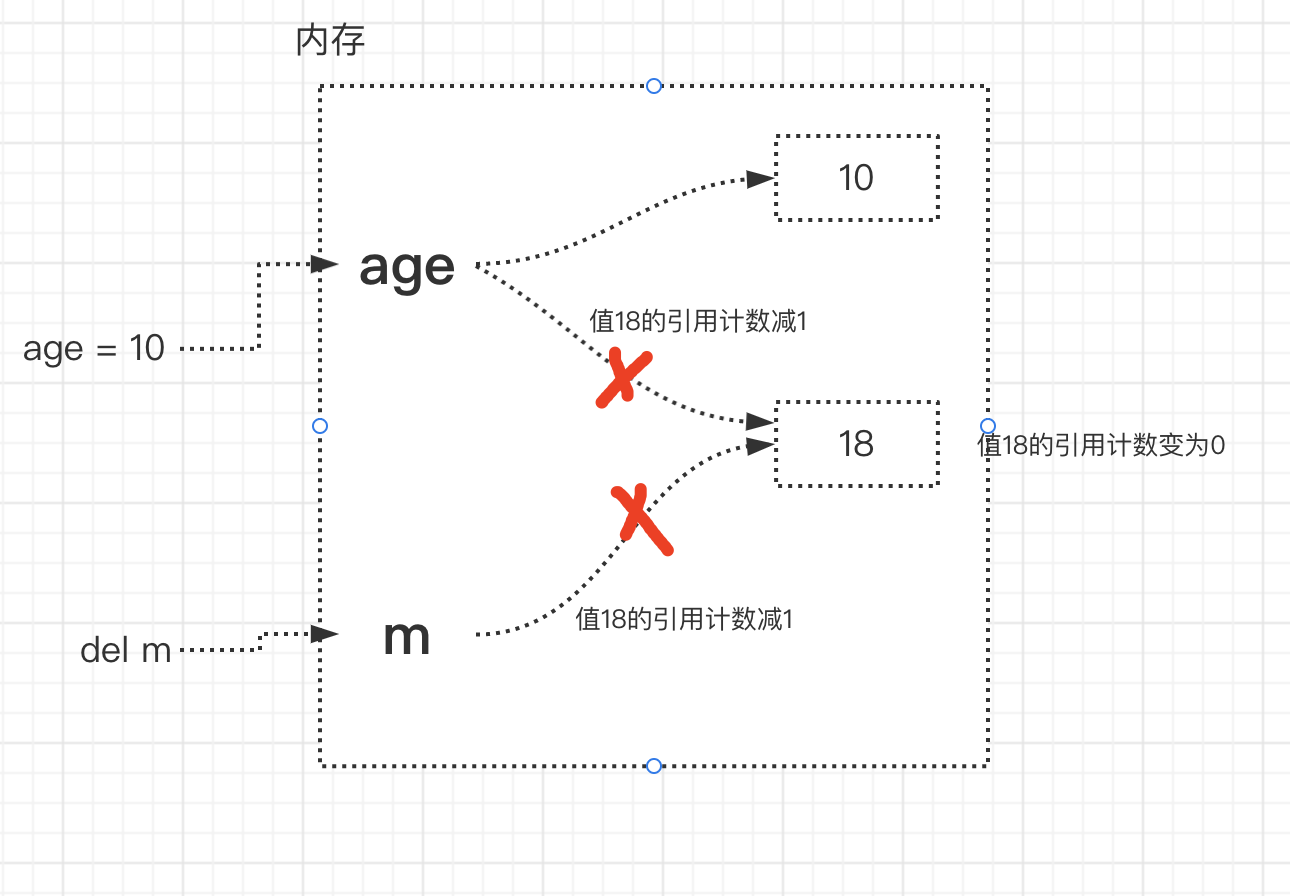
- 值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
# 一个变量值可以有多个变量名指向,有一个变量名指向,引用计数就是1,有两个就是2 # 只要引用计数不为0,这个变量值就不是垃圾数据,当引用计数为0了,说明这个变量值就没用了,就可以清除了 """ 1. 一个变量名只能指向一个内存空间 2. 一个内存空间可以被多个变量名指向 """
(4.2)引用计数的解决问题与解决方案
(4.2.1)问题一
- 引用计数机制存在着一个致命的弱点,即循环引用(也称交叉引用)
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# 1. l1与l2之间有相互引用
# 2. l1 = ['xxx'的内存地址,列表2的内存地址]
# 3. l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
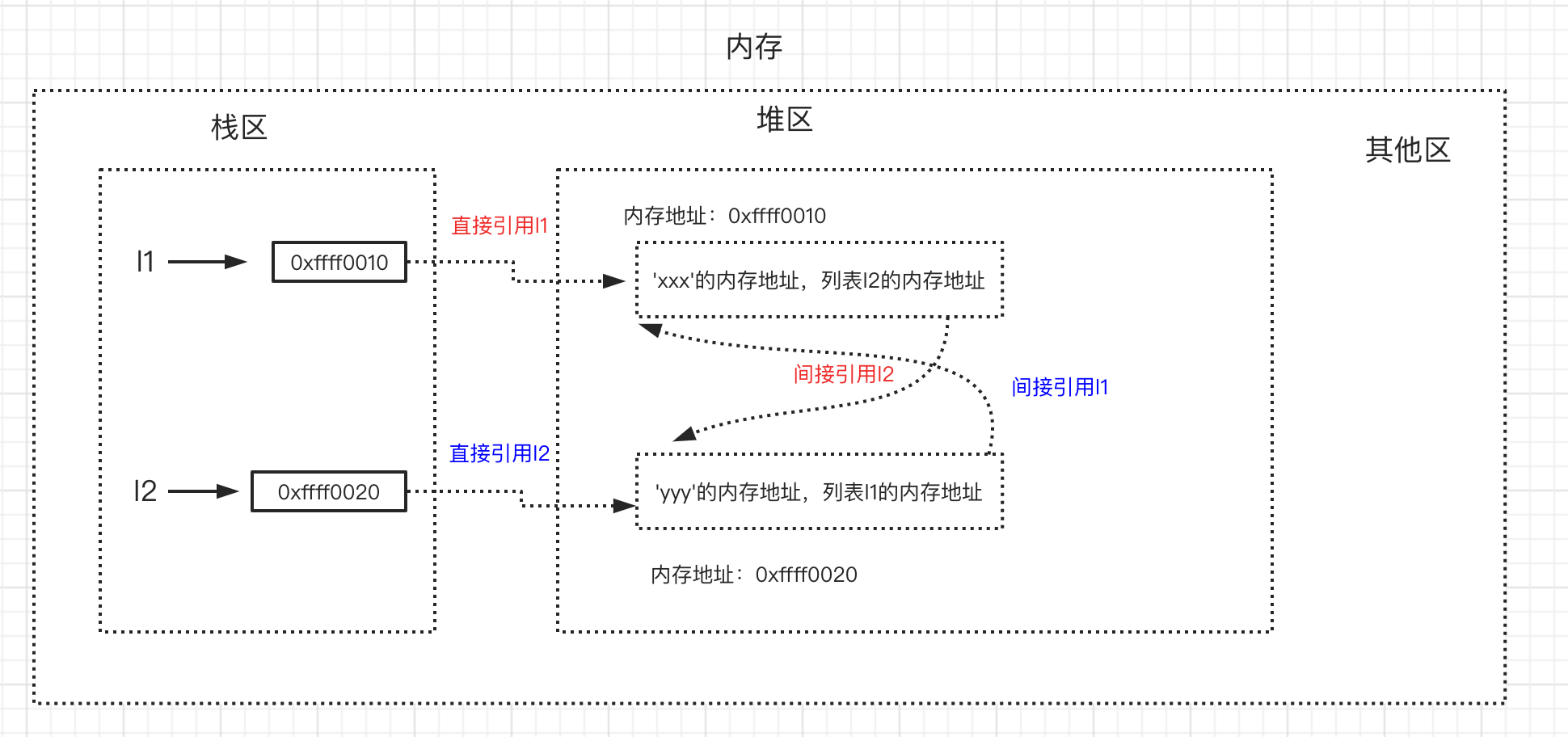
- 循环引用会导致:
- 值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收
- 什么意思呢?试想一下,请看如下操作
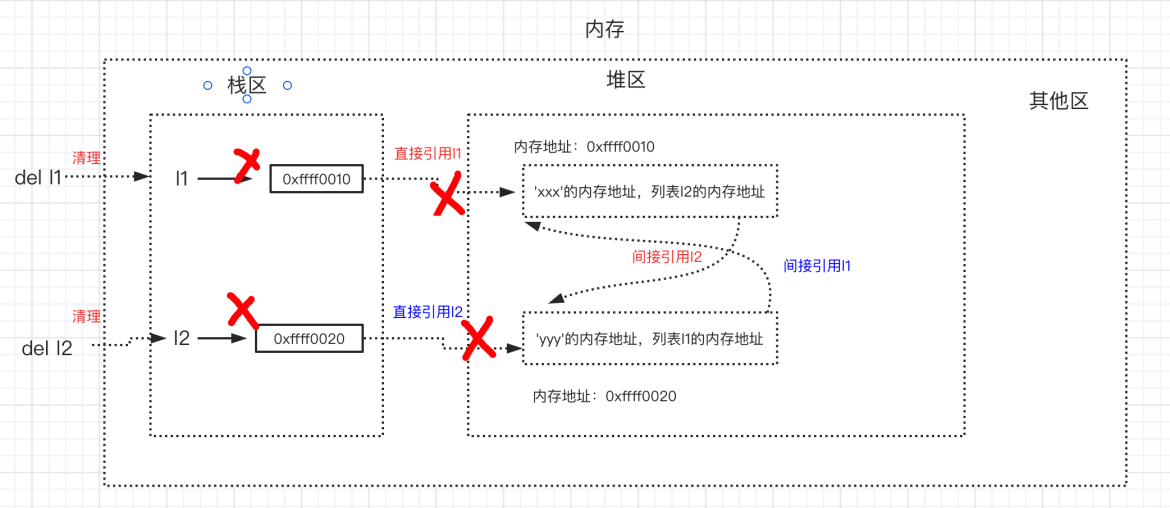
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1
>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1
- 此时,只剩下列表1与列表2之间的相互引用
-
但此时两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们
- 所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0
- 因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。
-
所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
(4.2.2) 解决方案:标记-清除
当内存空间即将沾满的时候,python会暂停程序的运行,从头到位扫描一遍,并且把扫描出来的垃圾数据做标记,然后,一次性做清除处理
-
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。
- 而“标记-清除”计数就是为了解决循环引用的问题。
-
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作
- 第一项则是标记
- 通俗地讲就是:
- 栈区相当于“根”,凡是从根出发可以访达(直接或间接引用)的,都称之为“有根之人”,有根之人当活,无根之人当死。
- 具体地:
- 标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
- 通俗地讲就是:
- 第二项则是清除
- 清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
- 第一项则是标记
-
基于上例的循环引用,当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容以及直接引用关系
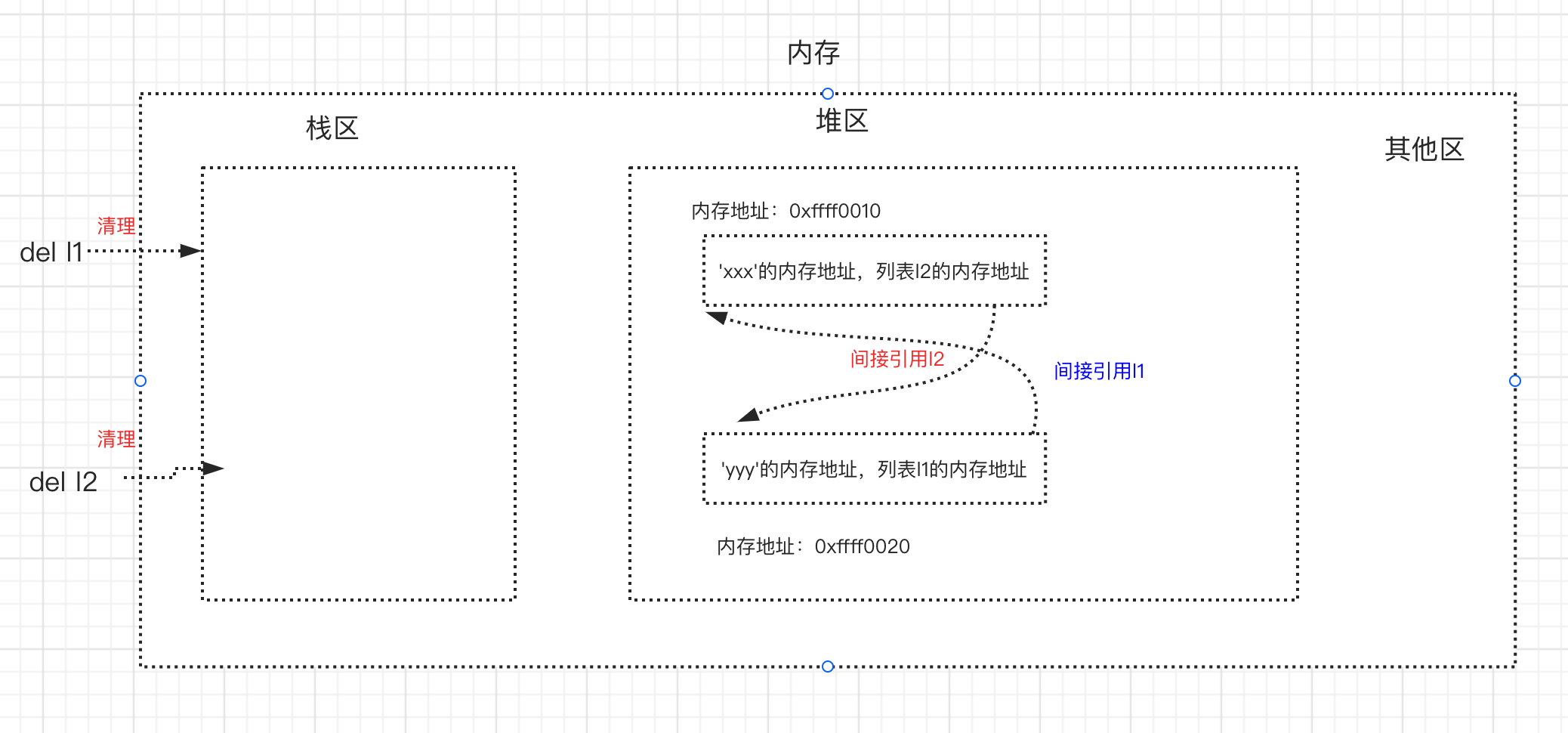
- 这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
(4.2.3)问题二:效率问题
- 基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的
- 于是引入了分代回收来提高回收效率
- 分代回收采用的是用“空间换时间”的策略。
(4.2.4)解决方案:分代回收
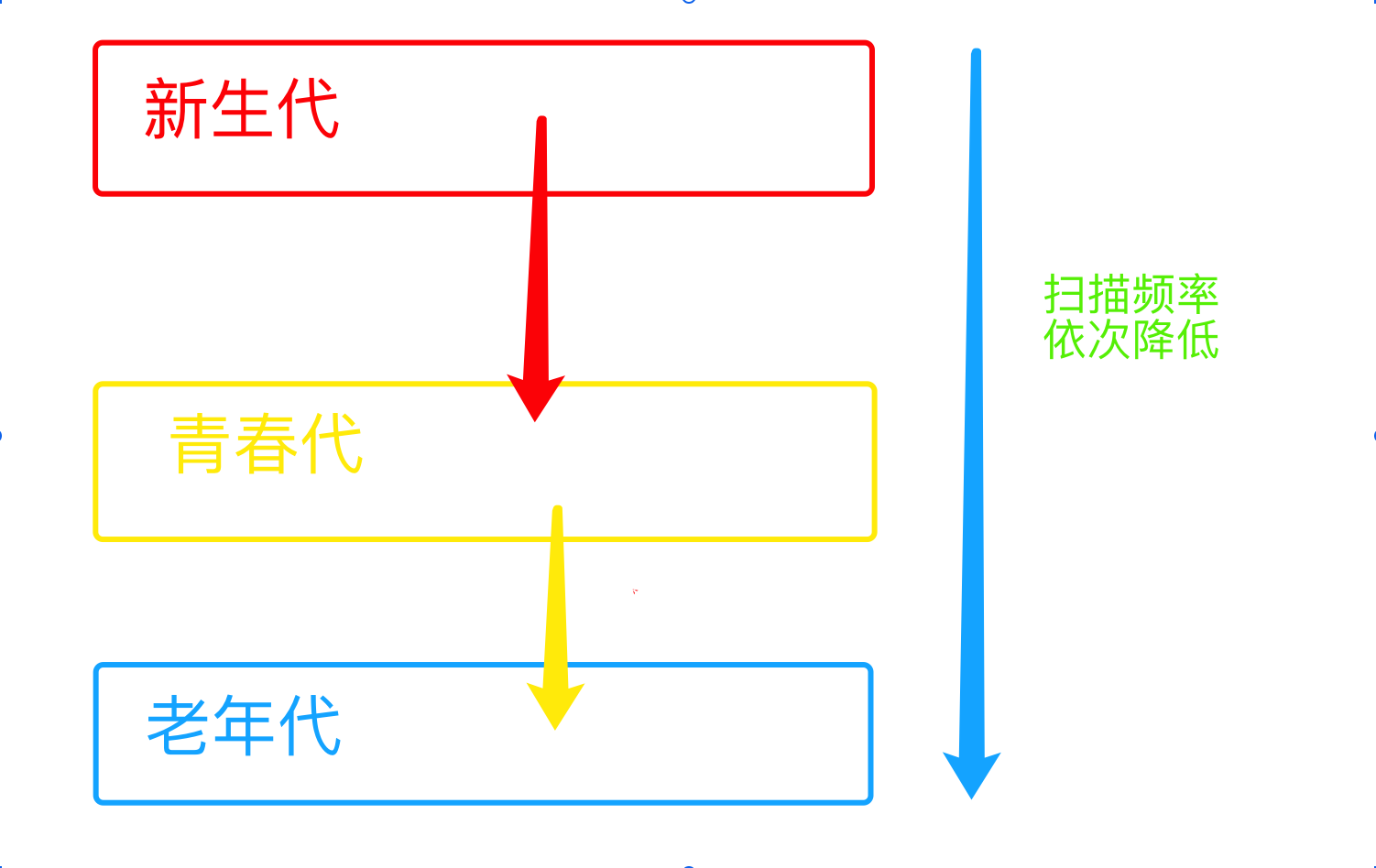
- 分代回收的核心思想是:
- 在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低
- 具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,
青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低
- 回收
- 回收依然是使用引用计数作为回收的依据
- 虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
- 例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,这就到导致了应该被回收的垃圾没有得到及时地清理。
- 没有十全十美的方案:
- 毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描,可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低,所以我们只能将二者中和。
(4.2.5)小结
- 垃圾回收机制是在清理垃圾&释放内存的大背景下
- 允许分代回收以极小部分垃圾不会被及时释放为代价,以此换取引用计数整体扫描频率的降低,从而提升其性能
- 这是一种以空间换时间的解决方案
【四】基本数据类型
- 我们学习变量是为了让计算机能够像人一样去记忆事物的某种状态
- 而变量的值就是用来存储事物状态的,很明显事物的状态分成不同种类的(比如人的年龄,身高,职位,工资等等)
- 所以变量值也应该有不同的类型,例如
salary = 3.1 # 用浮点型去记录薪资
age = 18 # 用整型去记录年龄
name = 'lili' # 用字符串类型去记录人名
【1】数字类型
(1)整形(int)
(1.1)作用
- 用来记录人的年龄,出生年份,学生人数等整数相关的状态

(1.2)定义
age=18
birthday=1990
student_count=48
(2)浮点型(float)
(2.1)作用
- 用来记录人的身高,体重,薪资等小数相关的状态
(2.2)定义
height=172.3
weight=103.5
salary=15000.89
(3)数字类型的应用
(3.1)数字运算
>>> a = 1
>>> b = 3
>>> c = a + b
>>> c
4
(3.2)比较大小
>>> x = 10
>>> y = 11
>>> x > y
False
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17401902.html

